Neste artigo, quero compartilhar minha experiência no uso desta biblioteca de código aberto no exemplo da implementação de uma tarefa com a análise de
arquivos PDF / DOC / DOCX contendo currículos de especialistas.
Aqui também descreverei os estágios da implementação da ferramenta para preparar o conjunto de dados. Em seguida, será possível treinar o modelo
BERT no conjunto de dados recebido como parte da tarefa de reconhecer entidades a partir de textos (
Reconhecimento de Entidades Nomeadas - doravante
NER ).
Então, por onde começar. Naturalmente, primeiro você precisa instalar e configurar o ambiente para executar nossa ferramenta. Eu instalarei no
Windows 10 .
No Habré já existem vários artigos dos desenvolvedores desta biblioteca, onde há apenas um guia de instalação detalhado. E neste artigo, eu gostaria de juntar tudo, do lançamento ao treinamento do modelo. Também indicarei soluções para alguns dos problemas que encontrei ao trabalhar com esta biblioteca.
IMPORTANTE: ao instalar, é importante cumprir as versões de todos os produtos e componentes, pois geralmente há problemas com versões incompatíveis. Isto é especialmente verdade na biblioteca TensorFlow . Até acontece que, para algumas tarefas, até o commit necessário no GitHub, você precisa usá-lo. No caso do DeepPavlov , a conformidade apenas com a versão suportada é suficiente.
Vou indicar as versões do produto da configuração de trabalho e as especificações do meu laptop em que iniciei o processo de treinamento da rede neural. Fornecerei alguns links que também descrevem a instalação e a configuração da biblioteca
DeepPavlov de código
aberto .
Links úteis de desenvolvedores do DeepPavlov
Versões de componentes para instalação
- Python 3.6.6 - 3.7
- Comunidade do Visual Studio 2017 (opcional)
- Ferramentas de compilação do Visual C ++ 14.0.25420.1
- nVIDIA CUDA 10.0.130_411.31_win10
- cuDNN-10.0-windows10-x64-v7.6.5.32
Configurando o ambiente para suporte à GPU
- Instale o Python ou o Visual Studio Community 2017 incluído no Python . Na minha instalação, usei o segundo método, instalando a Comunidade do Visual Studio com suporte ao Python .
Claro, você precisa adicionar manualmente o caminho à pastaC:\Program Files (x86)\Microsoft Visual Studio\Shared\Python36_64
para a variável de sistema PATH , em que o Python está instalado no Visual Studio, mas isso não é um problema para mim, é importante saber que instalei uma versão para o Python .
Mas este é o meu caso, você pode instalar tudo separadamente. - A próxima etapa é instalar as ferramentas de criação do Visual C ++ .
- Em seguida, instale o nVIDIA CUDA .
IMPORTANTE: se a biblioteca nVIDIA CUDA foi instalada anteriormente, você deve remover todos os componentes instalados anteriormente da nVIDIA, até o driver de vídeo. E somente então, em uma instalação limpa do driver de vídeo, execute a instalação do nVIDIA CUDA .
- Agora instale o cuDNN para o nVIDIA CUDA .
Para fazer isso, você precisa se registrar para ser membro do NVIDIA Developer Program (é grátis).

- Faça o download da versão cuDNN para CUDA 10.0

- Descompacte o arquivo em uma pasta
C:\Users\<_>\Downloads\cuDNN
- Copie todo o conteúdo da pasta .. \ cuDNN para a pasta em que instalamos o CUDA
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0
- Reinicie o computador. Opcional, mas eu recomendo.
Instale o DeepPavlov
- Crie e ative o ambiente virtual Python .
IMPORTANTE: Fiz isso através do Visual Studio.
- Para isso, criei um novo projeto para o código From Existing Python .

- Pressionamos mais a última janela, mas em Concluir não clicamos ainda. Você deve desmarcar a opção " Detectar ambientes virtuais "

- Clique em Finish .
- Agora você precisa criar um ambiente virtual.

- Deixamos tudo por padrão.

- Abra a pasta do projeto na linha de comando. E execute o comando:
.\env\Scripts\activate.bat

- Agora tudo está pronto para instalar o DeepPavlov . Nós executamos o comando:
pip install deeppavlov
- Em seguida, você precisa instalar o TensorFlow 1.14.0 com suporte à GPU . Para fazer isso, execute o comando:
pip install tensorflow-gpu==1.14.0
- Quase tudo está pronto. Você só precisa ter certeza de que o TensorFlow utilizará a placa gráfica para cálculos. Para fazer isso, escrevemos um script simples devices.py , o seguinte conteúdo:
from tensorflow.python.client import device_lib print(device_lib.list_local_devices())
ou tensorflow_test.py :
import tensorflow as tf tf.test.is_built_with_cuda() tf.test.is_gpu_available(cuda_only=False, min_cuda_compute_capability=None)
- Depois de executar o devices.py , devemos ver algo como o seguinte:
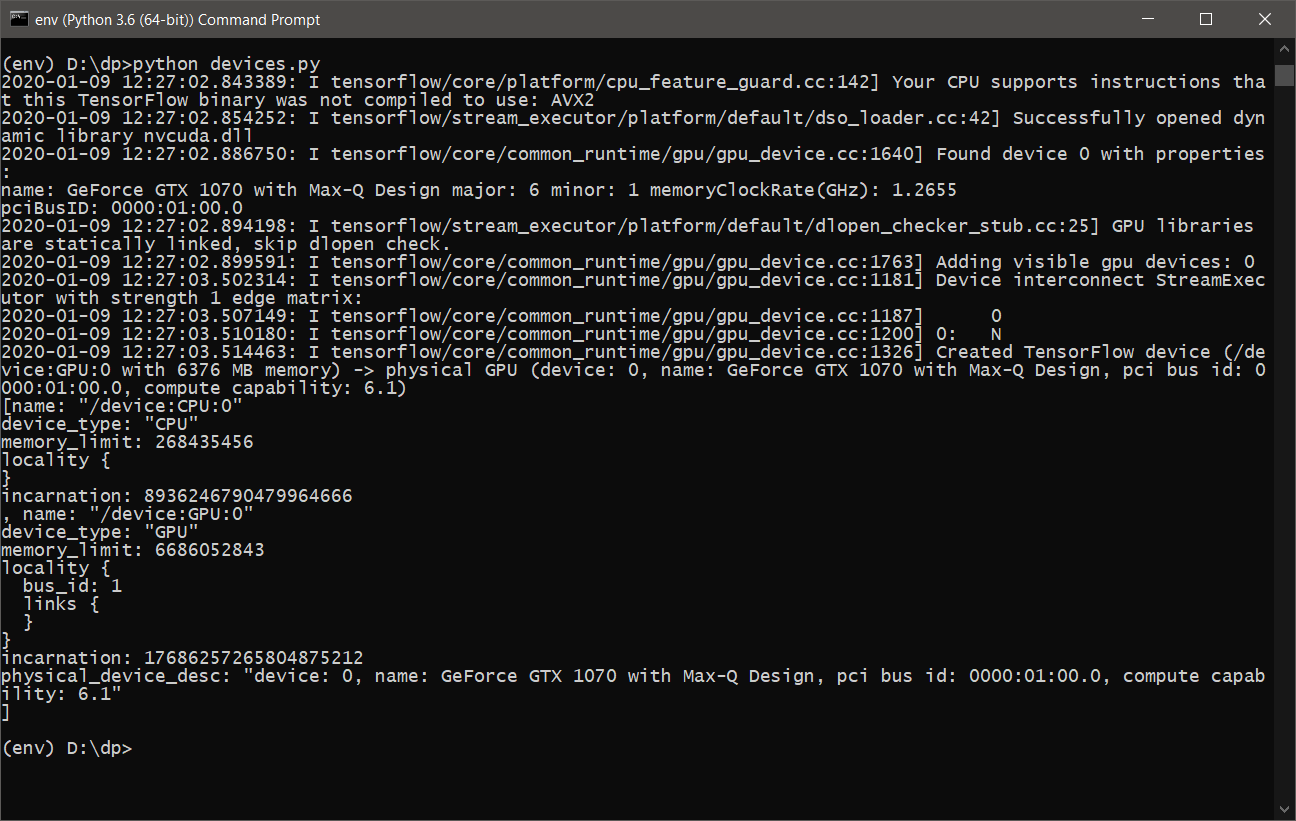
- Agora você está pronto para aprender e usar o DeepPavlov com suporte a GPU .
DeepPavlov na API REST
Para iniciar e instalar o serviço para a API REST, você precisa executar os seguintes comandos:
- Instalar em um ambiente virtual ativo
python -m deeppavlov install ner_ontonotes_bert_mult
- Faça o download do modelo ner_ontonotes_bert_mult dos servidores DeepPavlov
python -m deeppavlov download ner_ontonotes_bert_mult
- Executar API REST
python -m deeppavlov riseapi ner_ontonotes_bert_mult -p 5005
Este modelo estará disponível em
http: // localhost: 5005 . Você pode especificar sua porta.
Todos os modelos serão baixados por padrão ao longo do caminho.
C:\Users\<_>\.deeppavlov
Configurando o DeepPavlov para treinamento
Antes de iniciar o processo de aprendizado, precisamos configurar o
DeepPavlov para que o processo de aprendizado não "travar" com um erro de que a memória da nossa placa de vídeo está cheia. Para isso, temos arquivos de configuração para cada modelo.
Como no exemplo dos desenvolvedores, também vou usar o modelo
ner_ontonotes_bert_mult . Todas as configurações padrão do
DeepPavlov estão localizadas ao longo do caminho:
<_>\env\Lib\site-packages\deeppavlov\configs\ner
No meu caso, o arquivo será nomeado como o modelo
ner_ontonotes_bert_mult.json .
Para a configuração do meu laptop, tive que alterar o valor
batch_size no bloco de
trem para 4.

Caso contrário, minha placa de vídeo "engasgou" depois de alguns minutos e o processo de aprendizado caiu com um erro.
Configuração Nobook
- Modelo: MSI GS-65
- Processador: Core i7 8750H 2200 MHz
- A quantidade de memória instalada: 32 GB DDR-4
- Disco Rígido: SSD de 512 GB
- Placa de vídeo: GeForce GTX 1070 8192 Mb
Ferramenta de preparação de conjunto de dados
Para treinar o modelo, você precisa preparar um conjunto de dados. O conjunto de dados consiste em três arquivos
train.txt ,
valid.txt ,
test.txt . Com uma discriminação dos dados no seguinte percentual de trem - 80%, válido e teste para 10%.
O conjunto de dados para o modelo BERT é o seguinte:
Ivan B-PERSON Ivanov I-PERSON Senior B-WORK_OF_ART Java I-WORK_OF_ART Developer I-WORK_OF_ART IT B-ORG - I-ORG Company I-ORG Key O duties O : 0 Java B-WORK_OF_ART Python B-WORK_OF_ART CSS B-WORK_OF_ART JavaScript B-WORK_OF_ART Russian B-LOC Federation I-LOC . O Petr B-PERSON Petrov I-PERSON Junior B-WORK_OF_ART Web I-WORK_OF_ART Developer I-WORK_OF_ART Boogle B-ORG IO ' O ve O developed O Web B-WORK_OF_ART - O Application O . Skills O : O ReactJS B-WORK_OF_ART Vue B-WORK_OF_ART - I-WORK_OF_ART JS I-WORK_OF_ART HTML B-WORK_OF_ART CSS B-WORK_OF_ART Russian B-LOC Federation I-LOC . O ...
O formato do conjunto de dados é o seguinte:
<_><><_>
IMPORTANTE: após o final da frase, deve haver uma quebra de linha. Se a oferta contiver mais de 75 tokens, também será necessário colocar uma quebra de linha; caso contrário, ao aprender o modelo, o processo falhará.
Para preparar o conjunto de dados, escrevi uma interface da web na qual é possível fazer upload de arquivos
DOC / PDF / DOCX para um servidor, analisá-lo em texto sem formatação e, em seguida, executar esse texto por meio de um modelo ativo com acesso à API REST enquanto salva o resultado em um banco de dados intermediário. Para isso eu uso o
MongoDB .
Após a conclusão das ações acima, você pode prosseguir para a formação do conjunto de dados para nossas necessidades.
Para fazer isso, criei um painel separado na minha interface da Web escrita, onde é possível pesquisar por tokens do conjunto de dados e depois alterar o tipo de token e o próprio texto do token.
A ferramenta também sabe como, automaticamente, com base em uma lista de palavras, atualizar o tipo de token especificado pelo usuário mediante solicitação.
Em geral, a ferramenta ajuda a automatizar parte do trabalho, mas você ainda precisa fazer muito trabalho manual.
Uma interface para verificar o resultado e dividir o conjunto de dados em três arquivos também é implementada.
DeepPavlov Training
Então chegamos à parte mais interessante. Para o processo de aprendizado, você primeiro precisa fazer o download do modelo
ner_ontonotes_bert_mult ; se ainda não o fez, é necessário concluir as duas primeiras etapas da seção
DeepPavlov até a API REST acima.
Antes de iniciar o processo de aprendizado, você deve concluir duas etapas:
- Exclua completamente a pasta com o modelo treinado:
C:\Users\<_>\.deeppavlov\models\ner_ontonotes_bert_mult
Como esse modelo foi treinado em um conjunto de dados diferente. - Copie os arquivos preparados do conjunto de dados train.txt, valid.txt, test.txt para a pasta
C:\Users\<_>\.deeppavlov\downloads\ontonotes
Agora você pode iniciar o processo de aprendizado.
Para iniciar o treinamento, você pode escrever um script
train.py simples do seguinte formato:
from deeppavlov import configs, train_model ner_model = train_model(configs.ner.ner_ontonotes_bert_mult, download=False)
ou use a linha de comando:
python -m deeppavlov train <_>\env\Lib\site-packages\deeppavlov\configs\ner\ner_ontonotes_bert_mult.json
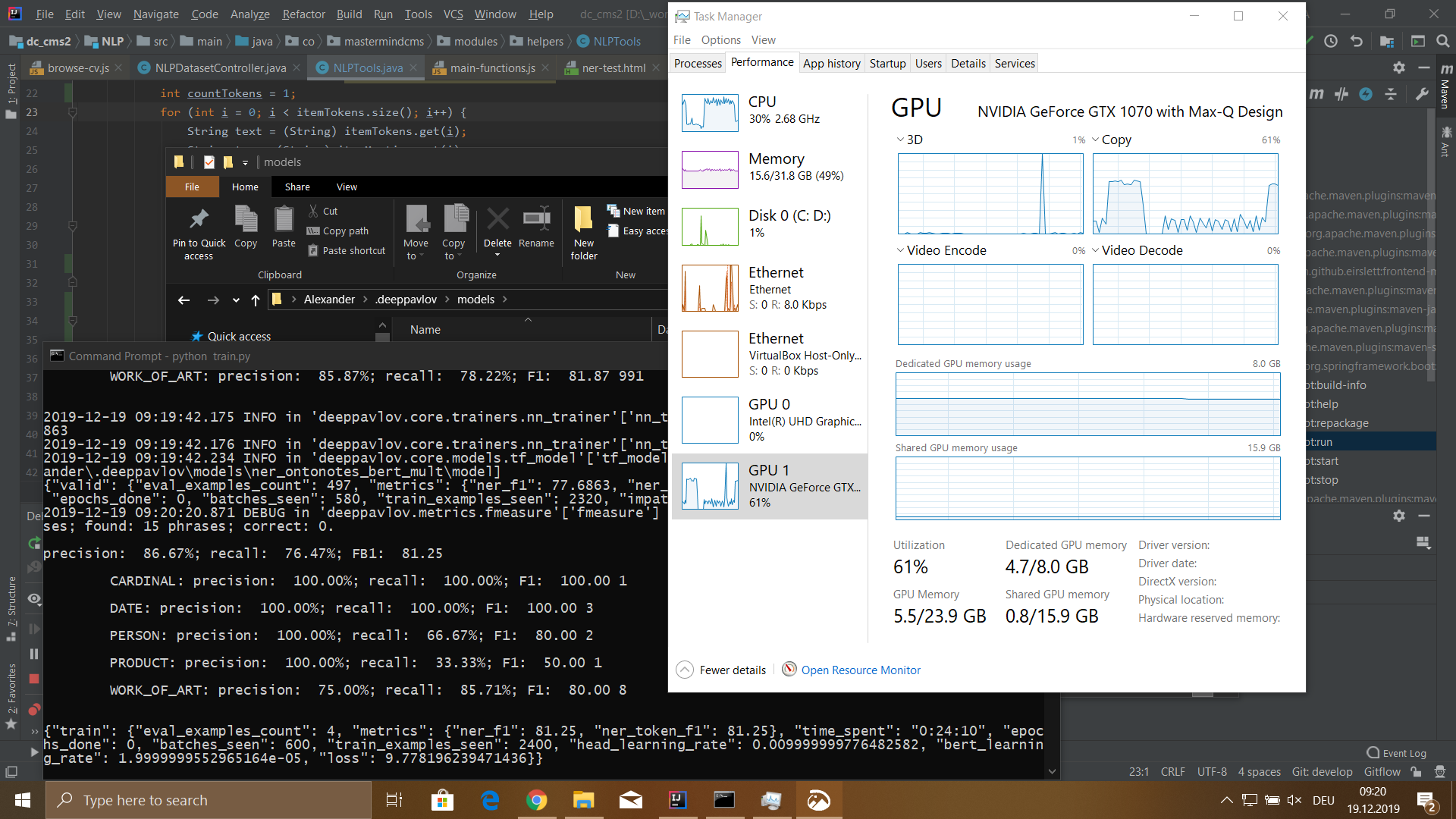
Resultados
Treinei um modelo em um conjunto de dados com um tamanho de 115.540 tokens. Esse conjunto de dados foi gerado a partir de 100 arquivos de currículo de funcionários. O processo de aprendizado levou 5 horas e 18 minutos.
O modelo tinha os seguintes significados:
- precisão: 76,32%;
- recordação: 72,32%;
- FB1: 74,27;
- perda: 5.4907482981681826;
Depois de editar vários problemas na geração automática do conjunto de dados, recebi uma
perda abaixo. Mas, em geral, fiquei satisfeito com o resultado. Obviamente, ainda tenho muitas perguntas sobre o uso desta biblioteca, e o que descrevi aqui é apenas uma gota no balde.
Gostei muito da biblioteca por sua simplicidade e facilidade de uso. Pelo menos para a tarefa
NER . Ficarei muito feliz em discutir outros recursos desta biblioteca e espero que alguém ache o material deste artigo útil.