Olá pessoal!
Você já deve saber sobre a iniciativa Machine Learning for Social Good (# ml4sg) da comunidade Open Data Science. Dentro de sua estrutura, os entusiastas usam métodos de aprendizado de máquina para resolver problemas socialmente significativos gratuitamente. Nós, a equipe do projeto Lacmus (#proj_rescuer_la), estamos envolvidos na implementação de soluções modernas de Deep Learning para encontrar pessoas perdidas fora da área povoada: na floresta, campo, etc.

Segundo estimativas aproximadas, na Rússia mais de cem mil pessoas desaparecem todos os anos. A parte tangível deles são pessoas que se perderam longe da habitação humana. Felizmente, alguns dos perdidos são escolhidos por eles mesmos; equipes de busca e resgate voluntárias são mobilizadas para ajudar os outros. O mais famoso desapego é talvez o Lisa Alert, mas quero observar que ele não é o único.
Os principais métodos de busca no momento, no século XXI, são pentear os arredores a pé usando meios técnicos, que geralmente não são mais complicados do que uma sirene ou um farol agitado. O tópico, é claro, é relevante e quente, gera muitas idéias para o uso do progresso científico e tecnológico na busca de conquistas; alguns deles são incorporados na forma de protótipos e testados em competições especialmente organizadas. Mas a floresta é a floresta, e as condições reais da pesquisa, juntamente com os limitados recursos materiais, tornam esse problema difícil e ainda muito longe de uma solução completa.
Recentemente, as equipes de resgate estão cada vez mais usando veículos aéreos não tripulados (VANTs) para examinar grandes áreas do território, fotografando o terreno a uma altura de 40 a 50 m. Com uma operação de busca e salvamento, são obtidos milhares de fotografias e, até o momento, os voluntários examinam manualmente. É claro que esse processamento é longo e ineficiente. Após duas horas de trabalho, os voluntários se cansam e não podem continuar a busca e, afinal, a saúde e a vida das pessoas dependem de sua velocidade.
Juntamente com as equipes de busca e resgate, estamos desenvolvendo um programa para procurar pessoas desaparecidas em imagens tiradas com UAVs. Como especialistas em aprendizado de máquina, nos esforçamos para tornar a pesquisa automática e rápida.

Diferenças de soluções semelhantes
Seria injusto dizer que o Lacmus é o único projeto que está sendo desenvolvido nessa direção. No entanto, parece que poucas pessoas estão se desenvolvendo em estreita cooperação com equipes de resgate, concentrando-se em suas necessidades e capacidades urgentes. Há algum tempo, foi realizada a competição Odyssey, na qual diferentes equipes competiram na formação da melhor solução para pesquisar e salvar pessoas, incluindo o uso de UAVs. Estando no estágio inicial de desenvolvimento, participamos dessa competição não como participantes, mas como observadores. Comparando os resultados da competição, informações sobre projetos semelhantes e nossa experiência na comunicação com equipes como Lisa Alert, Owl, Extreme, quero observar os problemas inerentes a muitos análogos:
- O custo da implementação. Algumas equipes do concurso Odyssey estão desenvolvendo seus próprios drones e UAVs inovadores. Mas você precisa entender que o PSO na Rússia geralmente opera sem fins lucrativos, e equipar os operadores de drones com máquinas no valor de mais de 1.000.000 de rublos é muito caro. Além disso, não basta apenas produzir uma aeronave, é necessário estabelecer sua manutenção. É difícil para as pequenas empresas oferecer soluções pelo mesmo dinheiro que as dos concorrentes chineses difíceis.
- O foco comercial de muitas soluções. Não há nada errado com os projetos de negócios, mas encontrar pessoas perdidas na floresta é uma tarefa bastante específica; nem todo desenvolvimento comercial pode ser integrado a ela. Você pode criar um drone maravilhoso e colocar um neurônio reconhecendo as culturas lá, mas é improvável que esse projeto seja útil para encontrar pessoas na floresta usando equipes de pesquisa voluntária: aqui você precisa da solução mais barata, mas eficaz. Câmeras multicanais caras não são adequadas aqui. Apenas RGB, apenas hardcore. Pelas mesmas razões, os termovisores também desaparecem, cujos modelos baratos têm uma resolução muito baixa. (E, em geral, os termovisores são ineficazes aqui, porque uma pessoa congelada na floresta emite muito pouco calor).
- As arquiteturas de redes neurais populares usadas nas soluções conhecidas - YOLO, SSD, VGG - têm métricas de boa qualidade em conjuntos de dados públicos como o ImageNet, mas não funcionam bem em imagens em nossa área de domínio bastante específica. (Sobre a escolha da arquitetura de rede neural, opções e recursos testados e testados usados no final - abaixo).
- Quase ninguém usa as oportunidades para otimizar modelos para inferência. Nas áreas de pesquisa, geralmente não há conexão com a Internet; portanto, você precisa processar as imagens recebidas localmente. A maioria das equipes de resgate usa laptops com GPUs de baixa potência, ou mesmo sem eles, executando redes neurais em CPUs convencionais. É fácil calcular que, se uma média de 10 segundos for gasta no processamento de uma única imagem, 1000 imagens serão processadas em cerca de 3 horas. Aqui, podemos dizer que cada segundo é importante.
- Fechamento dos desenvolvimentos existentes. Todas as soluções que conhecemos são fechadas e proprietárias. Mas o problema é complexo demais para ser resolvido pelas forças de um pequeno punhado de pessoas e não por todos que estão prontos para ajudar. Portanto, estamos desenvolvendo uma solução totalmente de código aberto: é estranho pensar que um tópico que atraia tantos voluntários que trabalham “no campo” não será igualmente interessante para os especialistas em TI.
- Falta de liberdade de distribuição. Os PSOs voluntários geralmente não são centralizados, as abordagens e os aplicativos de trabalho são transferidos de mão em mão; o software com cópias licenciadas não funciona aqui. É por isso que, entre outras coisas, escolhemos uma estratégia de código aberto e distribuição aberta para que qualquer pessoa possa baixar e usar nossa solução. Somos a favor da ciência aberta e do código aberto!
Preparação de dados
Parece que se toda operação de busca usando UAVs trouxer milhares de fotos, a matriz de dados acumulados deve ser enorme - pegue e treine. Nem tudo acabou sendo tão simples, porque:
- Não há armazenamento centralizado para dados marcados. As fotos tiradas durante as operações de busca não são usadas ou processadas no futuro.
- Os dados obtidos são muito desequilibrados. Em uma foto com a pessoa encontrada, existem vários milhares de fotografias "em branco". Como as informações sobre as imagens digitalizadas não são gravadas em nenhum lugar, para encontrar as necessárias entre elas, é necessário realizar uma grande quantidade de trabalho pela segunda vez - pelos esforços de uma pequena equipe que não possui “olhos treinados”.
- Cada imagem, por si só, também é "desequilibrada": a pessoa desejada ocupa uma pequena fração de toda a área da imagem nela. Obviamente, uma boa rede neural não deve apenas ser capaz de dizer que, na opinião dela, uma pessoa está presente na imagem - ela deve circular um local específico (isto é, executar a tarefa de detectar objetos, não classificar imagens). Caso contrário, o operador gastará tempo e energia extras olhando para ele e também poderá rejeitar por engano a foto desejada. Mas, para isso, a rede neural deve aprender com os dados marcados, nas fotografias, onde o objeto desejado é marcado usando um software especial. Ninguém fará isso durante uma operação de pesquisa - não antes.
- As estatísticas sobre as poses em que as pessoas foram encontradas, a época do ano, o tipo de terreno e outras características das fotos não são levadas em consideração. Esses dados seriam muito úteis para a criação de imagens de treinamento "sintéticas" usando fotografia em etapas, editores de fotos ou modelos generativos - mas, para usar tudo isso, você precisa entender como uma foto se parece com uma pessoa realmente perdida. Agora, ao reconstruir essas fotografias, é preciso confiar na experiência subjetiva dos especialistas em resgate.
- Além das dificuldades técnicas, são possíveis obstáculos legais que impõem restrições à propriedade das imagens obtidas. Muitas vezes, nossos pedidos de ajuda na coleta de dados permanecem completamente sem resposta. Devido à falta de tais dados, problemas legais ou preguiça comum - isso não é claro.
Portanto, informações valiosas não são usadas de forma alguma para o treinamento de redes neurais, sendo perdidas ou mortas em algum lugar em discos e armazenamentos em nuvem, em vez de melhorar o volume e a qualidade da amostra de treinamento. Estamos escrevendo um serviço que permitirá, entre outras coisas, enviar fotos valiosas para nós (sobre isso também abaixo), mas há, como sempre, mais tarefas do que pessoas.
Além disso, até o momento, a rede possui muito poucos conjuntos de dados bons (abertos) com imagens de UAVs. O mais adequado que encontramos é o
Stanford Drone Dataset (SDD) . É uma fotografia de uma altura acima do campus universitário, com objetos marcados da classe "Pedestre" (pedestre), juntamente com ciclistas, ônibus e carros. Apesar do ângulo de disparo similar, os pedestres fotografados e o ambiente têm pouco em comum com o que está acontecendo em nossas fotos. As experiências realizadas neste conjunto de dados mostraram que as métricas de qualidade dos detectores treinados em nossos dados mostram um resultado baixo. Como resultado, agora usamos o SDD para treinar o chamado backbone, que extrai atributos de nível superior, e as camadas extremas precisam ser concluídas nas imagens da nossa área de domínio.
É por isso que nos comunicamos pela primeira vez com vários mecanismos de busca e equipes de resgate por um longo tempo, tentando entender como uma pessoa que estava perdida na floresta se parece com uma foto de cima. Como resultado, coletamos estatísticas exclusivas sobre 24 poses, nas quais as pessoas desaparecidas são mais frequentemente encontradas. Filmamos e marcamos nosso próprio conjunto de dados - Lacmus Drone Dataset (LaDD), que na primeira versão incluía mais de 400 imagens. As filmagens foram realizadas principalmente com a ajuda do DJI Mavic Pro e Phantom, a uma altura de 50 a 100 metros, a resolução das fotos era 3000x4000, o tamanho médio da pessoa era 50x100 px. No momento, já temos a quarta versão do conjunto de dados com 2 mil imagens, reais e “simuladas”. Continuamos trabalhando para reabastecer o conjunto de dados e a quinta versão está chegando.
À medida que reabastecemos nosso conjunto de dados, chegamos à necessidade de separar as imagens por estação. O fato é que um modelo treinado em fotos de inverno mostra melhores resultados do que um modelo treinado em todo o conjunto de dados, seja no verão ou na primavera separadamente. Talvez os sinais em um fundo nevado sejam melhor extraídos do que em grama barulhenta.

Ao mesmo tempo, ao treinar apenas em fotos de inverno, o número de falsos positivos (falsos positivos) aumenta. Aparentemente, as imagens de diferentes estações do ano são paisagens muito diferentes (domínios) e a rede neural não é capaz de generalizá-las. Isso ainda precisa ser visto, e até agora vemos duas maneiras:
- Faça muitas grades “pequenas” e aprenda-as para diferentes domínios separadamente (uma para o inverno, outra para o verão ... Além das estações do ano, você também pode dividir por área: por exemplo, um modelo para a faixa e planície do meio, outro para o sul etc.) .
- Aumente repetidamente nossos dados e tente treinar o modelo de uma só vez em todos os domínios. Com base na solução de um problema semelhante em um artigo da Yandex, tendemos a tentar esta opção específica. É difícil coletar um grande número de fotos reais com pessoas perdidas pelos motivos já descritos, portanto, talvez, tentaremos recriar exemplos educacionais realistas com base em imagens "vazias" (existem muitas). Portanto, em breve poderemos ter GANs.
Processo de aprendizagem
A natureza de nossas imagens é significativamente diferente das imagens de conjuntos de dados populares como ImageNet, COCO etc. Como as redes neurais desenvolvidas para esses conjuntos podem ser pouco adequadas para a nossa tarefa, foi necessário realizar um estudo da aplicabilidade de várias arquiteturas. Para fazer isso, pegamos modelos pré-treinados no ImageNet, treinamos novamente no Stanford Drone Dataset, após o qual "congelamos" os backbones e as demais partes dos detectores foram treinadas diretamente em nossas imagens. As melhores métricas são apresentadas na tabela:
Além dos números na tabela acima, você deve prestar atenção a esse recurso das imagens do conjunto de dados do Lacmus Drone como um grande desequilíbrio de classe: a proporção da área de plano de fundo com a área do retângulo (âncora) com o objeto desejado é de vários milhares. Ao treinar o detector, isso envolve dois problemas:
- A maioria das regiões com plano de fundo não carrega nenhuma informação útil.
- As regiões com objetos devido ao seu pequeno número também não contribuem significativamente para o treinamento de pesos.
Para contornar esses problemas, vários esquemas de treinamento, configurações de rede e amostras de treinamento foram usados. Uma das arquiteturas de redes neurais que testamos, o RetinaNet, visa exatamente a reduzir os efeitos negativos de um grande desequilíbrio de classe. Os criadores do RetinaNet o projetaram para aumentar a precisão dos detectores de um estágio (cobrindo a imagem com uma densa rede de retângulos-âncoras predefinidos e refinando aqueles que melhor cobrem o objeto) em comparação com os detectores de dois estágios de melhor qualidade, mas mais lentos (os alunos aprendendo a encontrar primeiro as regiões candidatas) , especifique sua posição). Do ponto de vista dos autores do artigo sobre o RetinaNet, os detectores de um estágio perdem precisamente devido ao desequilíbrio causado por um grande número de âncoras vazias. No contexto dessa vantagem, nossa escolha foi feita em favor da RetinaNet com o backbone ResNet50.
A arquitetura desta rede
foi introduzida em 2017. A principal característica do RetinaNet, que permite lidar com os efeitos negativos dos desequilíbrios de classe no treinamento, é a função original de
perda de perda
focal :
Onde
p é a probabilidade estimada do conteúdo na região do objeto desejado estimado pelo modelo (para simplificar, a saída da rede neural se for reduzida ao intervalo [0, 1]).
Em outros domínios, a função de perda deve, em regra, ser resistente a instâncias atípicas (exemplos concretos), que provavelmente são discrepantes; seu impacto no treinamento com pesos deve ser reduzido. Na perda focal, pelo contrário, a influência de um fundo que ocorre com frequência (inliers, exemplos fáceis) é reduzida e objetos raramente vistos têm a maior influência no treinamento de pesos RetinaNet. Isso é feito devido a esta parte da fórmula:
Coeficiente
no expoente determina o "peso" de exemplos concretos na função de perda total.
Durante o processo de treinamento do RetinaNet, a função de perda é calculada para todas as orientações consideradas das áreas candidatas (âncoras), de todos os níveis de escala de imagem. No total, existem cerca de 100 mil áreas para uma imagem, o que é muito diferente da amostragem heurística (RPN) ou a pesquisa de instâncias raras (OHEM, SSD) se aproxima com um pequeno número de áreas (cerca de 256) para cada minibatch. O valor da perda focal é calculado como a soma dos valores da função para todas as âncoras, normalizados pelo número de âncoras que contêm os objetos desejados. A normalização é realizada apenas neles, e não no número total, uma vez que a grande maioria das âncoras é um fundo facilmente identificável, com pouca contribuição para a função de perda geral.
Estruturalmente, o RetinaNet consiste em um backbone e duas definições adicionais de Subnet de Classificação e Subnet de Regressão de Caixa.
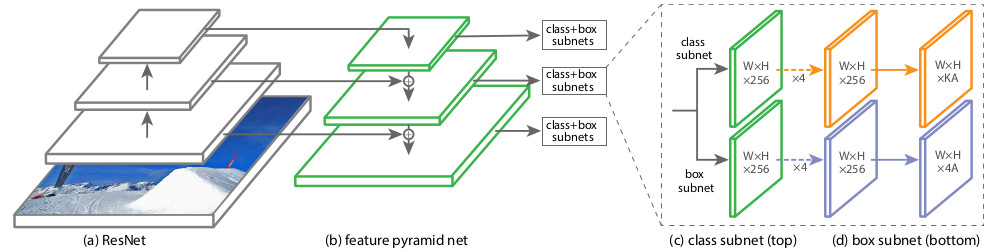
Como espinha dorsal, é usada a chamada
Rede de Pirâmide de Recursos , FPN, trabalhando em cima de uma das redes neurais convolucionais comumente usadas (por exemplo, ResNet50). O FPN possui saídas laterais adicionais de camadas ocultas da rede de convolução, formando níveis de pirâmide com diferentes escalas. Cada nível é complementado por um "caminho de cima para baixo", ou seja, informações de níveis mais altos que são menores, mas contêm informações sobre áreas de uma área maior. Parece um aumento artificial (por exemplo, simplesmente repetindo os elementos) de um mapa de recursos mais "minimizado" para o tamanho do mapa atual, adicionando-os elemento por elemento e transferindo-os para níveis mais baixos da pirâmide e para a entrada de outras sub-redes (ou seja, na Sub-rede de classificação e Sub-rede de regressão de caixa). Isso permite selecionar na imagem original uma pirâmide de sinais em diferentes escalas, nas quais objetos grandes e pequenos podem ser detectados. O FPN é usado em muitas arquiteturas, melhorando a detecção de objetos de vários tamanhos: RPN, DeepMask, Fast R-CNN, Mask R-CNN, etc.
Você pode ler mais sobre o FPN no
artigo original.
Em nossa rede, como no original, o FPN com 5 níveis numerados com
por
. Nível
tem permissão para
vezes menor que a imagem de entrada (não entraremos em detalhes de quais pontos do ResNet eles vêm - isso vai quebrar a perna). Todos os níveis da pirâmide têm o mesmo número de canais C = 256 e o número de âncoras A cerca de 1000 (dependendo do tamanho das imagens).
As âncoras têm áreas de [16 x 16] a [256 x 256] para cada nível da pirâmide de
antes
consequentemente, com um passo de deslocamento (passadas) [8 - 128] px. Esse tamanho permite analisar pequenos objetos e alguns arredores. Por exemplo, um galho, se você não levar em conta a realidade circundante, é muito semelhante a uma pessoa mentirosa.
O FPN original usa três proporções das âncoras (1: 2, 1: 1, 2: 1); RetinaNet aspect ratio [
]. 9- , / 16 400 px.
Classification Subnet . (Fully ConvNet, FCN), FPN. , :
- (W x H x C)
- 33
- ReLU
- 33 ( ) ,
- -
x A, K — . — Pedestrian.
Box Regression Subnet 4- . , FPN, Classification Subnet. , , (4 ) — :
, , IoU (Intersection over Union) > 0.5.
1, 0. .
( ) forward . 1k , 0,05. , threshold = 0,5.
RetinaNet
towardsdatascience .
, . OpenSource-, Github fizyr:
keras-retinanet , .
, , 20-30 . , :
E também ...
- Nvidia Jetson
- Corral Edge TPU
tensoflow 1.14 CPU AVX Intel nndl. AVX ( 2012 ) , Core 2 Duo!
Albumentations .
:
Produção
docker
desktop- c , . Nvidia Cuda CuDNN TensorFlow — . , Python . - , . — Docker. web- . , docker-. GUI . GUI , , , , . Docker API, GUI, . , Docker , .
#
. 3 :
dotnext . «! - ! - ? », — ! GUI # AvaloniaUI, 64- Win10, Linux Mac.
AvaloniaUI — , . WPF, , . , 2D- , WPF. , WPF.
, SkiaSharp GTK ( Unix ). X11 . , , (!). .Net Core Bios', AvaloniaUI .
AvaloniaUI , , . , 2019 , . WPF C# — . ( electron), , .
 ...
..., , issue. , ,
,
.
.
@kekekeks . , .NET .
desktop- mlOps- . :
- ;
- automatizar o processo de aprendizagem de uma rede neural, criar um ambiente para a pesquisa e fornecer acesso a outras pessoas;
- fornecer acesso à nuvem para equipes de busca e resgate, para que eles também possam usar os dados acumulados, se necessário;
A arquitetura geral do sistema se parece com isso:
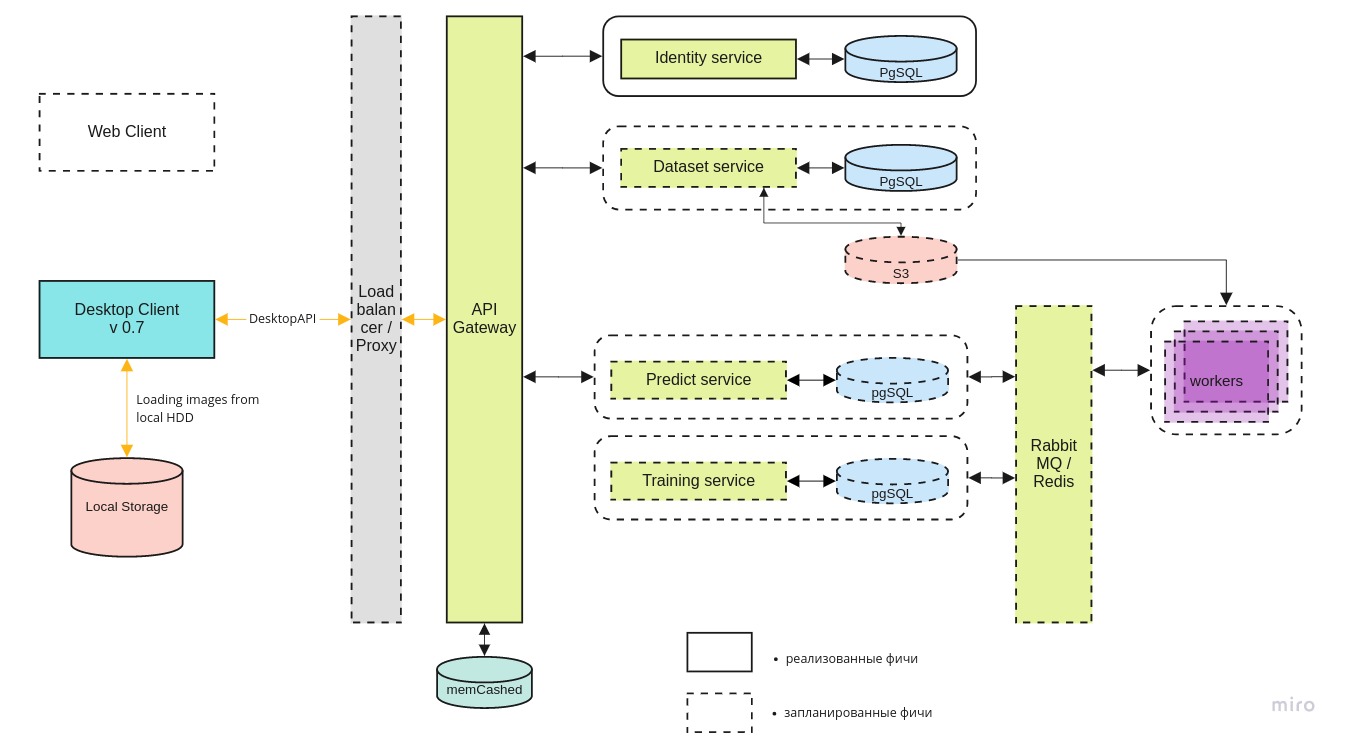 O cliente da área de
O cliente da área de trabalho pode trabalhar com a versão local do contêiner do docker e a versão mais recente no servidor central, por meio da API REST.
O microsserviço de
identidade fornece acesso ao servidor apenas para usuários autorizados.
O serviço de
conjunto de dados é usado para armazenar as próprias imagens e suas marcações.
O serviço
Predict permite processar rapidamente um grande número de imagens na presença de um amplo canal para pilotos.
É necessário um serviço de
treinamento para testar novos modelos e treinar novamente os existentes à medida que novos dados chegam.
A fila de tarefas é gerenciada usando o RabbitMQ / Redis.
Pesquisa de recursos de GPU
Apesar do fato de que a inferência da rede neural pode funcionar mesmo em um laptop simples, é necessária uma GPU para treinar o modelo. Tecnicamente, você pode treiná-lo na CPU, mas, na prática, leva muito tempo. Nem todas as pessoas que vêm para a equipe têm um computador adequado para o Deep Learning; portanto, estamos em busca dos recursos centralizados da GPU.
No momento, estamos negociando com a
DTL e esperamos que a cooperação se desenvolva. A singularidade dos servidores DTL GPU é o uso de refrigeração por imersão: imersão de racks em um fluido dielétrico especial. É assim:

 (Nota do fotógrafo: o azul não é um brilho de Cherenkov. É um destaque neles).
(Nota do fotógrafo: o azul não é um brilho de Cherenkov. É um destaque neles).Digressão lírica. "Você conhece a rede neural da Beeline?"
Honestamente, eu realmente não quero tocar nesse tópico (escorregadio), mas ele continua nos tocando, por isso é impossível fingir que estamos no tanque. Sim, conhecemos a rede neural da Beeline. De acordo com o feedback dos pilotos que colaboraram conosco, ele funciona pior que a nossa versão e apenas em plataformas de última geração. Segundo os desenvolvedores da Beeline - o projeto está congelado e não está sendo desenvolvido agora. Do ponto de vista do senso comum, as notícias no espírito da Beeline foram as primeiras na Rússia a desenvolver uma rede neural tão difícil. Poucas pessoas ainda implementam arquiteturas projetadas por laboratórios como o Facebook Research ou o Google Brain, e muito menos criam suas próprias. Na maioria das vezes, trata-se de adaptar uma biblioteca pública de código aberto às necessidades da sua área de assunto. Quantas vezes as bibliotecas abertas são usadas no software comercial russo, todos que desenvolvem esse software sabem. Na maioria das vezes, não há sequer uma violação da licença; mas deixar escapar as conquistas do OpenSource internacional como um todo, seu desenvolvimento e realizar PR alto é pelo menos feio. Parece que nossas realizações também foram usadas: em particular, em
nossa gamificação, nossas fotos foram
acesas. Compare com a foto "inverno" da seção sobre o conjunto de dados Lacmus:

Há outras razões para acreditar que o assunto não se limitou aos dados aqui.
O que é ruim para nós, em primeiro lugar, é que a rede neural da Beeline agora está desvinculada da impossibilidade. Quando mencionado, é impossível entender se é realmente sobre ela, ou sobre nosso aplicativo ou, em geral, sobre a opção de outra pessoa. Em condições de descentralização, pouca controlabilidade da JI e um pequeno número de canais de feedback, qualquer informação sobre a prevalência e a qualidade do trabalho em Lacmus seria útil, bem como sobre desenvolvimentos semelhantes - mas o hype em torno de Beeline ofuscou tudo.
Planejamos continuar monitorando a situação por enquanto, mas nosso pedido à comunidade é, em primeiro lugar, dizer "rede neural Beeline" somente quando eles tiverem 100% de certeza de que é isso e, em segundo lugar, ler licenças de código aberto e honestamente indicar autoria.
Sumário
Nos últimos 2019, os membros da Fundação Lacmus:
- Filmamos e marcamos um conjunto de dados exclusivo, cuja versão mais recente inclui mais de 2000 fotos;
- experimentou várias arquiteturas de redes neurais diferentes e escolheu a mais adequada;
- Selecionamos os melhores hiperparâmetros da rede neural e os treinamos em nossos próprios dados exclusivos para o reconhecimento mais preciso;
- desenvolveu um aplicativo de plataforma cruzada para operadores de UAV com a capacidade de usar ao trabalhar offline;
- otimizamos o trabalho da nossa rede neural para trabalhar com computadores portáteis econômicos e de baixo consumo de energia;
No momento, os melhores indicadores da métrica da rede neural LAPMUS são 94%. Nosso programa está pronto para uso em operações reais de busca e resgate e foi testado em execuções gerais. Em áreas abertas do tipo "campo" e "quebra-vento" foram encontrados todos os testes "perdidos". Já o Lakmus é usado por equipes de resgate e ajuda a encontrar pessoas.
E também recebemos o Prêmio do Projeto do Ano da Open Data Science:

Este ano planejamos:
- encontre um parceiro para uma infraestrutura de hospedagem confiável;
- implementar interface web e mlOps;
- formar um grande conjunto de dados sintéticos no mecanismo UE4 ou com a ajuda de GANs;
- lance uma competição InClass no Kaggle para todos que desejam atualizar suas habilidades de DL / CV e procurar as melhores soluções SOTA;
- adicione à nossa retinanet ainda mais implementações de backbones e variações dessa arquitetura;
Realmente não temos trabalhadores para implementar esses planos, por isso teremos prazer em todos, independentemente do nível e direção do treinamento.
Se juntos pudermos salvar pelo menos mais uma pessoa, todos os esforços não serão em vão.
Como ajudar o projeto
Somos um projeto OpenSource, e teremos o prazer de aceitar a todos! Aqui estão os links para nossos repositórios do github:
Se você é um desenvolvedor e deseja ingressar no projeto, pode escrever para Perevozchikov Georgy Pavlovich,
gosha20777 em todas as redes sociais,
gosha20777@live.ru ou participar do projeto pelo canal
# ml4sg no ODS (se você estiver lá).
Precisamos de:
- Desenvolvedores ML
- Desenvolvedores de C # / go / python;
- Trabalhadores da linha de frente;
- Beckers;
- Apenas pessoas ativas de qualquer direção! Teremos sempre o prazer de vê-lo!
Se você não estiver envolvido no desenvolvimento, também poderá ajudar o projeto:
- Você pode nos ajudar a escrever artigos;
- Você pode nos ajudar a escrever a documentação do usuário e um wiki (e corrigir erros gramaticais lá)))
- Você pode permanecer na função de gerente de produto e concluir tarefas no trello;
- Você pode nos oferecer uma ideia;
- Você pode distribuir esta postagem;
Sobre a equipe
Gerente de projeto: Georgy Pavlovich Perevozchikov,
gosha20777 .
Uma lista incompleta dos envolvidos (na verdade, é muito maior, se você foi esquecido injustamente, diga-me e adicionaremos):
- Os participantes mais ativos do ODS no canal #proj_rescuer_la : Kseniia, balezz, ei-grad, Palladdiumm, sharov_am, dartov
- Participantes do projeto fora da ODS: Martynova Viktoriya Viktorovna (organização do projeto, coleta e rotulagem de dados), Denis Petrovich Shurankov (organização da coleta de dados), Daria Pavlovna Perevozchikova (marcou cerca de 30% de todas as fotos).
- Operadores de UAV do esquadrão Liza Alert, que ajudaram com as imagens e a formação do conjunto de dados: Partyzan, Vanteyich, Sevych, Califórnia, Tarekon, Evgen, GB.
Agradecimentos especiais:
- Para programadores da AvaloniaUI - a melhor estrutura .NET: worldbeater , kekekeks , Larymar
- Administradores do ODS por organizar a comunidade mais legal: natekin, Sasha, mephistopheies.
Este artigo foi co-escrito com
balezz e
gosha20777 habrozhitelami .
Todos devem ser engenhosos e nunca se perder!
 Demonstração em vídeo do trabalho para a sobremesa. Versão pré-alfa-inicial. Para quem lê até o fim. Fevereiro 2019.
Demonstração em vídeo do trabalho para a sobremesa. Versão pré-alfa-inicial. Para quem lê até o fim. Fevereiro 2019.