1. Introdução
Compreender como o classificador divide o espaço multidimensional inicial de atributos em muitas classes de destino é uma etapa importante para analisar qualquer problema de classificação e avaliar a solução obtida usando o aprendizado de máquina.
As abordagens modernas para visualização de decisões dos classificadores usam principalmente diagramas de dispersão que podem exibir apenas projeções das amostras de treinamento originais, mas não mostram explicitamente os limites reais da tomada de decisão ou usam a estrutura interna do classificador (por exemplo, kNN, SVM, regressão logística) para a qual é fácil construir uma geometria interpretação. Este método não é adequado para visualização, por exemplo, de um classificador de rede neural.
O artigo "Visualização baseada em imagem dos limites de decisão do classificador" (Rodrigues et al., 2018) propõe um método alternativo eficaz, bonito e razoavelmente simples para visualizar as soluções do classificador, desprovido das desvantagens acima. Ou seja, o método é adequado para classificadores de qualquer tipo e constrói os limites da tomada de decisão usando imagens com uma taxa de amostragem arbitrária.
Este post é uma breve visão geral das principais idéias e resultados do artigo original.
Descrição do método
A base do método é a amostragem reversa (eng. Upsampling) do plano da imagem  que é representado por um conjunto de pixels no espaço do recurso
que é representado por um conjunto de pixels no espaço do recurso  .
.
O método requer dois mapeamentos  - projeção direta do espaço do feixe para o plano da imagem e o inverso
- projeção direta do espaço do feixe para o plano da imagem e o inverso  . Como tais mapeamentos, LAMP (Joia et al. 2011) e iLAMP (Amorim et al. 2012) , respectivamente, são utilizados.
. Como tais mapeamentos, LAMP (Joia et al. 2011) e iLAMP (Amorim et al. 2012) , respectivamente, são utilizados.
Prédio
Para criar uma imagem, você precisa atribuir uma cor a cada pixel. Para isso, para cada pixel  vai encontrar
vai encontrar  pontos do hiperespaço fonte onde
pontos do hiperespaço fonte onde  - parâmetro definido pelo usuário. Deixe o pixel ja tem
- parâmetro definido pelo usuário. Deixe o pixel ja tem  protótipos reais do conjunto de treinamento. Em seguida, escolha uniformemente
protótipos reais do conjunto de treinamento. Em seguida, escolha uniformemente  os pontos restantes da superfície do pixel e encontre o protótipo para eles através da projeção traseira
os pontos restantes da superfície do pixel e encontre o protótipo para eles através da projeção traseira  . Assim, a cor de cada pixel será determinada por pelo menos pontos do espaço de origem e a imagem inteira será pintada.
. Assim, a cor de cada pixel será determinada por pelo menos pontos do espaço de origem e a imagem inteira será pintada.
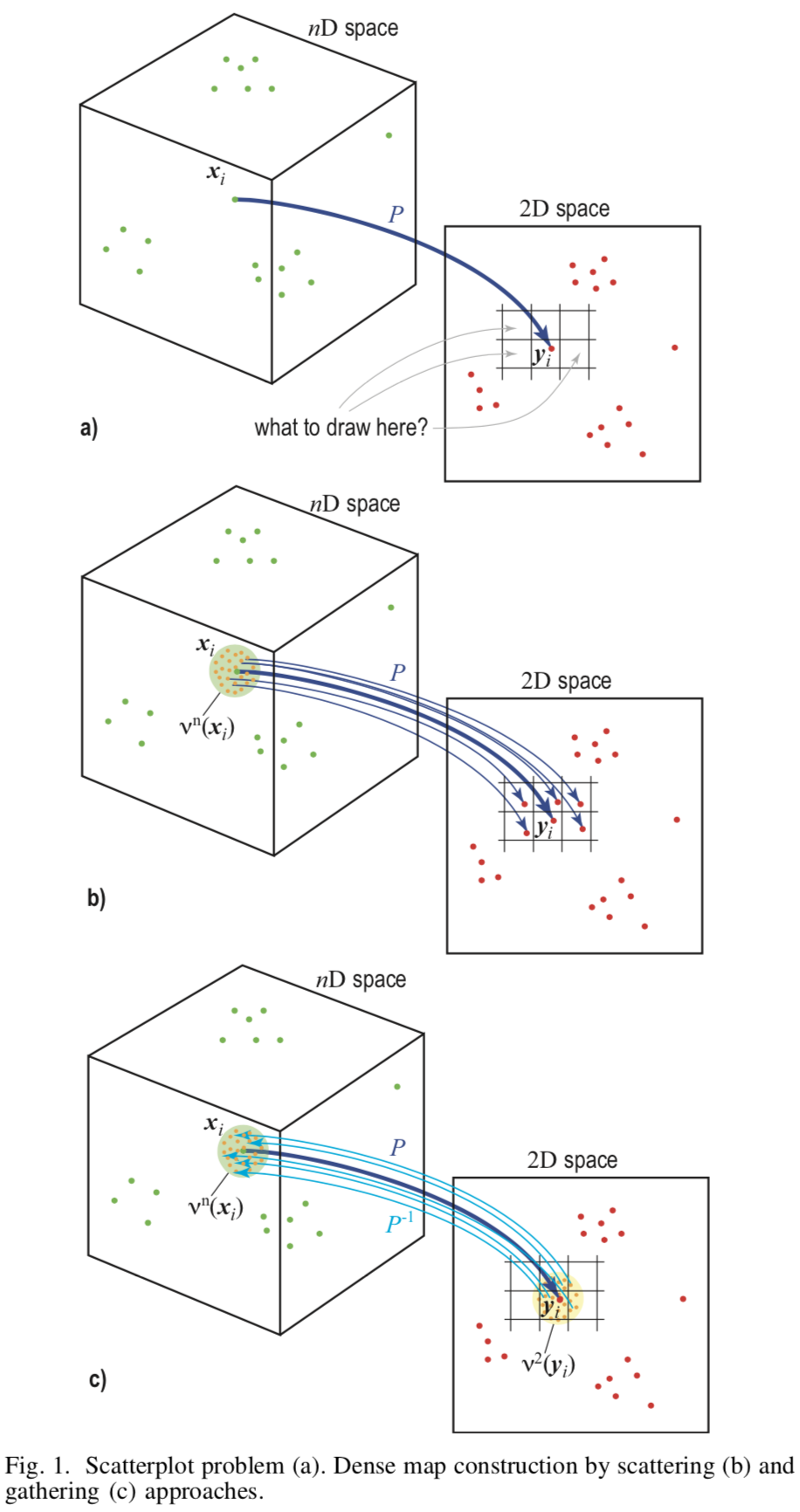
[Fig.1] Ilustração esquemática de diferentes abordagens
Definição de cores
Cor  cada pixel determinado pelo voto da maioria nos rótulos das classes das pré-imagens correspondentes.
cada pixel determinado pelo voto da maioria nos rótulos das classes das pré-imagens correspondentes.
![d (y) = \ text {argmax} _ {k \ em C} \ sum_ {y_i \ in y} [f (P ^ {- 1} (y_i)) = k]](https://habrastorage.org/getpro/habr/post_images/469/c8d/c50/469c8dc5021ee22be2190d80d4a8f9bd.svg)
onde  - muitas de todas as classes,
- muitas de todas as classes,  - classificador.
- classificador.
Cada classe receberá um tom (eng. Matiz)  - se a projeção tiver pontos da amostra real e um tom ligeiramente alterado
- se a projeção tiver pontos da amostra real e um tom ligeiramente alterado  para pixels nos quais existem apenas pontos sintéticos.
para pixels nos quais existem apenas pontos sintéticos.
Confusão
Definir mixagem de pixels (da confusão em inglês)  - como a razão entre o número de etiquetas da classe predominante e o número total de imagens inversas em pixels :
- como a razão entre o número de etiquetas da classe predominante e o número total de imagens inversas em pixels :
![c (y) = \ frac {\ max_ {k \ em C} \ sum_ {y_i \ in y} [f (P ^ {- 1} (y_i)) = k]} {| y |}](https://habrastorage.org/getpro/habr/post_images/62d/5e7/47f/62d5e747f958e587200665af682cbae9.svg)
Alto valor indica a consistência do classificador, enquanto um valor baixo sinaliza uma abordagem ao limite divisor. Misture as informações codificadas na saturação de pixels  - quanto maior a consistência, maior a saturação.
- quanto maior a consistência, maior a saturação.
Densidade
Embora um mínimo tenha sido gerado pontos de pré-imagem para cada pixel, pode haver pixels para os quais existem muito mais pontos reais do conjunto de treinamento. Esses pixels devem ser considerados ao renderizar. Para fazer isso, insira a densidade de pixels  como o número de sua imagem inversa aponta de . Pode-se usar essa densidade diretamente para determinar o brilho de um pixel como
como o número de sua imagem inversa aponta de . Pode-se usar essa densidade diretamente para determinar o brilho de um pixel como  , mas os autores do artigo apontam que isso não fornece o resultado desejado, porque alguns tons são obviamente mais escuros que outros. Portanto, uma configuração mais sofisticada é usada ao mesmo tempo de saturação e brilho através de um parâmetro de densidade normalizada.
, mas os autores do artigo apontam que isso não fornece o resultado desejado, porque alguns tons são obviamente mais escuros que outros. Portanto, uma configuração mais sofisticada é usada ao mesmo tempo de saturação e brilho através de um parâmetro de densidade normalizada.

Então se ![\ hat {\ rho} \ em [0, 0,5]](https://habrastorage.org/getpro/habr/post_images/5f3/8f9/0c5/5f38f90c57fe8c26092278e6a36b55c7.svg) - o brilho depende linearmente do parâmetro dentro
- o brilho depende linearmente do parâmetro dentro ![[V_ {min} = 0,1, V_ {max} = 1]](https://habrastorage.org/getpro/habr/post_images/b1e/ef5/e22/b1eef5e220c553d3c437ee6ddb9f4f08.svg) . At
. At ![\ hat {\ rho} \ em [0,5, 1]](https://habrastorage.org/getpro/habr/post_images/4cc/04d/a79/4cc04da7997da643ef6671babba1ec57.svg) começa a crescer linearmente a saturação de
começa a crescer linearmente a saturação de  antes
antes  .
.
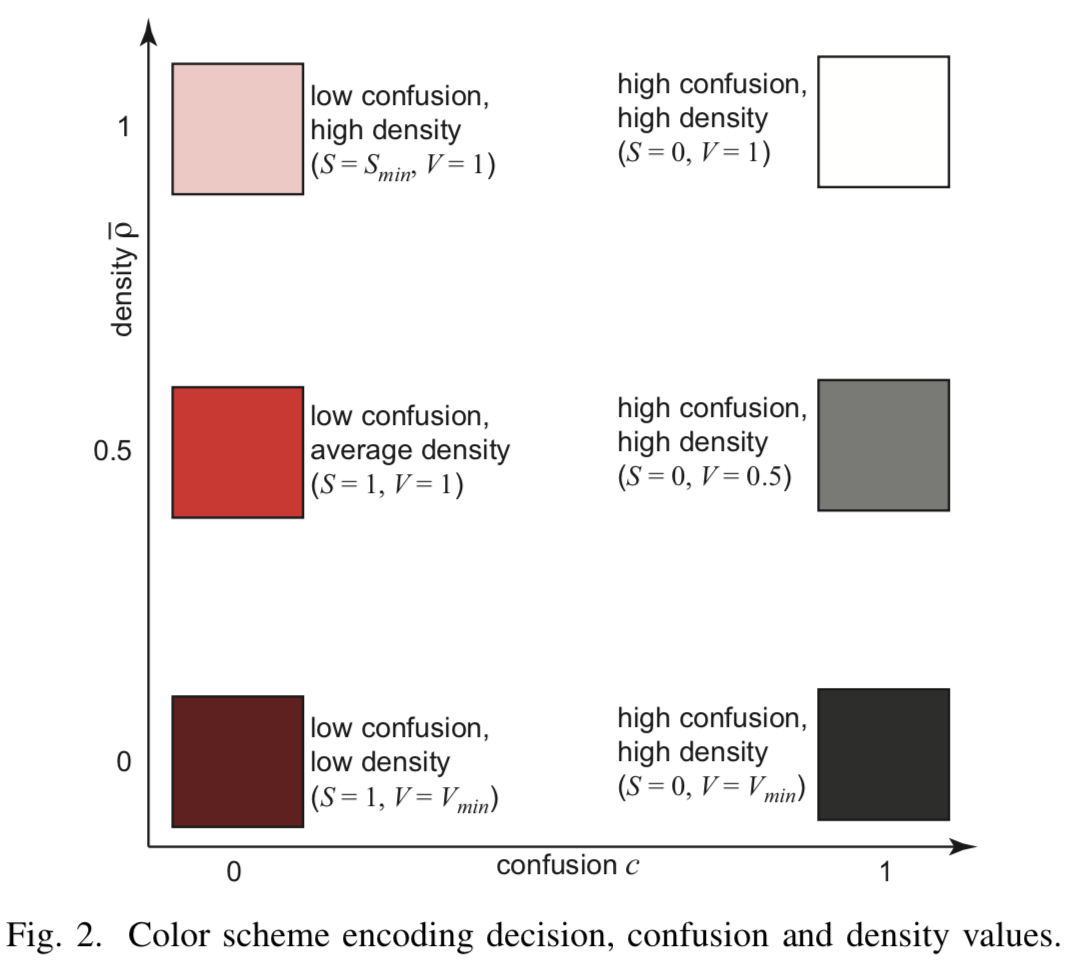
[Fig.2] Código de cores
Experimentos e Resultados
Para experimentos, foram resolvidos os problemas de classificação binária no conjunto de imagens digitais MNIST e classificação multiclasse no conjunto de dados de segmentação de imagens , que contém 2310 imagens divididas em 7 classes. Existem 19 atributos para cada imagem.
Resultados de imagem com várias configurações de resolução  e o número mínimo de protótipos para o classificador binário LogisticRegression no MNIST são mostrados na figura [3]. As aulas são separadas por uma linha reta com alta precisão e o algoritmo de visualização faz um excelente trabalho. Com o aumento da resolução, as nuvens dos pontos de origem se dissolvem quase completamente entre os muitos pontos gerados.
e o número mínimo de protótipos para o classificador binário LogisticRegression no MNIST são mostrados na figura [3]. As aulas são separadas por uma linha reta com alta precisão e o algoritmo de visualização faz um excelente trabalho. Com o aumento da resolução, as nuvens dos pontos de origem se dissolvem quase completamente entre os muitos pontos gerados.
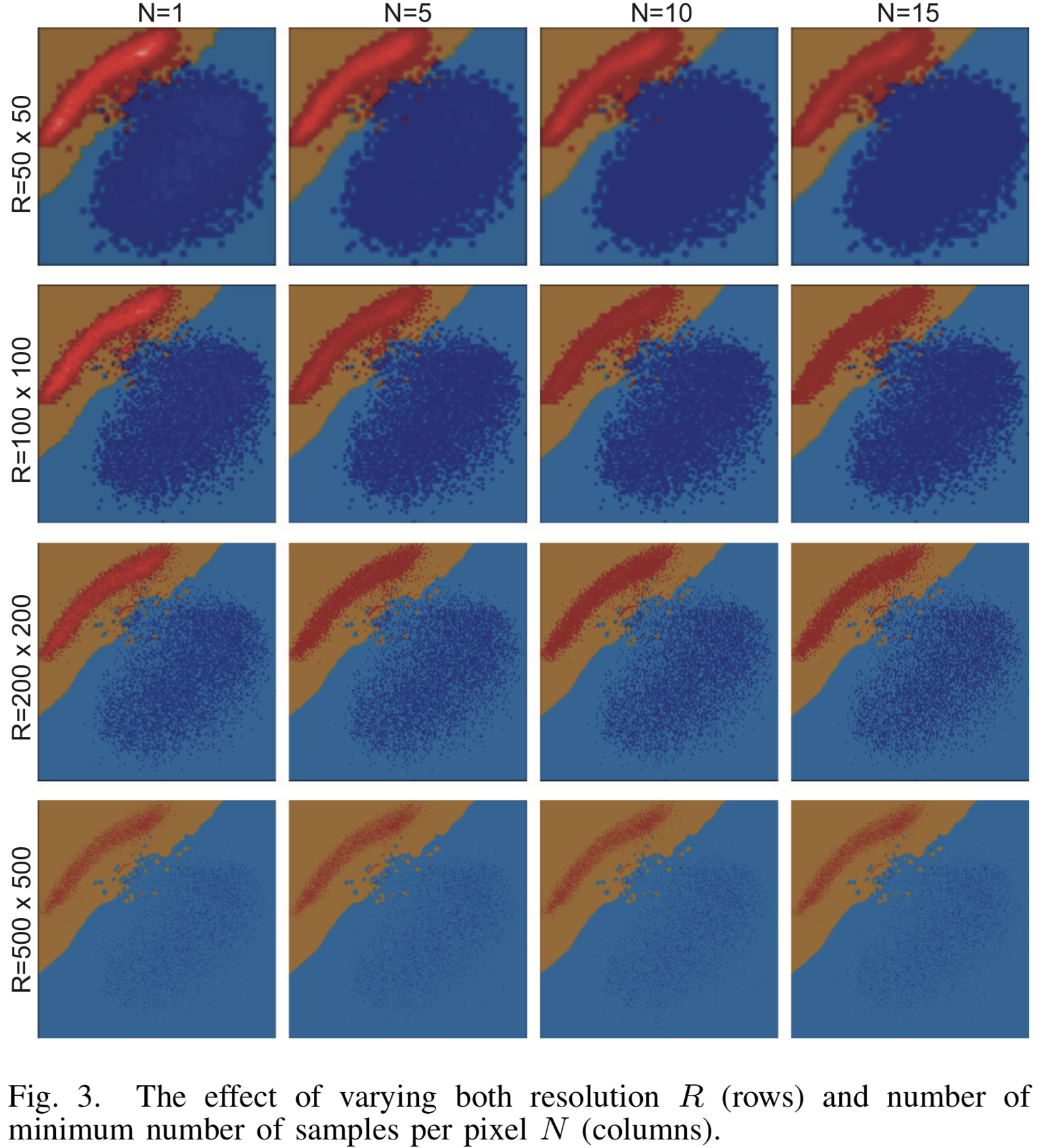
[Fig. 3] O resultado da visualização para vários parâmetros de resolução e o número mínimo de amostras N para o classificador LogisticRegression
Visualização quando  para três classificadores diferentes para multi-classificação na figura [4]. As projeções dos pontos de partida são fortemente misturadas e não é possível construir limites de divisão explícitos nos locais onde as projeções dos casos de teste são acumuladas. No entanto, além do cluster principal, foram obtidos limites explícitos de classe, informações sobre as quais não são exibidas em projeções comuns, mas são obtidas apenas com a ajuda de pontos sintéticos.
para três classificadores diferentes para multi-classificação na figura [4]. As projeções dos pontos de partida são fortemente misturadas e não é possível construir limites de divisão explícitos nos locais onde as projeções dos casos de teste são acumuladas. No entanto, além do cluster principal, foram obtidos limites explícitos de classe, informações sobre as quais não são exibidas em projeções comuns, mas são obtidas apenas com a ajuda de pontos sintéticos.
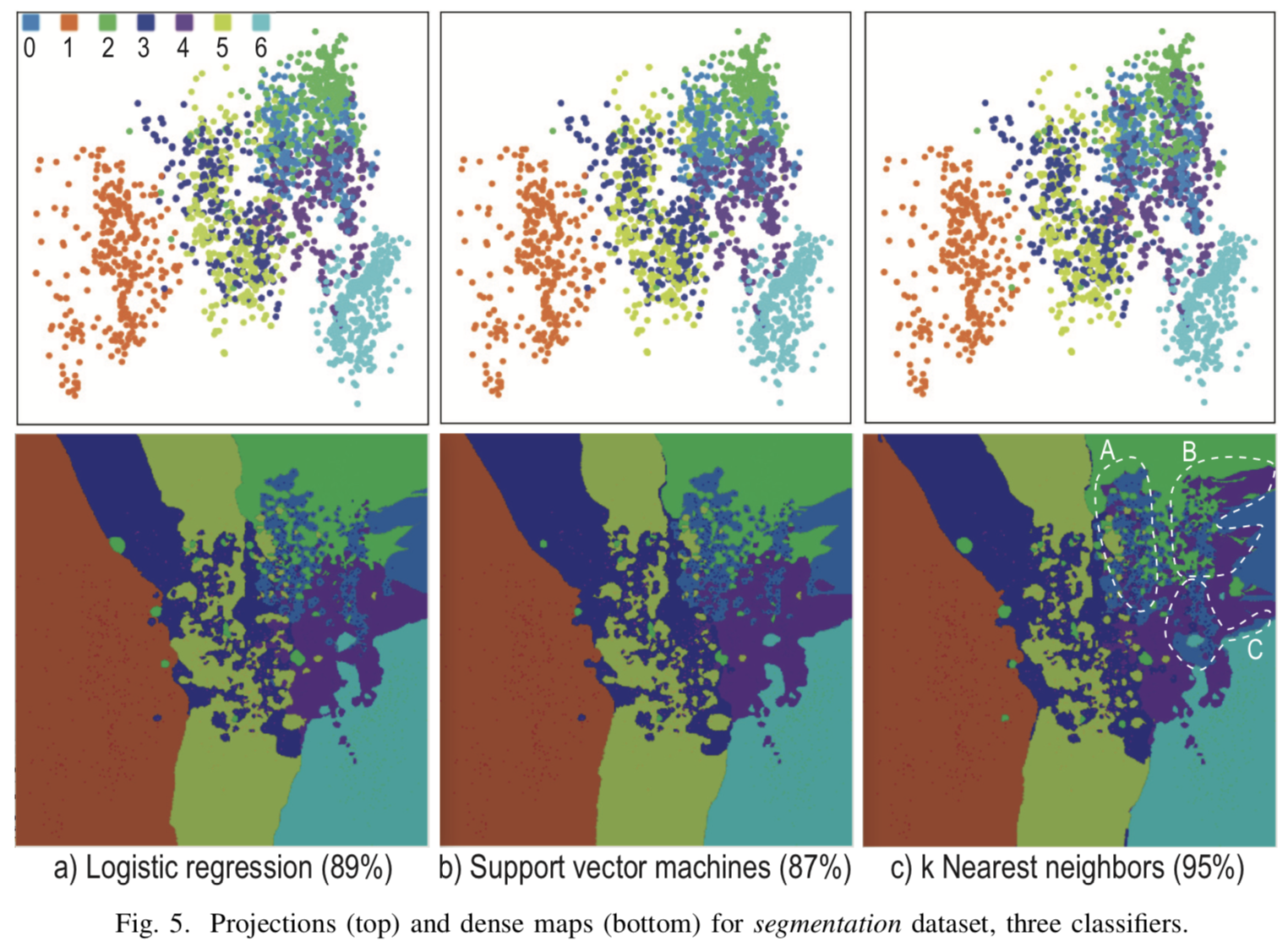
[Fig. 4] O resultado da visualização de três classificadores diferentes para k = 7, R = 500x500, N = 5
Conclusão
A visualização de limites de classe pode ser usada na construção e depuração de um algoritmo decisivo, na seleção de hiperparâmetros, na luta contra a reciclagem, para apresentar e analisar os resultados.
O método descrito pelos autores do artigo original pode ser usado para qualquer problema de classificação, onde os dados podem ser representados como um conjunto de sinais de uma dimensão fixa. Diferentemente de outros algoritmos de visualização, essa abordagem pode ser usada para qualquer classificador arbitrariamente complexo e para conjuntos de dados com um número arbitrário de exemplos, mesmo com um número muito pequeno, porque mesmo com pequenas o algoritmo funciona de forma estável, sem perder muito em qualidade.