- Entrada
- Conexão de biblioteca
- Onde classe
- Participar da aula
- Consulta de classe
╔═══╗╔═══╗╔═══╗╔═══╗╔╗─╔╗────╔═══╗╔══╗╔═══╗ ║╔══╝║╔═╗║║╔══╝║╔══╝║╚═╝║────║╔═╗║╚╗╔╝║╔══╝ ║║╔═╗║╚═╝║║╚══╗║╚══╗║╔╗─║────║╚═╝║─║║─║║╔═╗ ║║╚╗║║╔╗╔╝║╔══╝║╔══╝║║╚╗║────║╔══╝─║║─║║╚╗║ ║╚═╝║║║║║─║╚══╗║╚══╗║║─║║────║║───╔╝╚╗║╚═╝║ ╚═══╝╚╝╚╝─╚═══╝╚═══╝╚╝─╚╝────╚╝───╚══╝╚═══╝ 5HHHG HH HHHHHHH 9HHHA HHHHHHHH5 HHHHHHHHHHHHHHHHHH 9HHHHH5 5HHHHHHHHHHHHHHHHHHHHHHHHHHH HHHHHHHHHHHHHHHHHHHHHHHHHHHH ;HHHHHHHHHHHHHHHHHHHHHHHHHHA H2 HHHHHHHHHHHHHHHHHHHHHH HHHHHHHHHHHHHHHHHHHHHHH9 HHHHHHHHHHHHHHHHHHHHHHH AHHHHHHHHHHHHHHHHHHHHHH HHHHHHHHHHHHHHHHHHHHH9 iHS HHHHHHHHHHHHHHHHHHHHHHhh HHHHHHHHHHHHHHHHHH AA HHHHHHHHHHHHHH3 &H Hi HS Hr & H& H& Hi
Entrada
Quero falar sobre o desenvolvimento da minha pequena biblioteca em php. Que tarefas ela resolve? Por que eu decidi escrever e por que poderia ser útil para você? Bem, tente responder a estas perguntas.
O GreenPig (daqui em diante GP ) é um pequeno assistente de banco de dados que pode complementar a funcionalidade de qualquer estrutura php usada.
Como qualquer ferramenta GP , ela é aprimorada para resolver certos problemas. Será útil se você preferir escrever consultas de banco de dados em sql puro e não usar o registro ativo e outras tecnologias semelhantes. Por exemplo, temos um banco de dados Oracle em funcionamento e, muitas vezes, consultas ocupam várias telas com dezenas de junções, funções plsql, união de todas, etc., ainda são usadas. etc., então não há mais nada a fazer além de escrever consultas em sql puro.
Mas com essa abordagem, surge a pergunta: como gerar onde a parte da consulta sql quando os usuários pesquisam informações? O GP visa, em primeiro lugar, a compilação conveniente por meio do php, onde há uma solicitação de qualquer complexidade.
Mas o que me levou a escrever nesta biblioteca (exceto, é claro, para obter uma experiência interessante)? Estas são três coisas:
Primeiro, a necessidade de obter não uma resposta simples padrão do banco de dados, mas uma matriz aninhada em forma de árvore.
Aqui está um exemplo de uma amostra de banco de dados padrão: [ [0] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 1 ['name'] => ' ()' ['value'] => 790 ], [1] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 2 ['name'] => ' ' ['value'] => 24 ], [2] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 3 ['name'] => ' ' ['value'] => 75 ], [3] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 10 ['name'] => ' ' ['value'] => 5 ], [4] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 8 ['name'] => ' ()' ['value'] => 0.12 ], [5] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 9 ['name'] => ' ' ['value'] => 1 ], [6] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 10 ['name'] => ' ' ['value'] => 5 ], [7] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 8 ['name'] => ' ()' ['value'] => 0.12 ], [8] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 9 ['name'] => ' ' ['value'] => 1 ], [9] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 10 ['name'] => ' ' ['value'] => 5 ], [10] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 8 ['name'] => ' ()' ['value'] => 0.12 ], [11] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 9 ['name'] => ' ' ['value'] => 1 ], [12] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 1 ['name'] => ' ()' ['value'] => 790 ], [13] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 2 ['name'] => ' ' ['value'] => 24 ], [14] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 3 ['name'] => ' ' ['value'] => 75 ], [15] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 1 ['name'] => ' ()' ['value'] => 790 ], [16] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 2 ['name'] => ' ' ['value'] => 24 ], [17] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 3 ['name'] => ' ' ['value'] => 75 ] ]
Para obter uma matriz semelhante a uma árvore, precisamos trazer o resultado para o formulário desejado ou fazer N consultas ao banco de dados para cada produto. E se precisamos de paginação, e mesmo com classificação? GP é capaz de resolver esses problemas. Aqui está um exemplo de uma amostra com GP :
[ [1] => [ ['prod_type'] => 'car' ['properties'] => [ [1] => [ ['name'] => ' ()' ['value'] => 790 ] [2] => [ ['name'] => ' ' ['value'] => 24 ] [3] => [ ['name'] => ' ' ['value'] => 75 ] ] ] [4] => [ ['prod_type'] => 'phone' ['properties'] => [ [10] => [ ['name'] => ' ' ['value'] => 5 ] [8] => [ ['name'] => ' ()' ['value'] => 0.12 ] [9] => [ ['name'] => ' ' ['value'] => 1 ] ] ] ]
E, é claro, ao mesmo tempo, conveniente paginação e classificação: ->pagination(1, 10)->sort('id') .
A segunda razão não é tão frequente, mas, no entanto, ocorre (e no meu caso, essa é a principal razão). Se algumas entidades estiverem armazenadas no banco de dados e as propriedades dessas entidades forem dinâmicas e definidas pelos usuários, quando você precisar procurar entidades por suas propriedades, será necessário adicionar (ingressar) na mesma tabela com os valores das propriedades (quantas vezes forem usadas propriedades ao pesquisar). Portanto, o GP o ajudará a conectar todas as tabelas e gerar a consulta where com quase uma função. No final do artigo, analisarei esse caso em detalhes.
E, finalmente, tudo isso deve funcionar para o banco de dados Oracle e para o mySql. Há também vários recursos descritos na documentação.
É possível que eu tenha inventado outra bicicleta, mas procurei conscientemente e não encontrei uma solução adequada para mim. Se você conhece uma biblioteca que resolve esses problemas - escreva nos comentários.
Antes de prosseguir diretamente para um exame da própria biblioteca e para exemplos, direi que haverá apenas a essência, sem explicações detalhadas. Se você se interessar em como o GP funciona, pode ver a documentação , tentei explicar tudo em detalhes.
Conexão de biblioteca
A biblioteca pode ser instalada via compositor: o composer require falbin/green-pig-dao
Então você precisa escrever uma fábrica através da qual você usará esta biblioteca.
Onde classe
Usando essa classe, você pode compor a parte where da consulta sql de qualquer complexidade.
Parte atômica da solicitação
Considere a menor parte atômica de uma consulta. É descrito por uma matriz: [, , ]
Exemplo: ['name', 'like', '%%']
- O primeiro elemento da matriz é apenas uma string, inserida na consulta sql sem alterações e, portanto, você pode escrever funções sql nela. Exemplo:
['LOWER(name)', 'like', '%%'] - O segundo elemento também é uma string inserida no sql sem alterações entre dois operandos. Pode aceitar os seguintes valores: =,>, <,> =, <=, <>, como, não como, entre, não entre, dentro, não dentro .
- O terceiro elemento da matriz pode ser do tipo numérico ou de sequência. Onde a classe substituirá automaticamente o alias gerado na consulta sql.
- Elemento de matriz com chave sql. Às vezes é necessário que o valor seja inserido no código sql sem alterações. Por exemplo, para aplicar funções. Isso pode ser conseguido especificando 'sql' como a chave (para o terceiro elemento). Exemplo:
['LOWER(name)', 'like', 'sql' => "LOWER('$name')"] - Um elemento de matriz com a chave de ligação é uma matriz para armazenar ligações. O exemplo acima está errado do ponto de vista da segurança. Você não pode inserir variáveis no sql - é muita injeção. Portanto, nesse caso, você precisará especificar aliases, por exemplo, assim:
['LOWER(name)', 'like', 'sql' => "LOWER(:name)", 'bind'=> ['name' => $name] ] - O operador in pode ser escrito assim:
['curse', 'not in', [1, 3, 5]] . A classe Where converte essa entrada no seguinte código sql: curse not in (:al_where_jCgWfr95kh, :al_where_mCqefr95kh, :al_where_jCfgfr9Gkh) - A declaração entre pode ser escrita assim:
['curse', ' between', 1, 5] . A classe Where converte essa entrada no seguinte código sql: curse between :al_where_Pi4CRr4xNn and :al_where_WiPPS4NKiG
Mas tenha cuidado, se o terceiro e o quarto elementos da matriz forem seqüências de caracteres, uma lógica especial será aplicada. Nesse caso, acredita-se que a seleção seja de um intervalo de datas e, portanto, é usada a função sql de converter uma string para uma data. A função de conversão para uma data (mySql e Oracle têm diferentes) e seus parâmetros são obtidos de uma matriz de configurações (mais na documentação). A matriz ['build_date', 'between', '01.01.2016', '01.01.2019'] será convertida em sql: build_date between TO_DATE(:al_where_fkD7nZg5lU, 'dd.mm.yyyy hh24:mi::ss') and TO_DATE(:al_where_LdyVRznPF8, 'dd.mm.yyyy hh24:mi::ss')
Consultas complicadas
Vamos criar uma instância da classe através da fábrica: $wh = GP::where();
Para indicar a conexão lógica entre as "partes atômicas" da solicitação, você deve usar as linkAnd() ou linkOr() . Um exemplo:
Ao usar as funções linkAnd / linkOr, todos os dados são armazenados em uma instância da classe Where - $ wh. Além disso, todas as "partes atômicas" indicadas na função estão entre colchetes .
O SQL de qualquer complexidade pode ser descrito por três funções: linkAnd(), linkOr(), getRaw() . Considere um exemplo:
A classe Where tem uma variável privada que armazena a expressão bruta. Os linkAnd() e linkOr() sobrescrevem essa variável, portanto, ao construir uma expressão lógica, os métodos são aninhados juntos e a variável com a expressão bruta contém dados obtidos do último método executado.
Classe JOIN
Join é uma classe que gera um fragmento de junção do código sql. Vamos criar uma instância da classe através da fábrica: $jn = GP::leftJoin('coursework', 'student_id', 's.id') , onde:
- o curso é a mesa em que vamos nos juntar
- student_id - uma coluna com uma chave estrangeira da tabela de cursos .
- s.id - a coluna da tabela com a qual a junção deve ser escrita junto com o alias da tabela (nesse caso, o alias da tabela é s).
left JOIN coursework coursework_joM9YuTTfW ON coursework_joM9YuTTfW.student_id = s.id gerado: left JOIN coursework coursework_joM9YuTTfW ON coursework_joM9YuTTfW.student_id = s.id
Ao criar uma instância da classe, já descrevemos a condição para juntar tabelas, mas pode ser necessário esclarecer e expandir a condição. As funções linkAnd / linkOr ajudarão você a fazer isso: $jn->linkAnd(['semester_number', '>', 2])
inner JOIN coursework coursework_Nd1n5T7c0r ON coursework_Nd1n5T7c0r.student_id = s.id and (semester_number > :al_where_M1kEcHzZyy) gerado: inner JOIN coursework coursework_Nd1n5T7c0r ON coursework_Nd1n5T7c0r.student_id = s.id and (semester_number > :al_where_M1kEcHzZyy)
Se houver várias tabelas para ingressar, você poderá combiná-las em uma classe: CollectionJoin .
Consulta de classe
Esta é a classe principal para trabalhar com o banco de dados, através dele existe uma seleção, gravação, atualização e exclusão de dados. Você também pode executar determinado processamento de dados obtidos no banco de dados.
Considere um exemplo típico.
Vamos criar uma instância da classe através da fábrica: $qr = GP::query();
Agora vamos definir o modelo sql, substituir os valores necessários para o cenário fornecido no modelo sql e dizer que queremos obter um registro, e especificamente os dados da coluna average_mark .
$rez = $qr->sql("select /*select*/ from student s inner join mark m on s.id = m.student_id inner join lesson l on l.id = m.lesson_id /*where*/ /*group*/") ->sqlPart('/*select*/', 's.name, avg(m.mark) average_mark', []) ->whereAnd('/*where*/', ['s.id', '=', 1]) ->sqlPart('/*group*/', 'group by s.name', []) ->one('average_mark');
Resultado: 3,16666666666666666666666666666666666667
Seleção de um banco de dados com parâmetros aninhados
Acima de tudo, não tive a oportunidade de obter uma seleção do banco de dados em uma exibição em árvore, com propriedades anexadas. Portanto, a biblioteca GP tem essa oportunidade e a profundidade do aninhamento não é limitada.
A maneira mais fácil de considerar o princípio de operação é baseada em um exemplo. Para consideração, adotamos o seguinte esquema de banco de dados:

Conteúdo da tabela:
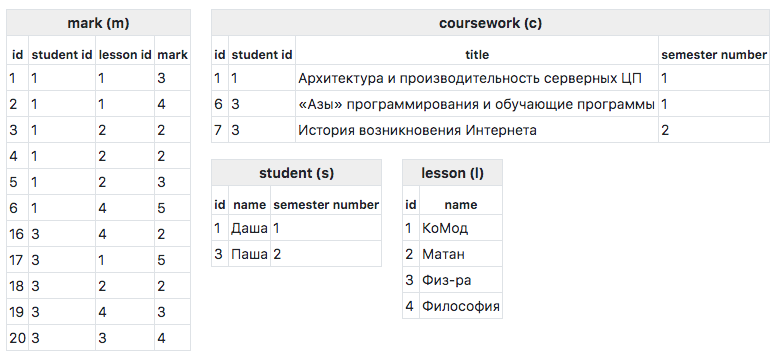
Freqüentemente, ao consultar um banco de dados, você deseja obter uma resposta semelhante a uma árvore, não uma resposta simples. Por exemplo, executando esta consulta:
SELECT s.id, s.name, c.id title_id, c.title FROM student s INNER JOIN coursework c ON c. student_id = s.id WHERE s.id = 3
Temos um resultado simples:
[ 0 => [ 'id' => 3, 'name' => '', 'title_id' => 6, 'title' => '«» ', ], 1=> [ 'id' => 3, 'name' => '', 'title_id' => 7, 'title' => ' ' ] ]
Usando o GP, você pode obter este resultado:
[ 3 => [ 'name' => '', 'courseworks' => [ 6 => ['title' => '«» '], 7 => ['title' => ' '] ] ] ]
Para alcançar esse resultado, você precisa passar uma matriz com opções para a função all (a função retorna todas as linhas de consulta):
all([ 'id'=> 'pk', 'name' => 'name', 'courseworks' => [ 'title_id' => 'pk', 'title' => 'title' ] ])
A matriz $option no agregador de funções ( $option , $ rawData) e all ( $options ) é criada de acordo com as seguintes regras:
- Chaves de matriz - nomes de colunas. Elementos da matriz - novos nomes para colunas, você pode inserir o nome antigo.
- Há uma palavra reservada para valores de matriz -
pk . Ele diz que os dados serão agrupados por esta coluna (a chave da matriz é o nome da coluna). - Em cada nível, deve haver apenas um
pk . - Na matriz agregada (resultante), os valores da coluna declarada por
pk serão usados como chaves. - Se for necessário colocar parte das colunas em um nível mais baixo, um novo nome inventado será usado como uma chave de matriz, e uma matriz construída de acordo com as regras descritas acima será usada como valor.
Considere um exemplo mais complexo. Suponha que precisamos obter todos os alunos com o nome de seus cursos e com todas as notas em todas as disciplinas. Gostaríamos de recebê-lo não em uma forma plana, mas em uma árvore, sem duplicatas. Abaixo está a consulta desejada para o banco de dados e o resultado.
SELECT s.id student_id, s.name student_name, s.semester_number, c.id coursework_id, c.semester_number coursework_semester, c.title coursework_title, l.id lesson_id, l.name lesson, m.id mark_id, m.mark FROM student s LEFT JOIN coursework c ON c.student_id = s.id LEFT JOIN mark m ON m.student_id = s.id LEFT JOIN lesson l ON l.id = m.lesson_id ORDER BY s.id, c.id, l.id, m.id
O resultado não nos convém:
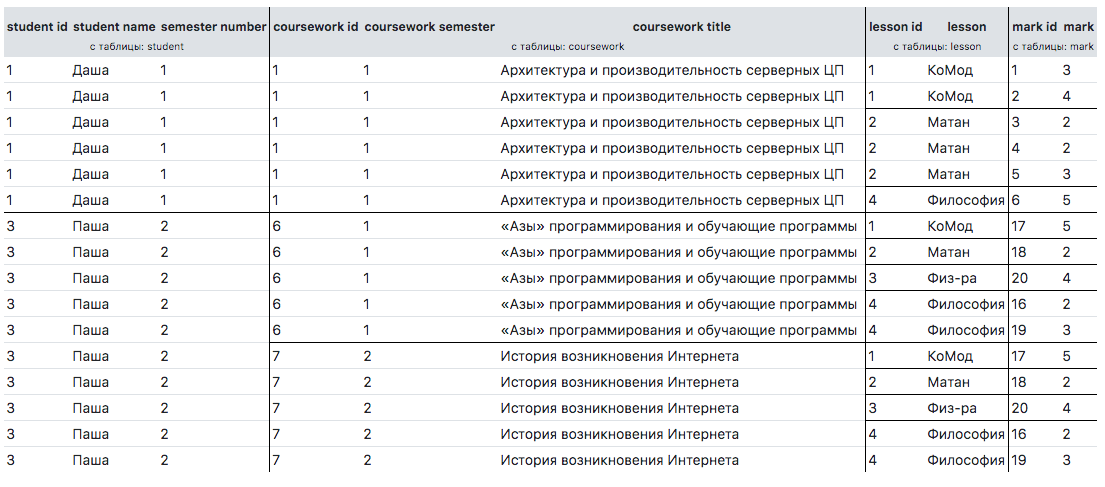
Para realizar a tarefa, você precisa escrever a seguinte matriz de $option :
$option = [ 'student_id' => 'pk', 'student_name' => 'name', 'courseworks' => [ 'coursework_semester' => 'pk', 'coursework_title' => 'title' ], 'lessons' => [ 'lesson_id' => 'pk', 'lesson' => 'lesson', 'marks' => [ 'mark_id' => 'pk', 'mark' => 'mark' ] ] ];
Consulta ao banco de dados:
A função aggregator pode processar qualquer matriz com uma estrutura semelhante ao resultado de uma consulta ao banco de dados, de acordo com as regras descritas na $option .
A variável $result contém os seguintes dados:
[ 1 => [ 'name' => '', 'courseworks' => [ 1 => ['title' => ' '], ], 'lessons' => [ 1 => [ 'lesson' => '', 'marks' => [ 1 => ['mark' => 3], 2 => ['mark' => 4] ] ], 2 => [ 'lesson' => '', 'marks' => [ 3 => ['mark' => 2], 4 => ['mark' => 2], 5 => ['mark' => 3] ] ], 4 => [ 'lesson' => '', 'marks' => [ 6 => ['mark' => 5] ] ] ] ], 3 => [ 'name' => '', 'courseworks' => [ 1 => ['title' => '«» '], 2 => ['title' => ' '] ], 'lessons' => [ 1 => [ 'lesson' => '', 'marks' => [ 17 => ['mark' => 5] ] ], 2 => [ 'lesson' => '', 'marks' => [ 18 => ['mark' => 2] ] ], 3 => [ 'lesson' => '-', 'marks' => [ 20 => ['mark' => 4] ] ], 4 => [ 'lesson' => '', 'marks' => [ 16 => ['mark' => 2], 19 => ['mark' => 3] ] ], ] ] ]
A propósito, com paginação com consulta agregada, apenas os dados mais básicos são considerados. No exemplo acima, haverá apenas 2 linhas para paginação.
União múltipla consigo no nome da pesquisa
Como escrevi anteriormente, a principal tarefa da minha biblioteca é simplificar a geração das partes where para consultas selecionadas. Então, nesse caso, talvez seja necessário juntar-nos repetidamente à mesma tabela para a consulta where? Uma das opções é quando temos um determinado produto cujas propriedades não são conhecidas antecipadamente e serão adicionadas pelos usuários, e precisamos ter a oportunidade de procurar produtos por essas propriedades dinâmicas. A maneira mais fácil de explicar com um exemplo simplificado.
Suponha que tenhamos uma loja on-line vendendo componentes de computador e que não tenhamos uma variedade rigorosa e que compraremos periodicamente um componente ou outro. Mas gostaríamos de descrever todos os nossos produtos como uma única entidade e procurar todos os produtos. Portanto, quais entidades podem ser distinguidas do ponto de vista da lógica de negócios:
- Produto. A entidade mais importante em torno da qual tudo é construído.
- Tipo de produto. Isso pode ser representado como a propriedade raiz de todas as outras propriedades do produto. Por exemplo, em nossa pequena loja, é apenas: RAM, SSD e HDD.
- Propriedades do produto. Em nossa implementação, qualquer propriedade pode ser aplicada a qualquer tipo de produto, a escolha permanece na consciência do gerente. Em nossa loja, os gerentes criaram apenas três propriedades: tamanho da memória, fator de forma e DDR.
- O valor das mercadorias. O valor que o comprador irá gerar na pesquisa.
Toda a lógica de negócios descrita acima é refletida em detalhes na imagem abaixo.
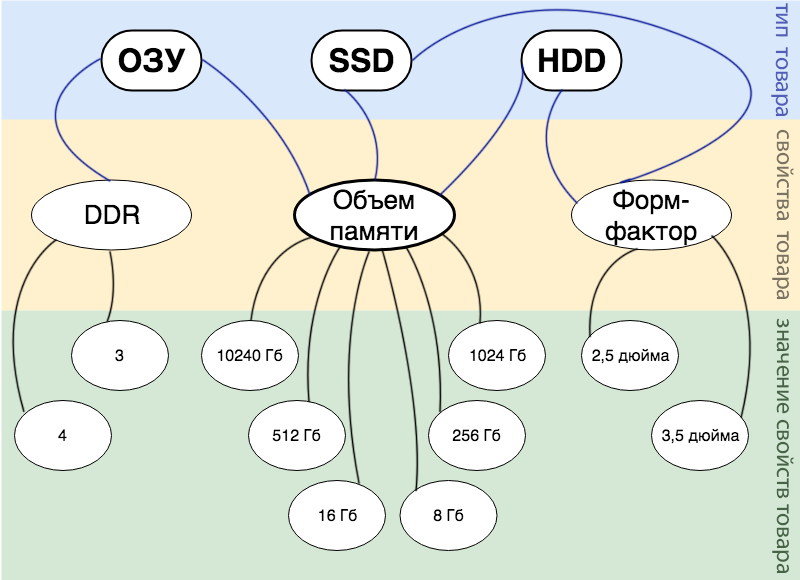
Por exemplo, temos um produto: 16 GB DDR 3 RAM . No diagrama, isso pode ser exibido da seguinte maneira:
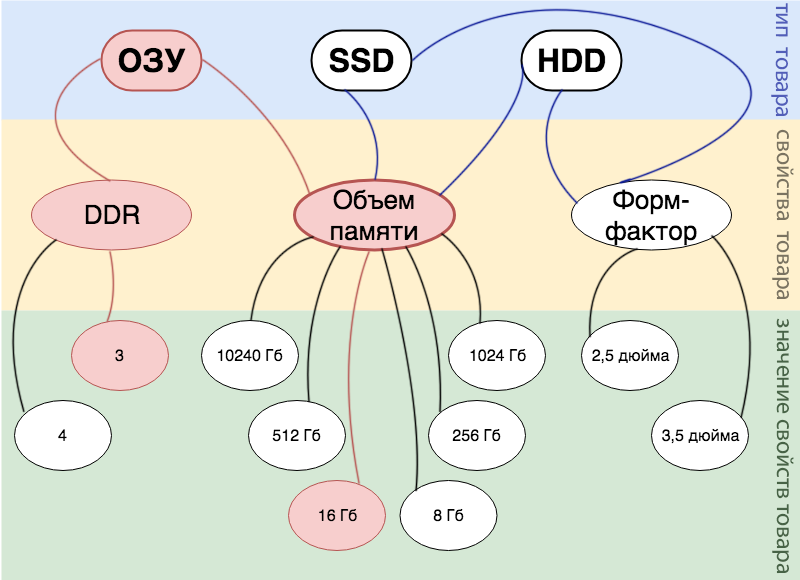
A estrutura e os dados do banco de dados são claramente visíveis na figura a seguir:
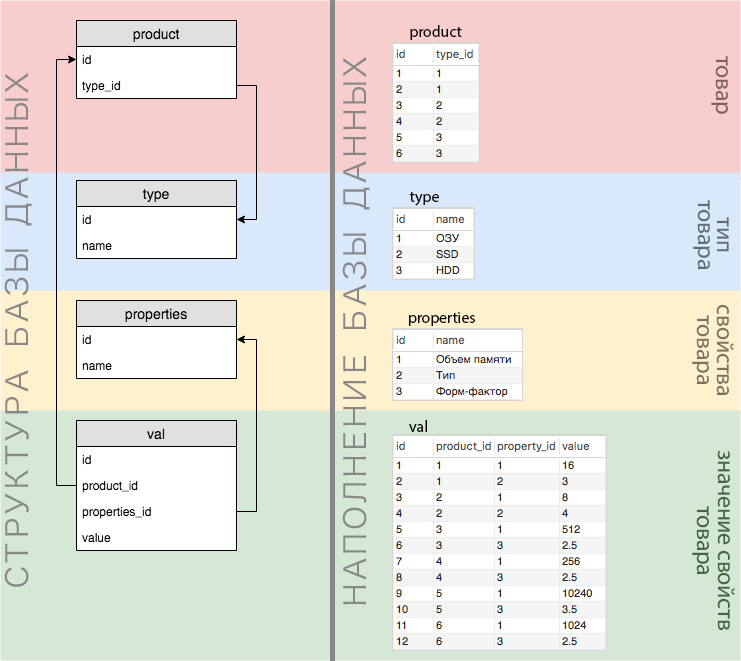
Como podemos ver no diagrama, todos os valores de todas as propriedades são armazenados em uma tabela de valores (a propósito, em nossa versão simplificada, todas as propriedades têm valores numéricos). Portanto, se queremos procurar simultaneamente várias propriedades com um monte de AND, obtemos uma seleção vazia.
Por exemplo, um comprador está procurando produtos adequados para essa solicitação: a quantidade de memória deve ser superior a 10 GB e o fator de forma deve ser de 2,5 polegadas . Se escrevermos sql como mostrado abaixo, obteremos uma seleção vazia:
select * from product p inner join val v on v.product_id = p.id where (v.property_id = 1 and v.value > 10) AND (v.property_id = 3 and v.value = 2.5)
Como os valores de todas as propriedades são armazenados em uma tabela, para procurar várias propriedades, você deve associar o valor da tabela a cada propriedade que será pesquisada. Mas há uma nuance: join junta tabelas "horizontalmente" (para a palavra união todas as junções "verticalmente"), o seguinte é um exemplo:

Este resultado não nos convém, gostaríamos de ver todos os valores em uma coluna. Para fazer isso, você precisa associar-se à tabela val 1 vezes mais do que as propriedades pelas quais a pesquisa é realizada.

Estamos perto de gerar automaticamente a consulta sql. Vamos olhar para a função
whereWithJoin ($aliasJoin, $options, $aliasWhere, $where) , que fará todo o trabalho:
- $ aliasJoin - um alias no modelo base, em vez do qual a parte sql com junções é substituída.
- $ options - uma matriz com descrições das regras para gerar a parte de junção.
- $ aliasWhere - um alias no modelo base, que substitui a parte where sql.
- $ where é uma instância da classe Where.
Vejamos um exemplo: whereWithJoin('/*join*/', $options, '/*where*/', $wh) .
Primeiro, crie a variável $ options : $options = ['v' => ['val', 'product_id', 'p.id']];
v é o alias da tabela. Se o alias dado for encontrado em $ wh , uma nova tabela val será conectada por join (onde product_id é a chave estrangeira da tabela val e p.id é a chave primária da tabela com o alias p ), um novo alias e esse alias serão gerados para ela substituirá v em onde.
$ wh é uma instância da classe Where. Formamos a mesma solicitação: a memória deve ter mais de 10 GB e o fator de forma deve ter 2,5 polegadas.
$wh->linkAnd([ $wh->linkAnd([ ['v.property_id', '=', 1], ['v.value', '>', 10] ])->getRaw(),
Ao criar uma solicitação where, é necessário agrupar a peça com a propriedade id e seu valor entre colchetes, isso informa à função whereWithJoin() que o alias da tabela será o mesmo nesta parte.
$qr->sql("select p.id, t.name type_name, pr.id prop_id, pr.name prop_name, v.id val_id, v.value from product p inner join type t on t.id = p.type_id inner join val v on v.product_id = p.id inner join properties pr on pr.id = v.property_id /*join*/ /*where*/") ->whereWithJoin('/*join*/', $options, '/*where*/', $wh)
Examinamos o sql gerado, as $qr->debugInfo() e o tempo de execução da consulta: $qr->debugInfo() :
[ [ 'type' => 'info', 'sql' => 'select p.id, t.name type_name, pr.id prop_id, pr.name prop_name, v.id val_id, v.value from product p inner join type t on t.id = p.type_id inner join val v on v.product_id = p.id inner join properties pr on pr.id = v.property_id inner JOIN val val_mIQWpnHhdQ ON val_mIQWpnHhdQ.product_id = p.id inner JOIN val val_J0uveMpwEM ON val_J0uveMpwEM.product_id = p.id WHERE ( val_mIQWpnHhdQ.property_id = :al_where_leV5QlmOZN and val_mIQWpnHhdQ.value > :al_where_ycleYAswIw ) and ( val_J0uveMpwEM.property_id = :al_where_dinxDraTOE and val_J0uveMpwEM.value = :al_where_wZJhUqs74i )', 'binds' => [ 'al_where_leV5QlmOZN' => 1, 'al_where_ycleYAswIw' => 10, 'al_where_dinxDraTOE' => 3, 'al_where_wZJhUqs74i' => 2.5 ], 'timeQuery' => 0.0384588241577 ] ]
$qr->rawData() :
[ [ 'id' => 3, 'type_name' => 'SSD', 'prop_id' => 1, 'prop_name' => ' ', 'val_id' => 5, 'value' => 512 ], [ 'id' => 3, 'type_name' => 'SSD', 'prop_id' => 3, 'prop_name' => '-', 'val_id' => 6, 'value' => 2.5 ], [ 'id' => 4, 'type_name' => 'SSD', 'prop_id' => 1, 'prop_name' => ' ', 'val_id' => 7, 'value' => 256 ], [ 'id' => 4, 'type_name' => 'SSD', 'prop_id' => 3, 'prop_name' => '-', 'val_id' => 8, 'value' => 2.5 ], [ 'id' => 6, 'type_name' => 'HDD', 'prop_id' => 1, 'prop_name' => ' ', 'val_id' => 11, 'value' => 1024 ], [ 'id' => 6, 'type_name' => 'HDD', 'prop_id' => 3, 'prop_name' => '-', 'val_id' => 12, 'value' => 2.5 ] ]
$qr->aggregateData() :
[ 3 => [ 'type' => 'SSD', 'properties' => [ 1 => [ 'name' => ' ', 'values' => [ 5 => ['val' => 512] ] ], 3 => [ 'name' => '-', 'values' => [ 6 => ['val' => 2.5] ] ] ] ], 4 => [ 'type' => 'SSD', 'properties' => [ 1 => [ 'name' => ' ', 'values' => [ 7 => ['val' => 256] ] ], 3 => [ 'name' => '-', 'values' => [ 8 => ['val' => 2.5] ] ] ] ], 6 => [ 'type' => 'HDD', 'properties' => [ 1 => [ 'name' => ' ', 'values' => [ 11 => ['val' => 1024] ] ], 3 => [ 'name' => '-', 'values' => [ 12 => ['val' => 2.5] ] ] ] ] ]
, , whereWithJoin() , .
whereWithJoin() , , n , m . n m 1 id . , AND .
GitHub .