Clickhouse é um mecanismo de banco de dados de sistema de gerenciamento de banco de dados de consulta analítica (OLAP) de código aberto, criado por Yandex. É usado pelo Yandex, CloudFlare, VK.com, Badoo e outros serviços em todo o mundo para armazenar grandes quantidades de dados (inserir milhares de linhas por segundo ou petabytes de dados armazenados no disco).
Em um DBMS regular de "string", cujos exemplos são MySQL, Postgres, MS SQL Server, os dados são armazenados nesta ordem:
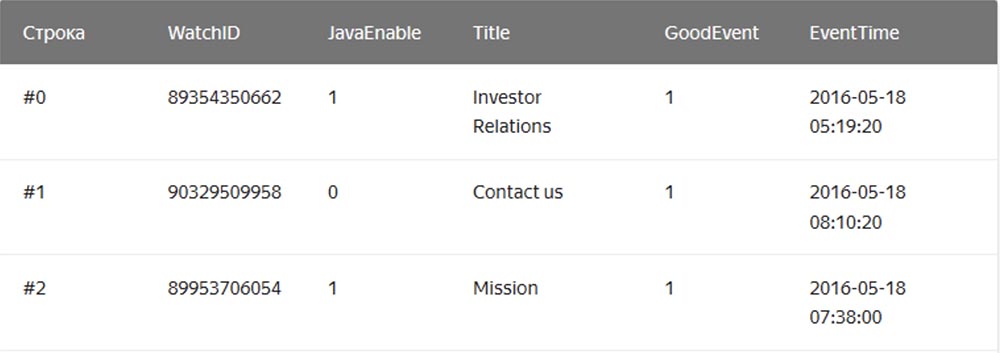
Nesse caso, os valores relacionados a uma linha são fisicamente armazenados lado a lado. Em um DBMS colunar, os valores de diferentes colunas são armazenados separadamente e os dados de uma coluna são armazenados juntos:
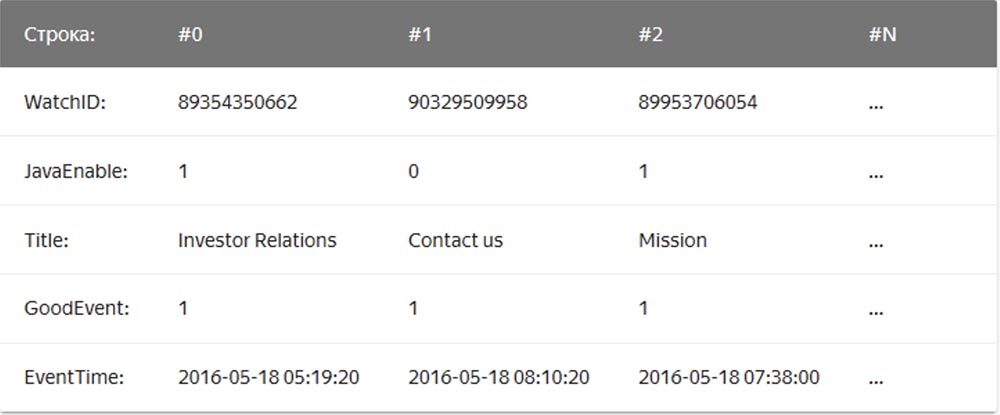
Exemplos de DBMSs colunares são Vertica, Paraccel (Actian Matrix, Amazon Redshift), Sybase IQ, Exasol, Infobright, InfiniDB, MonetDB (VectorWise, Actian Vector), LucidDB, SAP HANA, Google Dremel, Google PowerDrill, Druid, kdb +.
A empresa de
encaminhamento de correspondência Qwintry começou a usar o Clickhouse em 2018 para gerar relatórios e ficou muito impressionada com sua simplicidade, escalabilidade, suporte a SQL e velocidade. A velocidade desse DBMS foi limitada pela mágica.
Simplicidade
O Clickhouse é instalado no Ubuntu com um único comando. Se você conhece SQL, pode começar a usar o Clickhouse imediatamente para suas necessidades. No entanto, isso não significa que você possa executar "show create table" no MySQL e copiar e colar o SQL no Clickhouse.
Comparado ao MySQL, neste DBMS existem diferenças importantes de tipos de dados nas definições de esquemas de tabela; portanto, para um trabalho confortável, você ainda precisa de algum tempo para alterar as definições do esquema de tabela e estudar os mecanismos de tabela.
O Clickhouse funciona muito bem sem nenhum software adicional, mas se você quiser usar a replicação, precisará instalar o ZooKeeper. A análise de desempenho da consulta mostra excelentes resultados - as tabelas do sistema contêm todas as informações e todos os dados podem ser obtidos usando o SQL antigo e chato.
Desempenho
- Referência comparativa da Clickhouse com a Vertica e o MySQL em um servidor de configuração: dois soquetes de CPU Intel® Xeon® E5-2650 v2 a 2.60GHz; 128 GiB de RAM; md RAID-5 em 8 6 TB SATA HDD, ext4.
- Referência comparativa da Clickhouse com o armazenamento de dados em nuvem do Amazon RedShift.
- Trechos do Blog de desempenho do Cloudflare Clickhouse :

O banco de dados ClickHouse possui um design muito simples - todos os nós no cluster têm a mesma funcionalidade e usam apenas o ZooKeeper para coordenação. Construímos um pequeno cluster de vários nós e realizamos testes, durante os quais descobrimos que o sistema possui um desempenho bastante impressionante, o que corresponde às vantagens declaradas nos benchmarks de DBMSs analíticos. Decidimos dar uma olhada no conceito por trás do ClickHouse. O primeiro obstáculo à pesquisa foi a falta de ferramentas e o pequeno tamanho da comunidade ClickHouse. Por isso, investigamos o design desse sistema de gerenciamento de banco de dados para entender como ele funciona.
O ClickHouse não suporta o recebimento de dados diretamente do Kafka (no momento, ele já sabe como), uma vez que é apenas um banco de dados, por isso, escrevemos nosso próprio serviço de adaptador no Go. Ele leu as mensagens codificadas pelo Cap'n Proto da Kafka, as converteu em TSV e as inseriu no ClickHouse em lotes por meio da interface HTTP. Mais tarde, reescrevemos este serviço para usar a biblioteca Go em conjunto com nossa própria interface ClickHouse para melhorar o desempenho. Ao avaliar o desempenho dos pacotes recebidos, descobrimos uma coisa importante - verificou-se que na ClickHouse esse desempenho depende muito do tamanho do pacote, ou seja, do número de linhas inseridas ao mesmo tempo. Para entender por que isso está acontecendo, examinamos como o ClickHouse armazena dados.
O mecanismo principal, ou melhor, a família de mecanismos de tabela usados pelo ClickHouse para armazenar dados, é o MergeTree. Esse mecanismo é conceitualmente semelhante ao algoritmo LSM usado pelo Google BigTable ou Apache Cassandra, mas evita a construção de uma tabela de memória intermediária e grava dados diretamente no disco. Isso proporciona excelente taxa de transferência de gravação, uma vez que cada pacote inserido é classificado apenas pela chave primária "chave primária", é compactado e gravado no disco para formar um segmento.
A ausência de uma tabela de memória ou qualquer conceito de "atualização" dos dados também significa que eles só podem ser adicionados; o sistema não suporta alterá-los ou excluí-los. Hoje, a única maneira de excluir dados é excluí-los por meses, pois os segmentos nunca cruzam o limite do mês. A equipe ClickHouse está trabalhando ativamente para tornar esse recurso personalizável. Por outro lado, isso torna a gravação e a fusão de segmentos perfeitas, para que a largura de banda da recepção seja escalada linearmente com o número de inserções paralelas até que a E / S ou os núcleos estejam saturados.
No entanto, esse fato também significa que o sistema não é adequado para pacotes pequenos; portanto, os serviços e inserções Kafka são usados para buffer. Além disso, o ClickHouse em segundo plano continua a executar constantemente a mesclagem de segmentos, para que muitas pequenas informações sejam combinadas e registradas mais vezes, aumentando assim a intensidade da gravação. Nesse caso, muitas peças não relacionadas causarão uma aceleração agressiva das inserções enquanto a fusão continuar. Descobrimos que o melhor compromisso entre a recepção de dados em tempo real e o desempenho da recepção é receber um número limitado de inserções por segundo na tabela.
A chave para o desempenho da leitura de tabelas é indexar e posicionar dados no disco. Independentemente da velocidade do processamento, quando o mecanismo precisar verificar terabytes de dados do disco e usar apenas parte deles, isso levará tempo. O ClickHouse é um armazenamento de colunas; portanto, cada segmento contém um arquivo para cada coluna (coluna) com valores classificados para cada linha. Assim, colunas inteiras que não estão na consulta podem ser puladas primeiro e, em seguida, várias células podem ser processadas em paralelo com a execução vetorizada. Para evitar uma verificação completa, cada segmento possui um pequeno arquivo de índice.
Como todas as colunas são classificadas por "chave primária", o arquivo de índice contém apenas os rótulos (linhas capturadas) de cada enésima linha para poder armazená-las na memória, mesmo em tabelas muito grandes. Por exemplo, você pode definir as configurações padrão "marcar cada 8192ª linha" e, em seguida, a indexação "escassa" da tabela com 1 trilhão. linhas, que se encaixam facilmente na memória, terão apenas 122.070 caracteres.
Desenvolvimento de sistemas
O desenvolvimento e aprimoramento da Clickhouse podem ser rastreados até o repositório do
Github e garantir que o processo de "crescimento" esteja ocorrendo em um ritmo impressionante.
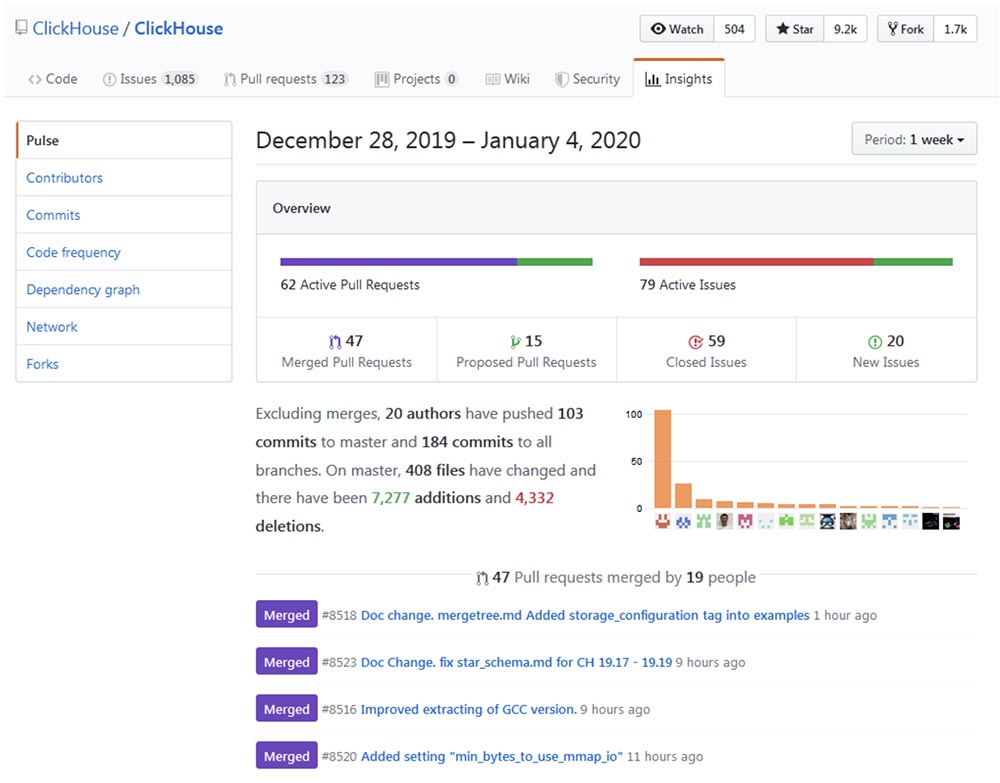
Popularidade
Clickhouse parece estar crescendo exponencialmente, principalmente na comunidade de língua russa. A conferência do ano passado, High load 2018 (Moscou, 8 a 9 de novembro de 2018) mostrou que monstros como vk.com e Badoo usam o Clickhouse, com o qual colam dados (por exemplo, logs) de dezenas de milhares de servidores ao mesmo tempo. Em um vídeo de 40 minutos,
Yuri Nasretdinov, da equipe VKontakte, fala sobre como isso é feito . Em breve publicaremos a transcrição no Habr para facilitar o trabalho com o material.
Áreas de aplicação
Depois de algum tempo pesquisando, acho que há áreas nas quais o ClickHouse pode ser útil ou capaz de substituir completamente outras soluções mais tradicionais e populares, como MySQL, PostgreSQL, ELK, Google Big Query, Amazon RedShift, TimescaleDB, Hadoop, MapReduce, Pinot e Druid. A seguir, são apresentados detalhes do uso do ClickHouse para atualizar ou substituir completamente os DBMSs acima.
Estendendo o MySQL e o PostgreSQL
Mais recentemente, substituímos parcialmente o MySQL pelo ClickHouse para a
plataforma de boletins informativos da
Mautic . O problema era que o MySQL, devido ao seu design mal concebido, registrou todas as cartas enviadas e todos os links nesta carta com um hash base64, criando uma enorme tabela MySQL (email_stats). Depois de enviar apenas 10 milhões de cartas para os assinantes do serviço, essa tabela ocupou 150 GB de espaço no arquivo e o MySQL começou a "entediar" em consultas simples. Para corrigir o problema de espaço no arquivo, usamos a compactação de tabela do InnoDB, que reduziu em 4 vezes. No entanto, ainda não faz sentido armazenar mais de 20 a 30 milhões de e-mails no MySQL apenas para ler a história, pois qualquer consulta simples que, por algum motivo, precise executar uma varredura completa, leva a uma troca e uma grande carga de E / S, por sobre as quais recebemos regularmente avisos do Zabbix.

A Clickhouse usa dois algoritmos de compactação que reduzem a quantidade de dados em cerca de
3 a
4 vezes , mas nesse caso específico os dados eram especialmente "compactáveis".

Substituição de ELK
Com base em nossa própria experiência, a pilha ELK (ElasticSearch, Logstash e Kibana, nesse caso em particular, ElasticSearch) requer muito mais recursos para executar do que o necessário para armazenar logs. O ElasticSearch é um ótimo mecanismo, se você precisar de uma boa pesquisa de log de texto completo (e acho que realmente não precisa disso), mas me pergunto por que, de fato, se tornou o mecanismo de log padrão. Seu desempenho de recepção em combinação com o Logstash criou problemas para nós, mesmo com cargas bastante pequenas, e exigiu a adição de uma quantidade crescente de RAM e espaço em disco. Como banco de dados, o Clickhouse é melhor que o ElasticSearch pelos seguintes motivos:
- Suporte de dialeto SQL;
- A melhor taxa de compactação dos dados armazenados;
- Suporte para pesquisas de expressão regular regex em vez de pesquisas de texto completo;
- Planejamento de consulta aprimorado e maior desempenho geral.
Atualmente, o maior problema que surge ao comparar o ClickHouse com o ELK é a falta de soluções para os logs de remessa, bem como a falta de documentação e auxílios de treinamento sobre este tópico. Ao mesmo tempo, cada usuário pode configurar o ELK usando o Digital Ocean Guide, que é muito importante para a rápida implementação de tais tecnologias. Existe um mecanismo de banco de dados aqui, mas ainda não existe o Filebeat for ClickHouse. Sim, existe um sistema
fluente e um sistema para trabalhar com logs de
loghouse , existe uma ferramenta de
clicktail para inserir dados de arquivos de log no ClickHouse, mas tudo isso leva mais tempo. No entanto, o ClickHouse ainda lidera devido à sua simplicidade, portanto, mesmo os iniciantes o instalam elementarmente e começam a usá-lo totalmente em apenas 10 minutos.
Preferindo soluções minimalistas, tentei usar o FluentBit, uma ferramenta para enviar logs com uma quantidade muito pequena de memória, junto com o ClickHouse, enquanto evitava usar o Kafka. No entanto, pequenas incompatibilidades, como
problemas de formato de data , devem ser corrigidas antes que isso possa ser feito sem uma camada proxy que converta dados do FluentBit em ClickHouse.
Como alternativa ao Kibana, você pode usar o
Grafana como
back-end do ClickHouse. Pelo que entendi, isso pode causar problemas de desempenho ao renderizar uma quantidade enorme de pontos de dados, especialmente nas versões mais antigas do Grafana. Na Qwintry, ainda não tentamos isso, mas as queixas sobre isso de tempos em tempos aparecem no canal de suporte do ClickHouse no Telegram.
Substituindo o Google Big Query e o Amazon RedShift (solução para grandes empresas)
O caso de uso ideal para o BigQuery é fazer o download de 1 TB de dados JSON e executar consultas analíticas neles. O Big Query é um ótimo produto cuja escalabilidade é difícil de superestimar. Este é um software muito mais complexo que o ClickHouse, executado em um cluster interno, mas do ponto de vista do cliente, ele tem muito em comum com o ClickHouse. O BigQuery pode subir rapidamente de preço assim que você paga por cada SELECT, portanto, essa é uma solução SaaS real com todos os seus prós e contras.
O ClickHouse é a melhor opção quando você realiza muitas consultas computacionalmente caras. Quanto mais consultas SELECT você executa a cada dia, mais faz sentido substituir o Big Query pelo ClickHouse, porque essa substituição economiza milhares de dólares quando se trata de muitos terabytes de dados processados. Isso não se aplica aos dados armazenados, o que é bastante barato para processar no Big Query.
O artigo do cofundador da Altinity, Alexander Zaitsev,
“Mudando para ClickHouse”, fala sobre os benefícios dessa migração de DBMS.
Substituindo o TimescaleDB
O TimescaleDB é uma extensão do PostgreSQL que otimiza o trabalho com séries temporais de séries temporais em um banco de dados regular (
https://docs.timescale.com/v1.0/introduction ,
https://habr.com/en/company/zabbix/blog/458530 / ).
Embora o ClickHouse não seja um concorrente sério no nicho da série temporal, mas a estrutura da coluna e a execução de consultas de vetores, na maioria dos casos de processamento de consultas analíticas, é muito mais rápido que o TimescaleDB. Ao mesmo tempo, o desempenho de recebimento de dados do pacote ClickHouse é cerca de três vezes maior, além disso, usa 20 vezes menos espaço em disco, o que é realmente importante para o processamento de grandes quantidades de dados históricos:
https://www.altinity.com/blog/ClickHouse-for -time-series .
Diferentemente do ClickHouse, a única maneira de economizar espaço em disco no TimescaleDB é usar o ZFS ou sistemas de arquivos similares.
As próximas atualizações do ClickHouse provavelmente introduzirão a compactação delta, o que o tornará ainda mais adequado para o processamento e armazenamento de dados de séries temporais. O TimescaleDB pode ser uma escolha melhor do que uma ClickHouse nua nos seguintes casos:
- pequenas instalações com uma quantidade muito pequena de RAM (<3 GB);
- um grande número de pequenos INSERTs que você não deseja armazenar em buffer em fragmentos grandes;
- melhor consistência, uniformidade e requisitos de ACID;
- Suporte PostGIS;
- mesclando com tabelas existentes do PostgreSQL, já que o Timescale DB é essencialmente o PostgreSQL.
Concorrência com os sistemas Hadoop e MapReduce
O Hadoop e outros produtos MapReduce podem executar muitos cálculos complexos, mas geralmente trabalham com grandes atrasos.O ClickHouse corrige esse problema processando terabytes de dados e fornecendo resultados quase instantaneamente. Portanto, o ClickHouse é muito mais eficiente para realizar pesquisas analíticas interativas e rápidas, o que deve ser interessante para especialistas em processamento de dados.
Competição com Pinot e Druida
Os concorrentes mais próximos da ClickHouse são o Pinot e o Druid, um produto de código aberto colunar linearmente escalável. Um excelente trabalho comparando esses sistemas foi publicado em um artigo de
Roman Leventov de 1 de fevereiro de 2018.
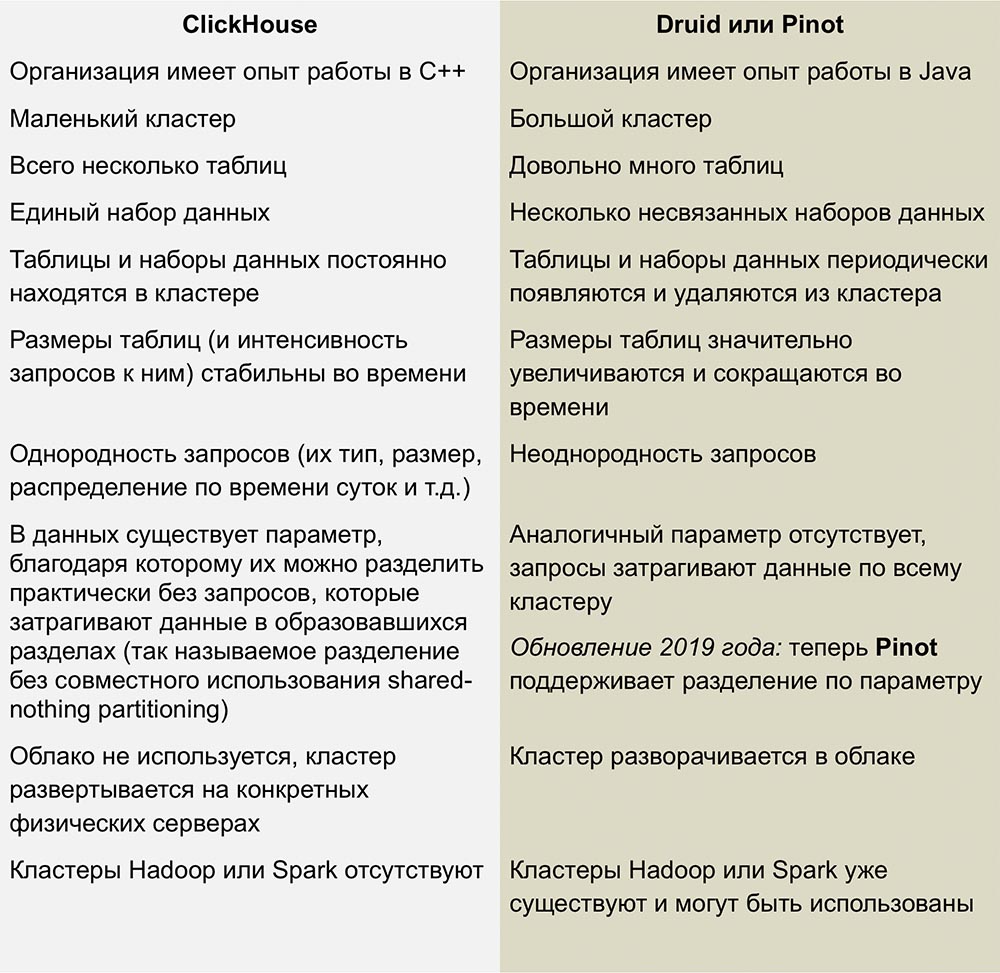
Este artigo requer atualização - ele afirma que o ClickHouse não oferece suporte às operações UPDATE e DELETE, o que não é totalmente verdadeiro para as versões mais recentes.
Não temos experiência suficiente com esses DBMSs, mas não gosto da complexidade da infraestrutura usada para executar o Druid e o Pinot - esse é um monte de "partes móveis" cercadas por Java por todos os lados.
Druid e Pinot são projetos da incubadora Apache, cujo progresso no desenvolvimento é coberto em detalhes pelo Apache nas páginas de seus projetos GitHub. Pinot apareceu na incubadora em outubro de 2018 e Druid nasceu 8 meses antes - em fevereiro.
A falta de informações sobre como o AFS funciona me dá algumas, e talvez perguntas tolas. Gostaria de saber se os autores de Pinot notaram que a Apache Foundation é mais disposta a Druid, e essa atitude em relação ao concorrente causou inveja? O desenvolvimento do Druid desacelerará e o Pinot acelerará se os patrocinadores que apoiam o primeiro de repente se interessarem pelo último?
Desvantagens do ClickHouse
Imaturidade: Obviamente, essa ainda não é uma tecnologia chata, mas, de qualquer forma, nada semelhante é observado em outros DBMSs colunares.
Pastilhas pequenas não funcionam bem em alta velocidade: as pastilhas devem ser divididas em pedaços grandes, porque o desempenho de pastilhas pequenas diminui proporcionalmente ao número de colunas em cada linha. É assim que o ClickHouse armazena dados no disco - cada coluna significa 1 arquivo ou mais; portanto, para inserir 1 linha contendo 100 colunas, você deve abrir e gravar pelo menos 100 arquivos. É por isso que um intermediário é necessário para armazenar inserções em buffer (a menos que o próprio cliente forneça buffer) - geralmente é Kafka ou algum tipo de sistema de gerenciamento de filas. Você também pode usar o mecanismo de tabela Buffer para copiar posteriormente grandes blocos de dados nas tabelas MergeTree.
As junções de tabela são limitadas pela RAM do servidor, mas pelo menos elas estão lá! Por exemplo, Druid e Pinot não possuem essas conexões, uma vez que são difíceis de implementar diretamente em sistemas distribuídos que não suportam a movimentação de grandes quantidades de dados entre nós.
Conclusões
Nos próximos anos, planejamos fazer uso extensivo do ClickHouse no Qwintry, pois esse DBMS fornece um excelente equilíbrio de desempenho, baixa sobrecarga, escalabilidade e simplicidade. Tenho certeza de que ele começará a se espalhar rapidamente assim que a comunidade ClickHouse tiver mais maneiras de usá-lo em instalações pequenas e médias.
Um pouco de publicidade :)
Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando aos seus amigos o
VPS baseado em nuvem para desenvolvedores a partir de US $ 4,99 , um
analógico exclusivo de servidores básicos que foi inventado por nós para você: Toda a verdade sobre o VPS (KVM) E5-2697 v3 (6 núcleos) 10GB DDR4 480GB SSD 1Gbps de 10GB de US $ 19 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
Dell R730xd 2 vezes mais barato no data center Equinix Tier IV em Amsterdã? Somente temos
2 TVs Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV a partir de US $ 199 na Holanda! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - a partir de US $ 99! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?