
1. Introdução
Eu gosto muito de programação, sou amador e a primeira e a última vez que ganhei dinheiro com programação em 1996. Mas às vezes escrevo algo para automatizar tarefas diárias. Cerca de um ano atrás, golang foi descoberto. Como uma ferramenta para criar utilitários, o golang se mostrou muito conveniente. Então
Havia uma necessidade de processar um grande número (mais de mil, e vejo os sorrisos de um profissional) de arquivos com informações geofísicas especiais. O formato do arquivo é texto, simples. Se você está subitamente interessado, então este é um formato LAS .
O arquivo LAS contém cabeçalho e dados.
Os dados são praticamente CSV, apenas delimitador de tabulação ou espaços.
E o cabeçalho contém uma descrição dos dados e aqui geralmente contém texto em russo. Pode ser o nome do campo, o nome dos estudos registrados em um arquivo, etc.
Esses arquivos foram criados em momentos diferentes e em programas diferentes, no fato de que em um arquivo parte é codificada no CP1251 e parte no CP866. Eu preciso processar esses arquivos, o que significa entender. Portanto, era necessário determinar automaticamente a codificação do arquivo.
Como resultado, ele inventou uma bicicleta no golang e, consequentemente, uma pequena biblioteca nasceu com a capacidade de detectar uma página de código.
Sobre codificações. Há pouco tempo, no habr, havia um bom artigo sobre codificações Como as codificações de texto funcionam. De onde vêm os "crocodilos". Os princípios de codificação. Generalização e análise detalhada: se você quiser entender o que são "ossos" ou "ossos", vale a pena ler.
No começo, joguei minha decisão. Então tentei encontrar uma solução de trabalho pronta para golang, mas falhei. Havia duas soluções, mas ambas não funcionam.
- A primeira "pronta para uso" - golang.org/x/net/html/charset função DetermineEncoding ()
- Segunda biblioteca - saintfish / chardet no github
Ambos certamente estão enganados em algumas codificações. O padrão geralmente não pode determinar quase nada de arquivos de texto, é compreensível, foi feito para páginas html.
Ao pesquisar, encontrei frequentemente utilitários prontos do mundo linux - enca . Foi encontrada sua versão compilada para WIN32, versão 1.12. Também vou considerar, há coisas divertidas por lá. Peço desculpas imediatamente por minha completa ignorância do linux, o que significa que provavelmente existem mais soluções que você também pode tentar alterar para o código golang. Eu não parecia mais.
Comparação de soluções encontradas para codificação de detecção automática
Preparou um catálogo de dados de teste de softlandia \ cpd com arquivos em diferentes codificações. O conteúdo dos arquivos é muito curto e igual. Uma linha "russo na codificação CodePageName". Adicionei arquivos com uma mistura de codificações e alguns casos complexos e tentei determinar.
Eu acho que ficou engraçado.
Observação 1
enca não determinou a codificação do arquivo UTF-16LE sem a BOM - isso é estranho, tudo bem. Tentei adicionar mais texto, mas não obtive o resultado.
Observação 2. Problemas com os códigos CP1251 e KOI8-R
Linhas 15 e 16. O comando enca tem problemas.
Aqui vou fazer uma explicação, o fato é que as codificações CP1251 (também conhecido como Windows 1251) e KOI8-R são muito próximas se considerarmos apenas caracteres alfabéticos.
Quadro CP 1251
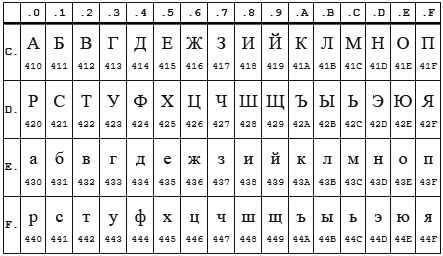
Mesa KOI8-r

Nas duas codificações, o alfabeto está localizado de 0xC0 a 0xFF , mas onde uma codificação possui letras maiúsculas, a outra possui letras minúsculas. Aparentemente, o enca funciona em letras minúsculas. Acontece que, se você enviar a string "STP" codificada no CP1251 para o programa de encaixe , ele decidirá que é a string "veementemente" codificada no KOI8-r , que será relatada. Reverso também funciona.
Observação 3
A biblioteca padrão html / charset só pode ser confiável com uma definição UTF-8 , mas tenha cuidado! Ele deve ser usado exatamente charset.DetermineEncoding () , pois o método utf8.Valid (b [] byte) nos arquivos codificados utf-16be retorna true .
Própria bicicleta

A detecção automática de codificação é possível apenas por métodos heurísticos imprecisos. Se não soubermos em que idioma e em que codificação o arquivo de texto está gravado, será possível determinar a codificação com alta precisão, mas será difícil ... e você precisará de muito texto.
Para mim, esse objetivo não foi definido. É o suficiente para eu determinar as codificações sob o pressuposto de que existe russo. E, em segundo lugar, você precisa determinar por um pequeno número de caracteres - 10 caracteres devem ter uma definição bastante confiante e, de preferência, 5-6 caracteres em geral.
Algoritmo
Quando descobri a coincidência das codificações KOI8-re CP1251 pela localização do alfabeto, fiquei triste por alguns dias ... ficou claro que tinha que pensar um pouco. Acabou assim.
Principais decisões:
- Trabalharemos com uma fatia de bytes, para compatibilidade com charset.DetermineEncoding ()
- Os casos de codificação UTF-8 e BOM são verificados separadamente
- Os dados de entrada são passados por vez para cada codificação. Cada um calcula dois critérios inteiros. Cuja soma de dois critérios é maior, ele venceu.
Critérios de conformidade
Primeiro critério
O primeiro critério é o número das letras mais populares do alfabeto russo.
As letras mais comuns são: o, e, a, e, n, t, s, p, b, l, k, m, d, p, y . Essas cartas oferecem 82% de cobertura. Para todas as codificações, exceto KOI8-re CP1251, usei apenas as 9 primeiras letras: o, e, a e, n, t, s, p, c. Isso é suficiente para uma determinação confiável.
Mas para o KOI8-re CP1251 eu tive que modificar o arquivo. Os códigos de algumas dessas letras coincidem, por exemplo, a letra o tem o código 0xEE no CP1251, enquanto no KOI8-r esse código tem a letra n . As seguintes cartas populares foram usadas para essas codificações. Para CP1251, usei a, e, n, c, p, b, l, k, i. Para KOI8-r - o, a, u, t, s, b, l, k, m.
Segundo critério
Infelizmente, para casos muito curtos (o comprimento total do texto em russo é de 5 a 6 caracteres), a ocorrência de letras populares é de 1 a 3 peças e há uma sobreposição das codificações KOI8-re CP1251. Eu tive que introduzir um segundo critério. Contagem consoante + vogal .
Espera-se que essas combinações ocorram com mais frequência no idioma russo e, consequentemente, na codificação em que o número desses pares é maior, essa codificação tem um critério maior.
Ambos os critérios são calculados, somados e o valor recebido é o critério final.
O resultado é mostrado na tabela acima.
Recursos que encontrei
Um pequeno toque nos encantos e problemas associados ao golang. A seção pode ser interessante apenas para iniciantes, que escrevem em golang.
Os problemas
Pessoalmente andei por algumas das pedras subaquáticas dos 50 tons de Go: armadilhas, armadilhas e erros comuns de iniciantes .
Excessivamente preocupante e tentando soprar na água, ouvindo outras pessoas sobre as terríveis queimaduras do leite, foi longe demais ao verificar o parâmetro de entrada do tipo io.Reader. Eu verifiquei uma variável como io.Reader com reflexão.
Mas, como aconteceu no meu caso, é suficiente verificar nada. Agora tudo é mais fácil
func CodePageDetect(r io.Reader, stopStr ...string) (IDCodePage, error) {
uma chamada para bufio.NewReader (r) .Peek (ReadBufSize) passa silenciosamente no seguinte teste:
var data *os.File res, err := CodePageDetect(data)
Nesse caso, Peek () retorna um erro.
Uma vez que entrou em um rake com a transferência de matrizes por valor. Um pouco estúpido ao tentar alterar os elementos armazenados no mapa, percorrendo-os ao alcance ...
Delícias
É difícil dizer exatamente se as mãos trêmulas constantes do linter e do compilador ou o uso ativo do intervalo, ou todos juntos, mas praticamente não há incursões para tirar o índice dos limites.
Claro, é muito bom viver com o coletor de lixo. Suponho que ainda tenho que dominar o processo de automatizar a alocação / liberação de memória, mas até agora o sorriso idiota não sai do meu rosto.
Digitação forte também é um pedaço de felicidade.
Variáveis com um tipo de função são, portanto, uma fácil implementação de vários comportamentos para objetos do mesmo tipo.
Estranho pouco teve que sentar no depurador, relendo o código geralmente dá o resultado.
Prazer dos filhotes por ter muitas ferramentas prontas para uso, é uma sensação maravilhosa quando o compilador, a linguagem, a biblioteca e o código do IDE Visual Studio trabalham juntos para você em harmonia.
Obrigado falconandy pelas dicas construtivas e úteis.
Graças a ele
- testes traduzidos no testify e eles realmente se tornaram mais legíveis
- testes fixos para caminhos de arquivo de dados para compatibilidade com Linux
- andou por um linter - mas ele encontrou um erro real (cópia maldita / passado)
Eu continuo adicionando testes, um caso de não definir UTF16 foi revelado. Atualizado. Agora, UTF16 e LE e BE são detectados mesmo na ausência de letras russas