Geralmente, as tabelas contêm um grande número de campos lógicos, não há como indexar todos eles e a eficácia dessa indexação é baixa. No entanto, para trabalhar com expressões lógicas arbitrárias em SQL, é adequado um mecanismo de indexação multidimensional, que será discutido sob o gato.
No SQL, os campos lógicos são usados principalmente em dois casos. Primeiro, quando você realmente precisa de um atributo binário, por exemplo, 'compra / venda' na tabela de transações. Tais atributos raramente mudam com o tempo.
Em segundo lugar, para registrar o estado da
máquina de estado que descreve o registro. Entende-se que um objeto lógico correspondente a um registro de tabela passa por uma série de estados, cujo número e as transições entre eles são determinados pela lógica aplicada. Um exemplo simples é a técnica de "exclusão reversível", quando um registro não é destruído fisicamente, mas apenas marcado como excluído.
Se a máquina for complexa, pode haver uma quantidade razoável desses campos; em uma de
nossas tabelas, existem 58 (+14 obsoletos) campos (incluindo conjuntos de sinalizadores) e isso não é algo fora do comum. Isso não foi planejado originalmente, mas à medida que o produto se desenvolve e os requisitos externos mudam, as máquinas correspondentes se desenvolvem, os desenvolvedores vão e vêm, os analistas mudam ... em algum momento, pode ser mais seguro obter uma nova flag, em vez de entender todos os meandros. Além disso, dados históricos foram acumulados e suas condições devem permanecer adequadas.
offtopicDe certa forma, isso é semelhante ao processo evolutivo, quando uma massa de informações / mecanismos é armazenada no genoma que, à primeira vista, não é necessária, mas é impossível se livrar deles. Por outro lado, vale a pena tratar esses mecanismos com respeito, porque foram eles que permitiram aos predecessores evolucionários sobreviver (inclusive durante as
grandes extinções ) e vencer a corrida evolutiva. Mais uma vez, quem sabe aonde a evolução nos levará e o que será útil no futuro.
Colocar um sinalizador significa não apenas adicionar um campo do tipo correspondente, mas também levá-lo em consideração na operação do autômato, em quais estados ele afeta e em quais transições ele participa. Na prática, fica assim:
- um processo ou uma série de processos, vamos chamá-los de "escritores", criar novos registros no estado inicial (possivelmente em um dos estados iniciais)
- vários processos, vamos chamá-los de "leitores", de tempos em tempos eles lêem objetos que estão nos estados de que precisam
- Em vários processos, vamos chamá-los de "manipuladores", monitorar estados específicos e, com base na lógica aplicada, alterar esses estados. I.e. operar uma máquina de estado.
Para selecionar registros que estão em um estado específico, é raro quando a filtragem por um dos campos booleanos é suficiente. Geralmente, essa é uma expressão completa, às vezes não trivial. Parece que você precisa indexar esses campos e o processador SQL descobrirá isso. Mas não é tão simples.
Em primeiro lugar, pode haver muitos campos booleanos; indexá-los todos seria um desperdício.
Em segundo lugar, pode revelar-se inútil, pois a seletividade para cada um dos campos será baixa e a probabilidade conjunta não é coberta pelas estatísticas do processador SQL.
Suponha que na tabela T1 existam dois campos booleanos: F1 e F2 e a consulta
select F1, F2, count(1) from T1 group by F1, F2
desiste
I.e. embora, de acordo com F1 e F2, verdadeiro e falso sejam igualmente prováveis, a combinação (verdadeiro, falso) cai apenas uma vez em mil. Como resultado, se indexarmos F1 e F2 separadamente
e forçá-los a serem usados na consulta , o processador SQL terá que ler metade dos dois índices e cruzar os resultados. Pode ser mais barato ler a tabela inteira e calcular a expressão para cada linha.
E mesmo que você colete estatísticas sobre solicitações concluídas, isso não será muito útil. estatísticas especificamente para os campos responsáveis pelo estado da máquina flutuam muito. De fato, a qualquer momento um "manipulador" pode vir e transferir metade das linhas do estado S1 para S2.
Para trabalhar com essas expressões, sugere-se um índice multidimensional, cujo algoritmo foi
apresentado anteriormente e mostrou-se bastante bom.
Mas primeiro você precisa descobrir como uma expressão lógica arbitrária se transformará em uma (s) consulta (s) para o índice.
Forma normal disjuntiva
Uma única consulta para um índice multidimensional é um retângulo multidimensional que limita o espaço da consulta. Se o campo participar da solicitação, uma restrição será definida para ele. Caso contrário, o retângulo nesta coordenada é limitado apenas pela largura dessa coordenada. As coordenadas lógicas têm capacidade para 1.
Uma consulta de pesquisa nesse índice é uma cadeia de & (conjunção), por exemplo, a expressão: v1 & v2 & v3 & (! V4), equivalente a v1: [1,1], v2: [1,1], v3: [1, 1], v4: [0,0]. E todos os outros campos têm um intervalo: [0,1].
Diante disso, nosso olhar imediatamente se volta para o
DNF - uma das formas canônicas de expressões lógicas. Argumenta-se que qualquer expressão pode ser representada como uma disjunção das conjunções literárias. Um literal aqui se refere a um campo lógico ou a sua negação.
Em outras palavras, através de manipulações simples, qualquer expressão lógica pode ser representada como uma disjunção de várias consultas para um índice lógico multidimensional.
Há um MAS. Essa transformação, em alguns casos, pode levar a um aumento exponencial no tamanho da expressão. Por exemplo, a conversão de
leva a uma expressão de 2 ** n termos. Nesses casos, o desenvolvedor do aplicativo deve pensar no significado físico do que está fazendo e, por parte do processador SQL, você sempre pode recusar o uso do índice lógico se o número de conjunções exceder os limites razoáveis.
Algoritmo de indexação multidimensional
Para a indexação multidimensional, são usadas as propriedades de uma curva de numeração auto-semelhante baseada em simplex hiper-cúbico com o lado 2. Como
resultado , duas versões dessas curvas são de importância prática - a curva Z e a curva de Hilbert.
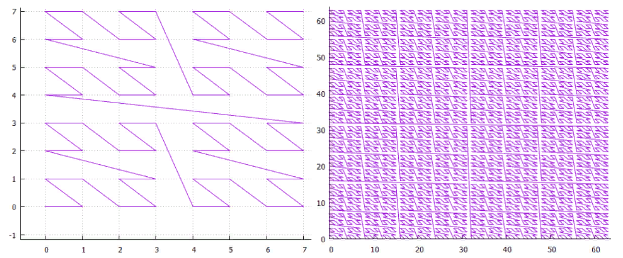 Figura 1 curva Z bidimensional, 3 e 6 iterações
Figura 1 curva Z bidimensional, 3 e 6 iterações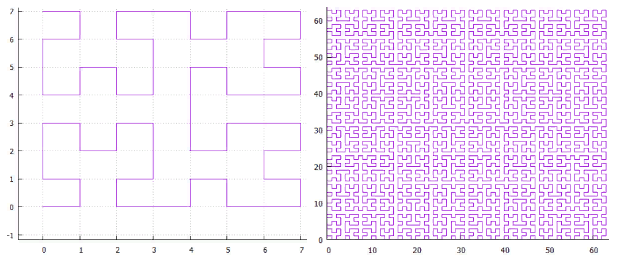 Figura 2 Curva Hilbert bidimensional, 3 e 6 iterações
Figura 2 Curva Hilbert bidimensional, 3 e 6 iterações- Um simplex N-dimensional com o lado 2 tem 2 ** n vértices e (2 ** n-1) transições entre eles.
- Uma iteração elementar de um simplex transforma cada vértice de um simplex em um simplex de nível inferior.
- Depois de fazer o número necessário de iterações, podemos construir uma estrutura hiper-cúbica de qualquer tamanho.
- Além disso, cada nó dessa rede terá seu próprio número único - o caminho percorrido ao longo da curva de numeração desde o início. Além disso, cada nó dessa rede possui um valor em cada uma das coordenadas. De fato, a curva de numeração traduz o ponto multidimensional em um valor unidimensional adequado para indexação com uma árvore B regular .
- Todos os nós localizados dentro de um simplex de qualquer nível estão dentro do mesmo intervalo e esse intervalo não se cruza com nenhum simplex do mesmo nível.
- Portanto, qualquer retângulo de pesquisa (caixa) pode ser dividido em um pequeno número de subconsultas hiper-cúbicas, em cada uma das quais o índice pode ser lido por uma pesquisa / deslocamento.
- Para isso, adicionamos a mágica do trabalho de baixo nível com a árvore B para não fazer solicitações inúteis e ... o algoritmo está pronto.
Veja como funciona na prática:
 Figura 3 Exemplo de pesquisa no índice bidimensional (curva Z)
Figura 3 Exemplo de pesquisa no índice bidimensional (curva Z)A Figura 3 mostra o particionamento da extensão de pesquisa original em subconsultas e os pontos encontrados. Foi utilizado um índice bidimensional, construído em um conjunto aleatório e uniformemente distribuído de 100.000.000 pontos de extensão [1.000.000, 1.000.000].
Índice multidimensional lógico
Como estamos falando de indexação multidimensional, é hora de pensar em quanto pode ser multidimensional? Existem limitações objetivas?
Obviamente, como a árvore B possui uma organização da página e, para ser uma árvore, pelo menos dois elementos devem ser garantidos para caber na página. Se você escolher a página por 8K, o armazenamento de um item não poderá ultrapassar 4K. Em 4K, sem compactação, são adequados cerca de 1000 valores de 32 bits. Isso é bastante, além dos limites de qualquer aplicação razoável, podemos dizer que os limites físicos praticamente não estão disponíveis.
Há um outro lado, cada dimensão adicional não é de forma alguma livre, ocupa espaço em disco e torna o trabalho mais lento. Do ponto de vista do "significado físico", os campos que mudam ao mesmo tempo devem ser incluídos no mesmo índice e a busca por eles também caminha junto. Não faz sentido indexar tudo em uma linha.
Os campos lógicos são diferentes. Como vimos, dezenas de campos lógicos podem estar envolvidos nos mesmos mecanismos. E os custos de armazenamento / leitura são bastante pequenos. Há uma tentação de coletar todos os campos lógicos em um índice e ver o que acontece.
É verdade que existem nuances:
- Até agora, no valor indexado, os dígitos das diferentes coordenadas eram misturados, nos dígitos menos significativos da chave havia os bits menos significativos das coordenadas ... Portanto, a ordem dos campos durante a indexação não importava.
- Agora, um bit é gasto no armazenamento do valor de um campo lógico. I.e. alguns campos lógicos vão para o final da chave e outros para o começo. Isso significa que a filtragem por parte dos campos será muito eficaz e, para alguns, será muito ineficiente. De fato, se fizermos uma pesquisa na ordem mais baixa, teremos que ler o índice inteiro para obter uma resposta. Mas isso (provavelmente) é melhor do que ler a tabela inteira para responder à mesma pergunta.
- Há um problema de escolha - todos os campos lógicos são iguais, mas alguns serão mais iguais que outros. De considerações gerais, é necessário observar as distorções das estatísticas, quanto mais forte a razão verdadeiro / falso para um campo específico estiver distante do equilíbrio, mais antiga será a descarga em que seu valor será.
- O particionamento pelo tipo da curva de numeração desaparece; se antes era necessário escolher entre a curva Z e a curva de Hilbert, não há diferença prática nos dados de bit único.
- NULLs. Com base no fato de NULL não ser um valor desconhecido, mas na ausência de qualquer valor, esses registros não devem ser incluídos no índice. Nos índices unidimensionais, é isso que acontece. Mas, no nosso caso, pode acontecer que alguns dos campos lógicos contenham valores, e outros não. Como resultado, não podemos colocar isso no índice, pois o algoritmo de pesquisa não sabe como trabalhar com lógica ternária. E, portanto, esses registros devem ser impossíveis de serem inseridos na tabela (se houver um índice multidimensional, não necessariamente lógico).
Espera-se que um índice multidimensional lógico possa, em alguns casos, não funcionar com muita eficiência. A rigor, qualquer índice pode funcionar ineficientemente se houver muitos dados na área de pesquisa. Mas, para um índice lógico multidimensional, isso é composto pela dependência da ordem dos campos descrita acima, quando, por causa de um pequeno resultado, é necessário ler o índice inteiro. Na medida em que isso é um problema na prática, apenas o experimento pode mostrar.
Experiência numérica
Construindo um índice:
- o índice será de 128 bits, ou seja, construído em 128 campos lógicos
- e conterá 2 ** 30 elementos
- o valor do elemento de índice será um número de 0 a 2 ** 30
- a chave do elemento de índice será o mesmo número deslocado 48 bits para a esquerda, ou seja, os campos lógicos 48 a 78 serão preenchidos com os dígitos do número na mesma ordem
- como resultado, obtemos 30 campos lógicos significativos no meio da chave, os bits restantes serão preenchidos 0
- Cada um dos campos booleanos possui estatísticas iguais verdadeiras / falsas
- Todos são estatisticamente independentes.
Pesquisa:
- Cada experimento corresponde à seleção de vários campos lógicos consecutivos e à atribuição de valores de pesquisa para eles. Não porque o algoritmo possa pesquisar apenas em faixas, mas porque é possível visualizar os resultados do experimento com mais clareza, temos apenas duas dimensões - a largura da faixa e sua posição
- Um total de 24 séries de experimentos. Em cada série, procuraremos valores em que a faixa de campos lógicos da largura correspondente N (de 1 a 24 bits) leva o valor verdadeiro.
- Em cada série, haverá uma sub-série de experimentos em que uma faixa de campos lógicos de uma largura selecionada está localizada com diferentes turnos S desde o início da faixa em 30 campos lógicos significativos. Total de experimentos (30-N) nas sub-séries.
- Em cada experimento, é feita uma pesquisa por todos os elementos do índice que satisfazem a condição, ou seja, campos com números no intervalo [48 + S, 48 + S + N -1] serão pesquisados no intervalo [1,1], o restante no intervalo [0,1]
- A pesquisa é feita desde o início a frio
- O resultado é o número de páginas de disco lidas, incluindo o cache (cache de 4096 páginas)
- O controle da operação correta é feito de duas maneiras - o número de elementos encontrados deve ser igual a 2 ** (30-N) e nos valores encontrados, você pode verificar os dígitos correspondentes
Então
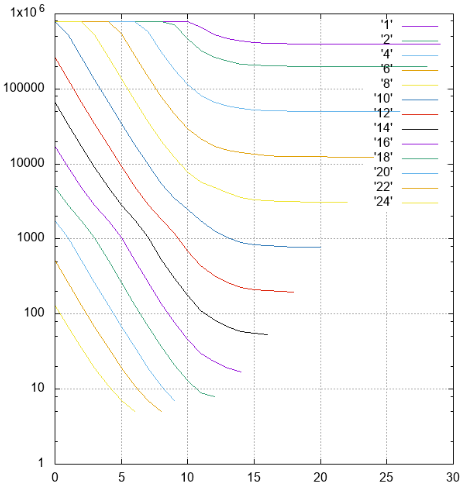 Figura 4 Resultados, o número de páginas lidas em diferentes séries
Figura 4 Resultados, o número de páginas lidas em diferentes sériesPor Y - o número de páginas lidas é adiado.
Em X - turno de tiras da categoria mais jovem (48) para a mais velha. Listras de larguras diferentes são assinadas e marcadas em cores diferentes.
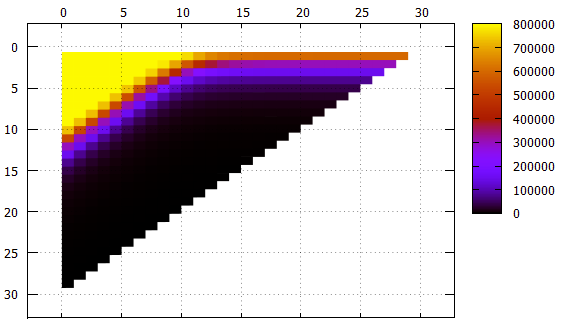 Figura 5 Os mesmos dados da Figura 4, outra visualização
Figura 5 Os mesmos dados da Figura 4, outra visualizaçãoMudança de banda X
Y - largura de banda
O que deve ser observado:
- embora isso não seja diretamente visível nas imagens, o índice funciona corretamente, mas é visível no número de elementos encontrados e no conteúdo dos elementos
- todas as faixas com largura não superior a 10 e com desvio de 0 requerem leitura contínua do índice
- listras com uma largura de 1 a 18 com um aumento no deslocamento atingem a assíntota 2 ** (- N) do tamanho de todo o índice, o que é lógico
- para bandas mais largas da assíntota - a altura da árvore, não pode haver menos leituras
- um pouco mais de 1000 elementos são colocados na página da folha de índice, isso pode ser visto em uma faixa de largura 10, que quando o deslocamento 0 não exige mais a leitura de todo o índice, algumas páginas podem ser ignoradas
- a filtragem de baixo nível funciona surpreendentemente bem. Considere uma faixa com uma largura de 10. Uma opção ideal de pesquisa é com um turno de 20 (um total de 30 campos significativos), quando não há campos indefinidos no prefixo, os dados podem ser encontrados com um único feixe. Nessa situação, aproximadamente 1/1000 do índice é lido durante a pesquisa - 779 páginas.
O caso intermediário é um turno de 10, temos um prefixo e um sufixo de 10 campos desconhecidos. O número de páginas é 2484, apenas três vezes pior do que no caso ideal.
E mesmo no pior dos casos, com um deslocamento de 0 (um prefixo de 20 campos desconhecidos), você pode pular algumas páginas.
No geral, o algoritmo de indexação multidimensional pode ser reconhecido como eficiente, mesmo em um caso tão absurdo.
Mas a opção mais malsucedida do ponto de vista do índice lógico é considerada - estados equiprobáveis em todos os campos lógicos independentes.Experimente dados reais
Tabela de
negociações , total de 278.479.918 linhas, dados de um dos loops de teste.
Os resultados de algumas consultas na tabela abaixo:
A leitura / processamento de uma única página leva em média 0,8 ms.
Não há necessidade de descrever o significado de consultas específicas, elas estão aqui apenas para demonstrar operacionalidade. O que, a propósito, está confirmado.
Mas antes que essa técnica possa ser útil, muito resta a ser feito. Então, para continuar.