Os sistemas de controle de versão são uma ferramenta diária para desenvolvedores. Em grandes monorepositórios, os requisitos para eles são muito específicos. Por isso, as empresas adaptam as soluções existentes, como o Facebook faz com o Mercurial e a Microsoft com o Git, ou desenvolvem seus próprios sistemas: Piper e CitC no Google e Arc VCS no Yandex.
No relatório, o desenvolvedor Vladimir Kikhtenko
kikht conta por que a Yandex precisava de seu próprio sistema de controle de versão e como ele funciona. Considere isso do lado de um desenvolvedor comum: como acessar o código-fonte, reservar um ramo para desenvolvimento e integrar as alterações em uma base de código comum. Nós olhamos por baixo - aprendemos sobre a representação interna dos dados e sua exibição em um sistema de arquivos virtual com uma cópia de trabalho. Discutiremos as dificuldades na implementação das funções do VCS em um sistema de arquivos virtual e ao carregar dados vagarosamente. Vamos falar sobre como garantir a confiabilidade da infraestrutura do servidor do repositório.
No final, você pode ver um registro não oficial do relatório.
- Boa tarde a todos, meu nome é Vladimir. Todos vocês ouviram discursos sobre não escrever bicicletas. Meu relatório estará do outro lado da barricada.
De fato, o Yandex tem um monorepositório no qual há muito código. E chegamos à conclusão de que estamos desenvolvendo nosso próprio sistema de controle de versão.

Como chegamos a essa vida? Historicamente, esse monorepositório morava conosco no SVN. Ela pratica o desenvolvimento baseado em tronco. Não há ramificações com muito poucas exceções. Todo o código deve primeiro entrar no tronco e depois ficar cheio.
Com o crescimento do repositório, a única maneira possível de trabalhar com ele foi o checkout seletivo, pois ele é suportado no SVN. Carregar o repositório inteiro para si mesmo não é totalmente impossível, mas é muito difícil trabalhar com ele.

Qual é a escala do nosso problema? Aqui estão alguns números: 6 milhões de confirmações, quase 2 milhões de arquivos individuais. O tamanho total com todo o histórico do repositório é de 2 TB. Para deixar claro o que esses números significam em comparação com outros repositórios típicos, aqui está um gráfico. A mediana do GitHub é o tamanho médio do repositório no GitHub, 1 MB. O percentil 90 no GitHub é o que meus colegas chamavam de "repositório do filho da namorada da minha mãe". E tudo o resto são os famosos grandes repositórios.
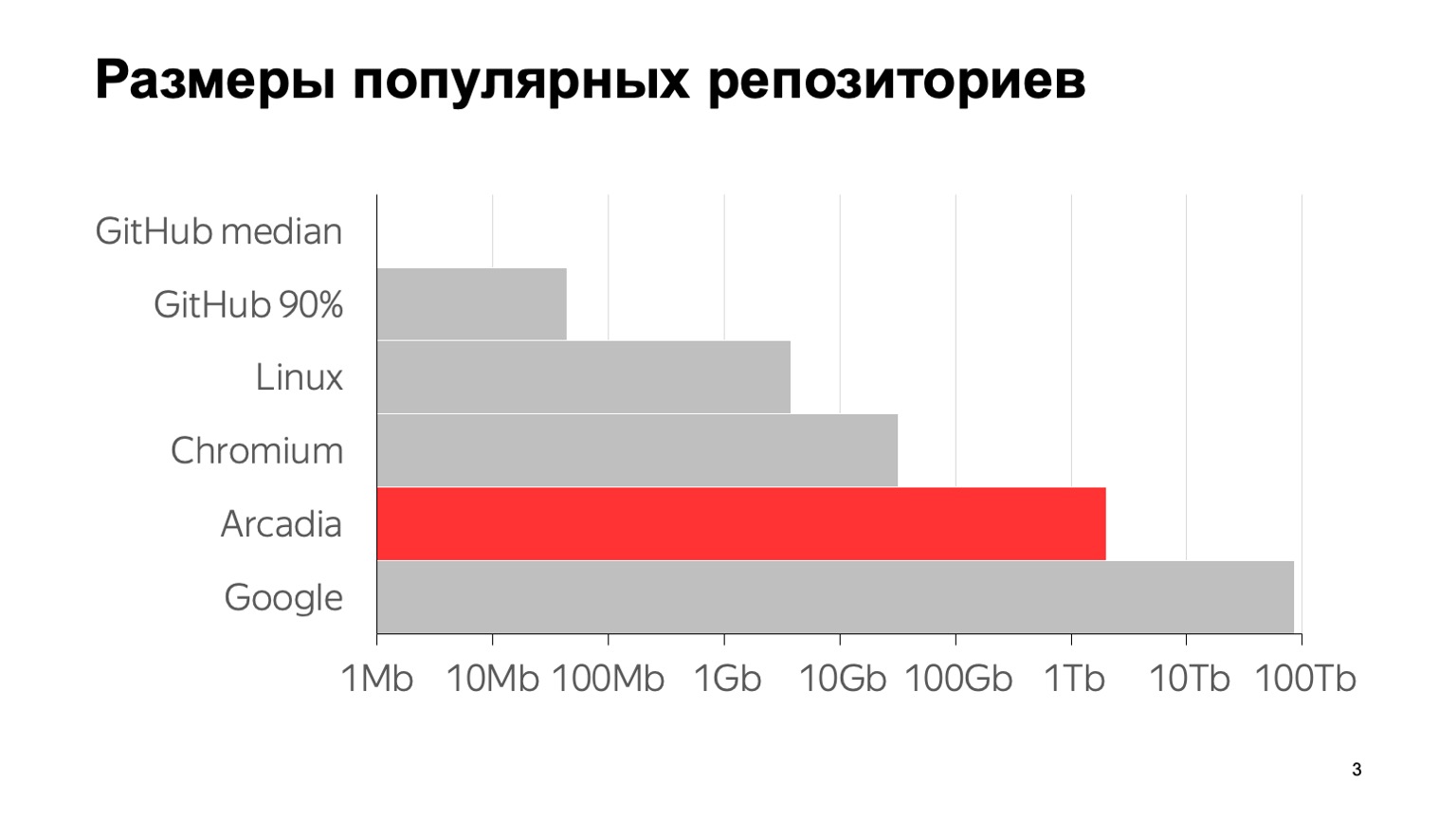
Até onde eu sei, o maior repositório do mundo é o Google. Uma estimativa de seu tamanho é dada a partir de um artigo em 2015 - provavelmente desde então eles cresceram. Como você pode ver, a escala é logarítmica. Pode-se ver que também somos muito grandes.
Como os diferentes sistemas de controle de versão funcionam ao tentar baixar todo o repositório? Naturalmente, não começamos imediatamente a desenvolver nosso sistema de controle de versão. Tentamos converter nosso repositório em diferentes sistemas. A tentativa mais séria foi feita com Mercurial. E os resultados do tempo das operações típicas ainda não nos agradam.
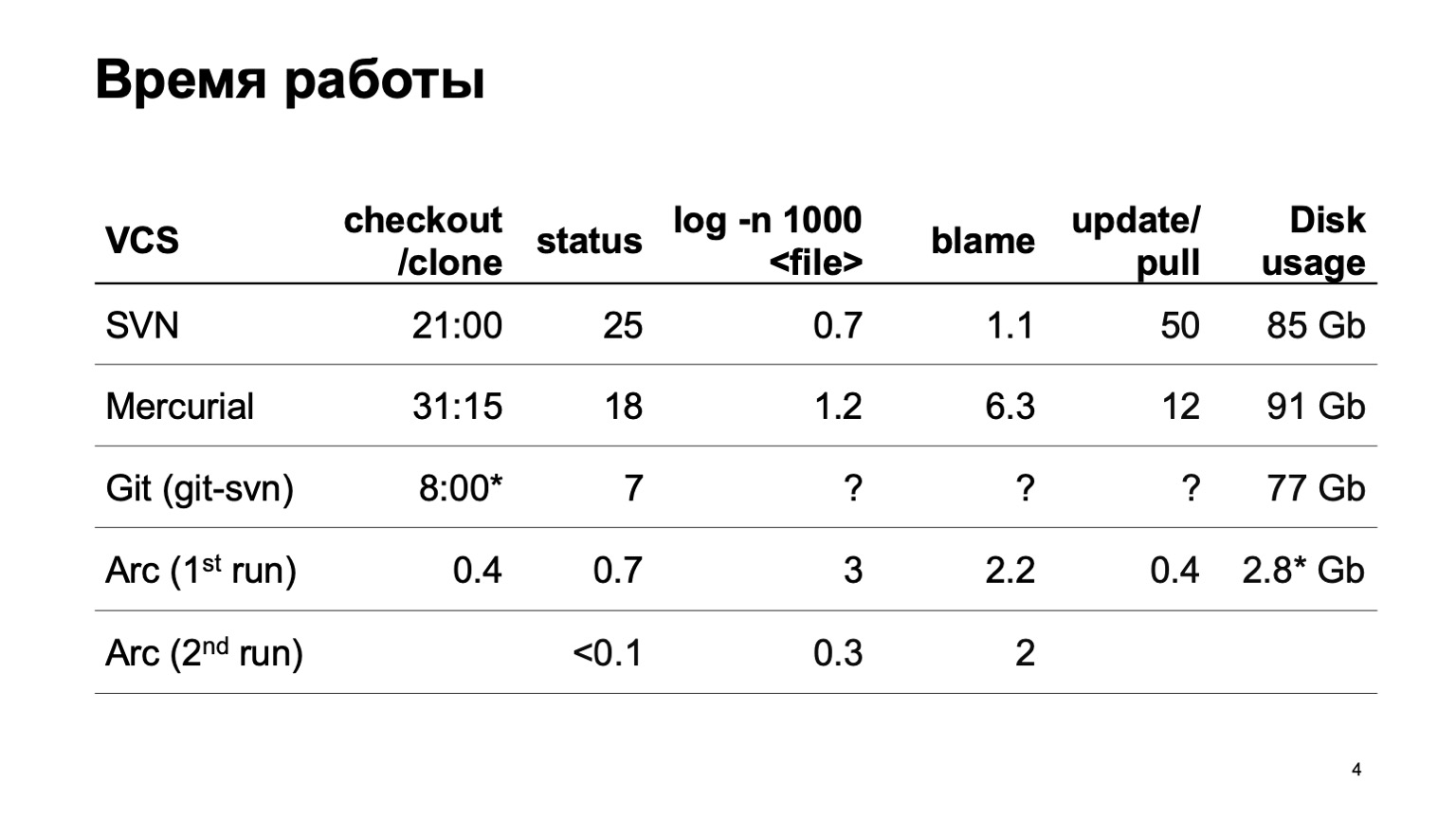
Durante a preparação do relatório, o git-svn, infelizmente, não pôde converter nosso repositório inteiro. Converti uma fatia de um pequeno número de confirmações, então não posso estimar quantas operações relacionadas ao histórico funcionam. Em um segmento, eles são rápidos, e como será para 6 milhões de confirmações não é muito claro.
No final, estão os números do nosso sistema de controle de versão. Você pode obter instantaneamente uma cópia de trabalho. Na primeira partida, as operações de log ficam um pouco mais lentas; na segunda partida, tudo funciona rapidamente.
E o último dígito. Como nosso sistema de controle de versão carrega todos os dados preguiçosamente, apenas os códigos-fonte que realmente elaboramos e que realmente usamos estão no disco. Isso é significativamente menor do que baixar o todo.

Como conseguimos isso? A principal característica: a cópia de trabalho que criamos não é um arquivo real no disco. Este é um sistema de arquivos virtual. No Linux e Mac, isso é feito com o fusível, no Windows com o ProjFS. Carregamos todos os dados preguiçosamente; portanto, quanto espaço em disco é usado, como realmente precisamos, não estamos tentando carregar tudo com antecedência. E realizamos todo o tipo de operações pesadas no servidor. Em particular - a operação do log e um pouco mais.

A interface do nosso sistema de controle de versão, em geral, repete o Git, então não mostrarei como é o fluxo de trabalho típico. Imagine o Git. Tudo é o mesmo: checkout para obter a revisão desejada, ramificação para criar ramificações, confirmação para confirmações, stash também é suportado da mesma maneira. O que essa abordagem oferece? Reduzimos significativamente o limite de entrada. A maioria dos desenvolvedores dentro e fora do Yandex pode trabalhar com o Git. Eles não precisam aprender nada de novo.
Por outro lado, não temos o objetivo de derrubar o Git. Falarei sobre isso mais tarde em mais detalhes. Apoiar toda a variedade de equipes git parece loucura, quase não precisamos de todas.

Vou falar um pouco sobre o interior, sobre como tudo funciona. Vamos começar com o modelo de dados. Nosso modelo de dados é muito semelhante ao modelo geográfico, com algumas diferenças. Da mesma forma, todos os objetos que criamos dentro são imutáveis, eles são tratados por um hash de seu conteúdo e, dentro, são armazenados em flatbuffers.

Como é a estrutura? Existem objetos de confirmação, cada confirmação tem um ancestral separado ou vários. E dessa maneira eles constroem algumas histórias do DAG (gráfico acíclico direcionado).
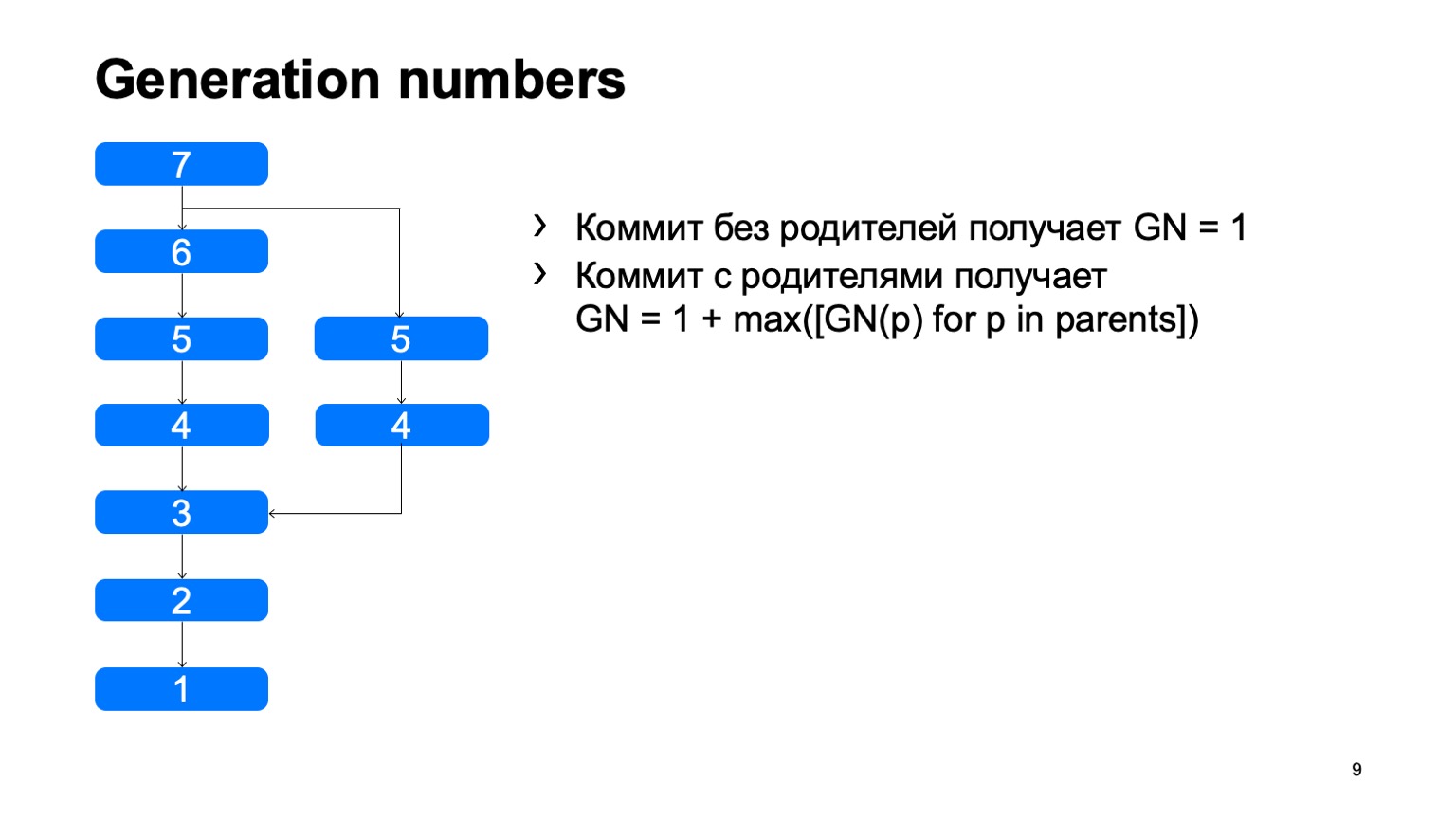
O que temos e o que não apareceu imediatamente no Git são os números de geração. Usando um algoritmo simples, consideramos uma certa distância da raiz da árvore. Por que precisamos disso? Tudo isso é costurado na estrutura dos objetos, uma vez corrigido, e nunca muda novamente.
Uma operação bastante importante para um sistema de controle de versão é encontrar o menor ancestral comum para os dois commits. Na versão básica, ele pode ser implementado simplesmente percorrendo a largura, começando em dois pontos, marcando todos os commits alcançados lá com um ou outro sinal, assim que eles encontrarem um commit com esses dois sinais, haverá o ancestral menos comum.
Como isso funcionará em uma implementação ingênua? Algo assim: vá ao redor e encontre nosso commit desejado.
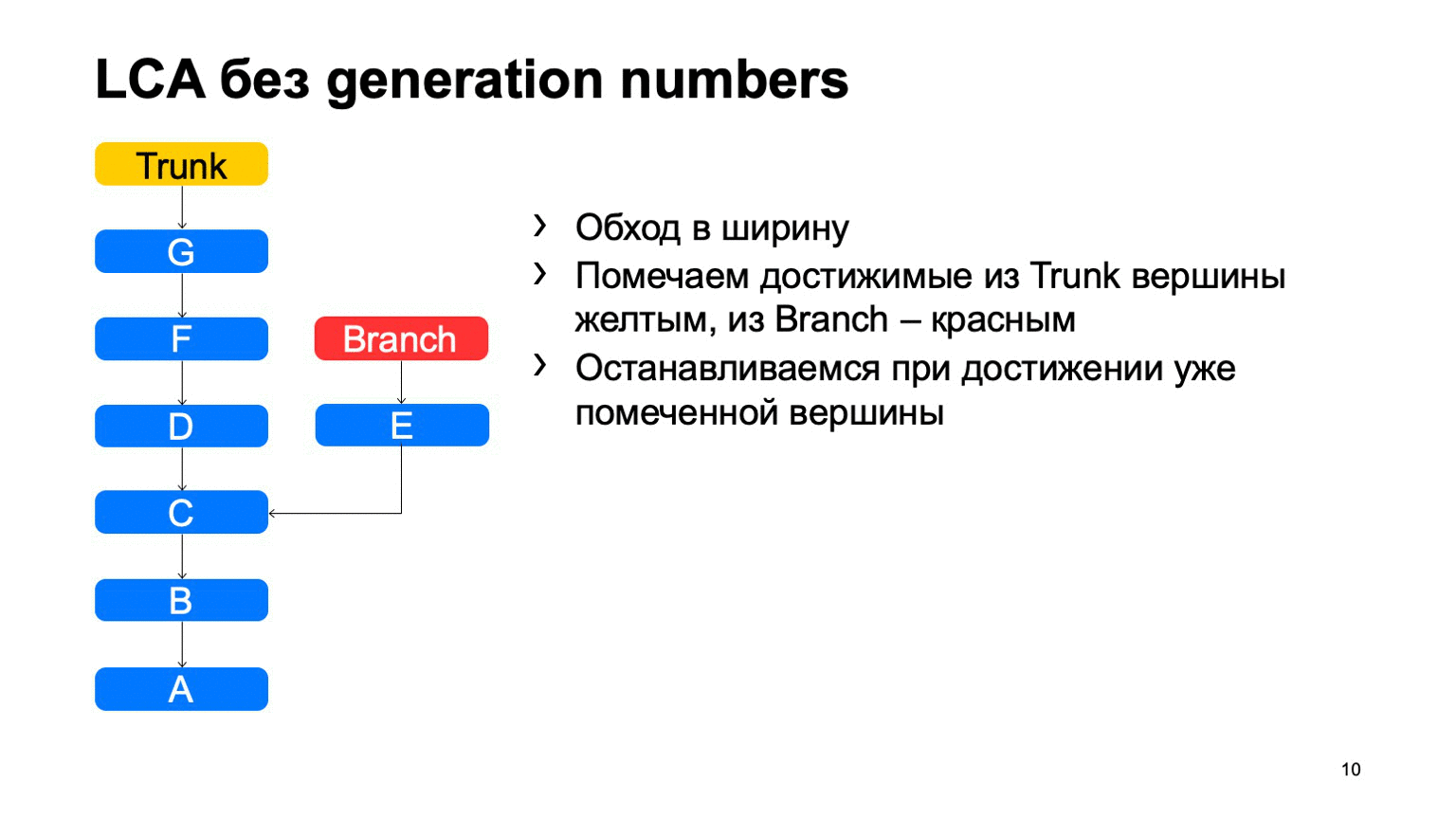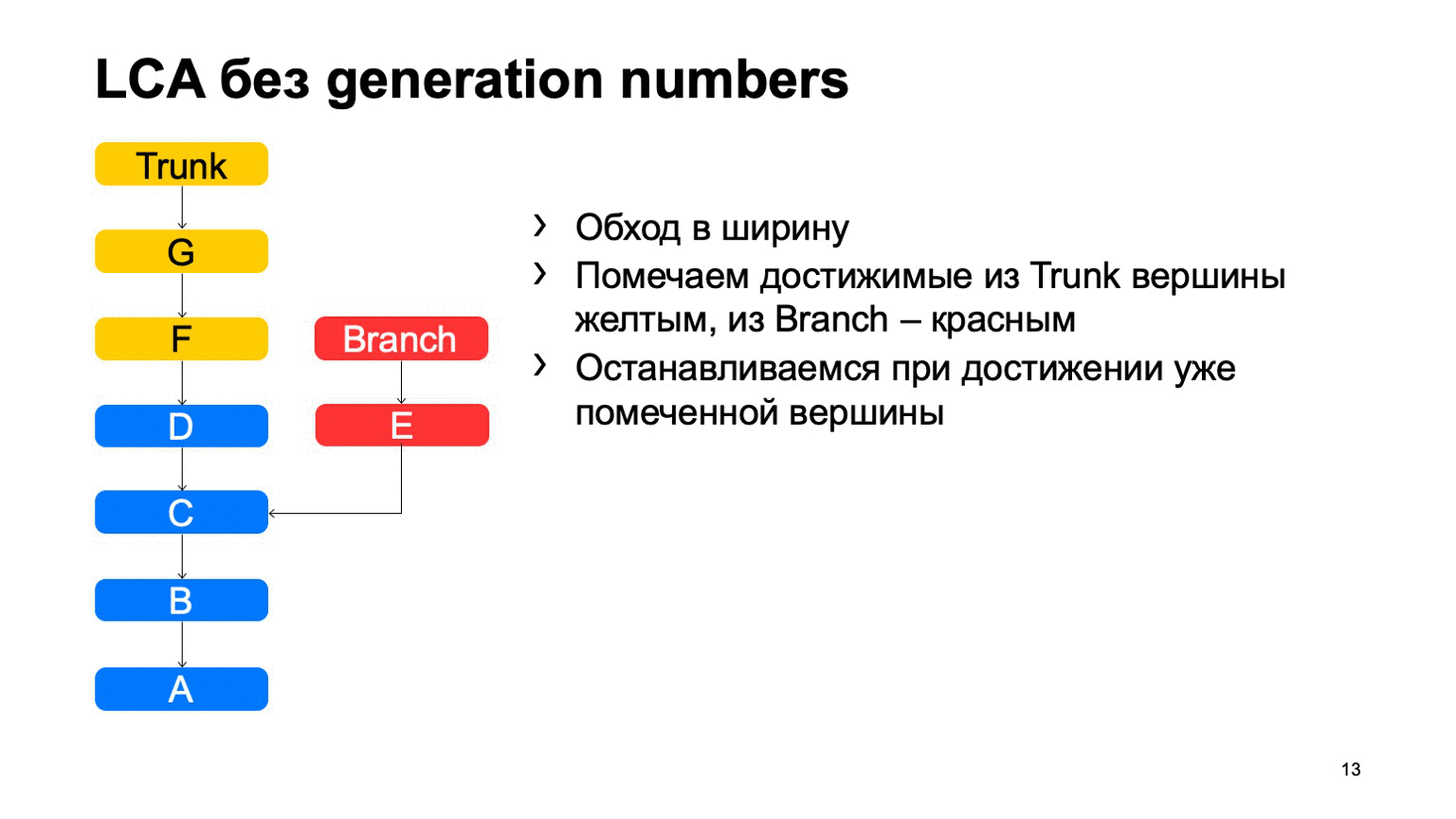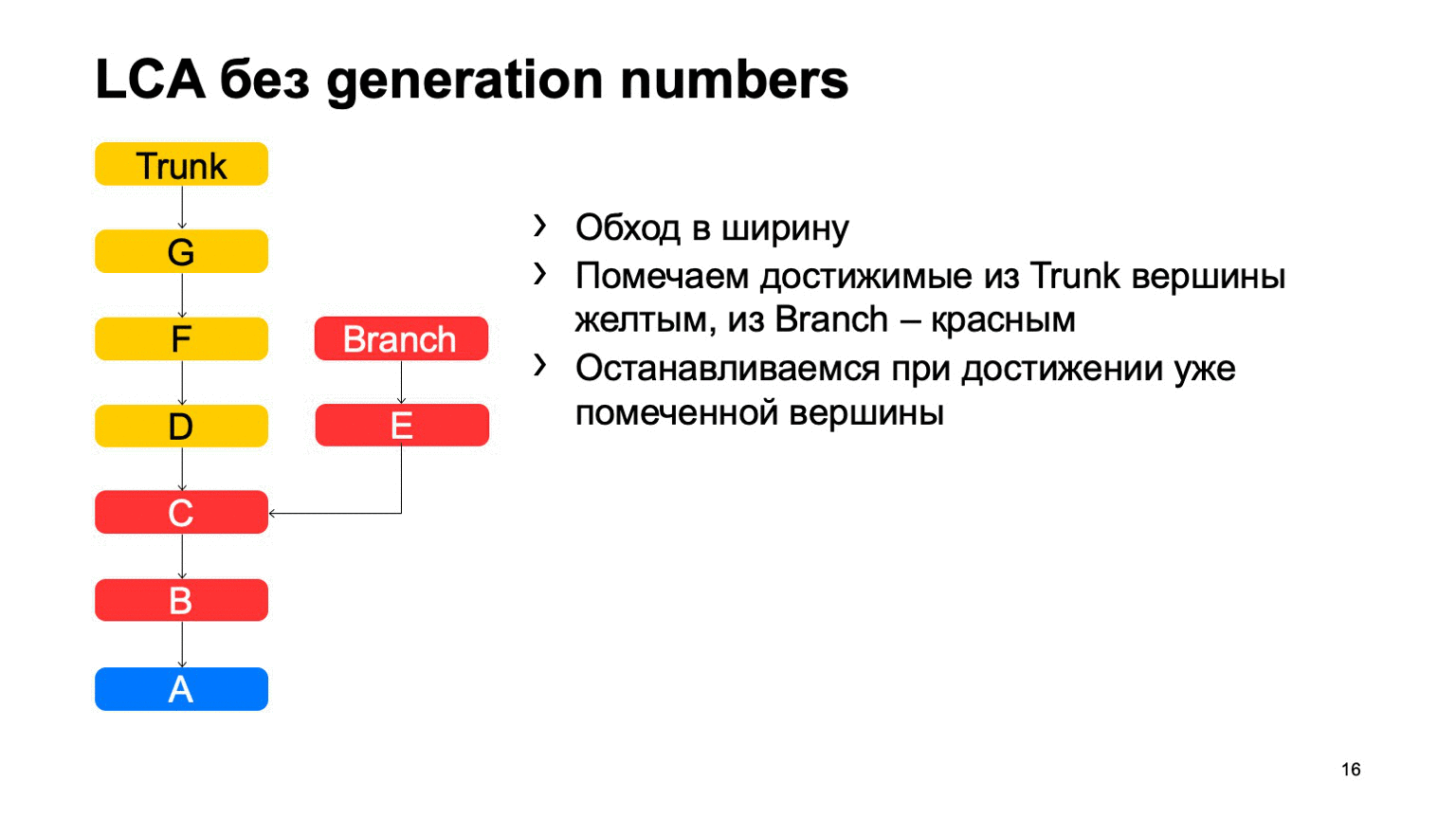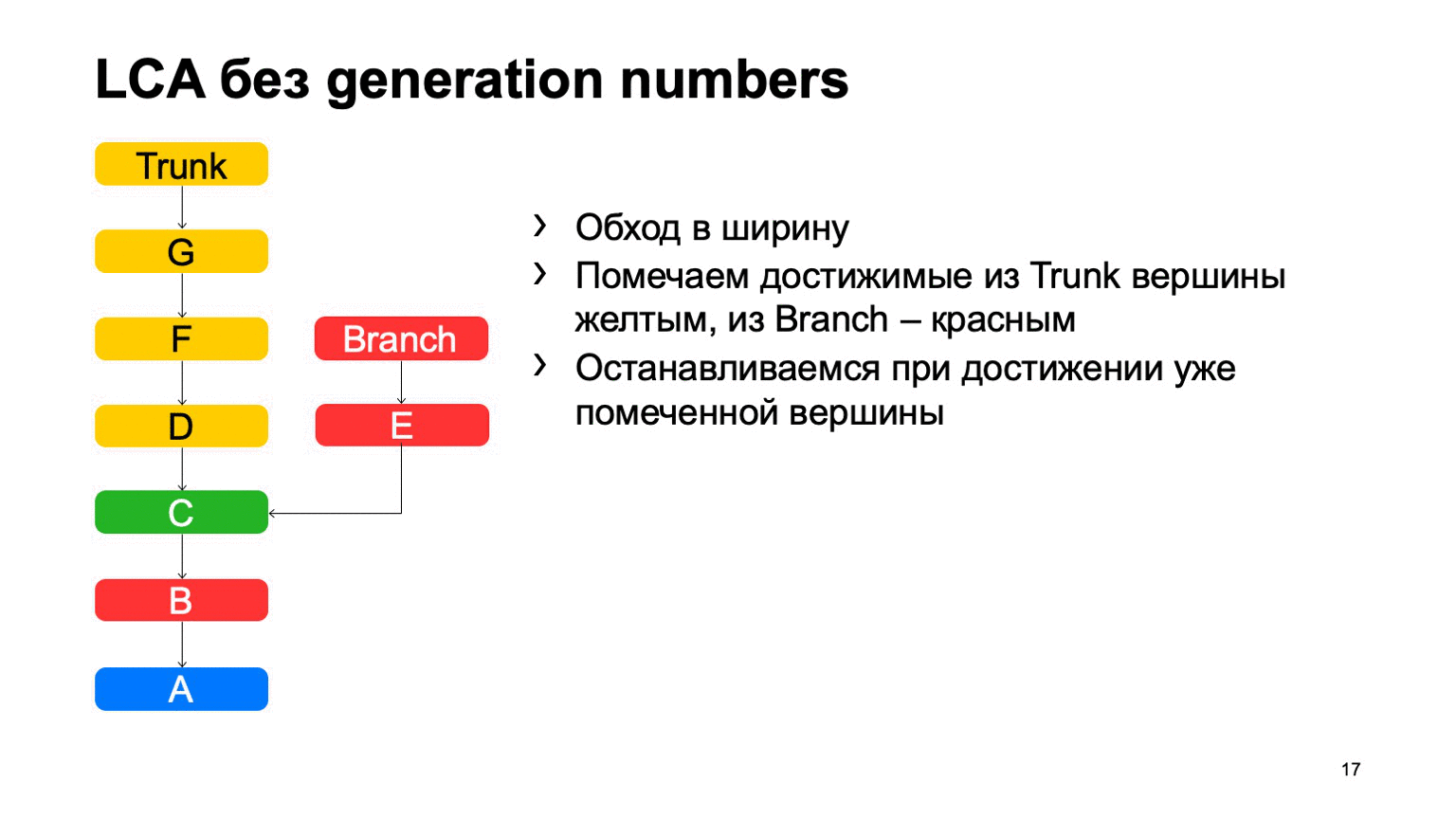
O problema é com B, que é supérfluo. Parece que não conseguimos entrar, mas analisamos. E quanto mais tivermos a diferença entre um ramo e um tronco usando um exemplo, mais confirmações extras encontraremos. No caso de um monorepositório, quando a taxa de consolidação em um tronco é alta o suficiente, essa distância pode ser muito grande. E haverá dezenas de milhares de confirmações extras.


No caso de existirem números de geração, podemos usar a fila de prioridade ao rastrear, e o rastreamento será mais ou menos assim: uma vez - e encontre imediatamente o que você precisa.

Este é um exemplo da diferença entre o nosso modelo. No Git, isso era suportado anteriormente, eles usavam carimbos de data e hora dos números de geração, mas isso só funcionará se os horários para a criação de confirmações forem consistentes com o gráfico de confirmação.
Infelizmente, esse não é o caso do nosso histórico de repositórios. Existem confirmações resultantes da migração de outro repositório e o tempo começa a retroceder nelas. No Git, isso era suportado em algum momento, mas nem sempre é aplicável lá, porque no Git você pode substituir o objeto de confirmação por outro localmente. A imunidade do modelo sofre com isso; portanto, os números de geração que não registram, às vezes não são aplicáveis ao que está escrito neles, isso não é verdade. Não temos esse problema.
Outra vantagem dessa otimização é que ela é completamente local. Para usar esses números, não precisamos ter o gráfico de confirmação inteiro. E geralmente não temos nada, conosco é carregado preguiçosamente. Quanto menos carregarmos preguiçosamente, melhor viveremos.
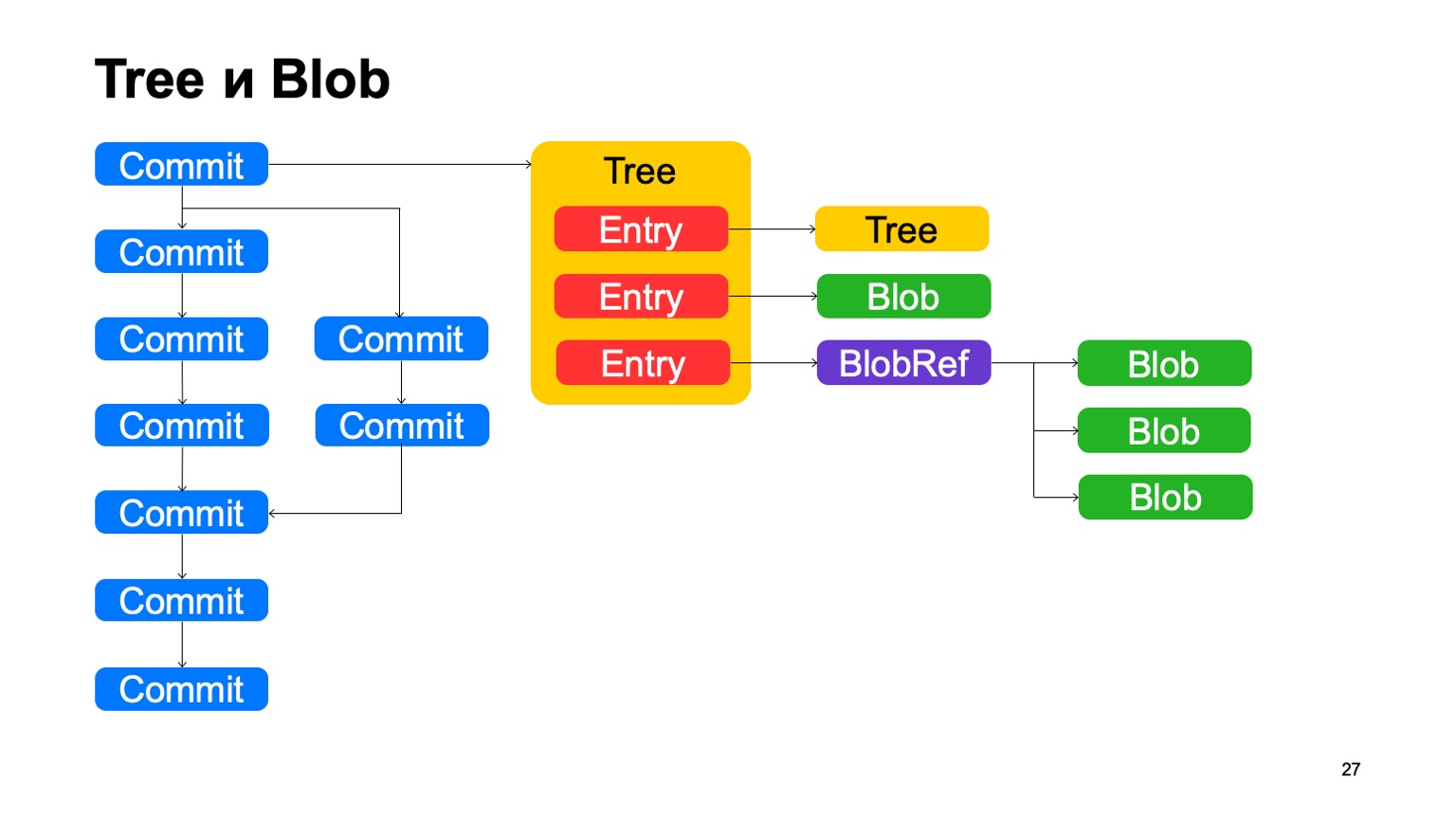
Além de confirmações, o modelo é muito semelhante ao Git. Cada confirmação aponta para um determinado objeto da árvore, a árvore consiste em registros, cada registro é outra árvore e, portanto, a hierarquia de diretórios é exibida aqui, ou é um blob, algum arquivo. Além disso, temos o BlobRef, quando o arquivo é muito grande, dividimos em pedaços e o apresentamos em um objeto especial. Isso é tudo, como no Git.

Do que não gostamos no Git? Chamamos isso de informação de cópia. Se o arquivo foi copiado em algum tipo de confirmação, o Git não salva essas informações de forma alguma e tenta restaurá-las com heurísticas quando mostra diferenças e status. Guardamos essas informações no gráfico. Os registros podem ter algum link de informações de cópia para outro commit, para o caminho dentro do repositório nesse commit, pelo qual sabemos que esse arquivo foi copiado nesse commit.
Também há desduplicação, pois, ao lado, esse blob é armazenado uma vez. Mas a desduplicação seria a mesma, porque o conteúdo do arquivo não foi alterado, pois seria desduplicado por hash.
Como os back-ends são organizados? Se o Git tiver um sistema de controle de versão distribuído, não precisará de back-end. Sentimos isso especialmente quando o GitHub está inoperante. Entendemos claramente que o Git não precisa de back-end. Nosso sistema é cliente-servidor, ele armazena todos os dados no servidor e a disponibilidade do servidor é necessária para fazer o download dos objetos que ainda não estão no cliente.

Todos os dados que armazenamos no banco de dados Yandex. Este é um banco de dados muito legal que fornece a transação, o nível necessário de confiabilidade. Tem tudo o que precisamos, e isso nos salvou de muitos problemas.
Graças a isso, os back-ends em si são completamente sem estado, o estado inteiro está no banco de dados e os back-end que podemos escalar facilmente com a facilidade necessária.
E para a interação que com os clientes, a do interserver, usamos o gRPC, havia um relatório detalhado sobre isso hoje.
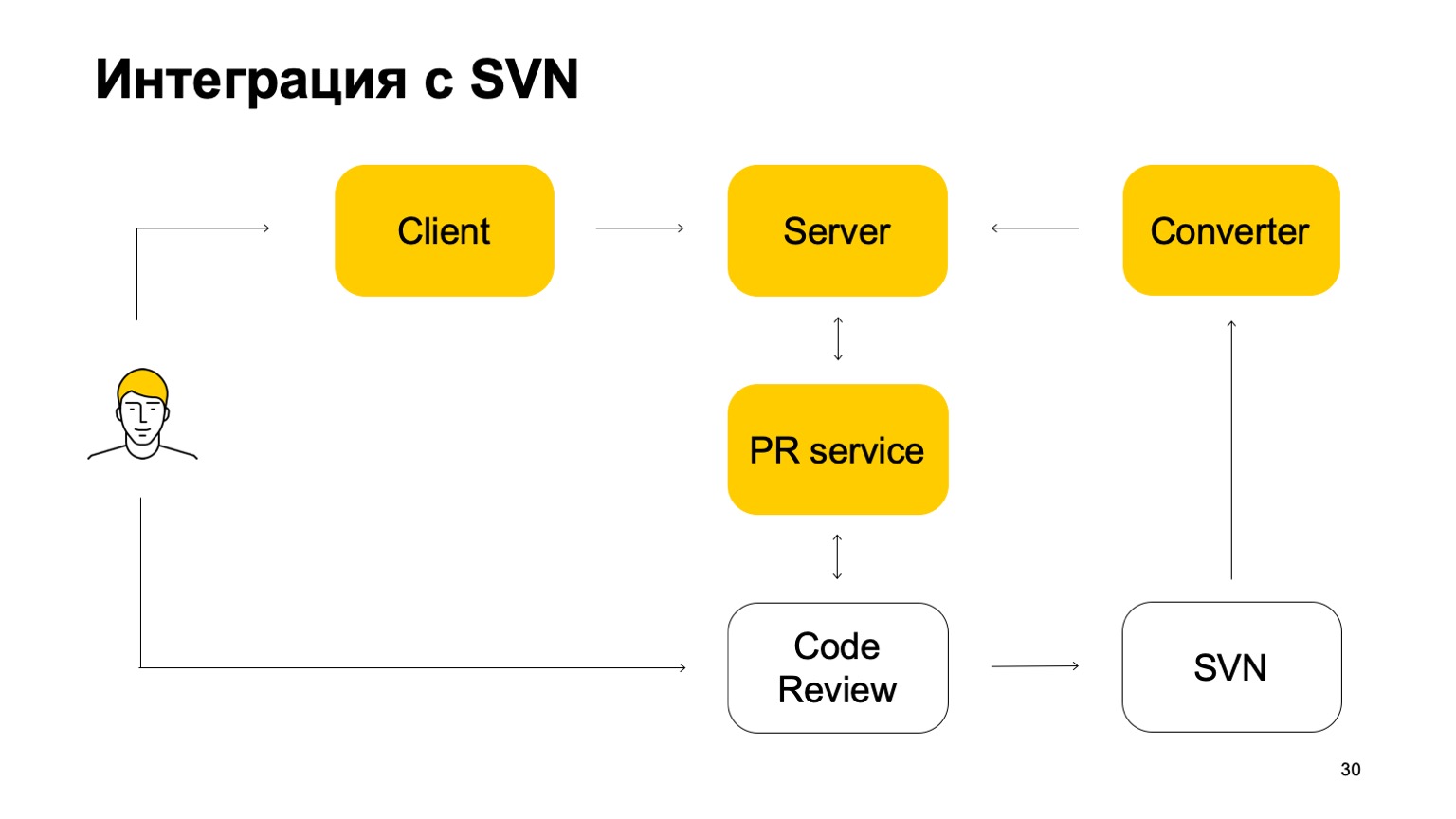
Como nosso sistema é integrado ao SVN? O repositório SVN continua ativo. Além disso, nosso sistema de controle de versão ainda não é auto-suficiente. Como ela trabalha nessa parte? Inicialmente, há algum componente Converter que monitora o status do repositório SVN e transforma as confirmações do SVN em confirmações do Arc - nosso sistema de controle de versão.
Em seguida, há um cliente que monta uma cópia de trabalho e vai ao servidor para obter dados. Quando um desenvolvedor confirma algo, ele é enviado primeiro ao servidor Arc, mas, para que essas alterações cheguem ao tronco, nossa filial principal, eles devem passar pelo sistema de solicitação de pool e pelo sistema de revisão de código. Aí vem outro serviço que monitora as ramificações do Arc e, se forem atualizadas, envia uma solicitação de pool à nossa revisão de código do sistema. A seguir, o sistema de revisão de código, quando for decidido que esse patch precisa ser mesclado, o confirma ao SVN. Não é tão simples: ele adiciona uma certa quantidade de metadados para que esse commit seja realmente uma mescla desse e daquele ramo do Arc. E então essa confirmação já vê o conversor, encontra esses metadados e cria uma confirmação no servidor Arc. Este é o ciclo de confirmações. Portanto, enquanto não podemos viver sem SVN, porque temos tronco no SVN.
O ramo principal é constantemente sincronizado com o nosso servidor, mas não permitimos confirmar diretamente com ele.

Sobre a confiabilidade dos back-ends. Obviamente, planejamos que todos os desenvolvedores do Yandex usem essa coisa, por isso é importante para nós que não quebre. Esse é um padrão intra-índice: nossos serviços devem sobreviver à falha de qualquer data center. O sistema de controle de versão não é exceção. Aqui, somos grandemente salvos pelo fato de o YDB suportar isso. E nossos back-end são sem estado, existem diferentes partes implementadas de maneiras ligeiramente diferentes. Servidores que operam em objetos Arc operam em ramificações, são sem estado, replicados. Conversores que convertem constantemente do SVN são replicados de acordo com o esquema ativo-ativo. Existem vários conversores trabalhando simultaneamente, eles convertem ao mesmo tempo e, no momento em que tentam atualizar a ramificação do Arc, resolvem conflitos. Um conseguiu, o outro falhou. Ele está tentando converter algo mais.
O serviço de solicitação de pool é replicado pelo master-slave. Há uma delas funcionando. Se falhar, um novo é selecionado através do YDB. Há coisas maravilhosas como os semáforos, que têm sérias garantias de acessibilidade e confiabilidade. Os acessos aos semáforos são completamente serializados. Usamos semáforos para o serviço de descoberta de solicitações de pool e para selecionar líderes.
Um pouco sobre como o cliente funciona. Essa é a parte mais difícil do nosso sistema de controle de versão, porque existe um sistema de arquivos virtual. De fato, somos forçados a implementar todas as operações em arquivos por conta própria. Analisarei algumas operações básicas, descreverei aproximadamente nos dedos o que acontece lá dentro quando as fazemos.

Por exemplo, abrimos um arquivo para gravação. Quando abrimos o arquivo para gravação, encontramos o blob correspondente do nosso modelo de objeto. Se necessário, faça o upload de algo do servidor. Se criarmos fisicamente um arquivo em uma loja especial, todas as solicitações adicionais que forem para esse arquivo serão enviadas para proxy. Assim, até que as alterações localizadas sejam confirmadas (no Git é chamado de não-estágio), elas entram no armazenamento temporário. Chamamos esses arquivos de materializados.

Se abrirmos o arquivo para leitura, não poderemos materializar nada, mas simplesmente fornecer dados diretamente do nosso blob.

Aqui é o momento em que adicionamos o arquivo ao índice. Neste ponto, você precisa ver se temos algo materializado. Existe um arquivo que foi alterado. Se estiver, crie um blob para ele e salve-o no índice.

A próxima operação é o status do arco. É interessante porque é o que em sistemas de controle de versão convencionais em tamanhos tão lentos, porque precisa percorrer toda a árvore de arquivos. Não precisamos percorrer toda a árvore de arquivos, porque todos os pedidos de alteração de arquivos passam por nosso driver de fusível e sabemos imediatamente quais arquivos valem a pena verificar se há alterações. Verificamos o que conseguimos escrever no índice e imprimimos a resposta.

Confirme o tempo. Tudo parece estar claro. Existe um índice, já criamos blobs para esses objetos, criamos objetos em árvore que correspondem a esse estado, criamos um novo objeto de confirmação e escrevemos no armazenamento de objetos.

Em seguida, alternamos a cópia de trabalho para o novo commit. Esta é uma operação complicada, que pode ser claramente feita com o comando checkout. E aqui você pode pensar que todas as nossas alterações locais parecem já ter se materializado, podemos assumir que devemos devolver arquivos que não são materializados a partir de novas confirmações. E é isso. Todas as operações subseqüentes são simplesmente enviadas para outra árvore e blobs.

Por que isso pode não funcionar? A primeira versão foi sobre isso. O problema está em todos os tipos de operações complicadas, como redefinição de arco - suave. Eles nos trocam de árvore, mas não materializam arquivos. Eles continuam a existir em algum lugar sagrado. Também temos arquivos não rastreados e ignorados, que também precisam ser processados de uma maneira especial. Nesse local, coletamos muitos ancinhos e, finalmente, chegamos à conclusão de que ainda precisamos pegar uma árvore (agora uma cópia de trabalho) durante o checkout, pegar a árvore do commit para o qual estamos mudando, pegar o índice e aceitá-lo perfeitamente espere.
Mas em termos da complexidade dos algoritmos, não perdemos nada aqui: todas essas árvores de mudanças locais são proporcionais às mudanças que fizemos. Portanto, não devemos percorrer todo o repositório com essas operações, elas ainda funcionam muito rapidamente.
Ao mesmo tempo, estamos fazendo alguma mágica para que os carimbos de data e hora que damos aos arquivos sejam mais ou menos corretos. Se apenas armazenarmos arquivos no sistema de arquivos, ele será monitorado, e o tempo sempre passa. Aqui nós mesmos devemos lembrar de alguma forma que arquivo o usuário viu em que momento. E se ele mudou para um commit anterior, não comece a dar um tempo antes. Como os sistemas de montagem, todos os IDEs não estão prontos para isso, eles tiram muitas coisas.

Em nosso sistema de controle de versão, o suporte ao desenvolvimento baseado em tronco é acertado. Primeiro, o que eu já disse: todas as alterações passam pelas solicitações e tronco da piscina. Há mais alguns pontos. Não temos suporte de ramificação de grupo. As ramificações criadas no Arc são vinculadas a um usuário específico, e somente ele pode confirmar lá. Isso nos permite evitar ramos de vida longa. No SVN, isso não foi particularmente porque é inconveniente fazer ramificações lá. E é conveniente fazê-las no Arc, e se isso não for controlado, temos medo de que algumas partes do nosso mono-repositório deixem suas ramificações e conduzam seu desenvolvimento lá. Isso é contrário ao modelo que queremos fazer.

Em segundo lugar, não temos um comando de mesclagem. Todas as fusões de filiais ocorrem sob nosso rígido controle. Agora estamos desenvolvendo ramificações para lançamentos, nas quais também será possível mesclar. Isso também será realizado não por alguma equipe de usuários, mas por máquinas de servidor, provavelmente.

Quais são os nossos planos? 20% dos desenvolvedores de monorepositórios já usam nosso sistema de controle de versão. - , , . — . - 80% , , . , , Git.
, - , , Arc, SVN .
— , CI . , , . . .
— , CI Arc, - . , . . , ++- , , . .
. « Git». : Git. , , .
. Git . , . - . , checkout reset, . , , . : Git. « , ». Git .
. Git, git begin-wave-stash?
:
— .
— , Git ? — , , , . , . Git . , . .