Neste artigo, apresento a vocês meus pensamentos sobre a história e as perspectivas do desenvolvimento da Internet, redes centralizadas e descentralizadas e, como resultado, a possível arquitetura da rede descentralizada da próxima geração.
Algo está errado com a Internet
Eu conheci a Internet pela primeira vez em 2000. Obviamente, isso está longe do começo - a Rede já existia antes disso, mas esse tempo pode ser chamado de primeiro auge da Internet. A World Wide Web é uma brilhante invenção de Tim Berners-Lee, web1.0 em sua forma canônica clássica. Muitos sites e páginas com links para hiperlinks. À primeira vista - uma arquitetura simples, como toda brilhante:
descentralizada e gratuita . Eu quero - estou viajando pelos sites de outras pessoas, seguindo hiperlinks; Eu quero - eu crio meu próprio site no qual publico o que é interessante para mim - por exemplo, meus artigos, fotos, programas, hiperlinks para sites que são interessantes para mim. E outros postam links para mim.
Parece - uma imagem idílica? Mas você já sabe como tudo terminou.
Havia muitas páginas, e a busca por informações tornou-se algo muito não trivial. Os hiperlinks registrados pelos autores simplesmente não conseguiram estruturar essa enorme quantidade de informações. Primeiro, havia diretórios preenchidos manualmente e, em seguida, mecanismos de busca gigantes que começaram a usar algoritmos engenhosos de classificação heurística. Sites foram criados e abandonados, as informações foram duplicadas e distorcidas. A Internet estava comercializando rapidamente e se distanciando da rede acadêmica ideal. A linguagem de marcação rapidamente se transformou em uma linguagem de formatação. Havia publicidade, banners vis e irritantes e a tecnologia de promoção e engano dos mecanismos de busca - SEO. A rede ficou rapidamente entupida com lixo informativo. Os hiperlinks deixaram de ser uma ferramenta de comunicação lógica e se transformaram em uma ferramenta de promoção. Os sites eram pequenos, fechados, transformados de "páginas" abertas em "aplicações" herméticas, tornando-se apenas um meio de gerar renda.
Mesmo assim, eu tinha um certo pensamento de que "algo está errado aqui". Um monte de sites diferentes, variando de páginas iniciais primitivas com uma aparência vyrviglazny e terminando com "megaportals", sobrecarregados com banners tremeluzentes. Mesmo se sites com o mesmo tópico - eles são completamente independentes, cada um tem seu próprio design, sua própria estrutura, banners irritantes, pesquisas mal trabalhadas, problemas com o download (sim, eu queria ter informações offline). Mesmo assim, a Internet começou a se transformar em uma espécie de televisão, onde todo tipo de enfeites estava preso a um conteúdo útil com unhas.
A descentralização se tornou um pesadelo.
O que voce quer
Paradoxalmente, como usuário, eu não precisava de descentralização! Lembrando meus pensamentos claros daqueles tempos, chego à conclusão de que precisava ... de um
único banco de dados ! Uma consulta à qual daria todos os resultados, mas não a mais adequada para o algoritmo de classificação. Um em que todos esses resultados seriam uniformemente modelados e modelados pelo meu próprio desenho único, em vez de desenhos vyrviglaznymi feitos por numerosos Vasya Pupkin. Um que poderia ser mantido offline e não ter medo de que amanhã o site desapareça e as informações desapareçam para sempre. Um em que eu poderia inserir minhas informações - por exemplo, comentários e tags. Um em que eu poderia pesquisar, classificar e filtrar com meus algoritmos pessoais.
Web 2.0 e redes sociais
Enquanto isso, o conceito da Web 2.0 entrou na arena. Formulado em 2005 por Tim O'Reilly como "uma metodologia para projetar sistemas que, levando em consideração as interações de rede, se tornam melhores quanto mais pessoas os usam" - e implicando o envolvimento ativo dos usuários na criação e edição coletiva de conteúdo da Web. Sem exagero, as redes sociais se tornaram o pináculo e o triunfo desse conceito. Plataformas gigantes que reúnem bilhões de usuários e armazenam centenas de petabytes de dados.
O que recebemos nas redes sociais?
- unificação de interface; despejou que todas as possibilidades para criar um usuário de design vyviglazny diverso não precisam; todas as páginas de todos os usuários têm o mesmo design e são adequadas a todos e são até convenientes; apenas o conteúdo é diferente.
- unificação funcional; toda a variedade de scripts também era desnecessária. Lenta, amigos, álbuns ... durante a existência de redes sociais, sua funcionalidade se estabilizou mais ou menos e é improvável que mude: afinal, a funcionalidade é determinada pelos tipos de atividade das pessoas, e as pessoas praticamente não mudam.
- banco de dados único; trabalhar com esse banco de dados acabou sendo muito mais conveniente do que com muitos sites diferentes; a pesquisa se tornou muito mais fácil. Em vez de varrer continuamente uma variedade de páginas fracamente acopladas, armazenando tudo isso em cache, classificando por algoritmos heurísticos complexos - uma consulta unificada relativamente simples para um único banco de dados com uma estrutura conhecida.
- interface de feedback - curtidas e republicações; na web comum, o mesmo Google não pôde receber feedback dos usuários depois de clicar no link nos resultados da pesquisa. Nas redes sociais, essa conexão era simples e natural.
O que perdemos?
Perdemos a descentralização, o que significa liberdade . Acredita-se que agora nossos dados não nos pertencem. Se antes poderíamos hospedar uma página inicial mesmo em nosso próprio computador, agora entregamos todos os nossos dados a gigantes da Internet.
Além disso, à medida que a Internet evoluiu, governos e empresas se interessaram por ela, e houve problemas de censura política e restrições de direitos autorais. Nossas páginas nas redes sociais podem ser banidas e excluídas se o conteúdo não obedecer a nenhuma regra da rede social; para um cargo descuidado - leve à responsabilidade administrativa e até criminal.
E aqui estamos novamente pensando: é possível retornar a descentralização para nós? Mas de uma forma diferente, desprovida das deficiências da primeira tentativa?
Redes ponto a ponto
As primeiras redes p2p apareceram muito antes da web 2.0 e se desenvolveram paralelamente ao desenvolvimento da web. A principal aplicação clássica do p2p é o compartilhamento de arquivos; as primeiras redes foram projetadas para compartilhar músicas. As primeiras redes (como o Napster) foram essencialmente centralizadas e, portanto, os detentores dos direitos autorais as cobriram rapidamente. Os seguidores seguiram o caminho da descentralização. Em 2000, os protocolos ED2K (o primeiro cliente eDokney) e Gnutella apareceram; em 2001, o protocolo FastTrack (cliente KaZaA) apareceu. Gradualmente, o grau de descentralização aumentou, as tecnologias melhoraram. Os sistemas com uma “fila de downloads” foram substituídos por torrents, e o conceito de tabelas de hash DHT distribuídas apareceu. À medida que as castanhas foram apertadas pelos estados, o anonimato dos participantes tornou-se mais exigido. Desde 2000, a rede Freenet está em desenvolvimento, desde 2003 I2P, e em 2006 o projeto RetroShare foi lançado. Você pode mencionar as inúmeras redes p2p que existiam anteriormente e já desapareceram - e agora estão operacionais: WASTE, MUTE, TurtleF2F, RShare, PerfectDark, ARES, Gnutella2, GNUNet, IPFS, ZeroNet, Tribbler e muitos outros. Existem muitos deles. Eles são diferentes. Muito diferente - tanto no objetivo quanto no design ... Provavelmente muitos de vocês nem conhecem todos esses nomes. E isso está longe de tudo.
No entanto, as redes p2p têm muitas desvantagens. Além das falhas técnicas inerentes a cada implementação específica do protocolo e do cliente, por exemplo, uma desvantagem bastante geral é a complexidade da pesquisa (ou seja, tudo o que a Web 1.0 encontrou, mas em uma versão ainda mais complicada). O Google não está aqui com sua pesquisa onipresente e instantânea. E se, para redes de compartilhamento de arquivos, você ainda pode usar a pesquisa por nome de arquivo ou meta-informação, encontrar algo, por exemplo, em redes de cebola ou sobreposição i2p, é muito difícil, se possível.
Em geral, se traçarmos analogias com a Internet clássica, a maioria das redes descentralizadas fica presa em algum lugar no nível do FTP. Imagine a Internet, na qual não há nada além de FTP: nem sites modernos, nem web2.0, nem Youtube ... Isso acontece nesse estado, e há redes descentralizadas. E, apesar das tentativas individuais de mudar alguma coisa, há poucas mudanças.
Conteúdo
Vamos passar para outra peça importante desse quebra-cabeça - o conteúdo. O conteúdo é o principal problema de qualquer recurso da Internet e, em particular, descentralizado. De onde obtê-lo? Obviamente, você pode contar com muitos entusiastas (como é o caso das redes p2p existentes), mas o desenvolvimento da rede será bastante longo e haverá pouco conteúdo.
Trabalhar com a Internet normal é a pesquisa e o estudo de conteúdo. Às vezes é preservação (se o conteúdo é interessante e útil, muitos, especialmente aqueles que acessaram a Rede durante o período de discagem - inclusive eu), sabiamente o mantêm offline para não se perder; pois a Internet é algo incontrolável para nós, hoje não há site amanhã , hoje existe um vídeo no YouTube - amanhã ele foi excluído etc.
E para torrents (que percebemos mais como um meio de entrega do que como uma rede p2p), a preservação geralmente está implícita. E esse, a propósito, é um dos problemas dos torrents: é difícil mover o arquivo baixado uma vez para onde é mais conveniente usá-lo (como regra, você precisa regenerar manualmente a distribuição) e é absolutamente impossível renomeá-lo (você pode criar um link físico, mas poucas pessoas sabem disso).
Em geral, muitos armazenam conteúdo de uma maneira ou de outra. Qual é o seu destino futuro? Geralmente, os arquivos salvos aparecem em algum lugar do disco, em uma pasta como Downloads, em uma pilha comum, e ficam lá, junto com muitos milhares de outros arquivos. Isso é ruim - e ruim para o próprio usuário. Se a Internet possui mecanismos de busca, o computador local do usuário não possui nada disso. É bom que o usuário seja elegante e use para classificar os arquivos baixados "recebidos". Mas nem todos eles ...
De fato, agora existem muitos que não economizam nada, mas confiam inteiramente no online. Porém, em redes p2p, supõe-se que o conteúdo seja armazenado localmente no dispositivo do usuário e distribuído para outros participantes. É possível encontrar uma solução que permita envolver ambas as categorias de usuários em uma rede descentralizada sem alterar seus hábitos e, além disso, facilitar sua vida?
A idéia é bastante simples: e se tornarmos um meio conveniente e transparente para o usuário salvar conteúdo da Internet comum e economizar inteligentemente com metainformações semânticas, e não em um heap geral, mas em uma estrutura específica com a possibilidade de estruturação adicional e, ao mesmo tempo, distribuir o conteúdo salvo em descentralizado a rede?
Vamos começar salvando
Não consideraremos o uso utilitário da Internet para visualizar previsões do tempo ou horários de aeronaves. Estamos mais interessados em objetos independentes e mais ou menos imutáveis - artigos (a partir de tweets / posts de redes sociais e terminando com artigos grandes, como aqui no Habré), livros, imagens, programas, gravações de áudio e vídeo. De onde vêm as informações? Geralmente
- redes sociais (várias notícias, notas pequenas - “tweets”, fotos, áudio e vídeo)
- artigos sobre recursos temáticos (como Habr); não existem muitos bons recursos, geralmente esses recursos também são construídos com base no princípio das redes sociais
- sites de notícias
Como regra, existem funções padrão: curtir, repassar, compartilhar nas redes sociais etc.
Imagine um
plug-in de navegador que salvará de maneira especial tudo o que gostamos, republicado, salvo no “favorito” (ou clicamos em um botão de plug-in especial exibido no menu do navegador, caso o site não tenha uma função semelhante / repost / marcador). A idéia principal é que você goste - como fez um milhão de vezes antes, e o sistema salva o artigo, a foto ou o vídeo em um armazenamento offline especial e este artigo ou a imagem fica disponível - e para visualização offline pela interface do cliente descentralizada e na rede mais descentralizada! Quanto a mim, é muito conveniente. Não há ações desnecessárias e resolvemos imediatamente muitos problemas:
- salvar conteúdo valioso que pode ser perdido ou excluído
- enchimento rápido de rede descentralizada
- agregação de conteúdo de diferentes fontes (você pode ser registrado em dezenas de recursos da Internet, e todos os curtidas / republicações se agruparão em um único banco de dados local)
- estruturando seu conteúdo de acordo com suas regras
Obviamente, o plug-in do navegador deve ser configurado na estrutura de cada site (isso é bastante realista - já existem plug-ins para salvar o conteúdo do Youtube, Twitter, VK, etc.). Não existem muitos sites para os quais faça sentido criar plugins pessoais. Como regra, essas são redes sociais difundidas (quase não há uma dúzia delas) e um certo número de sites temáticos de alta qualidade, como o Habr (também existem alguns). Com o código-fonte aberto e as especificações, o desenvolvimento de um novo plug-in baseado em um modelo em branco não deve levar muito tempo. Para outros sites, você pode usar o botão salvar universal, que salvaria a página inteira em mhtml - possivelmente depois de limpar a página da publicidade.
Agora sobre estruturação
Por economia “inteligente”, quero dizer, pelo menos, salvar com meta-informação: fonte de conteúdo (URL), conjunto de curtidas, tags, comentários, seus identificadores, etc. De fato, durante o armazenamento normal, essas informações são perdidas ... Uma fonte pode significar não apenas uma URL direta, mas também um componente semântico: por exemplo, um grupo em redes sociais ou um usuário que repostou. O plug-in pode ser inteligente o suficiente para usar essas informações para estruturação e marcação automáticas. Além disso, deve-se entender que o próprio usuário sempre pode adicionar algumas metainformações ao conteúdo armazenado, para as quais você deve fornecer ferramentas de interface mascaradas e convenientes (tenho muitas idéias sobre como fazer isso).
Assim, a questão da estruturação e organização de arquivos de usuários locais é resolvida. Esse é um benefício pronto que pode ser usado mesmo sem qualquer p2p. É apenas um tipo de banco de dados offline que sabe o que, onde e em que contexto salvamos e permite que você conduza pequenos estudos. Por exemplo, encontre usuários de uma rede social externa que gostem principalmente das mesmas postagens que você. Quantas redes sociais permitem isso explicitamente?
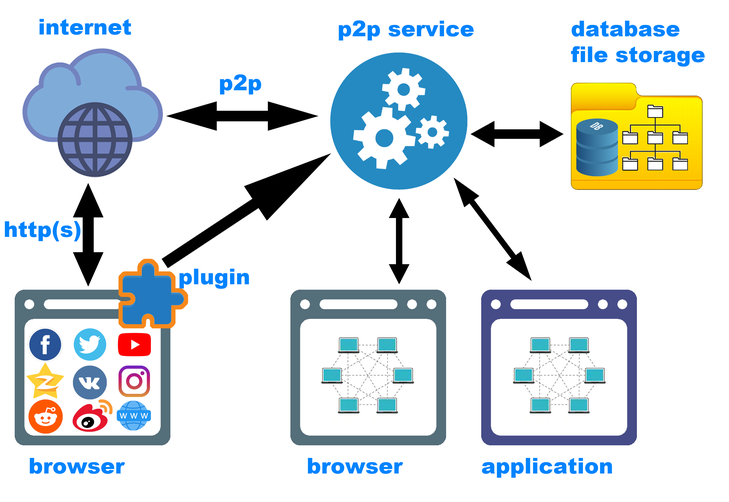
Já deve ser mencionado aqui que um plug-in de navegador certamente não é suficiente. O segundo componente mais importante do sistema é um serviço de rede descentralizado que é executado em segundo plano e atende a própria rede p2p (solicitações da rede e solicitações do cliente), além de salvar novo conteúdo usando o plug-in. O serviço, trabalhando em conjunto com o plug-in, colocará o conteúdo no lugar certo, calculará os hashes (e possivelmente determinará que esse conteúdo já foi salvo), acrescentará as meta-informações necessárias ao banco de dados local.
O que é interessante - o sistema já seria útil nesta forma, sem nenhum p2p. Muitas pessoas usam clippers da Web que adicionam conteúdo interessante da Web, por exemplo, ao Evernote. A arquitetura proposta é uma versão estendida desse clipper.
Finalmente, troca p2p
A melhor parte é que informações e meta-informações (capturadas da Web e suas) podem ser trocadas. O conceito de rede social é bem portado para a arquitetura p2p. Podemos dizer que a rede social e o p2p parecem ser feitos um para o outro. Idealmente, qualquer rede descentralizada deve ser construída como uma rede social, somente então ela funcionará com eficiência. "Amigos", "Grupos" - essas são as festas com as quais deve haver laços estáveis, e essas são tiradas de uma fonte natural - os interesses comuns dos usuários.
Os princípios de armazenamento e distribuição de conteúdo em uma rede descentralizada são completamente idênticos aos princípios de armazenamento (captura) de conteúdo da Internet comum. Se você usar algum conteúdo da rede (o que significa que você o salvou), qualquer pessoa poderá usar seus recursos (disco e canal) necessários para receber esse conteúdo especificamente.
Os gostos são a ferramenta mais fácil de salvar e compartilhar. Se eu quiser - não importa, na Internet externa ou dentro de uma rede descentralizada -, então eu gosto do conteúdo e, se estiver, estou pronto para mantê-lo localmente e distribuí-lo a outros membros da rede descentralizada.
- O conteúdo não é "perdido"; agora ele está armazenado localmente comigo, posso retornar a ele mais tarde, a qualquer momento, sem me preocupar com alguém excluí-lo ou bloqueá-lo
- Eu posso (imediatamente ou mais tarde) categorizá-lo, marcar, comentar, associar-se a outro conteúdo, em geral fazer algo significativo com ele - vamos chamá-lo de "formação de meta-informações"
- Eu posso compartilhar essas informações meta com outros membros da rede.
- Posso sincronizar minhas meta informações com as meta informações de outros participantes
Provavelmente, a recusa de antipatias também parece lógica: se eu não gostar do conteúdo, é bastante lógico que não quero desperdiçar meu espaço em disco para armazenamento e meu canal da Internet para distribuir esse conteúdo. Portanto, aversões muito organicamente não se encaixam na descentralização (embora às vezes ainda seja
útil ).
Às vezes, você também precisa salvar o que não gosta. Existe uma palavra "necessária" :)
“
Favoritos ” (ou “Favoritos”) - não expresso minha atitude em relação ao conteúdo, mas salvo no meu banco de dados de favoritos local. «» (favorites) ( ), «» (bookmarks) — . «» — «» (.. «» ), «» - . ?
"
". , , , . () .
"
" — , , - , — , . , «», , — , / , .
, . — . — . , , , .
, , . , , , . , -, , ; , , .
, . , . , , , .. , . — , (, «» — , … , ).
, — ( i2p Retroshare), TOR VPN.
( ). , — , . — p2p , («backend»). , . — frontend. - ( ), GUI- (Windows, Linux, MacOS, Andriod, iOS ..). frontend'. backend'.
, . (.. , , , , — , , , ..), ( , Libgen), ( Freenet), ( ), ( — , , , , ..) .
1. — . (, ...) (, ...) —
2. , — /; p2p,
3.
4. /