Há dois anos, comecei o desenvolvimento mais um um gerador de código gratuito da OpenAPI Specification v3 para TypeScript ( está disponível no Github ). Inicialmente, decidi fazer uma geração eficiente de tipos de dados primitivos e complexos no TypeScript, levando em consideração vários recursos do esquema JSON , como oneOf / anyOf / allOf , etc. (A solução nativa do Swagger tinha alguns problemas com isso). Outra idéia foi usar esquemas de especificações para validação na parte frontal, traseira e outras partes do sistema.

Agora, o gerador de código está relativamente pronto - está no estágio MVP . Ele tem muito do que é necessário em termos de geração de tipos de dados, além de uma biblioteca experimental para gerar serviços de front-end (até agora para Angular). Neste artigo, quero mostrar os desenvolvimentos e dizer como eles podem ajudar se você usar o TypeScript e o OpenAPI v3. Ao longo do caminho, quero compartilhar algumas idéias e considerações que surgiram no meu processo de trabalho. Bem, se você estiver interessado, pode ler a história que eu escondi no spoiler para não complicar a leitura da parte técnica.
Conteúdo
- Antecedentes
- Descrição do produto
- Instalação e uso
- Pratique usando um gerador de código
- Usando tipos de dados gerados em aplicativos
- Decomposição de circuitos dentro da especificação da OEA
- Decomposição aninhada
- Serviços gerados automaticamente para trabalhar com a API REST
- Por que isso é necessário?
- Geração de serviços
- Usando serviços gerados
- Em vez de um posfácio
Antecedentes
Expandir para ler (pular)Tudo começou há dois anos - então eu trabalhei em uma empresa que desenvolvia uma plataforma de mineração de dados e fui responsável pelo frontend (principalmente TypeScript + Angular). Os recursos do projeto eram estruturas de dados complexas com um grande número de parâmetros (30 ou mais) e nem sempre relações comerciais óbvias entre eles. A empresa estava crescendo e o ambiente de software passava por mudanças bastante frequentes. O front-end tinha que ter conhecimento das nuances, porque alguns cálculos foram duplicados na frente e no back-end. Ou seja, esse foi o caso ao usar o OpenAPI é mais do que apropriado. Encontrei um período na empresa em que, em questão de meses, a equipe de desenvolvimento adquiriu uma única especificação, que se tornou uma base de conhecimento comum para os departamentos de back, front e até mesmo o Core, que estavam escondidos atrás da ampla parte de trás do back-end da web. A versão OpenAPI foi escolhida “para crescimento” - e ainda muito jovem v3.0
Isso não era mais uma especificação em um ou mais arquivos YML / JSON estáticos, e não o resultado de anotadores , mas toda uma biblioteca de componentes, métodos, modelos e propriedades, organizados de acordo com o conceito DDD da plataforma. A biblioteca foi dividida em diretórios e arquivos, e um colecionador especialmente organizado produziu documentos da OEA para cada área de estudo. Uma maneira experimental foi o fluxo de trabalho construído, que poderia ser descrito como Design-First.
Há um bom artigo no blog da empresa Yandex.Money, que falou sobre Design First
O Design First e a especificação geral ajudaram a descralizar o conhecimento, mas um novo problema se tornou aparente - mantendo a relevância do código. A especificação descreveu várias dezenas de métodos e dezenas (e depois centenas) de entidades. Mas o código teve que ser escrito manualmente: tipos de dados, serviços para trabalhar com REST, etc. Um ou dois sprints com histórias paralelas mudaram bastante a imagem; adicione complexidade à fusão de várias histórias e ao fator humano. A rotina ameaçava ser significativa e a solução parecia óbvia - você precisa da geração de código. Afinal, as especificações da OEA já continham todo o necessário para não redigitá-lo manualmente. Mas não foi tão simples.
O frontend está no final do ciclo de produção, então senti mudanças mais dolorosas do que colegas de outros departamentos. Ao projetar a API REST, o ambiente de back-end estava decidindo e, mesmo após a aprovação do “Design First”, a inércia permaneceu; para o front-end, tudo parecia menos óbvio. De fato, eu entendi isso desde o início e comecei a sondar o solo com antecedência - quando a conversa sobre uma especificação "universal" estava apenas começando. Não se falava em escrever seu próprio gerador de código; Eu só queria encontrar algo pronto.
Fiquei desapontado Havia dois problemas: a versão 3.0 da OEA, com o apoio de quem parecia não haver pressa e a qualidade das soluções em si - naquela época (lembro-me há dois anos), consegui encontrar duas soluções relativamente prontas: da Swagger e da Microsoft (parece que ). No primeiro, o apoio à OEA 3.0 estava na versão beta profunda. O segundo funcionou apenas com a versão 2.x, mas não havia previsões inequívocas. A propósito, não consegui iniciar o gerador de código da Microsoft nem em um documento de teste no formato Swagger 2.0. A solução da Swagger funcionou, mas um esquema mais ou menos complicado com links $ ref se transformou em um incompreensível "ERRO!", E dependências recursivas enviaram-no para um loop infinito. Houve problemas com tipos primitivos . Além disso, eu não entendia muito bem como trabalhar com serviços gerados automaticamente - eles pareciam ser feitos para exibição, e seu uso real criava mais problemas do que eles resolviam (na minha opinião). E, finalmente, a integração do arquivo JAR em um CI / CD orientado ao NPM foi inconveniente: tive que baixar manualmente o instantâneo necessário , que parecia pesar 13 megabytes, e fazer algo com ele. De um modo geral, fiz uma pausa e decidi assistir o que acontece a seguir.
Após cerca de cinco meses, o problema da geração de código surgiu novamente. Eu tive que reescrever e expandir parte do aplicativo Web e, ao mesmo tempo, queria refatorar serviços antigos para trabalhar com a API REST e tipos de dados. Mas a avaliação da complexidade não foi otimista: de uma semana para duas - e isso é apenas para serviços REST e descrições de tipo. Não direi que isso me deprimiu muito, mas ainda assim. Por outro lado, nunca encontrei uma solução para geração de código e não esperei, e sua implementação dificilmente levaria menos tempo. Ou seja, não havia dúvida: o benefício é duvidoso, os riscos são grandes. Ninguém apoiaria essa idéia, e eu não a propus. Enquanto isso, as férias de maio se aproximavam e a empresa me "devia" vários dias por trabalhar no fim de semana. Durante duas semanas, fugi de todas as experiências de trabalho para a Geórgia, onde morei por quase um ano.
Entre festas e festas, eu precisava fazer alguma coisa e decidi escrever minha decisão. Trabalhar em cafés de verão perto de Vake Park foi surpreendentemente produtivo e voltei a Peter com um gerador de código pronto para tipos de dados. Então, por mais um mês, "terminei" os serviços nos finais de semana antes de ele estar pronto para o trabalho.
Desde o início, abri o gerador de código, trabalhando nele no meu tempo livre. Embora, de fato, ele tenha escrito um rascunho de trabalho. Não direi que a revisão / adaptação ocorreu sem problemas; e não vou dizer que eles foram significativos. Mas, em algum momento, notei que parei de usar a documentação Redoc / Swagger: navegar pelo código era mais conveniente, desde que o código estivesse sempre atualizado e com comentários. Logo, "pontuei" minhas realizações, sem desenvolvê-las, até que um colega (agora há seis meses que eu parti para outra empresa) me aconselhou a levá-las mais a sério (ele também veio com o nome).
Eu não tinha tempo livre suficiente e vários meses levaram para finalizar em segundo plano: playground , aplicação de teste, reorganização do projeto. Agora estou pronto para receber feedback.
Descrição do produto
No momento, a solução para geração de código inclui três bibliotecas NPM integradas no oscro @codegena e localizadas em um repositório comum:
Instalação e uso
A opção mais prática é usar nos scripts do NodeJS executados a partir da CLI. Primeiro você precisa instalar as dependências:
npm i @codegena/oapi3ts, @codegena/ng-api-service, @codegena/oapi3ts-cli
Em seguida, crie um arquivo js (por exemplo, update-typings.js ) com o código:
"use strict"; var cliLib = require('@codegena/oapi3ts-cli'); var cliApp = new cliLib.CliApplication; cliApp.createTypings();
E comece passando três parâmetros:
node ./update-typings.js --srcPath ./specs/todo-app-spec.json --destPath ./src/lib --separatedFiles true
No destPath serão gerados arquivos e, de fato, o conteúdo desse diretório no repositório do projeto é criado da mesma maneira. Aqui está o script de geração , e é assim que ele é executado nos scripts do NPM. No entanto, se desejar, você pode usá-lo mesmo no navegador, como é feito no Playground .
Pratique usando um gerador de código
Em seguida, quero falar sobre o que obteremos como resultado: qual é a ideia de como isso nos ajudará. Um auxílio visual será o código do aplicativo de demonstração. Consiste em duas partes: um back-end (na estrutura NestJS ) e um front-end (no Angular ). Se desejar, você pode até executá-lo localmente .
Mesmo que você não esteja familiarizado com Angular e / ou NestJS, isso não deve causar problemas: os exemplos de código que serão fornecidos devem ser entendidos pela maioria dos desenvolvedores de TypeScript.
Embora o aplicativo seja o mais simplificado possível (por exemplo, o back-end armazena dados em uma sessão, não no banco de dados), tentei recriar o fluxo de dados e a hierarquia de tipos de dados inerentes ao aplicativo real. Está cerca de 80-85% pronto, mas o "acabamento" pode ser adiado, mas por enquanto é mais importante falar sobre o que já está lá.
Usando tipos de dados gerados em aplicativos
Suponha que tenhamos uma especificação OpenAPI (por exemplo, esta ) com a qual devemos trabalhar. Não importa se criamos algo do zero ou apoiamos, existe uma coisa importante com a qual provavelmente começaremos - digitando. Começaremos a descrever os tipos de dados básicos ou a fazer alterações neles. A maioria dos programadores faz isso para facilitar seu desenvolvimento futuro. Portanto, você não precisa examinar a documentação mais uma vez, lembre-se das listagens de parâmetros; e você pode ter certeza de que o IDE e / ou o compilador perceberão um erro de digitação.
Nossa especificação pode ou não incluir a seção components.schem . Mas, de qualquer forma, descreverá conjuntos de parâmetros, solicitações e respostas - e podemos usá-lo. Considere um exemplo:
@Controller('group') export class AppController {
Este é um fragmento de controlador para a estrutura NestJS com os parâmetros ( RewriteGroupParameters ), corpo da solicitação ( RewriteGroupRequest ) e corpo da resposta ( RewriteGroupResponse<T> ) RewriteGroupResponse<T> . Já neste fragmento de código, podemos ver os benefícios da digitação:
- Se confundirmos o nome do parâmetro destruído
groupId , especificando groupId , obteremos imediatamente um erro no editor.

- Se o método this.appService.rewriteGroup (groupId, body) tiver digitado parâmetros, poderemos controlar a correção do parâmetro do
body passado. E se o formato dos dados de entrada do método do controlador ou do método de serviço mudar, nós o saberemos imediatamente. No futuro, observo que o método de entrada do método de serviço possui um tipo de dados diferente de RewriteGroupRequest , mas, no nosso caso, eles serão idênticos. No entanto, se de repente o método de serviço for alterado e começar a aceitar o ToDoGroup vez do ToDoGroupBlank , o IDE e o compilador mostrarão imediatamente os locais das discrepâncias:
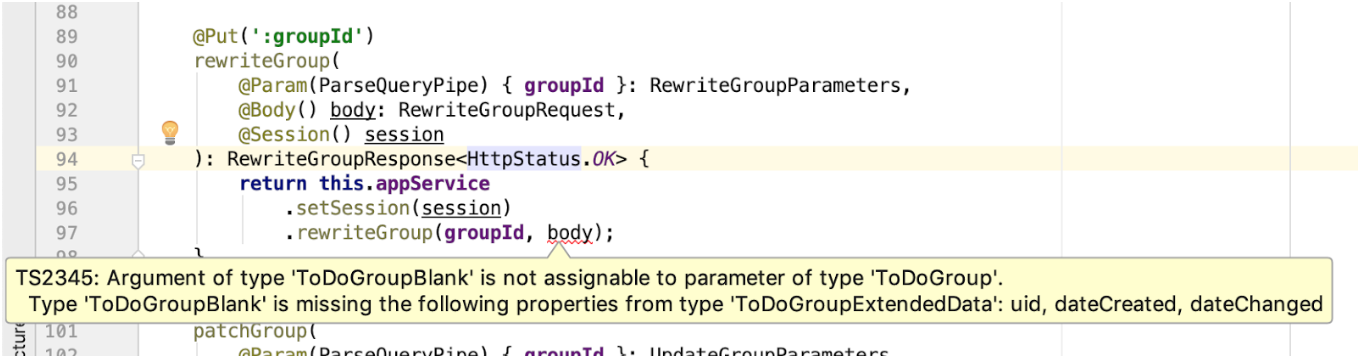
- Da mesma maneira, podemos controlar a conformidade do resultado retornado. Se a especificação do status de uma resposta bem-sucedida for alterada e se tornar
202 vez de 200 , também descobriremos isso, porque RewriteGroupResponse é um genérico com um tipo enumerado :

Agora, vamos ver um exemplo do aplicativo front-end que funciona com outro método da API :
protected initSelectedGroupData(truth: ComponentTruth): Observable<ComponentTruth> { return this.getGroupsService.request(null, { isComplete: null, withItems: false }).pipe( pickResponseBody<GetGroupsResponse<200>>(200, null, true), switchMap<ToDoGroup[], Observable<ComponentTruth>>( groups => this.loadItemsOfSelectedGroups({ ...truth, groups }) ) ); }
Não vamos nos antecipar e analisar o operador RxJS customizado pickResponseBody , mas vamos nos concentrar no refinamento do tipo GetGroupsResponse . Nós o usamos em uma cadeia de operadores RxJS, e o operador a seguir possui um refinamento de entrada de ToDoGroup[] . Se esse código funcionar, os tipos de dados indicados correspondem um ao outro. Aqui também podemos controlar a correspondência de tipos e, se o formato da resposta em nossa API mudar repentinamente, isso não escapará à nossa atenção:
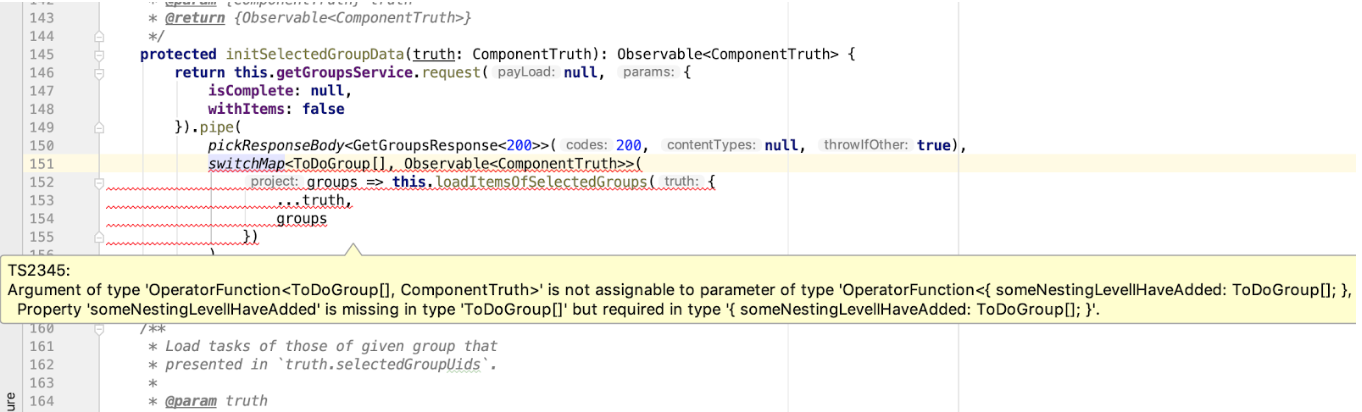
E, é claro, os parâmetros de chamada this.getGroupsService.request também this.getGroupsService.request digitados. Mas este é o tópico dos serviços gerados.
Nos exemplos acima, vemos que a digitação de solicitações, respostas e parâmetros pode ser usada em várias partes do sistema - front-end, back-end etc. Se o back-end e o front-end estiverem no mesmo mono-repositório e tiverem um ambiente ecológico compatível, eles poderão usar a mesma biblioteca compartilhada com o código gerado. Porém, mesmo que o back-end e o front-end sejam suportados por equipes diferentes e não tenham nada em comum, exceto a especificação pública da OEA, ainda será mais fácil sincronizar seu código.
Decomposição de circuitos dentro da especificação da OEA
Provavelmente, nos exemplos anteriores, você prestou atenção nas ToDoGroup , ToDoGroup , com as quais RewriteGroupResponse e GetGroupsResponse . Na verdade, RewriteGroupResponse é apenas um alias genérico para ToDoGroup , HttpErrorBadRequest , etc. É fácil adivinhar que ToDoGroup e HttpErrorBadRequest são os esquemas da seção de especificação components.schem referenciada pelo ponto de extremidade rewriteGroup (diretamente ou por meio de intermediários ):
"responses": { "200": { "description": "Todo group saved", "content": { "application/json": { "schema": { "$ref": "#/components/schemas/ToDoGroup" } } } }, "400": { "$ref": "#/components/responses/errorBadRequest" }, "404": { "$ref": "#/components/responses/errorGroupNotFound" }, "409": { "$ref": "#/components/responses/errorConflict" }, "500": { "$ref": "#/components/responses/errorServer" } }
Essa é a decomposição usual das estruturas de dados e seu princípio é o mesmo que em outras linguagens de programação. Os componentes, por sua vez, também podem ser decompostos: consulte outros componentes (incluindo recursivamente), use a combinação e outros recursos do Esquema JSON. Mas, independentemente da complexidade, eles devem ser convertidos corretamente em descrições de tipos de dados. Quero mostrar como você pode usar a decomposição no OpenAPI e como será o código gerado.
Os componentes em uma especificação da OEA bem projetada se sobrepõem ao modelo DDD dos aplicativos que o utilizam. Mas mesmo que a especificação seja imperfeita, você pode confiar nela, construindo seu próprio modelo de dados. Isso lhe dará mais controle sobre a correspondência dos seus tipos de dados com os tipos de subsistemas integráveis.
Como nosso aplicativo é uma lista de tarefas, a principal essência é a tarefa. É lógico colocá-lo nos componentes em primeiro lugar, porque outras entidades e terminais estarão de alguma forma conectados a ele. Mas antes disso você precisa entender duas coisas:
- Descrevemos não apenas a abstração, mas também as regras de validação, e quanto mais precisas e inequívocas forem, melhor.
- Como qualquer entidade armazenada em um banco de dados, uma tarefa possui dois tipos de propriedades: serviço e entrada do usuário.
Acontece que, dependendo do cenário de uso, temos duas estruturas de dados: a Tarefa que o usuário acabou de criar e a Tarefa que já está armazenada no banco de dados. No segundo caso, ele possui um UID exclusivo, data de criação, alteração etc., e esses dados devem ser atribuídos no back-end. Descrevi duas entidades ( ToDoTaskBlank e ToDoTask ) de tal maneira que a primeira é um subconjunto da segunda:
"components": { "ToDoTaskBlank": { "title": "Base part of data of item in todo's group", "description": "Data about group item needed for creation of it", "properties": { "groupUid": { "description": "An unique id of group that item belongs to", "$ref": "#/components/schemas/Uid" }, "title": { "description": "Short brief of task to be done", "type": "string", "minLength": 3, "maxLength": 64 }, "description": { "description": "Detailed description and context of the task. Allowed using of Common Markdown.", "type": ["string", "null"], "minLength": 10, "maxLength": 1024 }, "isDone": { "description": "Status of task: is done or not", "type": "boolean", "default": "false", "example": false }, "position": { "description": "Position of a task in group. Allows to track changing of state of a concrete item, including changing od position.", "type": "number", "min": 0, "max": 4096, "example": 0 }, "attachments": { "type": "array", "description": "Any material attached to the task: may be screenshots, photos, pdf- or doc- documents on something else", "items": { "$ref": "#/components/schemas/AttachmentMeta" }, "maxItems": 16, "example": [] } }, "required": [ "isDone", "title" ], "example": { "isDone": false, "title": "Book soccer field", "description": "The complainant agreed and recruited more members to play soccer." } }, "ToDoTask": { "title": "Item in todo's group", "description": "Describe data structure of an item in group of tasks", "allOf": [ { "$ref": "#/components/schemas/ToDoTaskBlank" }, { "type": "object", "properties": { "uid": { "description": "An unique id of task", "$ref": "#/components/schemas/Uid", "readOnly": true }, "dateCreated": { "description": "Date/time (ISO) when task was created", "type": "string", "format": "date-time", "readOnly": true, "example": "2019-11-17T11:20:51.555Z" }, "dateChanged": { "description": "Date/time (ISO) when task was changed last time", "type": "string", "format": "date-time", "readOnly": true, "example": "2019-11-17T11:20:51.555Z" } }, "required": [ "dateChanged", "dateCreated", "position", "uid" ] } ] } }
Na saída, temos duas interfaces TypeScript, e a primeira será herdada pela segunda :
export interface ToDoTaskBlank {
Agora, temos as descrições básicas da entidade Tarefa e as referimos a elas no código de nosso aplicativo, como foi feito no aplicativo de demonstração :
import { ToDoTask, ToDoTaskBlank, } from '@our-npm-scope/our-generated-lib'; export interface ToDoTaskTeaser extends ToDoTask { isInvalid?: boolean; isJustCreated?: boolean; isPending?: boolean; prevTempUid?: string; }
Neste exemplo, descrevemos uma nova entidade, adicionando ao ToDoTask as propriedades que nos faltam no lado do aplicativo front-end. Na verdade, expandimos o modelo de dados resultante, levando em consideração as especificidades locais. Em torno desse modelo, um conjunto de ferramentas locais e algo como um DTO primitivo aumentam gradualmente:
export function downgradeTeaserToTask( taskTeaser: ToDoTaskTeaser ): ToDoTask { const task = { ...taskTeaser }; if (!task.description || !task.description.trim()) { delete task.description; } else { task.description = task.description.trim(); } delete task.isJustCreated; delete task.isPending; delete task.prevTempUid; return task; } export function downgradeTeaserToTaskBlank( taskTeaser: ToDoTaskTeaser ): ToDoTaskBlank { const task = downgradeTeaserToTask(taskTeaser) as any; delete task.dateChanged; delete task.dateCreated; delete task.uid; return task; }
Alguém prefere tornar o modelo de dados mais integral e usar classes. export class ToDoTaskTeaser implements ToDoTask {
Mas isso é uma questão de estilo, adequação e como a arquitetura do aplicativo se desenvolverá. Em geral, independentemente da abordagem, podemos confiar em um modelo de dados básico e ter mais controle sobre a conformidade da digitação. Portanto, se por algum motivo o uid do ToDoTask se tornar um número, conheceremos todas as partes do código que exigem atualização:

Decomposição aninhada
Então agora temos a interface ToDoTask e podemos fazer referência a ela. Da mesma forma, descreveremos o ToDoTaskGroup e o ToDoTaskGroupBlank , e eles conterão propriedades dos tipos ToDoTask e ToDoTaskBlank , respectivamente. Mas agora vamos dividir o “Grupo de Tarefas” em dois, e não em três componentes: para maior clareza, descreveremos o delta em ToDoGroupExtendedData . Então, eu quero demonstrar uma abordagem na qual um componente é criado a partir dos outros dois:
"ToDoGroup": { "allOf": [ { "$ref": "#/components/schemas/ToDoGroupBlank" }, { "$ref": "#/components/schemas/ToDoGroupExtendedData" } ] }
Após iniciar a geração do código, obtemos uma construção TypeScript ligeiramente diferente:
export type ToDoGroup = ToDoGroupBlank &
Como o ToDoGroup não possui seu próprio "corpo", o gerador de código preferiu transformá-lo em uma união de interfaces. No entanto, se você adicionar a terceira parte com seu próprio esquema (anônimo), o resultado será uma interface com dois ancestrais (mas é melhor não fazer isso). E vamos observar que a propriedade de items da interface ToDoGroupBlank digitada como uma matriz do ToDoTaskBlank e redefinida no ToDoGroupBlank no ToDoTask . Assim, o gerador de código é capaz de transferir as nuances bastante complexas de decomposição do esquema JSON para o TypeScipt.
import { ToDoTaskBlank } from './to-do-task-blank'; export interface ToDoGroupBlank {
import { ToDoTask } from './to-do-task'; export interface ToDoGroupExtendedData {
Bem, é claro, no ToDoTask / ToDoTaskBlank também podemos usar a decomposição. Você deve ter notado que a propriedade attachments é descrita como uma matriz de elementos do tipo AttachmentMeta . E esse componente é descrito da seguinte maneira:
"AttachmentMeta": { "description": "Common meta data model of any type of attachment", "oneOf": [ {"$ref": "#/components/schemas/AttachmentMetaImage"}, {"$ref": "#/components/schemas/AttachmentMetaDocument"}, {"$ref": "#/components/schemas/ExternalResource"} ] }
Ou seja, esse componente se refere a outros componentes. Como ele não possui seu próprio esquema, o gerador de código não o transforma em um tipo de dados separado para não multiplicar entidades, mas transforma uma descrição anônima do tipo enumerado:
attachments?: Array< | AttachmentMetaImage
Ao mesmo tempo, para os componentes AttachmentMetaDocument e AttachmentMetaDocument , são descritas interfaces não anônimas importadas nos arquivos que as utilizam:
import { AttachmentMetaDocument } from './attachment-meta-document'; import { AttachmentMetaImage } from './attachment-meta-image';
Mas mesmo em AttachmentMetaImage , podemos encontrar um link para outra interface ImageOptions renderizada, usada duas vezes, inclusive dentro de uma interface anônima (o resultado da conversão de AdditionalProperties ):
import { ImageOptions } from './image-options'; export interface AttachmentMetaImage {
Assim, com base nas ToDoGroup ou ToDoGroup , na verdade integramos várias entidades ao código e a uma cadeia de suas conexões comerciais, o que nos dá mais controle sobre as alterações no sistema excessivo que vão além do nosso código. Obviamente, isso não faz sentido em todos os casos. Mas se você usa o OpenAPI, poderá ter mais um pequeno bônus, além da documentação real.
Serviços gerados automaticamente para trabalhar com a API REST
Por que isso é necessário?
Se usarmos um aplicativo front-end estatístico médio que funcione com uma API REST mais ou menos complexa, uma parte considerável de seu código será de serviços (ou apenas funções) para acessar a API. Eles incluem:
- Mapeamentos de URL e Parâmetro
- Validação de parâmetros, solicitação e resposta
- Extração de dados e manipulação de emergência
É desagradável que, em muitos aspectos, isso seja típico e não contenha nenhuma lógica única. Vamos supor um exemplo - como um esboço geral, o trabalho com a API pode ser construído:
Um exemplo esquemático simplificado de trabalho com a API REST import _ from 'lodash'; import { Observable, fromFetch, throwError } from 'rxjs'; import { switchMap } from 'rxjs/operators';
Você pode usar uma abstração de alto nível para trabalhar com o REST - dependendo da pilha usada, pode ser: Axios , Angular HttpClient ou qualquer outra solução semelhante. Mas o mais provável é que, basicamente, seu código coincida com este exemplo. Quase certamente, incluirá:
- Serviços ou funções para acessar pontos de extremidade específicos (função
getTasksFromServer em nosso exemplo) - Partes de código que processam o resultado (função
getRemainedTasks )
Em um aplicativo do mundo real, esse código será mais complicado: a especificação do aplicativo de demonstração descreve 5-6 opções de resposta . Freqüentemente, a API REST é projetada de forma que cada status de resposta do servidor seja tratado adequadamente. Mas mesmo a verificação dos dados de entrada tende a se tornar mais difícil no processo de desenvolvimento do aplicativo: quanto mais tempo leva para dar suporte e processar análises de erros, mais você deseja saber sobre os gargalos na circulação de dados no aplicativo.
Em cada nó do encaixe das peças do software podem ocorrer erros, a detecção prematura dos quais (bem como a pesquisa de problemas difíceis de diagnosticar) pode ser muito cara para os negócios. Portanto, haverá verificações adicionais de esclarecimento. À medida que a base de código cresce, e o número de casos cobertos, o mesmo acontece com a complexidade de fazer alterações. Mas os negócios são uma mudança constante, e não há como contornar isso. Portanto, devemos nos preocupar com como faremos alterações antecipadamente.
Voltando ao tópico OpenAPI, observamos que nas especificações da OEA pode haver informações suficientes para:
- Descreva todos os terminais necessários na forma de funções ou serviços
- URL
— . , , / — 5, 10 200, . , , : , , , RxJS- pickResponseBody , , - ; tapResponse , side-effect (tap) HTTP-. , - . , , .
, — -, . , , , "" / API "-" "" . - , "" ( ), .
, REST API Angular. , , /. . , , . , , .. .
" " . Angular-, update-typings.js :
"use strict"; var cliLib = require('@codegena/oapi3ts-cli'); var cliApp = new cliLib.CliApplication; cliApp.createTypings(); cliApp.createServices('angular');
, Angular- API . , - - , . , RewriteGroupService . ApiService , , , -:
, JSON Schema , . , , :
import { schema as domainSchema } from './schema.b4c655ec1635af1be28bd6';
, schema.b4c655ec1635af1be28bd6.ts , , .
, Angular-.
Angular-ApiModule :
import { ApiModule, API_ERROR_HANDLER } from '@codegena/ng-api-service'; import { CreateGroupItemService, GetGroupsService, GetGroupItemsService, UpdateFewItemsService } from '@codegena/todo-app-scheme'; @NgModule({ imports: [ ApiModule, // ... ], providers: [ RewriteGroupService, { provide: API_ERROR_HANDLER, useClass: ApiErrorHandlerService }, // ... ], // ... }) export class TodoAppModule { }
, [])( https://angular.io/guide/dependency-injection ):
@Injectable() export class TodoTasksStore { constructor( protected createGroupItemService: CreateGroupItemService, protected getGroupsService: GetGroupsService, protected getGroupItemsService: GetGroupItemsService, protected updateFewItemsService: UpdateFewItemsService ) {} }
— , request , :
return this.getGroupsService.request(null, { isComplete: null, withItems: false }).pipe( pickResponseBody<GetGroupsResponse<200>>(200, null, true), switchMap<ToDoGroup[], Observable<ComponentTruth>>( groups => this.loadItemsOfSelectedGroups({ ...truth, groups }) ) );
request Observable<HttpResponse<R> | HttpEvent<R>> , , . , , . , , , . RxJS- pickResponseBody .
, , , . API, . . , :
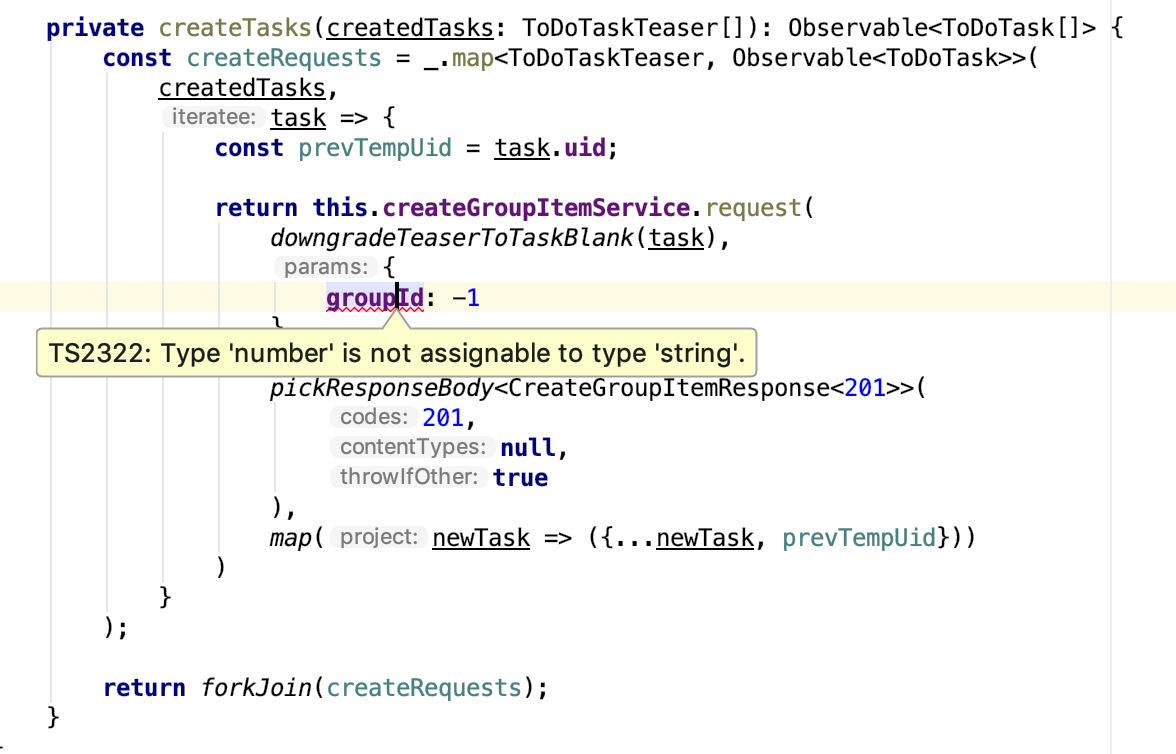
. JSON Schema . , "" - . , Sentry Kibana , . . , , .
, . , :)
Em vez de um posfácio
, . -, " " — . , , , .
— , - / ( ). , — .
.