
Olá Habr!
Férias de Ano Novo são um ótimo momento para faça uma pausa na TI Use habilidades profissionais em seu hobby favorito. Vasculhando o site da classificação esportiva ChGK , encontrei uma excelente API que permite obter dados sobre todos os jogos de todos os torneios. Então, tive a ideia de criar um gráfico da comunidade de especialistas e testar a teoria de seis apertos de mão em uma comunidade geograficamente dispersa e estritamente offline. Sob imagens katom de gráficos e estatísticas inúteis.
Para começar, um breve programa educacional, o que é esportes ChGK.
O que é esportes ChGK
Tenho certeza de que, com a versão televisiva de "O quê? Onde Quando? ”O leitor está familiarizado com o topo e as letras dos telespectadores. O Sports ChGK é uma extensão do formato de televisão que permite que várias equipes joguem simultaneamente.
No café, na casa dos jovens, na sala de reuniões da universidade, várias equipes de até seis pessoas se reúnem. O anfitrião lê as perguntas, um minuto é dado para reflexão. No final do minuto, a equipe registra a resposta à forma do jogo e levanta. Pessoas especialmente treinadas, chamadas andorinhas, coletam papel. Normalmente, 36 perguntas são lidas por jogo, divididas em três rodadas. Quem respondeu acima de tudo, que bem feito.
Existem muitos torneios no ChGK, há até campeonatos europeu e mundial. Estou enviando os curiosos a uma fonte respeitável de informações . E exemplos de perguntas podem ser encontrados aqui .
Recuperação de dados
Assumimos que os jogadores estejam familiarizados se jogaram pelo menos uma vez em uma mesa de jogo. Graças à boa API, o download de dados sobre todos os torneios e equipes não é um problema.
Sob os spoilers, nem mesmo a Beautiful Soup é usada, apenas solicitações. Um caderno de anotações com todo o código-fonte estará no final do artigo.
Baixar dados para todos os torneiosurl = 'https://rating.chgk.info/api/tournaments.json/?page={}' df = pd.DataFrame(columns=['name', 'start']) for i in range(1, 7): data = requests.get(url.format(i)).json() for item in data["items"]: df.loc[item["idtournament"]] = (item["name"], item["date_start"]) df.to_csv('tournaments.csv')
Resta fazer o download das listas de jogos de todos os torneios e lembrar de todos os conhecidos. Inicialmente, planejei armazenar os fatos de um jogo conjunto em um DataFrame, mas a velocidade de adicionar novos registros era deprimente. Portanto, definiremos a partir de tuplas (id1, id2), onde id1, id2 são os identificadores de jogadores que estão familiarizados. Ao mesmo tempo, livre-se das duplicatas.
Fazendo o download de composições e conhecendo df = pd.read_csv('tournaments.csv').set_index('Unnamed: 0') url = 'https://rating.chgk.info/api/tournaments/{}/recaps.json' links = set() for id in df.index: teams = requests.get(url.format(id)).json() for team in teams: t = team["recaps"] for i in range(len(t)): for j in range(i + 1, len(t)): first = int(t[i]["idplayer"]) second = int(t[j]["idplayer"]) if first < second: links.add((first, second)) else: links.add((second, first))
Obter um gráfico e explorar componentes conectados
Então, a preparação dos dados terminou, é hora de criar um gráfico! Para fazer isso, usaremos a biblioteca networkx , cujos recursos são suficientes para o nosso cluster.
players = itertools.chain(*links) G = nx.Graph() G.add_nodes_from(players) for t in links: G.add_edge(*t) print(nx.info(G))
Agora, existem cerca de duzentas mil pessoas na comunidade ChGK e, em média, um especialista em uma carreira jogou com 12 pessoas:
Number of nodes: 198145 Number of edges: 1206076 Average degree: 12.1737
É hora de descobrir quantos componentes conectados existem no gráfico de namoro. O Networkx tem uma excelente função chamada connector_components que faz exatamente o que você precisa:
clusters_l = [len(c) for c in sorted(nx.connected_components(G), key=len, reverse=True)] print(clusters_l[:20])
Quase três quartos dos jogadores estão em um componente conectado, o restante é dividido em subgráficos muito pequenos. Existem mais de oito mil deles.
[145922, 153, 124, 74, 72, 56, 50, 47, 42, 40, 39, 39, 38, 38, 37, 36, 36, 36, 36, 35]
Mesmo em uma escala logarítmica, a dominância do componente principal parece impressionante. No eixo X - o número do componente do maior para o menor, no eixo Y - seu tamanho (o eixo logarítmico).

O que causou uma distribuição tão desigual de pessoas nos componentes conectados? Na minha opinião, o ponto é o seguinte:
- um pequeno grupo de pessoas entra no jogo pela primeira vez e, assim, forma um pequeno grupo para 4-6 pessoas;
- se a cidade já tem uma comunidade grande, esse agrupamento se fundirá muito rapidamente com o principal - apenas uma pessoa precisa jogar para uma equipe do agrupamento principal;
- se na cidade de ChGK aparecer, o cluster viverá mais, porque jogar para uma equipe do cluster principal é mais difícil.
O processo se assemelha à formação de gotas de chuva nas nuvens: uma grande queda atrai pequenas e cresce rapidamente.
Antes de lidar com o componente principal, vejamos os componentes no primeiro ou no nono lugar (considero o componente principal como zero). Testamos a hipótese de que as pessoas nesses componentes são da mesma cidade. O conhecedor não tem apego à cidade (o que é lógico em nosso mundo moderno). No entanto, você pode olhar para o porto de origem do time pelo qual ele jogou pela última vez
Código de estatísticas da cidade for i in range(1, 10): _g = list(sorted(nx.connected_components(G), key=len, reverse=True)[i]) s = pd.Series() p_url = 'https://rating.chgk.info/api/players/{}/tournaments.json' t_url = 'https://rating.chgk.info/api/teams/{}.json' for player in _g: data = requests.get(p_url.format(player)).json() for item in data: team_id = data[item]["tournaments"][0]["idteam"] data = requests.get(t_url.format(team_id)).json() town = data[0]["town"] s.at[len(s)] = town print(' #{}'.format(i)) print(s.value_counts())
Placa de resumo:
Sim, pequenos grupos são quase inteiramente de uma cidade. Por favor, preste atenção ao componente de setenta e dois residentes de Tambov, que está associado ao Luxemburgo. No sétimo e nono lugar estão os componentes de Gorno-Altaysk, que por algum motivo não estão interconectados. Imagino prontamente a luta de dois clãs ChGK-ash, como Montecca e Capulet, que estão lutando pelo controle da cidade.
Suponho que, no futuro próximo, esses componentes se fundam nas principais mas continuará lutando .
O principal componente da conectividade
Então, chegamos ao componente principal. Obteremos o subgráfico desejado e veremos suas estatísticas:
subgraph_v = list(sorted(nx.connected_components(G), key=len, reverse=True)[0]) subgraph = G.subgraph(subgraph_v) print(nx.info(subgraph))
O número médio de conexões acabou sendo maior.
Number of nodes: 145922 Number of edges: 1070504 Average degree: 14.6723
E qual é o número máximo de conexões por jogador?
for t in sorted(G.degree, key=lambda x: x[1], reverse=True)[:10]: print(' {} {} '.format(t[0], t[1]))
42511 818 15051 798 29800 678 23020 666 16581 662 5328 657 29887 651 15811 645 30352 605 1055 602
Francamente, estou um pouco chocado com os números. Se você jogar com um novo time de cada vez, precisará de 818/5 × 164 jogos para chegar ao primeiro lugar. Incrível.
Lembraremos dos dois primeiros especialistas nesta classificação e usaremos suas habilidades de comunicação ainda mais.
Vamos estimar quantos conhecidos mais próximos um especialista médio possui:
Obtendo dados e plotando _count = 50 values = nx.degree_histogram(subgraph) plt.figure(figsize=(16, 8), dpi=80) plt.plot(range(_count),values[:_count],'ro-')
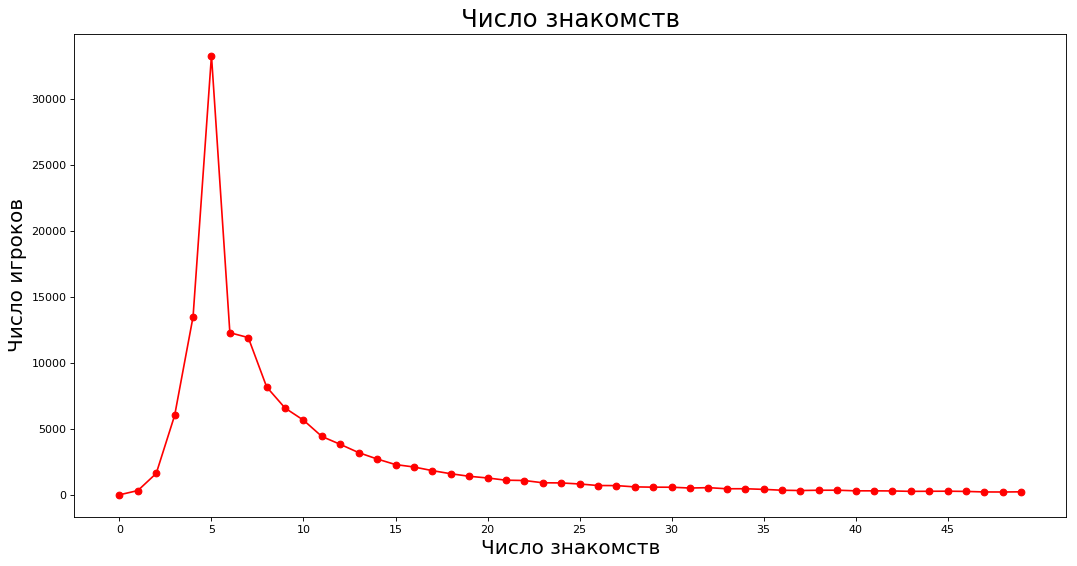
No eixo X - o número de conhecidos mais próximos, no eixo Y - o número de especialistas que possui o número correspondente de conhecidos. Por exemplo, aproximadamente 40.000 especialistas têm cinco conhecidos.
Observe que a moda tem 5 conhecidos (é engraçado que até seis pessoas possam estar na mesa). Ao mesmo tempo, a média aritmética do número de conhecidos é 14,67 e a mediana é 7. O fato é que os cavalheiros da classificação acima superestimam muito a média. Se cem pessoas não jogam no ChGK e um tem 800 conhecidos, então, em média, jogam no ChGK.
Distâncias para Jogadores
Porque Contar o diâmetro desse gráfico é um pouco difícil , vamos facilitar: faça uma lista de vários jogadores e encontre o máximo das distâncias mais curtas deles para outros especialistas. Como esses jogadores, peguei vários especialistas conhecidos, eu mesmo, um jogador aleatório e dois especialistas com o maior número de conhecidos (veja a classificação acima). Aqui está o que aconteceu:
famous_players = {9808: ' ', 5195: ' ', 25882: ' ', 29333: ' ', 118622: ' ', 42511: ' ', 15051: ' ', 118621: ' '} for key in famous_players: print('{}: {} - ' .format(famous_players[key], nx.eccentricity(subgraph, v=key)))
: 12 - : 12 - : 12 - : 12 - : 13 - : 12 - : 13 - : 13 -
Acontece que uma formulação forte da teoria dos seis apertos de mão (duas pessoas são separadas por não mais que cinco níveis de amigos em comum) está incorreta. O diâmetro do gráfico é provavelmente 13-14.
Que tal uma redação mais fraca (duas pessoas, em média, são separadas por não mais que cinco níveis de amigos em comum)?
for key in famous_players: paths = nx.shortest_path_length(subgraph, source=key).values() print('{}: {} - ' .format(famous_players[key], sum(paths) / len(paths)))
: 3.941461876893135 - : 3.7971107852140182 - : 3.89353216101753 - : 3.8634887131481204 - : 4.1443373857266215 - : 3.575478680390894 - : 3.608674497334192 - : 4.564102739819904 -
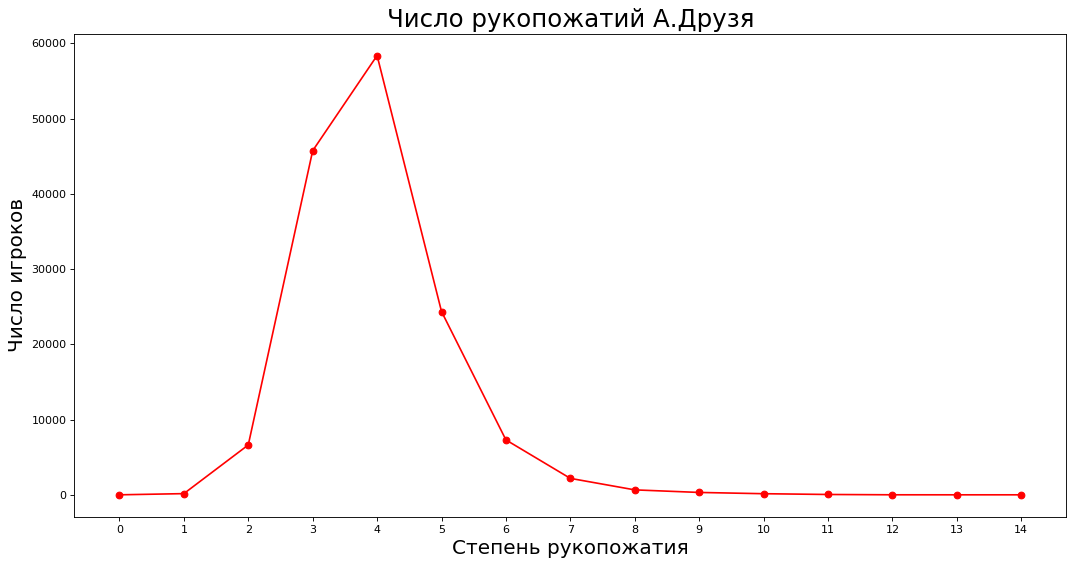
Se afrouxarmos a redação, a teoria será cumprida - em média, entre especialistas em 4-5 níveis de conhecimento. Traçamos quantas pessoas estão familiarizadas com o conhecedor aleatório A. Druzem diretamente, através de um, dois, etc. conhecedores.
Obtendo dados e plotando paths = nx.shortest_path_length(subgraph, source=9808) neighbours = [0] * 15 for k in paths: neighbours[paths[k]] += 1 _count = 15 plt.figure(figsize=(16, 8), dpi=80) plt.plot(range(_count),neighbours[:_count],'ro-')
No eixo X, o grau de familiaridade com A. Druzem (diretamente, através de um, dois, etc.), no eixo Y, o número de especialistas que estão familiarizados com A. Druzem dessa maneira.
Gráficos sociais
Porque criar um gráfico para quase 200 mil pessoas não é uma boa ideia, vamos facilitar: criaremos o componente de conectividade Kerch e um gráfico de pessoas associadas ao autor.
Componente Kerch
little_v = list(sorted(nx.connected_components(G), key=len, reverse=True)[1]) little = G.subgraph(little_v) plt.figure(figsize=(24, 12), dpi=200) pos = nx.kamada_kawai_layout(little) nx.draw(little, pos=pos, node_size=100, edge_color='gray', node_color=[val for (node, val) in little.degree()], cmap=plt.cm.jet) plt.show()

Você pode ver a separação dos componentes em equipes. Além disso, as equipes estão interconectadas com a ajuda, em regra, de um ou dois conhecedores sociáveis. No centro, há um núcleo pequeno de especialistas que jogou com um grande número de outros jogadores.
Contagem de uma pessoa
Encontraremos os conhecidos mais próximos de uma pessoa e veremos como eles estão relacionados. Para simplificar o gráfico, não adicionaremos a própria pessoa (ela já está conectada a todos)
id = 118622 ego_graph = [n for n in G.neighbors(id)]

O gráfico é muito mais denso, é possível distinguir um núcleo de 10 a 15 pessoas que estão familiarizadas. O tamanho máximo do clique é 13.
Conclusão
- É muito mais difícil conhecer uma pessoa no ChGK esportivo do que em uma rede social; você precisa ficar offline e jogar pelo menos um torneio. Ao mesmo tempo, especialistas estão espalhados por todo o mundo. No entanto, a distância média entre especialistas é de fato inferior a cinco.
- O site de classificação usa o número Snyatkovsky , que é um análogo do número Erdös no mundo do ChGK. O próprio Sr. Snyatkovsky ocupa o terceiro lugar em nosso ranking dos conhecedores mais sociáveis.
- Código de um artigo no meu github .
- Por comentários valiosos, o autor é grato ao White Noise e Who Framed Roger Federer, Mikhail Akulov, Vera Terentyeva e Firemoon .