Cubo sobre cubo, metaclusters, células, alocação de recursos
Fig. 1. Ecossistema Kubernetes no Alibaba CloudDesde 2015, o Alibaba Cloud Container Service para Kubernetes (ACK) tem sido um dos serviços de nuvem que mais crescem no Alibaba Cloud. Atende a vários clientes e também suporta a infraestrutura interna do Alibaba e outros serviços em nuvem da empresa.
Como em serviços de contêiner semelhantes de fornecedores de nuvem de classe mundial, nossas principais prioridades são confiabilidade e disponibilidade. Portanto, uma plataforma escalável e acessível globalmente foi criada para dezenas de milhares de clusters Kubernetes.
Neste artigo, compartilharemos nossa experiência no gerenciamento de um grande número de clusters Kubernetes na infraestrutura de nuvem, bem como na arquitetura da plataforma subjacente.
Entrada
O Kubernetes se tornou o padrão de fato para várias cargas de trabalho na nuvem. Como mostrado na fig. 1 no topo, mais e mais aplicativos do Alibaba Cloud agora funcionam em clusters do Kubernetes: são aplicativos com estado / sem estado, bem como gerenciadores de aplicativos. O gerenciamento do Kubernetes sempre foi um tópico de discussão interessante e sério para os engenheiros envolvidos na construção e manutenção da infraestrutura. Quando se trata de provedores de nuvem como o Alibaba Cloud, o dimensionamento vem à tona. Como gerenciar clusters Kubernetes nessa escala? Já falamos sobre práticas recomendadas para gerenciar grandes clusters Kubernetes de 10.000 nós. Obviamente, esse é um problema de escala interessante. Mas há outra escala de escala: o número
de clusters em si .
Discutimos esse tópico com muitos usuários do ACK. A maioria deles prefere executar dezenas, senão centenas, de pequenos ou médios agrupamentos de Kubernetes. Há razões razoáveis para isso: limitar danos potenciais, particionar clusters para diferentes equipes, criar clusters virtuais para teste. Se o ACK procura atender uma audiência global com esse modelo de uso, deve gerenciar de maneira confiável e eficiente um grande número de clusters em mais de 20 regiões.
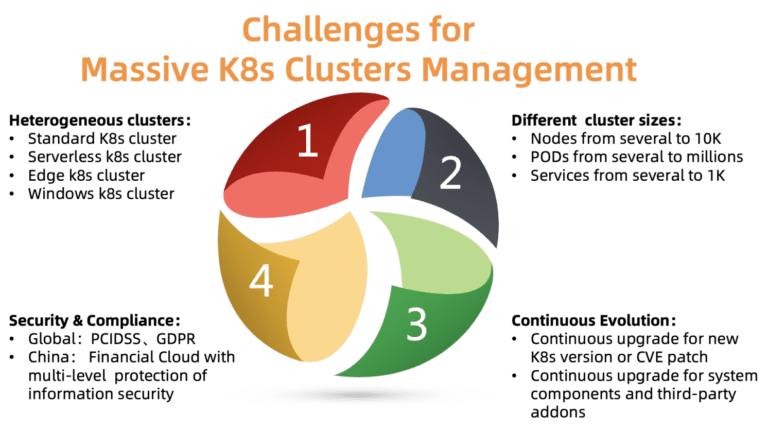 Fig. 2. Desafios de gerenciar um grande número de clusters do Kubernetes
Fig. 2. Desafios de gerenciar um grande número de clusters do KubernetesQuais são os principais problemas do gerenciamento de cluster nessa escala? Como mostra a figura, há quatro questões para lidar:
O ACK deve oferecer suporte a vários tipos de clusters, incluindo padrão, sem servidor, Edge, Windows e outros. Clusters diferentes requerem parâmetros, componentes e modelos de hospedagem diferentes. Alguns clientes precisam de ajuda com a personalização para seus casos específicos.
- Tamanhos de cluster diferentes
Os clusters variam em tamanho: de um par de nós com vários pods a dezenas de milhares de nós com milhares de pods. Os requisitos de recursos também são muito diferentes. A alocação inadequada de recursos pode afetar o desempenho ou até levar à falha.
Kubernetes está crescendo rapidamente. Novas versões são lançadas a cada poucos meses. Os clientes estão sempre prontos para experimentar novos recursos. Portanto, eles desejam colocar a carga de teste em novas versões do Kubernetes e a carga de trabalho em versões estáveis. Para atender a esse requisito, o ACK deve fornecer continuamente novas versões do Kubernetes aos seus clientes, mantendo versões estáveis.
- Conformidade de segurança
Os clusters são distribuídos em diferentes regiões. Portanto, eles devem cumprir vários requisitos de segurança e regulamentos oficiais. Por exemplo, um cluster na Europa deve obedecer ao GDPR e uma nuvem financeira na China deve ter níveis adicionais de proteção. Esses requisitos são obrigatórios, é inaceitável ignorá-los, pois isso cria enormes riscos para os clientes da plataforma em nuvem.
A plataforma ACK foi projetada para resolver a maioria dos problemas acima. Atualmente, gerencia de forma confiável e estável mais de 10 mil clusters Kubernetes em todo o mundo. Vamos ver como conseguimos isso, inclusive devido a vários princípios fundamentais de design / arquitetura.
Desenho
Cubo sobre cubo e favos de mel
Diferentemente de uma hierarquia centralizada, a arquitetura baseada em célula é normalmente usada para dimensionar uma plataforma além de um único data center ou para expandir o escopo da recuperação de desastres.
Cada região na nuvem Alibaba consiste em várias zonas (AZ) e geralmente corresponde a um data center específico. Em uma grande região (como Huangzhou), milhares de clusters de clientes Kubernetes executando o ACK são frequentemente encontrados.
O ACK gerencia esses clusters Kubernetes usando o próprio Kubernetes, ou seja, temos o metacluster Kubernetes para gerenciar clusters de clientes Kubernetes. Essa arquitetura também é chamada de “cubo-em-cubo” (kube-on-kube, KoK). A arquitetura KoK simplifica o gerenciamento de clusters de clientes à medida que a implantação de um cluster se torna simples e determinística. Mais importante, podemos reutilizar os recursos do Kubernetes nativo. Por exemplo, gerenciando servidores API através da implementação, usando o operador etcd para gerenciar vários etcd. Essa recursão sempre traz prazer particular.
Na mesma região, vários metaclusters do Kubernetes são implantados, dependendo do número de clientes. Esses metaclusters chamamos células. Para se proteger contra a falha de uma região inteira, o ACK suporta implantações multi-ativas em uma região: o metacluster distribui os componentes do assistente de cluster do cliente Kubernetes em várias zonas e os inicia simultaneamente, ou seja, no modo multi-ativo. Para garantir a confiabilidade e a eficácia do assistente, o ACK otimiza o posicionamento dos componentes e garante que o servidor de API e etcd estejam próximos um do outro.
Este modelo permite gerenciar de forma eficaz, flexível e confiável o Kubernetes.
Planejamento de recursos de metacluster
Como já mencionamos, o número de metaclusters em cada região depende do número de clientes. Mas em que momento você adiciona um novo metacluster? Esse é um problema típico de planejamento de recursos. Como regra, é habitual criar um novo quando os metaclusters existentes esgotarem todos os seus recursos.
Veja os recursos de rede, por exemplo. Na arquitetura KoK, os componentes Kubernetes dos clusters de clientes são implantados como pods no metacluster. Usamos o
Terway (Fig. 3), um plug-in de alto desempenho desenvolvido pela Alibaba Cloud para gerenciamento de rede de contêineres. Ele fornece um rico conjunto de políticas de segurança e permite que você se conecte a clientes de nuvem virtual privada (VPC) por meio do Alibaba Cloud Elastic Networking Interface (ENI). Para distribuir com eficiência recursos de rede entre nós, pods e serviços em um metacluster, devemos monitorar cuidadosamente seu uso dentro de um metacluster a partir de nuvens privadas virtuais. Quando os recursos de rede chegam ao fim, uma nova célula é criada.
Para determinar o número ideal de clusters de clientes em cada metacluster, também levamos em conta nossos custos, requisitos de densidade, cota de recursos, requisitos de confiabilidade e dados estatísticos. A decisão de criar um novo metacluster é tomada com base em todas essas informações. Observe que pequenos clusters podem se expandir muito no futuro, portanto, o consumo de recursos aumenta mesmo com o mesmo número de clusters. Geralmente deixamos espaço livre suficiente para o crescimento de cada cluster.
 Fig. 3. Arquitetura de rede Terway
Fig. 3. Arquitetura de rede TerwayDimensionando componentes do assistente em clusters de clientes
Os componentes do assistente têm requisitos de recursos diferentes. Eles dependem do número de nós e pods no cluster, o número de controladores / operadores não padrão interagindo com o APIServer.
No ACK, cada cluster de clientes Kubernetes tem diferentes requisitos de tamanho e tempo de execução. Não há configuração universal para hospedar componentes do assistente. Se definirmos por engano um limite baixo de recursos para um cliente grande, o cluster dele não suportará a carga. Se você definir um limite conservadoramente alto para todos os clusters, os recursos serão desperdiçados.
Para encontrar um compromisso sutil entre confiabilidade e custo, o ACK usa um sistema de tipos. Ou seja, definimos três tipos de clusters: pequeno, médio e grande. Cada tipo tem um perfil de alocação de recursos separado. O tipo é determinado com base no carregamento dos componentes do assistente, no número de nós e em outros fatores. O tipo de cluster pode mudar com o tempo. O ACK monitora constantemente esses fatores e pode aumentar / diminuir o tipo. Após alterar o tipo de cluster, a distribuição de recursos é atualizada automaticamente com o mínimo de intervenção do usuário.
Estamos trabalhando para melhorar esse sistema em termos de escala mais refinada e atualizações de tipo mais precisas, para que essas alterações ocorram de maneira mais suave e façam mais sentido econômico.
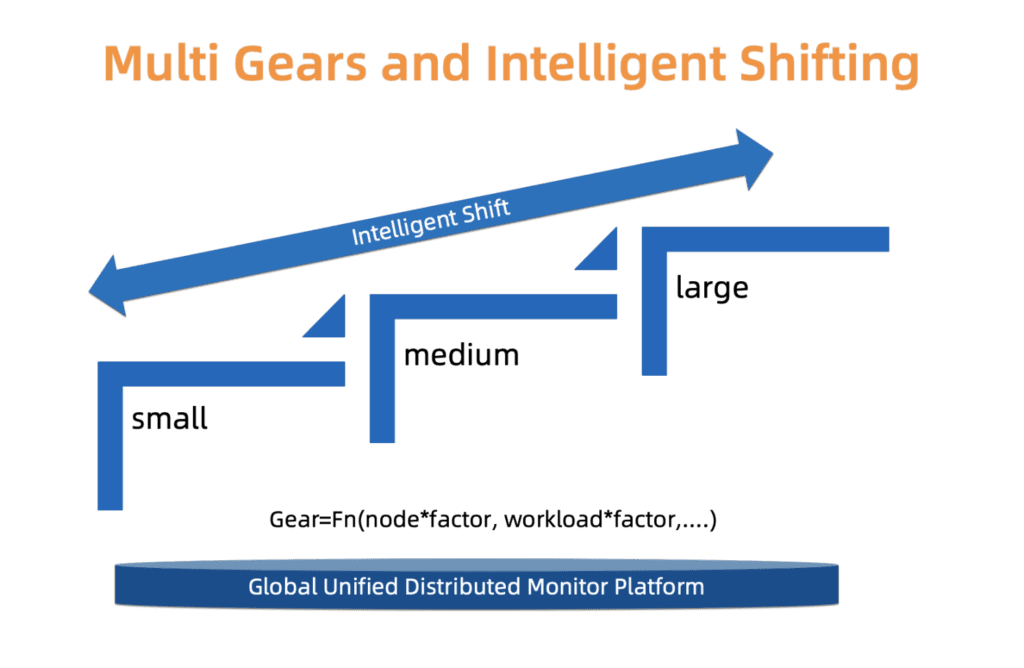 Fig. 4. Comutação inteligente do tipo multiestágio
Fig. 4. Comutação inteligente do tipo multiestágioA evolução dos clusters de clientes em uma escala
As seções anteriores descreveram alguns aspectos do gerenciamento de um grande número de clusters Kubernetes. No entanto, há outro problema que precisa ser resolvido: evolução do cluster.
O Kubernetes é o Linux no mundo das nuvens. É atualizado continuamente e se torna mais modular. Devemos fornecer constantemente a nossos clientes novas versões, corrigir vulnerabilidades e atualizar clusters existentes, além de gerenciar um grande número de componentes relacionados (CSI, CNI, Plug-in de Dispositivo, Plug-in de Agendador e muitos outros).
Tome o gerenciamento de componentes do Kubernetes como um exemplo. Para começar, desenvolvemos um sistema centralizado de registro e gerenciamento para todos esses componentes de plug-in.
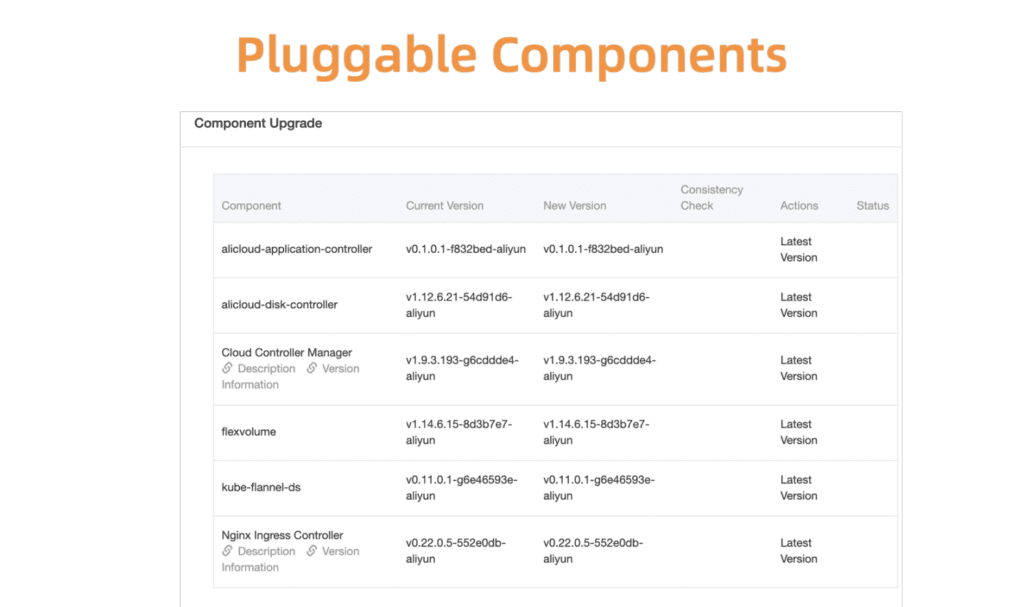 Fig. 5. Componentes flexíveis e plug-in
Fig. 5. Componentes flexíveis e plug-inAntes de prosseguir, você precisa garantir que a atualização seja bem-sucedida. Para isso, desenvolvemos um sistema de verificação de integridade de componentes. A validação é realizada antes e depois da atualização.
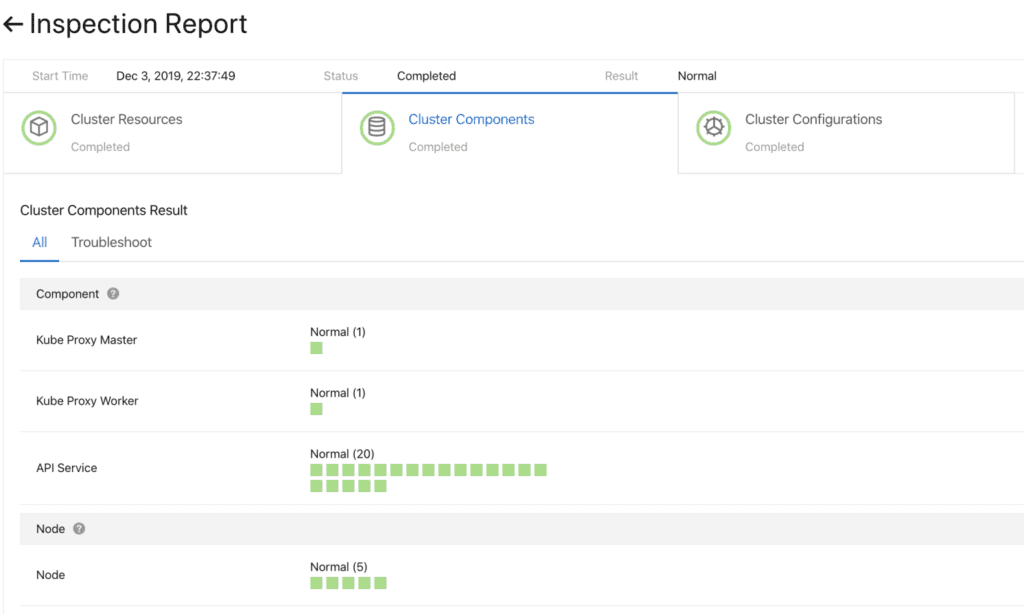 Fig. 6. Verificação preliminar dos componentes do cluster
Fig. 6. Verificação preliminar dos componentes do clusterPara atualizar esses componentes de maneira rápida e confiável, um sistema de implantação contínua trabalha com suporte para promoção parcial (escala de cinza), pausas e outras funções. Os controladores Kubernetes padrão não são adequados para esse uso. Portanto, para gerenciar os componentes do cluster, desenvolvemos um conjunto de controladores especializados, incluindo um plug-in e um módulo de controle auxiliar (gerenciamento de carro lateral).
Por exemplo, o controlador BroadcastJob foi projetado para atualizar componentes em cada máquina em funcionamento ou para verificar nós em cada máquina. O trabalho Broadcast executa um pod em todos os nós do cluster, como um DaemonSet. No entanto, o DaemonSet sempre suporta a operação contínua do pod, enquanto o BroadcastJob o minimiza. O controlador Broadcast também inicia pods nos nós recém-conectados e inicializa os nós com os componentes necessários. Em junho de 2019, abrimos o código-fonte para o mecanismo de automação OpenKruise, que nós mesmos usamos dentro da empresa.
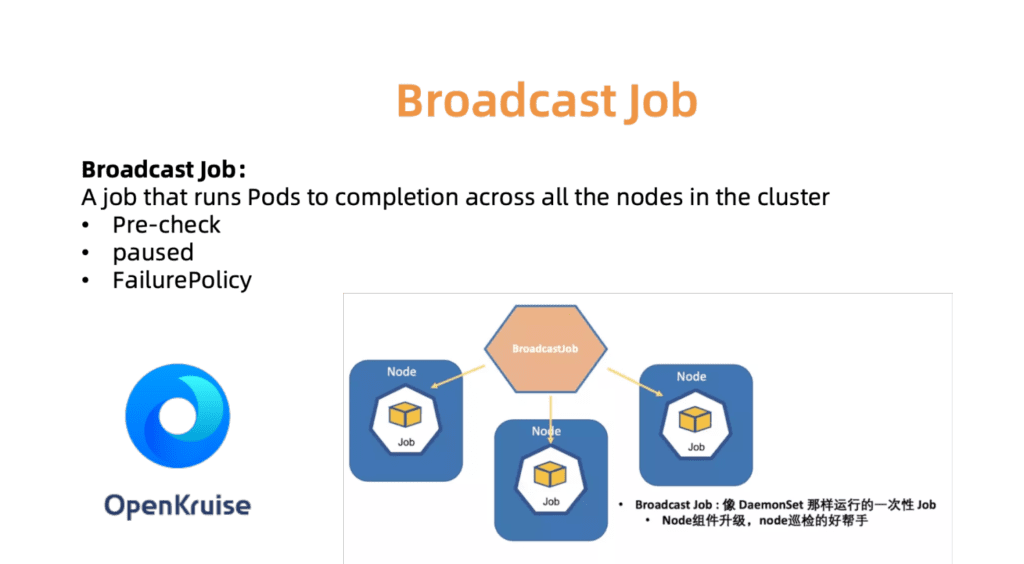 Fig. 7. O OpenKurise organiza atribuições de transmissão em todos os sites.
Fig. 7. O OpenKurise organiza atribuições de transmissão em todos os sites.Para ajudar os clientes a escolher as configurações corretas de cluster, também fornecemos um conjunto de perfis predefinidos, incluindo perfis sem servidor, borda, Windows e Bare Metal. À medida que o cenário se expande e as necessidades de nossos clientes aumentam, adicionaremos mais perfis para simplificar o processo de configuração tedioso.
 Fig. 8. Perfis de cluster avançados e flexíveis para diferentes cenários
Fig. 8. Perfis de cluster avançados e flexíveis para diferentes cenáriosObservabilidade global do data center
Como mostrado abaixo na fig. 9, Alibaba Cloud Container é implantado em vinte regiões do mundo. Dada essa escala, uma das principais tarefas do ACK é monitorar facilmente o status dos clusters em execução: se o cluster do cliente encontrar um problema, poderemos responder rapidamente à situação. Em outras palavras, você precisa criar uma solução que permita coletar de maneira eficiente e segura estatísticas em tempo real de clusters de clientes em todas as regiões - e apresentar visualmente os resultados.
 Fig. 9. Implantação global do serviço Alibaba Cloud Container em vinte regiões
Fig. 9. Implantação global do serviço Alibaba Cloud Container em vinte regiõesComo em muitos sistemas de monitoramento Kubernetes, temos o Prometheus como nossa principal ferramenta. Para cada metacluster, os agentes do Prometheus coletam as seguintes métricas:
- Métricas do sistema operacional, como recursos do host (processador, memória, disco etc.) e largura de banda da rede.
- Métricas para o sistema de gerenciamento de metacluster e cluster de clientes, como o kube-apiserver, o kube-controller-manager e o kube-scheduler.
- Métricas de kubernetes-state-metrics e cadvisor.
- Métricas Etcd, como tempo de gravação em disco, tamanho do banco de dados, taxa de transferência entre nós, etc.
As estatísticas globais são coletadas usando um modelo de agregação multicamada típico. Os dados de monitoramento de cada metacluster são agregados primeiro em cada região e depois enviados para um servidor central, o que mostra o cenário geral. Tudo funciona através do mecanismo de federação. O servidor Prometheus em cada data center coleta as métricas desse data center, e o servidor central Prometheus é responsável por agregar dados de monitoramento. O AlertManager se conecta ao Prometheus central e, se necessário, envia alertas via DingTalk, email, SMS, etc. Visualização - usando o Grafana.
Na Figura 10, o sistema de monitoramento pode ser dividido em três níveis:
A camada mais distante do centro. O Prometheus Edge Server é executado em cada metacluster, coletando métricas de clusters de meta e cliente no mesmo domínio de rede.
A função da camada em cascata do Prometheus é coletar dados de monitoramento de várias regiões. Esses servidores operam no nível de unidades geográficas maiores, como China, Ásia, Europa e América. À medida que os clusters crescem em uma região, ele pode ser dividido e, em seguida, um servidor Prometheus em nível de cascata aparecerá em cada nova região grande. Com essa estratégia, você pode dimensionar perfeitamente, conforme necessário.
O servidor central do Prometheus se conecta a todos os servidores em cascata e executa a agregação final de dados. Para confiabilidade, duas instâncias centrais do Prometheus conectadas aos mesmos servidores em cascata foram geradas em zonas diferentes.
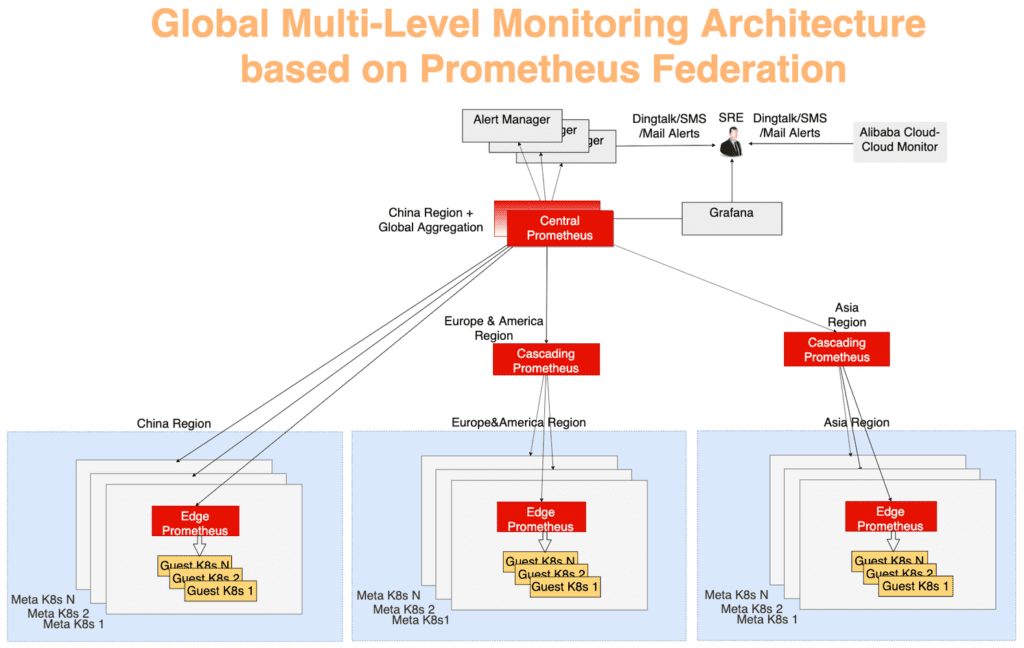 Fig. 10. Arquitetura global de monitoramento multicamada com base no mecanismo de federação Prometheus
Fig. 10. Arquitetura global de monitoramento multicamada com base no mecanismo de federação PrometheusSumário
As soluções em nuvem baseadas em Kubernetes continuam a transformar nosso setor. O Alibaba Cloud Container Service fornece hospedagem segura, confiável e de alto desempenho - este é um dos melhores serviços de hospedagem em nuvem da Kubernetes. A equipe do Alibaba Cloud acredita firmemente nos princípios do código aberto e da comunidade de código aberto. Definitivamente, continuaremos compartilhando nosso conhecimento no campo de operação e gerenciamento de tecnologias em nuvem.