Hoje vou contar como apliquei algoritmos de aprendizado profundo de reforço para controlar um robô. Em resumo, vou lhe mostrar como criar uma "caixa preta com redes neurais", que aceita a arquitetura do robô na entrada e gera um algoritmo que pode controlá-lo na saída.
O núcleo da solução é o algoritmo Advantage Actor Critic (A2C) com pontuações Advantage por meio da Generalized Advantage Estimation (GAE).
Sob o corte, a matemática, uma implementação do TensorFlow e muitas demonstrações do tipo de algoritmo de caminhada.
Conteúdo:
-
desafio-
Por que aprender reforço?-
Declaração de Aprendizado por Reforço-
gradiente político-
Políticas gaussianas diagonais-
Reduza a variação adicionando críticas-
Armadilhas- Conclusão
Desafio
Neste artigo, ensinaremos o robô a andar na simulação MuJoCo. Iremos pular a descrição da etapa criando um modelo do robô e a interface Python para o ambiente, porque não há nada interessante lá. Para entender, basta olhar para as demos no próprio MuJoCo e as fontes dos ambientes do MuJoCo no Gym OpenAI .
Na entrada, o agente terá muitos números de MuJoCo: posições relativas, ângulos de rotação, velocidade, aceleração de partes do corpo do robô, etc. No total, a ordem de ~ 800 recursos. Utilizamos a abordagem Deep Learning e não entenderemos o que eles realmente significam. O principal é que, nesse conjunto de números, haverá informações suficientes para que o agente possa entender o que está acontecendo com ele.
Na saída, esperaremos 18 números - o número de graus de liberdade do robô, o que significa os ângulos de rotação das dobradiças nas quais os membros estão fixos.
Por fim, o objetivo do agente é maximizar a recompensa total para o episódio. Terminaremos o episódio se o robô travar ou se 3000 etapas tiverem passado (15 segundos). Cada etapa recompensará o agente de acordo com a seguinte fórmula:
n e w c o m m a n d E m uma t h o p m a t h b b E n e w c o m m a n d I m uma t h o p m a t h b b R r t = D e l t a x ∗ 1000 + 0 ,5
I.e. o objetivo do agente aumentará sua coordenada x e não caia até o final do episódio.
Então, a tarefa é: encontrar uma função pi: R800 to R18 pelo qual a recompensa pelo episódio será a maior . Isso não parece muito certo? :) Vamos ver como o Deep Reinforcement Learning lida com essa tarefa.
Por que aprender reforço?
As abordagens modernas para resolver o problema do movimento de robôs ambulantes consistem em práticas clássicas de robótica, nas seções controle otimizado e otimização de trajetória : LQR, QP, otimização convexa. Leia mais: Postagem da equipe do Boston Dynamics no Atlas .
Essas técnicas são uma espécie de "codificação", porque exigem a introdução de muitos detalhes da tarefa diretamente no algoritmo de controle. Não há sistemas de aprendizagem neles - a otimização ocorre "no local".
Por outro lado, o Aprendizado por Reforço (daqui em diante RL) não requer hipóteses no algoritmo, tornando a solução do problema mais geral e escalável.
Declaração de Aprendizado por Reforço

Fonte
No problema de RL, consideramos a interação do agente e o ambiente como uma sequência de pares (estado, recompensa) e as transições entre eles - ação .
(s0) xrightarrowa0(s1,r1) xrightarrowa1... xrightarrowan−1(sn,rn)
Defina a terminologia:
- pi(at|st) - política , estratégia de comportamento do agente, probabilidade condicional,
- at sim pi( cdot|st) - ação é considerada uma variável aleatória da distribuição pi ,
Poderíamos considerar a política como uma função pi:States toAções , mas queremos tornar as ações do agente estocásticas, o que facilita a exploração . I.e. com alguma probabilidade, não realizamos as ações que o agente escolhe. - tau - trajetória traçada pelo agente, sequência (s1,s2,...,sn) .
A tarefa do agente é maximizar o retorno esperado :
J( pi)= E tau sim pi[R( tau)]= E tau sim pi left[ sumnt=0rt right]
Agora podemos formular o problema da RL, encontre:
pi∗=arg mathopmax piJ( pi)
onde pi∗ É a política ideal.
Leia mais no material da OpenAI: OpenAI Spinning Up .
Gradiente de política
Vale ressaltar que uma declaração rigorosa do problema de RL como um problema de otimização nos dá a oportunidade de usar os métodos de otimização já conhecidos, por exemplo, descida em gradiente . Imagine como seria legal se pudéssemos pegar o gradiente de retorno esperado pelos parâmetros do modelo : nabla thetaJ( pi theta) . Nesse caso, a regra para atualizar as escalas seria simples:
theta= thetaantigo+ alpha nabla thetaJ( pi theta)
Essa é precisamente a idéia de todos os métodos de gradiente de políticas . A conclusão estrita desse gradiente é um tanto incondicional. Não vamos escrever aqui, mas deixar um link para o maravilhoso material da OpenAI . O gradiente fica assim:
nabla thetaJ( pi theta)= E tau sim pi theta left[ sumTt=0 nabla theta log pi theta(at|st)R( tau) right]
Assim, a perda do nosso modelo será assim:
perda=− log( pi theta(at|st))R( tau)
Lembre-se que R( tau)= sumTt=0rt e pi theta(at|st) - esta é a saída do nosso modelo no momento em que ela estava st . O menos apareceu devido ao fato de que queremos maximizar J . Durante o treinamento, consideraremos o gradiente nos lotes e os adicionaremos para reduzir a variação (ruído de dados devido ao ambiente estocástico).
Este é um algoritmo de trabalho chamado REFORÇAR . E ele sabe como encontrar soluções para alguns ambientes simples. Por exemplo, "CartPole-v1" .
Considere o código do agente:
class ActorNetworkDiscrete: def __init__(self): self.state_ph = tf.placeholder(tf.float32, shape=[None, observation_space]) l1 = tf.layers.dense(self.state_ph, units=20, activation=tf.nn.relu) output_linear = tf.layers.dense(l1, units=action_space) output = tf.nn.softmax(output_linear) self.action_op = tf.squeeze(tf.multinomial(logits=output_linear,num_samples=1), axis=1)
Temos um pequeno perceptron dessa arquitetura: (o espaço de observação, 10, o espaço de ação) [para CartPole, este é (4, 10, 2)]. tf.multinomial permite escolher uma ação ponderada aleatoriamente. Para obter uma ação, você precisa ligar para:
action = sess.run(actor.action_op, feed_dict={actor.state_ph: observation})
E assim vamos treiná-lo:
batch_generator = generate_batch(environments, batch_size=batch_size) for epoch in tqdm_notebook(range(epochs_number)): batch = next(batch_generator)
O gerador de lotes executa o agente no ambiente e acumula dados para treinamento. Os elementos do lote são tuplas deste tipo: (st,at,R( tau)) .
Escrever um bom gerador é uma tarefa separada, onde a principal dificuldade é o alto custo relativo da chamada sess.run () em comparação com uma única etapa de simulação (mesmo MuJoCo). Para acelerar o trabalho, você pode explorar o fato de que as redes neurais são executadas em lotes e usam muitos ambientes paralelos. Mesmo iniciá-los sequencialmente em um thread dará uma aceleração significativa em comparação com um único ambiente.
Código do gerador usando DummyVecEnv das linhas de base OpenAI O agente resultante pode jogar em ambientes com um espaço finito de ações . Este formato não é adequado para a nossa tarefa. O agente que controla o robô deve emitir um vetor de Rn onde n - o número de graus de liberdade. ( ou você pode dividir o espaço de ação em intervalos e obter uma tarefa com uma saída discreta )
Políticas gaussianas diagonais
A essência da abordagem de políticas gaussianas diagonais é que o modelo produza parâmetros da distribuição normal n-dimensional, a saber mu theta - tapete. esperando e sigma theta desvio padrão. Assim que o agente precisar executar uma ação, solicitaremos esses parâmetros no modelo e tiraremos uma variável aleatória dessa distribuição. Então fizemos o agente sair Rn e tornou estocástico. O mais importante é que, tendo fixado a classe de distribuição na saída, podemos calcular log( pi theta(at|st)) e, portanto, gradiente político.
Nota: pode ser corrigido sigma theta como um hiperparâmetro, reduzindo assim a dimensão da saída. A prática mostra que isso não causa muito dano, mas, pelo contrário, estabiliza o aprendizado.
Leia mais sobre política estocástica .
Código do agente:
epsilon = 1e-8 def gaussian_loglikelihood(x, mu, log_std): pre_sum = -0.5 * (((x - mu) / (tf.exp(log_std) + epsilon))**2 + 2 * log_std + np.log(2 * np.pi)) return tf.reduce_sum(pre_sum, axis=1) class ActorNetworkContinuous: def __init__(self): self.state_ph = tf.placeholder(tf.float32, shape=[None, observation_space]) l1 = tf.layers.dense(self.state_ph, units=100, activation=tf.nn.tanh) l2 = tf.layers.dense(l1, units=50, activation=tf.nn.tanh) l3 = tf.layers.dense(l2, units=25, activation=tf.nn.tanh) mu = tf.layers.dense(l3, units=action_space) log_std = tf.get_variable(name='log_std', initializer=-0.5 * np.ones(action_space, std = tf.exp(log_std) self.action_op = mu + tf.random.normal(shape=tf.shape(mu)) * std
A parte do treinamento não é diferente.
Agora finalmente podemos ver como o REFINFORCE lidará com a nossa tarefa. A seguir, o objetivo do agente é mover para a direita.
Lenta mas seguramente rastejando em direção a seu objetivo.
Recompensa para viagem
Observe que existem membros extras em nosso gradiente. Ou seja, para cada etapa t ao pesar o gradiente do logaritmo, usamos a recompensa total para toda a trajetória . Assim, avaliando as ações do agente por suas realizações do passado. Parece errado, não é? Portanto, este
nabla thetaJ( pi theta)= E tau sim pi theta left[ sumTt=0 nabla theta log pi theta(at|st) sumTt′=0rt′ right]
vai se tornar isso
nabla thetaJ( pi theta)= E tau sim pi theta left[ sumTt=0 nabla theta log pi theta(at|st) sumTt′=trt′ right]
Encontre 10 diferenças :)
Embora a presença desses membros não estrague nada matematicamente, isso faz muito barulho para nós. Agora, durante o treinamento, o agente prestará atenção apenas às recompensas que recebeu após uma ação específica .
Devido a essa melhoria, a recompensa média aumentou. Um dos agentes recebidos aprendeu a usar os membros anteriores para alcançar seu objetivo:
Reduza a variação adicionando críticas
A essência de outras melhorias é a redução do ruído (variação) decorrente das transições estocásticas entre os estados do meio.
Isso nos ajudará a adicionar um modelo que preveja a quantidade média de recompensas recebidas pelo agente, a partir do estado s até o final da trajetória, ou seja, Função de valor.
V pi(s)= E tau sim pi left[R( tau)|s0=s right] text−Funçãodevalor
Q pi(s,a)= E tau sim pi left[R( tau)|s0=s,a0=a right] text−Funçãodevalordeação
A pi(s,a)=Q pi(s,a)−V pi(s) text−FunçãoAdvantage
A função Valor mostra o retorno esperado se nossa política iniciar o jogo a partir de um estado específico. O mesmo com a função Q, basta corrigir a primeira ação.
Adicionar crítica
É assim que o gradiente fica ao usar o Reward-to-Go:
nabla theta log pi theta(at|st) sumTt′=trt′
Agora, o coeficiente para o gradiente do logaritmo nada mais é do que uma amostra da função Valor.
sumTt′=trt′ simV pi(st)
Pesamos o gradiente de logaritmo com uma amostra de uma trajetória específica, o que não é bom. Podemos aproximar a função Valor com algum modelo, por exemplo, uma rede neural, e solicitar o valor necessário, reduzindo assim a variação. Chamaremos esse modelo de crítico (Critic) e o estudaremos em paralelo com a política. Assim, a fórmula do gradiente pode ser escrita como:
nabla theta log pi theta(at|st) sumTt′=trt′ approx nabla theta log pi theta(at|st)V pi( tau)
Reduzimos a variação, mas, ao mesmo tempo, introduzimos o viés em nosso algoritmo, já que as redes neurais podem cometer erros de aproximação. Mas o compromisso nessa situação é bom. Tais situações no aprendizado de máquina são chamadas de troca de viés e variância .
O crítico ensinará a regressão da função Valor em amostras de recompensa coletadas no ambiente. Como uma função de erro, tomamos o MSE. I.e. perda é assim:
loss=(V pi psi(st)− sumTt′=trt′)2
Código crítico:
class CriticNetwork: def __init__(self): self.state_ph = tf.placeholder(tf.float32, shape=[None, observation_space]) l1 = tf.layers.dense(self.state_ph, units=100, activation=tf.nn.tanh) l2 = tf.layers.dense(l1, units=50, activation=tf.nn.tanh) l3 = tf.layers.dense(l2, units=25, activation=tf.nn.tanh) output = tf.layers.dense(l3, units=1) self.value_op = tf.squeeze(output, axis=-1)
O ciclo de treinamento agora fica assim:
batch_generator = generate_batch(envs, batch_size=batch_size) for epoch in tqdm_notebook(range(epochs_number)): batch = next(batch_generator)
Agora, o lote contém outro valor, valor calculado pelo crítico no gerador.
I.e. o tipo de lote é este: (st,at,V pi psi(st), sumTt′=trt′) .
No ciclo, nada nos limita a treinar o crítico para a convergência , por isso tomamos várias etapas de descida gradiente, melhorando a aproximação da função Value e reduzindo o viés. No entanto, essa abordagem requer um tamanho de lote grande para evitar a reciclagem. Uma afirmação semelhante sobre política de aprendizagem não é verdadeira. Ele deve receber feedback instantâneo do ambiente de aprendizado; caso contrário, podemos nos encontrar em uma situação em que multamos a política por ações que ela ainda não teria tomado. Algoritmos com essa propriedade são chamados na política .
Linhas de base em gradientes de políticas
Pode-se demonstrar que no gradiente é permitido colocar uma ampla classe de outras funções úteis de t . Tais funções são chamadas de linhas de base . ( Conclusão deste fato ) As seguintes funções têm bom desempenho como linhas de base:

Fonte: artigo do GAE .
Linhas de base diferentes fornecem resultados diferentes, dependendo da tarefa. Como regra, o maior lucro é dado pela função Advantage e suas aproximações.
Há até um pouco de intuição por trás disso. Quando usamos o Advantage, multamos o agente na proporção de quanto melhor ou pior que a média o agente considera a ação que ele executou. E quanto melhor o agente joga no ambiente, mais altos se tornam seus padrões . O agente ideal irá desempenhar bem e avaliar todas as suas ações como tendo Advantage igual a 0 e, portanto, com um gradiente igual a 0.
Avaliação de vantagem através da função Value
Lembre-se da definição de vantagem:
A pi(s,a)=Q pi(s,a)−V pi(s) text−FunçãoAdvantage
Não está claro como aprender explicitamente essa função. Um truque virá ao resgate, o que reduzirá o cálculo da função Advantage ao cálculo da função Value.
Definir deltaVt=rt+V(st+1)−V(st) - Diferença temporal residual ( TD-residual ). Não é difícil deduzir que essa função se aproxima do Advantage:
E left[ deltaVt right]= E left[rt+V(st+1)−V(st) right]= E left[Q(st,at)−V(st) direita]=A(st,at)
Essa mudança conceitualmente complexa provoca uma mudança não tão grande no código. Agora, em vez de avaliar a função Valor, o crítico enviará uma avaliação do Advantage para o treinamento de políticas.
O algoritmo resultante é chamado de Advantage Actor-Critic .
def estimate_advantage(states, rewards): values = sess.run(critic.value_op, feed_dict={critic.state_ph: states}) deltas = rewards - values deltas = deltas + np.append(values[1:], np.array([0])) return deltas, values
Os agentes obtidos podem ser observados marcha confiante e uso síncrono dos membros:
Estimativa de Vantagens Generalizadas
Um artigo relativamente recente (2018), " Controle contínuo de alta dimensão usando determinação generalizada de vantagens ", oferece uma avaliação ainda mais eficaz do Advantage por meio da função Value. Reduz ainda mais a variação:
AGAE( gama, lambda)t= sum l=0infty( gama lambda)l deltaVt+l
onde:
- deltaVt=rt+V(st+1)−V(st) - TD residual,
- gama - fator de desconto (hiperparâmetro),
- lambda - hiperparâmetro.
A interpretação pode ser encontrada na própria publicação.
Implementação:
def discount_cumsum(x, coef):
Ao usar um tamanho de lote pequeno, o algoritmo convergiu para algumas ótimas locais. Aqui, o agente usa uma pata como bengala e o restante empurra:
Aqui, o agente não chegou ao uso de saltos, mas simplesmente mexeu rapidamente nos membros. E você também pode ver como ele se comporta; se ele hesitar, ele se voltará e continuará correndo:
O melhor agente, ele está no começo do artigo. Salto estável, durante o qual todos os membros saem da superfície. A capacidade desenvolvida de equilibrar permite que o agente corrija a trajetória a toda velocidade, se um erro foi cometido:
Armadilhas
O aprendizado de máquina é famoso pela dimensão do espaço de erros que pode ser cometido e obtém um algoritmo completamente inoperante. Mas a RL leva o problema a um nível totalmente novo.
Fonte
Aqui estão algumas das dificuldades encontradas durante o desenvolvimento.
- O algoritmo é surpreendentemente sensível aos hiperparâmetros. Houve uma mudança na qualidade da aprendizagem ao alterar a taxa de aprendizagem de 3e-4 para 1e-4. E a imagem mudou radicalmente - de um algoritmo completamente não convergente para o melhor que está no vídeo.
- O tamanho do lote não é o mesmo que em outras áreas da DL. Se na classificação de imagens você puder escolher o tamanho do lote 32-256 e o resultado não for alterado significativamente de aumentá-lo, é melhor levar alguns milhares, 3000 trabalhos para nossa tarefa. E novamente, por falta de convergência em um bom algoritmo.
- É melhor aprender várias vezes, às vezes com sementes aleatórias não dá sorte.
- Aprender em um ambiente tão complexo leva muito tempo e o progresso não é uniforme. Por exemplo, o melhor algoritmo aprendido por 8 horas, 3 dos quais mostraram um resultado pior do que uma linha de base aleatória. Portanto, ao testar os algoritmos, é melhor começar com um pequeno, como ambientes de brinquedos da academia.
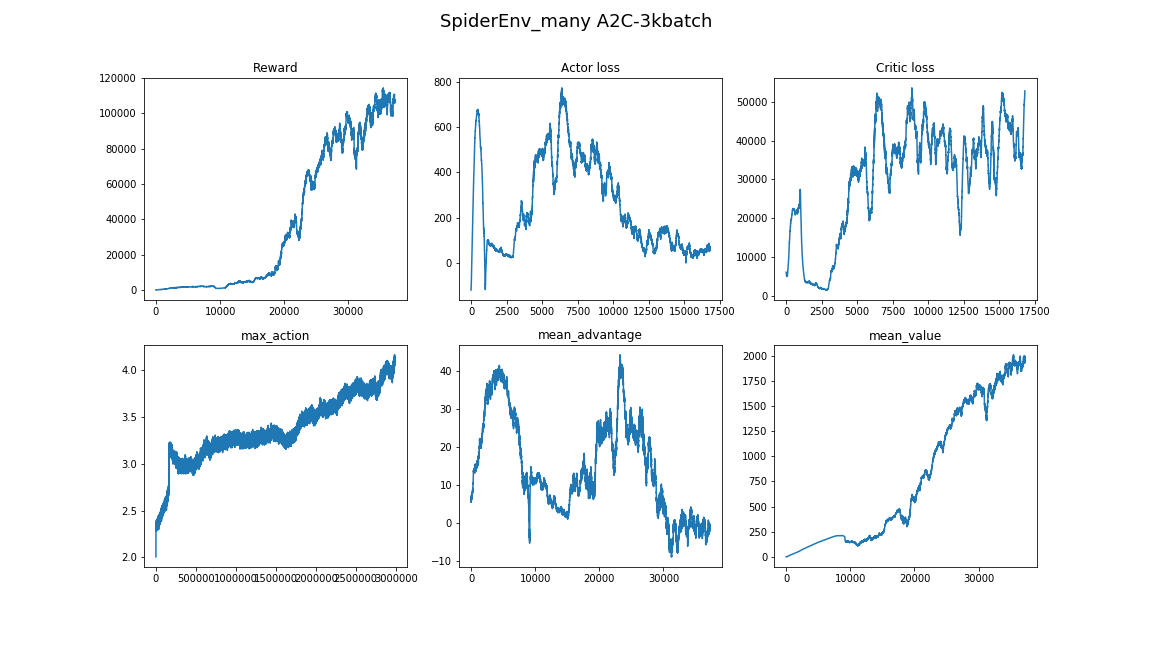
- Uma boa abordagem para encontrar hiperparâmetros e arquiteturas de modelo seria espiar artigos e implementações relacionadas. (o principal não é treinar novamente)
Você pode aprender mais sobre as nuances do Deep RL neste artigo: O Deep Reforcement Learning ainda não funciona .
Conclusão
O algoritmo resultante resolve de maneira convincente o problema. Função encontrada pi: R800 to R18 , controlando o robô com agilidade e confiança.
Uma continuação lógica será o estudo de parentes próximos dos algoritmos A2C, PPO e TRPO. Eles melhoram a eficiência da amostra , ou seja, tempo de convergência do algoritmo e são capazes de resolver problemas mais complexos. Foi a aleatorização automática de domínio PPO + que montou recentemente o cubo de Rubik em um robô .
Aqui você pode encontrar o código do artigo: repository .
Espero que tenham gostado do artigo e tenham sido inspirados pelo que o Deep Reinforcement Learning pode fazer hoje.
Obrigado pela atenção!
Links úteis:
Agradecemos a pinkotter , Vambala , andrey_probochkin , pollyfom e suriknik por ajudarem no projeto.
Em particular, Vambala e andrey_probochkin por criar um ambiente legal de MuJoCo.