 Só dói pela primeira vez!
Só dói pela primeira vez!Olá pessoal! Caros amigos, neste artigo, quero compartilhar minha experiência usando o TensorRT, RetinaNet com base no repositório
github.com/aidonchuk/retinanet-examples (este é um garfo da chave na mão oficial da
nvidia , que nos permitirá começar a usar modelos otimizados na produção o mais rápido possível).
Percorrendo os canais da comunidade
ods.ai , me deparo com perguntas sobre o uso do TensorRT, e a maioria das perguntas é repetida, por isso decidi escrever
um guia o
mais abrangente possível para usar a inferência rápida baseada no TensorRT, RetinaNet, Unet e janela de encaixe.
Descrição da tarefaProponho definir a tarefa da seguinte maneira: precisamos marcar o conjunto de dados, treinar a rede RetinaNet / Unet no Pytorch1.3 +, converter os pesos recebidos no ONNX, depois convertê-los no mecanismo TensorRT e executar tudo isso no docker, de preferência no Ubuntu 18 e extremamente de preferência na arquitetura ARM (Jetson) *, minimizando a implantação manual do ambiente. Como resultado, prepararemos um contêiner não apenas para exportação e treinamento do RetinaNet / Unet, mas também para o desenvolvimento e treinamento completos de classificação e segmentação com todas as ligações necessárias.
Etapa 1. Preparação do meio ambienteÉ importante notar aqui que recentemente eu abandonei completamente o uso e a implantação de pelo menos algumas bibliotecas na máquina da área de trabalho, bem como no devbox. A única coisa que você precisa criar e instalar é o ambiente virtual python e o cuda 10.2 (você pode restringir-se a um único driver nvidia) do deb.
Suponha que você tenha um Ubuntu 18. recém-instalado. Instale o cuda 10.2 (deb), não vou me deter no processo de instalação em detalhes; a documentação oficial é suficiente.
Agora vamos instalar o docker, o guia de instalação do docker pode ser encontrado com facilidade. Aqui está um exemplo
www.digitalocean.com/community/tutorials/docker-ubuntu-18-04-1-en , a versão 19+ já está disponível - coloque-o. Bem, não se esqueça de possibilitar o uso do docker sem o sudo, pois será mais conveniente. Depois que tudo acabou, fizemos o seguinte:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.imtqy.com/nvidia-docker/gpgkey | sudo apt-key add - curl -s -L https://nvidia.imtqy.com/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit sudo systemctl restart docker
E você nem precisa procurar no repositório oficial
github.com/NVIDIA/nvidia-docker .
Agora, faça o git clone
github.com/aidonchuk/retinanet-examples .
Resta apenas um pouco. Para começar a usar o docker com nvidia-image, precisamos nos registrar no NGC Cloud e fazer login. Vamos aqui para
ngc.nvidia.com , registramos e depois de entrar na NGC Cloud, pressione SETUP no canto superior esquerdo da tela ou siga este link
ngc.nvidia.com/setup/api-key . Clique em "gerar chave". Eu recomendo salvá-lo, caso contrário, na próxima vez que você o visitar, precisará regenerá-lo e, consequentemente, implantá-lo em um novo carrinho de mão, repita esta operação.
Execute:
docker login nvcr.io Username: $oauthtoken Password: <Your Key> -
Nome de usuário apenas copie. Bem, considere, o ambiente está implantado!
Etapa 2. Montagem do contêiner do dockerNa segunda etapa de nosso trabalho, montaremos o docker e nos familiarizaremos com o interior.
Vamos para a pasta raiz relativa ao projeto retina-examples e execute
docker build --build-arg USER=$USER --build-arg UID=$UID --build-arg GID=$GID --build-arg PW=alex -t retinanet:latest retinanet/
Coletamos o docker jogando o usuário atual nele - isso é muito útil se você escrever algo em um VOLUME montado com os direitos do usuário atual, caso contrário, haverá raiz e problemas.
Enquanto o docker estiver em andamento, vamos explorar o Dockerfile:
FROM nvcr.io/nvidia/pytorch:19.10-py3 ARG USER=alex ARG UID=1000 ARG GID=1000 ARG PW=alex RUN useradd -m ${USER} --uid=${UID} && echo "${USER}:${PW}" | chpasswd RUN apt-get -y update && apt-get -y upgrade && apt-get -y install curl && apt-get -y install wget && apt-get -y install git && apt-get -y install automake && apt-get install -y sudo && adduser ${USER} sudo RUN pip install git+https://github.com/bonlime/pytorch-tools.git@master COPY . retinanet/ RUN pip install --no-cache-dir -e retinanet/ RUN pip install /workspace/retinanet/extras/tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl RUN pip install tensorboardx RUN pip install albumentations RUN pip install setproctitle RUN pip install paramiko RUN pip install flask RUN pip install mem_top RUN pip install arrow RUN pip install pycuda RUN pip install torchvision RUN pip install pretrainedmodels RUN pip install efficientnet-pytorch RUN pip install git+https://github.com/qubvel/segmentation_models.pytorch RUN pip install pytorch_toolbelt RUN chown -R ${USER}:${USER} retinanet/ RUN cd /workspace/retinanet/extras/cppapi && mkdir build && cd build && cmake -DCMAKE_CUDA_FLAGS="--expt-extended-lambda -std=c++14" .. && make && cd /workspace RUN apt-get install -y openssh-server && apt install -y tmux && apt-get -y install bison flex && apt-cache search pcre && apt-get -y install net-tools && apt-get -y install nmap RUN apt-get -y install libpcre3 libpcre3-dev && apt-get -y install iputils-ping RUN mkdir /var/run/sshd RUN echo 'root:pass' | chpasswd RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config RUN sed 's@session\s*required\s*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd ENV NOTVISIBLE "in users profile" RUN echo "export VISIBLE=now" >> /etc/profile CMD ["/usr/sbin/sshd", "-D"]
Como você pode ver no texto, pegamos todos os nossos favoritos, compilamos a retinanet, distribuímos ferramentas básicas para a conveniência de trabalhar com o Ubuntu e configuramos o servidor openssh. A primeira linha é apenas a herança da imagem nvidia, para a qual fizemos um login no NGC Cloud e que contém Pytorch1.3, TensorRT6.xxx e várias bibliotecas que nos permitem compilar o código-fonte cpp para o nosso detector.
Etapa 3. Iniciando e Depurando o Contêiner do DockerVamos para o caso principal de usar o contêiner e o ambiente de desenvolvimento, para iniciar, executar o nvidia docker. Execute:
docker run --gpus all --net=host -v /home/<your_user_name>:/workspace/mounted_vol -d -P --rm --ipc=host -it retinanet:latest
Agora o contêiner está disponível em ssh <curr_user_name> @localhost. Após um lançamento bem-sucedido, abra o projeto no PyCharm. Em seguida, abra
Settings->Project Interpreter->Add->Ssh Interpreter
Etapa 1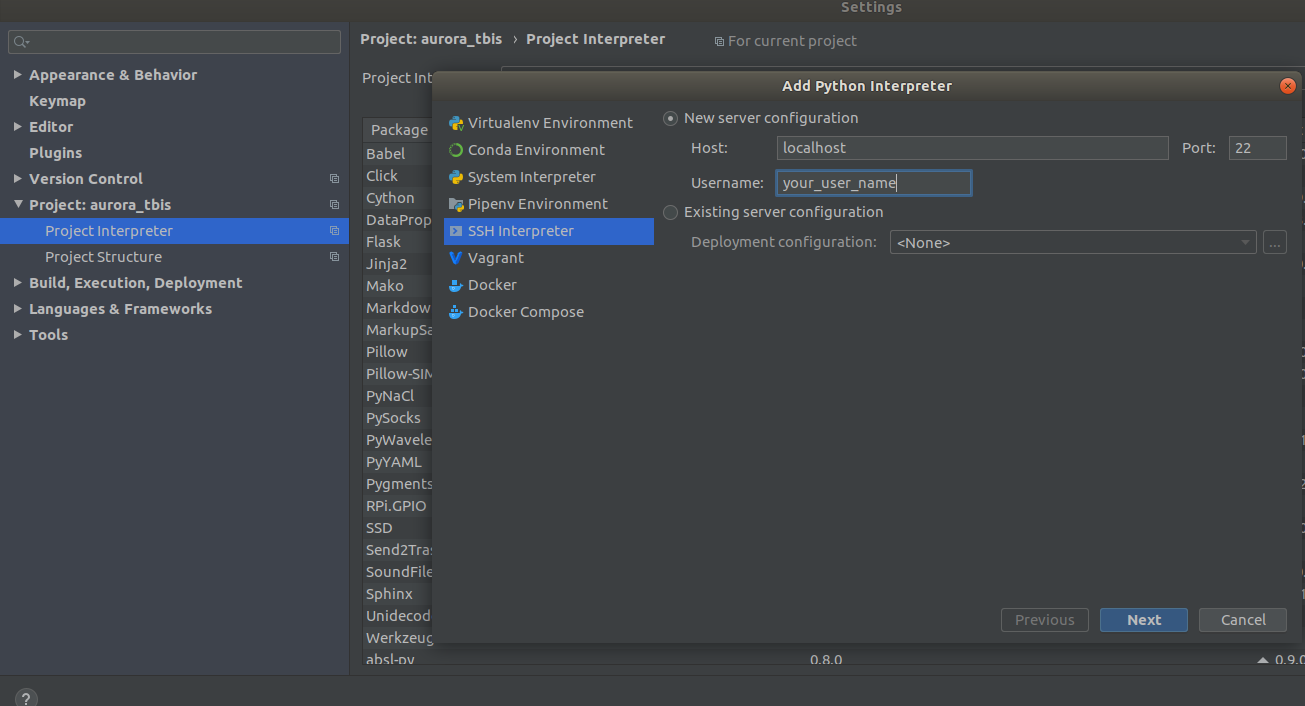 Etapa 2
Etapa 2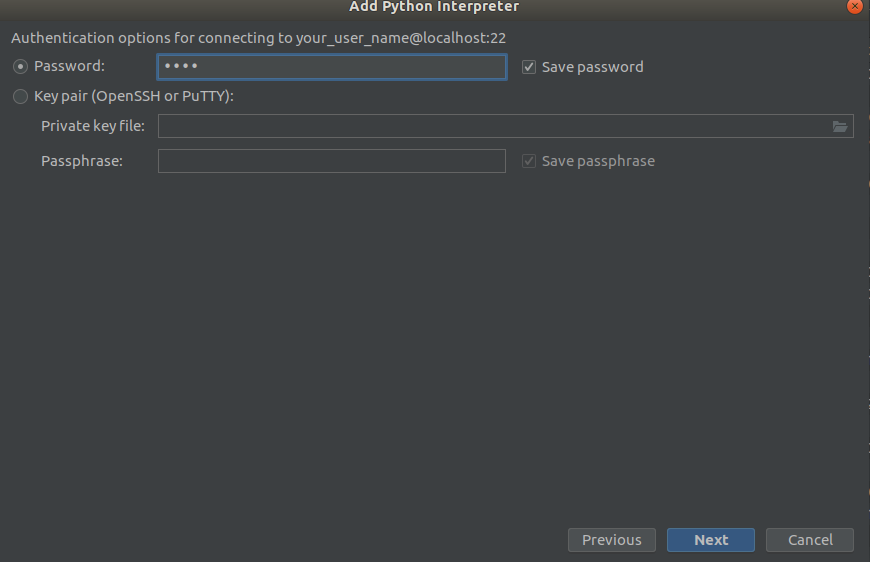 Etapa 3
Etapa 3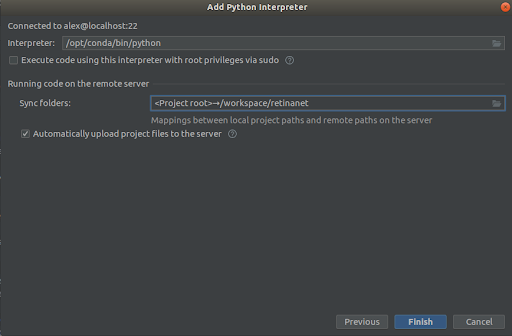
Selecionamos tudo como nas capturas de tela,
Interpreter -> /opt/conda/bin/python
- isso será em Python3.6 e
Sync folder -> /workspace/retinanet
Pressionamos a linha de chegada, esperamos a indexação, e é isso, o ambiente está pronto para uso!
IMPORTANTE !!! Imediatamente após a indexação, extraia os arquivos compilados do Retinanet da janela de encaixe. No menu de contexto na raiz do projeto, selecione
Deployment->Download
Um arquivo e duas pastas de construção, retinanet.egg-info e _so, aparecerão
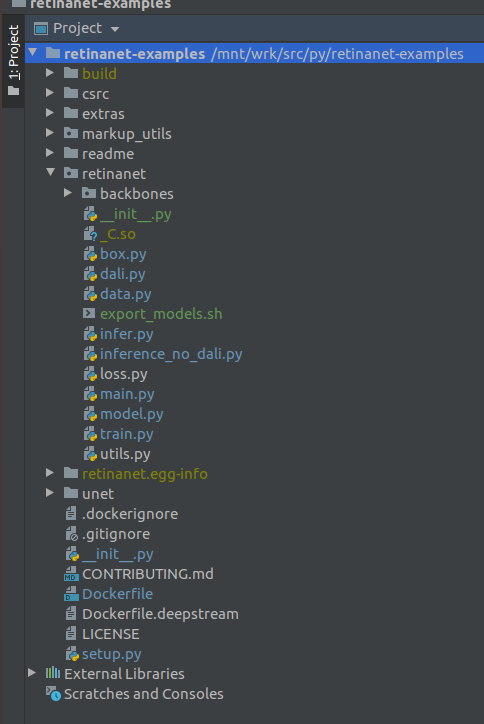
Se o seu projeto se parecer com isso, o ambiente verá todos os arquivos necessários e estamos prontos para aprender o RetinaNet.
Etapa 4. Marcando os dados e treinando o detectorPara marcação, eu uso principalmente o
supervise.ly - uma ferramenta agradável e conveniente, na última vez em que um monte de batentes foi corrigido e ele se tornou muito melhor.
Suponha que você tenha marcado o conjunto de dados e baixado, mas não funcionará imediatamente para colocá-lo em nosso RetinaNet, pois ele está em seu próprio formato e, para isso, precisamos convertê-lo em COCO. A ferramenta de conversão está em:
markup_utils/supervisly_to_coco.py
Observe que a categoria no script é um exemplo e você precisa inserir o seu próprio (não é necessário adicionar a categoria de plano de fundo)
categories = [{'id': 1, 'name': '1'}, {'id': 2, 'name': '2'}, {'id': 3, 'name': '3'}, {'id': 4, 'name': '4'}]
Por alguma razão, os autores do repositório original decidiram que você não treinaria nada, exceto COCO / VOC para detecção, então tive que modificar levemente o arquivo de origem
retinanet/dataset.py
Adicione suas albumentations.readthedocs.io/en/latest aumentos mais recentes favoritas e recorte as categorias costuradas do COCO. Também é possível espalhar grandes áreas de detecção se você estiver procurando objetos pequenos em imagens grandes, tiver um pequeno conjunto de dados =) e nada funcionar, mas mais sobre isso outra vez.
Em geral, o loop do trem também é fraco, inicialmente não salvou pontos de verificação, usou algum agendador terrível, etc. Mas agora tudo o que você precisa fazer é selecionar o backbone e executar
/opt/conda/bin/python retinanet/main.py
com parâmetros:
train retinanet_rn34fpn.pth --backbone ResNet34FPN --classes 12 --val-iters 10 --images /workspace/mounted_vol/dataset/train/images --annotations /workspace/mounted_vol/dataset/train_12_class.json --val-images /workspace/mounted_vol/dataset/test/images_small --val-annotations /workspace/mounted_vol/dataset/val_10_class_cropped.json --jitter 256 512 --max-size 512 --batch 32
No console, você verá:
Initializing model... model: RetinaNet backbone: ResNet18FPN classes: 2, anchors: 9 Selected optimization level O0: Pure FP32 training. Defaults for this optimization level are: enabled : True opt_level : O0 cast_model_type : torch.float32 patch_torch_functions : False keep_batchnorm_fp32 : None master_weights : False loss_scale : 1.0 Processing user overrides (additional kwargs that are not None)... After processing overrides, optimization options are: enabled : True opt_level : O0 cast_model_type : torch.float32 patch_torch_functions : False keep_batchnorm_fp32 : None master_weights : False loss_scale : 128.0 Preparing dataset... loader: pytorch resize: [1024, 1280], max: 1280 device: 4 gpus batch: 4, precision: mixed Training model for 20000 iterations... [ 1/20000] focal loss: 0.95619, box loss: 0.51584, 4.042s/4-batch (fw: 0.698s, bw: 0.459s), 1.0 im/s, lr: 0.0001 [ 12/20000] focal loss: 0.76191, box loss: 0.31794, 0.187s/4-batch (fw: 0.055s, bw: 0.133s), 21.4 im/s, lr: 0.0001 [ 24/20000] focal loss: 0.65036, box loss: 0.30269, 0.173s/4-batch (fw: 0.045s, bw: 0.128s), 23.1 im/s, lr: 0.0001 [ 36/20000] focal loss: 0.46425, box loss: 0.23141, 0.178s/4-batch (fw: 0.047s, bw: 0.131s), 22.4 im/s, lr: 0.0001 [ 48/20000] focal loss: 0.45115, box loss: 0.23505, 0.180s/4-batch (fw: 0.047s, bw: 0.133s), 22.2 im/s, lr: 0.0001 [ 59/20000] focal loss: 0.38958, box loss: 0.25373, 0.184s/4-batch (fw: 0.049s, bw: 0.134s), 21.8 im/s, lr: 0.0001 [ 71/20000] focal loss: 0.37733, box loss: 0.23988, 0.174s/4-batch (fw: 0.049s, bw: 0.125s), 22.9 im/s, lr: 0.0001 [ 83/20000] focal loss: 0.39514, box loss: 0.23878, 0.181s/4-batch (fw: 0.048s, bw: 0.133s), 22.1 im/s, lr: 0.0001 [ 94/20000] focal loss: 0.39947, box loss: 0.23817, 0.185s/4-batch (fw: 0.050s, bw: 0.134s), 21.6 im/s, lr: 0.0001 [ 105/20000] focal loss: 0.37343, box loss: 0.20238, 0.182s/4-batch (fw: 0.048s, bw: 0.134s), 22.0 im/s, lr: 0.0001 [ 116/20000] focal loss: 0.19689, box loss: 0.17371, 0.183s/4-batch (fw: 0.050s, bw: 0.132s), 21.8 im/s, lr: 0.0001 [ 128/20000] focal loss: 0.20368, box loss: 0.16538, 0.178s/4-batch (fw: 0.046s, bw: 0.131s), 22.5 im/s, lr: 0.0001 [ 140/20000] focal loss: 0.22763, box loss: 0.15772, 0.176s/4-batch (fw: 0.050s, bw: 0.126s), 22.7 im/s, lr: 0.0001 [ 148/20000] focal loss: 0.21997, box loss: 0.18400, 0.585s/4-batch (fw: 0.047s, bw: 0.144s), 6.8 im/s, lr: 0.0001 Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.52674 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.91450 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.35172 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61881 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.58824 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000 Saving model: 148
Para estudar todo o conjunto de parâmetros, consulte
retinanet/main.py
Em geral, eles são padrão para detecção e têm uma descrição. Execute o treinamento e aguarde os resultados. Um exemplo de inferência pode ser encontrado em:
retinanet/infer_example.py
ou execute o comando:
/opt/conda/bin/python retinanet/main.py infer retinanet_rn34fpn.pth --images /workspace/mounted_vol/dataset/test/images --annotations /workspace/mounted_vol/dataset/val.json --output result.json --resize 256 --max-size 512 --batch 32
A perda focal e vários backbones já estão embutidos no repositório e seus
retinanet/backbones/*.py
Os autores fornecem algumas características na placa de identificação:
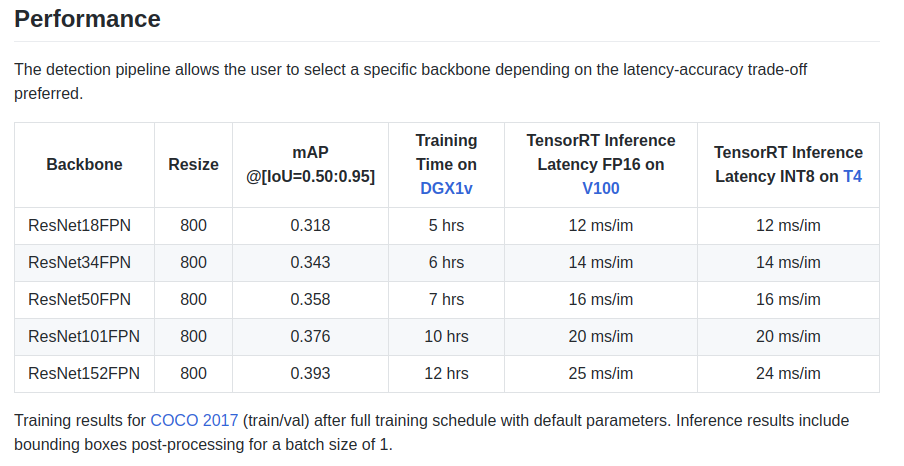
Há também um backbone ResNeXt50_32x4dFPN e ResNeXt101_32x8dFPN, retirado da visão da tocha.
Espero que tenhamos descoberto um pouco a detecção, mas você definitivamente deve ler a documentação oficial para
entender os modos de exportação e registro .
Etapa 5. Exportação e inferência de modelos Unet com codificador ResnetComo você provavelmente notou, as bibliotecas de segmentação foram instaladas no Dockerfile e, em particular, na maravilhosa biblioteca
github.com/qubvel/segmentation_models.pytorch . No pacote Yunet, você pode encontrar exemplos de inferência e exportação de pontos de verificação de pytorch no mecanismo TensorRT.
O principal problema ao exportar modelos do tipo Unet do ONNX para o TensoRT é a necessidade de definir um tamanho de Upsample fixo ou usar o ConvTranspose2D:
import torch.onnx.symbolic_opset9 as onnx_symbolic def upsample_nearest2d(g, input, output_size):
Usando essa conversão, você pode fazer isso automaticamente ao exportar para o ONNX, mas já na versão 7 do TensorRT esse problema foi resolvido e tivemos que esperar muito pouco.
ConclusãoQuando comecei a usar o docker, tive dúvidas sobre o desempenho das minhas tarefas. Em uma das minhas unidades, agora há bastante tráfego de rede criado por várias câmeras.
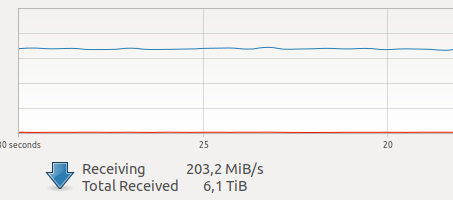
Vários testes na Internet revelaram uma sobrecarga relativamente grande para interação e gravação de rede em VOLUME, além de um GIL desconhecido e terrível, e desde que fotografar um quadro, a operação do driver e transmitir um quadro pela rede são operações atômicas no modo
difícil em tempo real online são muito críticos para mim.
Mas nada aconteceu =)
PS Resta adicionar seu loop de trem favorito para segmentação e produção!
ObrigadoGraças à comunidade
ods.ai , é impossível desenvolver sem ele! Muito obrigado a
n01z3 , DL, que desejava que eu assumisse a DL, por seus inestimáveis conselhos e extraordinário profissionalismo!
Use modelos otimizados na produção!
Aurorai, llc