O artigo consiste em duas partes:
- Uma breve descrição de algumas arquiteturas de rede para detectar objetos em uma imagem e segmentação de imagens com os links mais compreensíveis para recursos para mim. Tentei escolher explicações em vídeo e de preferência em russo.
- A segunda parte é uma tentativa de entender a direção do desenvolvimento de arquiteturas de redes neurais. E tecnologias baseadas nelas.

Figura 1 - Compreender a arquitetura das redes neurais não é fácil
Tudo começou com o fato de ele ter criado dois aplicativos de demonstração para classificar e detectar objetos em um telefone Android:
- Demonstração de back-end , quando os dados são processados no servidor e transferidos para o telefone. Classificação de imagem de três tipos de ursos: marrom, preto e pelúcia.
- Demonstração de front-end quando os dados são processados no próprio telefone. Detecção de objetos de três tipos: avelãs, figos e tâmaras.
Há uma diferença entre as tarefas de classificar imagens, detectar objetos em uma imagem e segmentar imagens . Portanto, era necessário descobrir quais arquiteturas de rede neural detectam objetos nas imagens e quais podem segmentar. Encontrei os seguintes exemplos de arquiteturas com os links mais compreensíveis para recursos para mim:
- Uma série de arquiteturas baseadas em R-CNN (regiões com recursos de C etvolução N etworks): R-CNN, R-CNN rápida, R-CNN mais rápida, R-CNN mais rápida , Máscara R-CNN . Para detectar um objeto em uma imagem usando o mecanismo RPN (Region Proposal Network), caixas delimitadoras são alocadas. Inicialmente, o mecanismo de busca seletiva mais lento foi usado em vez do RPN. Em seguida, as regiões limitadas selecionadas são alimentadas à entrada de uma rede neural normal para classificação. Na arquitetura do R-CNN, existem ciclos explícitos "para" de enumeração em regiões limitadas, no total até 2000 são executados na rede interna da AlexNet. Devido a loops explícitos "for", a velocidade de processamento da imagem é mais lenta. O número de ciclos explícitos, percorre a rede neural interna, diminui a cada nova versão da arquitetura e dezenas de outras alterações são realizadas para aumentar a velocidade e substituir a tarefa de detectar objetos pela segmentação de objetos na Máscara R-CNN.
- O YOLO (apenas um local de trabalho) é a primeira rede neural que reconhece objetos em tempo real em dispositivos móveis. Característica distintiva: distinguir objetos em uma execução (basta olhar uma vez). Ou seja, não há loops "for" explícitos na arquitetura YOLO, e é por isso que a rede é rápida. Por exemplo, é uma analogia: no NumPy não há loops explícitos "for" em operações com matrizes, que são implementadas no NumPy em níveis mais baixos da arquitetura por meio da linguagem de programação C. O YOLO usa uma grade de janelas predefinidas. Para impedir que o mesmo objeto seja detectado várias vezes, é usado o coeficiente de sobreposição da janela (IoU, Intersecção ou União). Essa arquitetura funciona em uma ampla gama e possui alta robustez : o modelo pode ser treinado em fotografias, mas ao mesmo tempo funciona bem em pinturas pintadas.
- SSD (Simple MultiBox D etector) - os “hacks” mais bem-sucedidos da arquitetura YOLO (por exemplo, supressão não máxima) são usados e novos são adicionados para tornar a rede neural mais rápida e precisa. Característica distintiva: distinguir objetos em uma corrida usando uma determinada grade de janelas (caixa padrão) na pirâmide de imagens. A pirâmide de imagens é codificada em tensores de convolução durante operações sucessivas de convolução e agrupamento (com a operação de agrupamento máximo, a dimensão espacial diminui). Dessa maneira, objetos grandes e pequenos são determinados em uma única execução de rede.
- O MobileSSD ( Mobile NetV2 + SSD ) é uma combinação de duas arquiteturas de rede neural. A primeira rede MobileNetV2 é rápida e aumenta a precisão do reconhecimento. O MobileNetV2 é usado no lugar do VGG-16, originalmente usado no artigo original . A segunda rede SSD determina a localização dos objetos na imagem.
- SqueezeNet é uma rede neural muito pequena, mas precisa. Por si só, não resolve o problema de detectar objetos. No entanto, ele pode ser usado com uma combinação de diferentes arquiteturas. E ser usado em dispositivos móveis. Uma característica distintiva é que os dados são compactados primeiro para quatro filtros convolucionais 1 × 1 e depois expandidos para quatro filtros convolucionais 1 × 1 e quatro 3 × 3. Uma dessas iterações de expansão de compactação de dados é chamada de “Módulo de Incêndio”.
- DeepLab (Segmentação de Imagem Semântica com Redes Convolucionais Profundas) - segmentação de objetos na imagem. Uma característica distintiva da arquitetura é uma convolução diluída, que preserva a resolução espacial. Isso é seguido pelo estágio de pós-processamento dos resultados usando um modelo probabilístico gráfico (campo aleatório condicional), que permite remover pequenos ruídos na segmentação e melhorar a qualidade da imagem segmentada. Por trás do formidável nome “modelo probabilístico gráfico” está o filtro gaussiano usual, que é aproximado em cinco pontos.
- Tentei entender o dispositivo RefineDet (rede neural de refino de detecção única para detecção de objetos), mas entendi muito pouco.
- Também observei como a tecnologia de atenção funciona: vídeo1 , vídeo2 , vídeo3 . Uma característica distintiva da arquitetura de “atenção” é a alocação automática de regiões de maior atenção à imagem (RoI, Razões de interesse) usando uma rede neural chamada Unidade de Atenção. As regiões com maior atenção são semelhantes às regiões limitadas (caixas delimitadoras), mas, diferentemente delas, elas não são fixas na imagem e podem ter bordas borradas. Então, das regiões de maior atenção, distinguem-se características (características) que são "alimentadas" a redes neurais recorrentes com arquiteturas LSDM, GRU ou Vanilla RNN . As redes neurais recursivas são capazes de analisar a relação dos sinais em uma sequência. As redes neurais recursivas foram originalmente usadas para traduzir texto em outros idiomas e agora para traduzir imagens em texto e texto em imagens .
Ao estudar essas arquiteturas, percebi que não entendia nada . E o ponto não é que minha rede neural tenha problemas com o mecanismo de atenção. A criação de todas essas arquiteturas parece uma espécie de hackathon enorme, onde os autores competem em hacks. Hack é uma solução rápida para uma tarefa difícil de software. Ou seja, não há conexão lógica visível e compreensível entre todas essas arquiteturas. Tudo o que os une é um conjunto dos hacks mais bem-sucedidos emprestados um do outro, além de uma operação de convolução comum com feedback (propagação reversa de erro, retropropagação). Nenhum pensamento sistêmico ! Não está claro o que mudar e como otimizar as conquistas existentes.
Como resultado da falta de uma conexão lógica entre os hacks, eles são extremamente difíceis de lembrar e colocar em prática. Isso é conhecimento fragmentado. Na melhor das hipóteses, vários momentos interessantes e inesperados são lembrados, mas a maior parte do que é entendido e incompreensível desaparece da memória em poucos dias. Será bom se em uma semana eu me lembrar pelo menos do nome da arquitetura. Mas foram necessárias várias horas e até dias de trabalho para ler artigos e assistir a vídeos de resenhas!
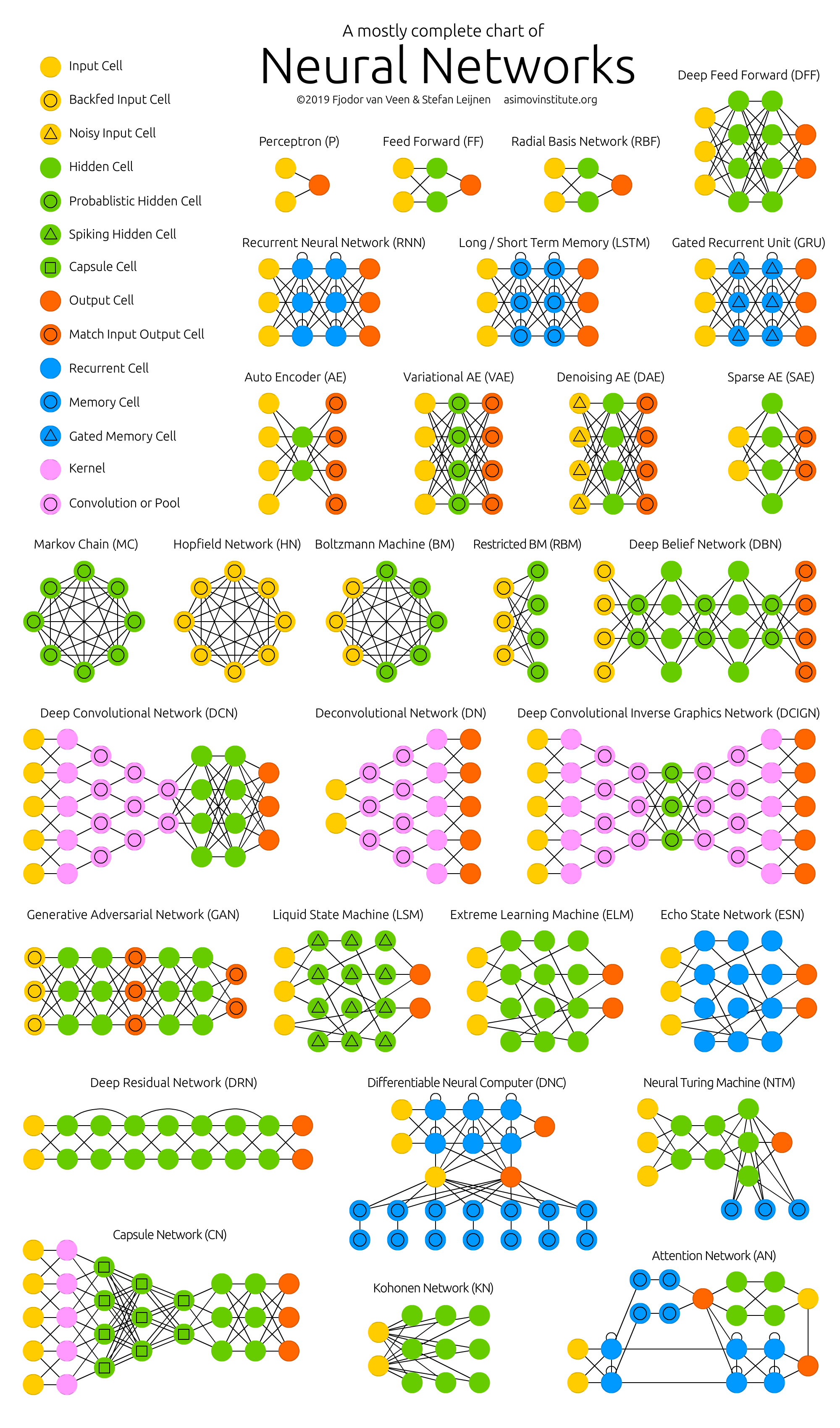
Figura 2 - Zoológico de redes neurais
A maioria dos autores de artigos científicos, na minha opinião pessoal, faz todo o possível para que mesmo esse conhecimento fragmentado não seja entendido pelo leitor. Mas os particípios em frases de dez linhas com fórmulas tiradas "do teto" são um tópico para um artigo separado (problema de publicação ou perecimento ).
Por esse motivo, tornou-se necessário sistematizar as informações nas redes neurais e, assim, aumentar a qualidade da compreensão e memorização. Portanto, o principal tópico de análise de tecnologias e arquiteturas individuais de redes neurais artificiais foi a seguinte tarefa: descobrir para onde tudo isso está se movendo , e não o dispositivo de qualquer rede neural específica separadamente.
Para onde está indo tudo isso? Os principais resultados:
- O número de startups no campo de aprendizado de máquina caiu acentuadamente nos últimos dois anos. Possível motivo: "as redes neurais deixaram de ser algo novo".
- Todos poderão criar uma rede neural funcional para resolver um problema simples. Para fazer isso, pegue o modelo finalizado no “zoológico modelo” e treine a última camada da rede neural ( transferência de aprendizado ) nos dados finais da Pesquisa de conjuntos de dados do Google ou em 25 mil conjuntos de dados Kaggle na nuvem gratuita do Jupyter Notebook .
- Grandes fabricantes de redes neurais começaram a criar “zoológicos modelo” (zoológico modelo). Com eles, você pode criar rapidamente um aplicativo comercial: TF Hub para TensorFlow, MMDetection para PyTorch, Detectron para Caffe2, chainer-modelzoo para Chainer e outros .
- Redes neurais em tempo real em dispositivos móveis. 10 a 50 quadros por segundo.
- O uso de redes neurais em telefones (TF Lite), em navegadores (TF.js) e em itens domésticos (IoT, Internet e Te). Especialmente em telefones que já suportam redes neurais no nível do hardware (neuroaceleradores).
- “Cada dispositivo, roupa e possivelmente até comida terão um endereço IP-v6 e se comunicarão” - Sebastian Trun .
- O aumento nas publicações de aprendizado de máquina começou a exceder a lei de Moore (dobrando a cada dois anos) desde 2015. Obviamente, são necessárias redes neurais de análise de artigos.
- As seguintes tecnologias estão ganhando popularidade:
- PyTorch - A popularidade está crescendo rapidamente e parece ultrapassar o TensorFlow.
- Seleção automática de hiperparâmetros AutoML - a popularidade está crescendo sem problemas.
- Diminuição gradual da precisão e aumento da velocidade de computação: lógica fuzzy , algoritmos de aumento , cálculos imprecisos (aproximados), quantização (quando os pesos de uma rede neural são convertidos em números inteiros e quantizados), neuroaceleradores.
- Tradução da imagem em texto e texto em imagem .
- Criando objetos tridimensionais em vídeo , agora em tempo real.
- O principal no DL é muitos dados, mas não é fácil coletá-los e marcá-los. Portanto, a anotação automatizada para redes neurais usando redes neurais está sendo desenvolvida.
- Com as redes neurais, a Ciência da Computação tornou-se repentinamente uma ciência experimental e surgiu uma crise de reprodutibilidade .
- O dinheiro de TI e a popularidade das redes neurais surgiram simultaneamente quando a computação se tornou um valor de mercado. A economia de ouro e câmbio está se tornando computação em moeda de ouro . Veja meu artigo sobre econofísica e o motivo do surgimento do dinheiro de TI.
Gradualmente, uma nova metodologia de programação ML / DL (Machine Learning & Deep Learning) aparece, que se baseia na apresentação do programa como uma coleção de modelos de redes neurais treinados.
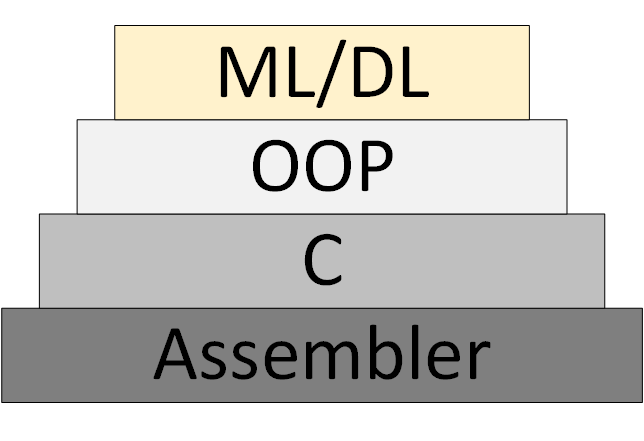
Figura 3 - ML / DL como uma nova metodologia de programação
No entanto, a “teoria das redes neurais” não apareceu, dentro da estrutura em que se pode pensar e trabalhar sistematicamente. O que agora é chamado de "teoria" é na verdade algoritmos heurísticos experimentais.
Links para meus e não apenas recursos:
- Boletim informativo sobre ciência de dados. Principalmente processamento de imagem. Quem quiser receber, deixe-o enviar um e-mail (foobar167 <gaff-gaf> gmail <dot> com). Envio links para artigos e vídeos à medida que o material se acumula.
- Uma lista geral de cursos e artigos que fiz e gostaria de fazer.
- Cursos e vídeos para iniciantes , dos quais vale a pena começar a estudar redes neurais. Além do folheto "Introdução ao aprendizado de máquina e redes neurais artificiais" .
- Ferramentas úteis onde todos encontrarão algo interessante para si.
- Os canais de vídeo para a análise de artigos científicos sobre Data Science foram extremamente úteis. Encontre, assine e envie links para seus colegas e para mim também. Exemplos:
Obrigado pela atenção!