HighLoad ++ Moscow 2018, sala de congressos. 9 de novembro, 15:00
Resumos e apresentação:
http://www.highload.ru/moscow/2018/abstracts/4066Yuri Nasretdinov (VKontakte): o relatório abordará a experiência de implementação do ClickHouse em nossa empresa - por que precisamos disso, quantos dados armazenamos, como escrevemos e assim por diante.

Recursos adicionais:
Usando o Clickhouse como um substituto para ELK, Big Query e TimescaleDB Yuri Nasretdinov: - Olá pessoal! Meu nome é Yuri Nasretdinov, como eles já me apresentaram. Eu trabalho na VKontakte. Vou falar sobre como inserimos dados no “ClickHouse” da nossa frota de servidores (dezenas de milhares).
O que são logs e por que coletá-los?
Sobre o que falaremos: o que fizemos, por que precisávamos do “ClickHouse”, respectivamente - por que o escolhemos, que tipo de desempenho você pode obter aproximadamente sem configurar nada especificamente. Vou falar mais sobre tabelas de buffer, sobre os problemas que tivemos com elas e sobre nossas soluções que desenvolvemos de código aberto - KittenHouse e Lighthouse.
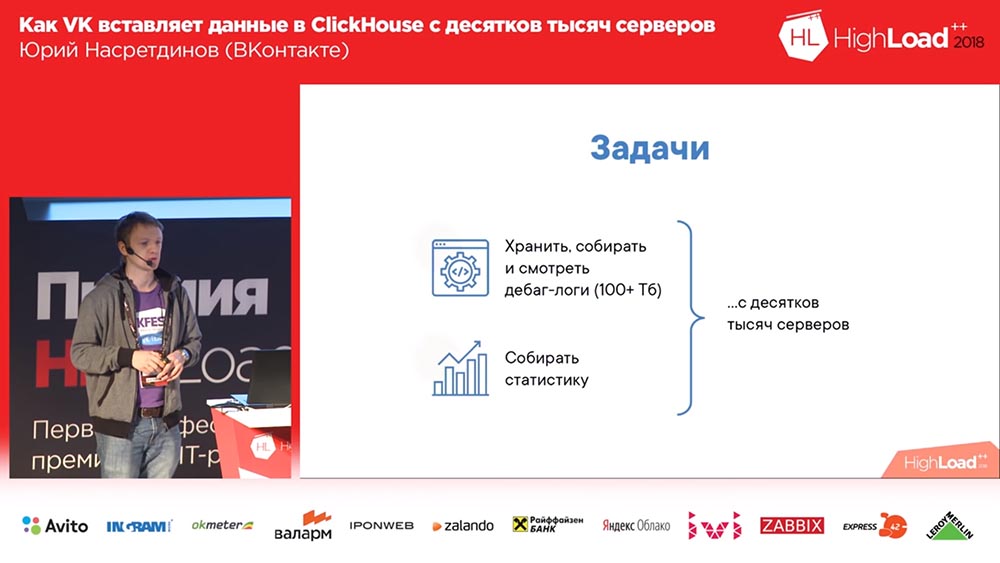
Por que precisamos fazer alguma coisa (no VKontakte tudo está sempre bem, certo?). Queríamos coletar logs de depuração (e havia centenas de terabytes de dados lá), talvez, de alguma forma, seja mais conveniente ler as estatísticas; e temos dezenas de milhares de servidores a partir dos quais tudo isso precisa ser feito.
Por que decidimos? Provavelmente tínhamos soluções para armazenar logs. Aqui - existe um público "Backend VK". Eu recomendo assinar.

O que são logs? Este é um mecanismo que retorna matrizes vazias. Motores em "VK" são o que outros chamam de microsserviços. E esse adesivo está sorrindo (muitas curtidas). Como assim? Bem, ouça!

O que pode ser usado para armazenar logs em geral? É impossível não mencionar o Khadup. Em seguida, por exemplo, Rsyslog (armazenamento nos arquivos desses logs). LSD Quem sabe o que é LSD? Não, esse LSD não. Os arquivos também são armazenados, respectivamente. Bem, ClickHouse é uma versão estranha de algum tipo.
Clickhouse e concorrentes: requisitos e oportunidades
O que nós queremos? Queremos que não precisemos tomar um banho de vapor especial com a operação, para que ele funcione imediatamente da caixa, com configuração mínima. Queremos escrever muito e escrever rápido. E queremos mantê-lo todos os meses, anos, ou seja, por um longo tempo. Podemos querer resolver algum tipo de problema que eles vieram até nós, eles disseram: "Algo não funciona aqui para nós", mas isso foi há 3 meses) e queremos ser capazes de vê-lo há três meses " Compactação de dados - é compreensível por que será uma vantagem - porque a quantidade de espaço ocupado é reduzida.

E temos um requisito tão interessante: às vezes escrevemos a saída de alguns comandos (por exemplo, logs), que podem ter mais de 4 kilobytes com bastante calma. E se isso funcionar no UDP, não será necessário gastar ... não haverá "sobrecarga" para a conexão e, para um grande número de servidores, isso será uma vantagem.

Vamos ver o que o código aberto oferece para nós. Em primeiro lugar, temos um mecanismo de logs - este é o nosso mecanismo; ele basicamente sabe tudo, até longas filas podem escrever. Bem, ele não comprime os dados de forma transparente - podemos comprimir grandes colunas se quisermos ... é claro que não queremos (se possível). O único problema é que ele só pode doar o que é colocado em sua memória; o resto, para ler, você precisa obter o binlog desse mecanismo e, consequentemente, leva um bom tempo.

Quais são as outras opções? Por exemplo, Khadup. Facilidade de uso ... Quem acredita que o Hadoup é fácil de configurar? Com a gravação, é claro, não há problemas. Com a leitura, às vezes surgem perguntas. Em princípio, eu diria que provavelmente não, especialmente para os logs. Armazenamento de longo prazo - é claro, sim, compactação de dados - sim, longas filas - é claro que você pode escrever. Mas para gravar de um grande número de servidores ... De qualquer forma, precisamos fazer algo sozinhos!
Rsyslog. Na verdade, nós o usamos como um substituto, para que fosse possível ler um binlog sem despejo, mas não conseguia gravar em linhas longas; em princípio, não conseguia escrever mais de 4 kilobytes. A compactação de dados deve ser feita da mesma maneira. A leitura irá dos arquivos.

Depois, há o desenvolvimento "ruim" do LSD. O mesmo é essencialmente o mesmo que o “Rsyslog”: ele suporta linhas longas, mas não sabe como usar o UDP e, de fato, por causa disso, infelizmente, há muitas coisas para reescrever lá. O LSD precisa ser refeito para que você possa gravar a partir de dezenas de milhares de servidores.

Ah aqui! Uma opção divertida é o ElasticSearch. Bem, como dizer? Está tudo bem com a leitura, ou seja, ele lê rapidamente, mas não muito bem com a escrita. Em primeiro lugar, se comprimir os dados, é muito fraco. Provavelmente, uma pesquisa completa requer mais estruturas de dados volumosas que o volume original. É difícil de explorar, muitas vezes surgem problemas com ela. E, novamente, uma entrada no "Elástico" - todos nós devemos fazer isso sozinhos.

Aqui ClickHouse - a opção ideal, é claro. A única coisa é que gravar de dezenas de milhares de servidores é um problema. Mas ela é pelo menos uma, podemos tentar resolver de alguma forma. E o restante do relatório é sobre esse problema. Qual o desempenho geral do ClickHouse que você pode esperar?
Como vamos incorporar? MergeTree
Quantos de vocês não ouviram falar do ClickHouse, não sabem? Precisa dizer, não é necessário? Muito rapido A inserção de 1-2 gigabits por segundo, rajadas de até 10 gigabits por segundo podem realmente suportar essa configuração - existem dois Xeons de 6 núcleos (isto é, nem os mais poderosos), 256 gigabytes de RAM, 20 terabytes por RAID (ninguém configurado, configurações padrão). Alexey Milovidov, desenvolvedor do ClickHouse, provavelmente chorando, que não configuramos nada (tudo funcionou assim para nós). Consequentemente, uma velocidade de varredura de, por exemplo, cerca de 6 bilhões de linhas por segundo pode ser obtida se os dados estiverem bem compactados. Se você gosta de% em uma linha de texto, 100 milhões de linhas por segundo, isto é, parece muito rapidamente.

Como vamos incorporar? Bem, você sabe disso em "VK" - em PHP. Nós, de cada trabalhador PHP, colaremos o HTTP no "ClickHouse", na placa MergeTree para cada entrada. Quem vê o problema neste circuito? Por alguma razão, nem todos levantaram as mãos. Vamos te contar.
Em primeiro lugar, existem muitos servidores - consequentemente, haverá muitas conexões (ruins). Então, no MergeTree, é melhor inserir dados não mais que uma vez por segundo. E quem sabe o porquê? Ok, bom. Vou falar um pouco mais sobre isso. Outra questão interessante é que nós, por assim dizer, não estamos fazendo análises, não precisamos enriquecer os dados, não precisamos de servidores intermediários, queremos incorporar diretamente no "ClickHouse" (de preferência - quanto mais reto, melhor).

Assim, como a inserção é implementada no MergeTree? Por que é melhor inseri-lo não mais que uma vez por segundo ou menos? O fato é que "ClickHouse" é um banco de dados colunar e classifica os dados em ordem crescente da chave primária e, quando você insere, o número de arquivos é criado por pelo menos o número de colunas nas quais os dados são classificados em ordem crescente da chave primária (um diretório separado é criado, um conjunto de arquivos em disco para cada inserção). Em seguida, a próxima inserção será inserida e, em segundo plano, eles se fundirão em uma "partição" maior. Como os dados são classificados, você pode "manipular" dois arquivos classificados sem consumir muito memória.
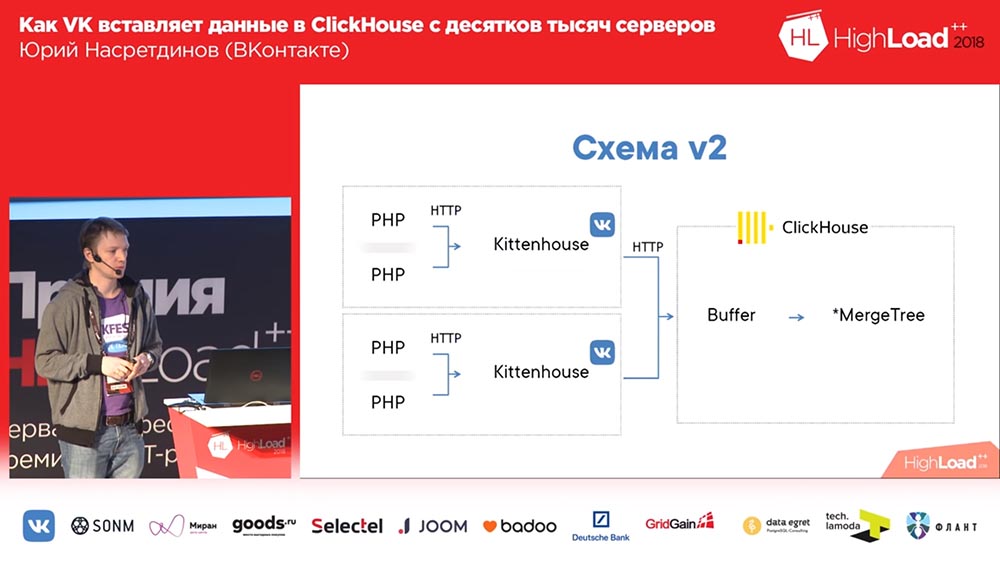
Mas, como você pode imaginar, se você escrever 10 arquivos para cada inserção, o “ClickHouse” terminará rapidamente (ou seu servidor); portanto, é recomendável inserir em pacotes grandes. Consequentemente, nunca lançamos o primeiro esquema em produção. Lançamos imediatamente um número 2 aqui:

Imagine aqui que existem cerca de mil servidores nos quais lançamos, há apenas PHP. E em cada servidor existe o nosso agente local, que chamamos de “Kittenhouse”, que mantém uma conexão com o “ClickHouse” e insere dados a cada poucos segundos. Ele não insere dados no MergeTree, mas na tabela de spooler, que serve para não inserir diretamente no MergeTree imediatamente.
Trabalhar com tabelas de buffer
O que é isso As tabelas de buffer são uma parte da memória embaralhada (ou seja, é possível inseri-las frequentemente). Eles consistem em várias partes, e cada uma delas funciona como um buffer independente e liberadas independentemente (se você tiver muitas partes no buffer, haverá muitas inserções por segundo). Você pode ler nessas tabelas - depois você lê a união do conteúdo do buffer e da tabela pai, mas nesse momento o registro é bloqueado, portanto, é melhor não ler a partir daí. E um QPS muito bom é mostrado pelas tabelas de buffer, ou seja, até 3 mil QPS, você não terá nenhum problema com a inserção. É claro que, se a energia foi perdida no servidor, os dados podem ser perdidos, porque eles foram armazenados apenas na memória.

Ao mesmo tempo, o esquema com o buffer é complicado por ALTER, porque você primeiro precisa descartar a tabela de buffer antiga com o esquema antigo (os dados não serão perdidos ao mesmo tempo, porque serão liberados antes da exclusão da tabela). Em seguida, você "altera" a tabela necessária e cria a tabela de buffer novamente. Assim, enquanto não há tabela de buffer, seus dados não fluem em lugar algum, mas você pode até localmente no disco.

O que é o Kittenhouse e como ele funciona?
O que é o KittenHouse? Este é um proxy. Adivinha qual idioma? Eu coletei os tópicos com mais hype no meu relatório - este é "Clickhouse", Vá, talvez eu me lembre de outra coisa. Sim, está escrito em Go, porque eu realmente não sei escrever em C, não quero.

Por conseguinte, mantém uma conexão com cada servidor, pode gravar na memória. Por exemplo, se escrevermos logs de erro em “Clickhouse”, se “Clickhouse” não tiver tempo para inserir dados (afinal, se muitos forem gravados), não incharemos de memória - simplesmente jogamos fora o resto. Porque, se escrevermos vários gigabits por segundo de erros, provavelmente poderemos lançar alguns. Kittenhouse sabe como. Além disso, ele sabe como entregar de maneira confiável, ou seja, grava em um disco na máquina local e de vez em quando (lá, uma vez em alguns segundos) tenta entregar dados desse arquivo. E, a princípio, usamos o formato normal de valores - não algum formato binário, formato de texto (como no SQL regular).

Mas então isso aconteceu. Usamos entrega confiável, escrevemos logs e decidimos (era um cluster de teste condicional) ... Por várias horas, eles a lançaram e levantaram de volta, e houve uma inserção de milhares de servidores - descobriu-se que o Clickhouse ainda tinha um “Thread on conexão ”- consequentemente, em mil conexões, a inserção ativa leva a uma carga média no servidor de cerca de mil e meia. Surpreendentemente, o servidor aceitou solicitações, mas esses dados foram inseridos após algum tempo; mas foi muito difícil para o servidor atendê-lo ...
Adicionar nginx
Essa solução para o modelo Thread por conexão é nginx. Colocamos o nginx na frente da Clickhouse, ao mesmo tempo, definimos o balanceamento para duas réplicas (aumentamos a velocidade de inserção em 2 vezes, embora não seja o fato de que deveria ser assim) e limitamos o número de conexões à Clickhouse, à montante e, consequentemente, mais do que em 50 compostos, parece não fazer sentido inserir.

Então percebemos que, em geral, esse esquema tem desvantagens, porque temos um nginx aqui. Portanto, se esse nginx estabelecer, apesar da presença de réplicas, perdemos dados ou, pelo menos, não escrevemos em lugar algum. Portanto, fizemos nosso balanceamento de carga. Também entendemos que o “Clickhouse” ainda é adequado para logs, e o “demônio” também começou a escrever seus próprios logs no “Clickhouse” também - muito conveniente, para ser honesto. Ainda o usamos para outros "demônios".

Eles descobriram um problema tão interessante: se você usar uma maneira não muito padrão de inserir no modo SQL, um analisador completo baseado em SQL AST será forçado, o que é bastante lento. Assim, adicionamos configurações para que isso nunca aconteça. Fizemos balanceamento de carga, verificações de integridade, para que, se alguém morrer, ainda deixemos os dados. Temos tabelas suficientes para que possamos ter diferentes clusters de "Clickhouse". E começamos a pensar em outros usos - por exemplo, queríamos gravar logs dos módulos nginx e eles não podem se comunicar usando nosso RPC. Bem, eu gostaria de ensiná-los de alguma forma a enviar - por exemplo, via UDP para receber eventos no host local e enviá-los para o “Clickhouse”.
Um passo da decisão
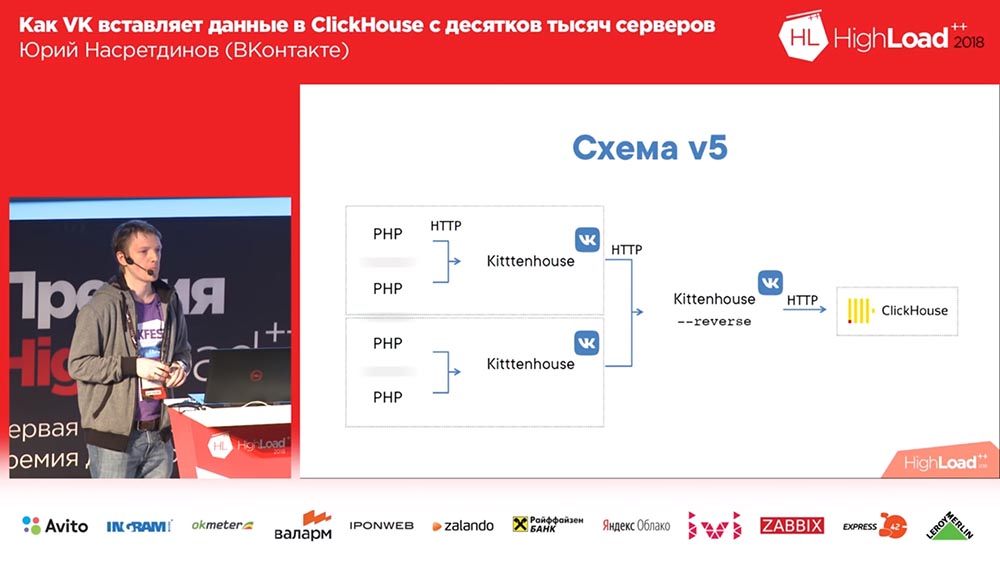
O esquema final começou a ter esta aparência (a quarta versão deste esquema): em cada servidor na frente da Clickhouse, há nginx (no mesmo servidor, além disso) e simplesmente proxies solicitações ao host local com um limite no número de conexões de 50 peças. E agora esse esquema já estava funcionando, era muito bom com ele.

Vivemos assim por cerca de um mês. Todo mundo estava feliz, adicionando tabelas, adicionando, adicionando ... Em geral, descobriu-se que a maneira como adicionamos tabelas de buffer não era muito ótima (digamos assim). Fizemos 16 peças em cada mesa e um intervalo de flash por alguns segundos; tínhamos 20 tabelas e 8 inserções por segundo foram para cada tabela - e nesse momento o “Clickhouse” começou ... os registros começaram a ficar em branco. Eles nem foram aprovados ... O Nginx tinha uma coisa tão interessante por padrão que, se as conexões terminassem no upstream, isso forneceria "502" para todas as novas solicitações.

E aqui em nós (eu apenas olhei para os logs na própria "Clickhouse" que eu olhei) em algum lugar em torno de meio por cento das solicitações falha. Consequentemente, a utilização do disco foi alta, houve muitas mesclagens. Bem, o que eu fiz? Naturalmente, não comecei a entender por que a conexão e a montante estão terminando.
Substituindo nginx por proxy reverso
Decidi que precisamos gerenciar isso sozinhos, não o damos ao nginx - o nginx não sabe quais são as tabelas no "Clickhouse" e substituí o nginx por um proxy reverso, que também escrevi.
O que ele esta fazendo? Ele funciona com base na biblioteca fasthttp "goosh", ou seja, rápido, quase tão rápido quanto o nginx. Desculpe, Igor, se você está aqui (nota: Igor Sysoev é um programador russo que criou o servidor da web nginx). Ele pode entender que tipo de consultas são - INSERT ou SELECT - respectivamente, ele mantém diferentes pools de conexões para diferentes tipos de consultas.

Assim, mesmo se não tivermos tempo para concluir as solicitações, os "selecionadores" serão aprovados e vice-versa. E agrupa os dados em tabelas de buffer - com um buffer pequeno: se houver erros, erros de sintaxe etc. - para que eles influenciem levemente o restante dos dados, porque quando inserimos simplesmente nas tabelas de buffer, tivemos pequenos " bachi ”e todos os erros de sintaxe afetaram apenas este pequeno pedaço; e aqui eles já afetarão o buffer grande. Pequeno é 1 megabyte, ou seja, não é tão pequeno.

Inserir um síncrono e essencialmente substituir o nginx faz essencialmente o mesmo que o nginx antes - o Kittenhouse não precisa ser alterado localmente para isso. E como usa fasthttp, é muito rápido - você pode fazer mais de 100 mil solicitações por segundo de inserções únicas por meio de proxies reversos. Teoricamente, você pode inserir uma linha em um proxy reverso kittenhouse, mas certamente não o fazemos.

O esquema começou a ter a seguinte aparência: o Kittenhouse, um proxy reverso agrupa muitas solicitações em tabelas e, por sua vez, as tabelas de buffer as inserem nas principais.
Killer - solução temporária, Kitten - permanente
Houve um problema tão interessante ... Algum de vocês já usou o fasthttp? Quem usou fasthttp com solicitações POST? Provavelmente, não valia a pena fazer isso de fato, porque ele armazena em buffer o corpo da solicitação por padrão e definimos o tamanho do buffer de 16 megabytes. A inserção deixou de chegar a tempo em algum momento e, de todas as dezenas de milhares de servidores, começaram a aparecer blocos de 16 megabytes, e todos estavam armazenados em buffer na memória antes de serem entregues ao Clickhouse. Assim, a memória acabou, o Killer Out-Of-Memory Killer veio, matou o proxy reverso (ou "Clickhouse", que teoricamente poderia "comer" mais do que o proxy reverso). O ciclo foi repetido. Não é um problema muito agradável. Embora tenhamos descoberto isso apenas após alguns meses de operação.
O que eu fiz? Novamente, eu realmente não gosto de entender o que exatamente aconteceu. Parece-me bastante óbvio que não há necessidade de armazenar em buffer a memória. Não consegui corrigir o fasthttp, embora tenha tentado. Mas eu encontrei uma maneira de fazê-lo para que não houvesse necessidade de consertar nada, e criei meu próprio método no HTTP - chamado KITTEN. Bem, é lógico - "VK", "Kitten" ... Como mais?

Se uma solicitação chegar ao servidor com o método Kitten, o servidor deverá responder "miar" - logicamente. Se ele responder, acredita-se que ele entenda esse protocolo, e então eu intercepto a conexão (existe um método desse tipo no fasthttp), e a conexão entra no modo "bruto". Por que eu preciso disso? Quero controlar como ocorre a leitura das conexões TCP. O TCP possui uma propriedade maravilhosa: se ninguém lê desse lado, o registro começa a esperar e a memória não é especialmente gasta nisso.
E então eu li em algum lugar entre 50 clientes por vez (de cinquenta porque cinquenta certamente deve ser suficiente, mesmo se vier de outro controlador de domínio) ... O consumo diminuiu com essa abordagem pelo menos 20 vezes, mas sinceramente , Não pude medir quanto exatamente, porque já não faz sentido (já se tornou no nível do erro). O protocolo é binário, ou seja, existe um nome de tabela e dados; não há cabeçalhos http, então não usei um soquete da web (não preciso me comunicar com os navegadores - criei um protocolo que atenda às nossas necessidades). E com ele estava tudo bem.
A tabela de buffer está triste
Recentemente, encontramos outro recurso interessante das tabelas de buffer. E esse problema já é muito mais doloroso que o resto. : «», «», , (, 60 ); Alter … «», «», , «» – , - , «» . ? ?

, , , . , , , «» ( – , , ), … , «» ( - «» ) – , - : ( , ), «» , - , . , «», – .

(, ) – «» query_thread_log. , - . 840 (100 ). , (, , , ) «» (inserts). , «» – «» . , – , . Porque , ! .

, ? «». .
«KitttenHouse»
, ? . ! : , , - . , .

, «», – , (, - ) , , – .

? . , , 10 , – -, , . , , , , – , «», 100 - – , , , . , . , .
, , . : , - , , , read only . ? . – - , - … ( , «», ClickHouse) ? ? , . . : , . , . .
. . , - ?.. «»? - … «»? , , . , . , .

– . , . , : , , ( ), – , .

Sequel Pro, «», . : «, -?» ? 2018-? , «» (MySQL) , «», ! «», – , .
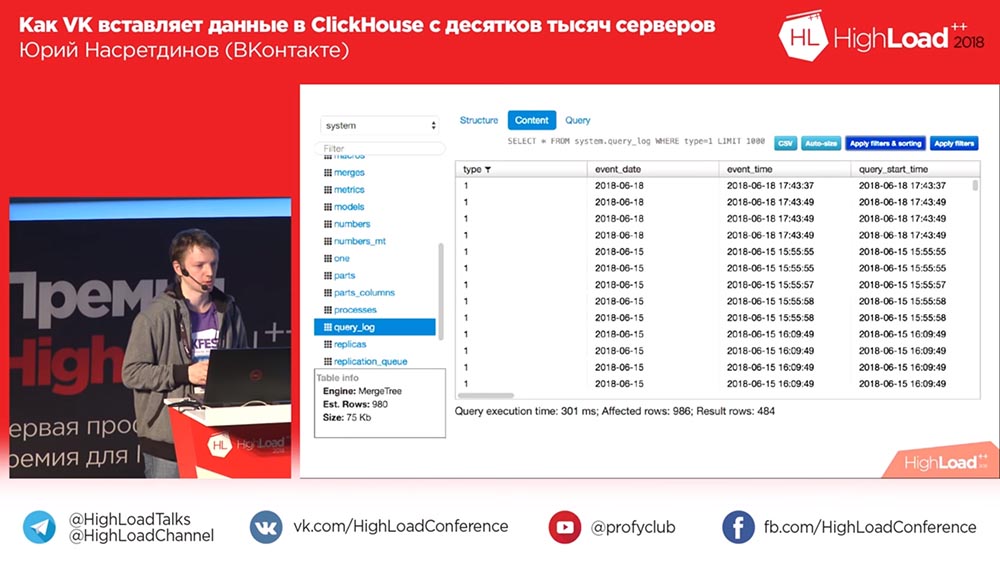
, , , , , , , , affected rows ( ), . .
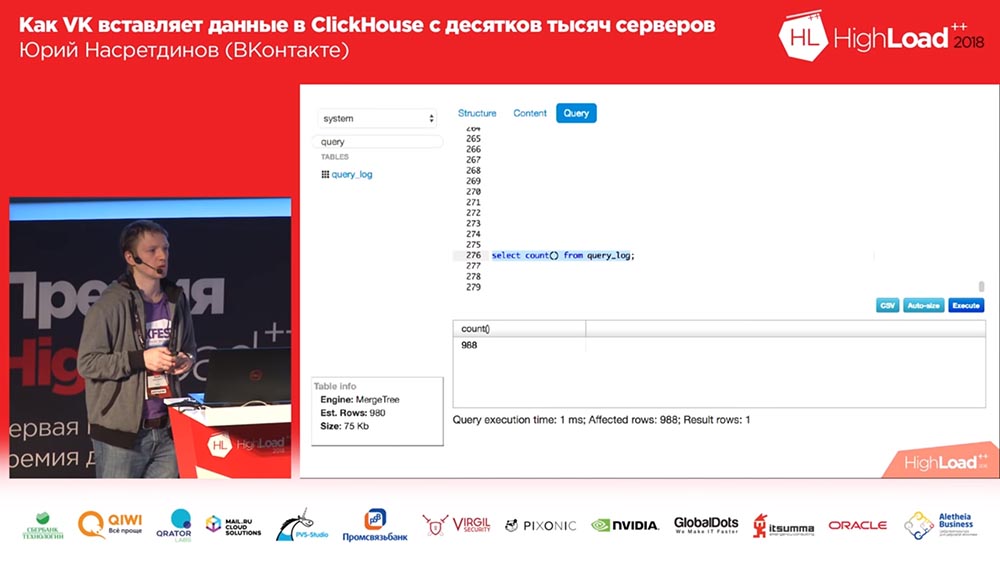
. «», . - - . .
«»
, «», , . , , – . , … , , .

TCP? , «» UDP. TCP… , , : «, ! , UDP». , TCP . , , – - ; , .
«» «» HighLoad Siberia, « »… , … , , . - , - , – , ( , , ).
. Muito obrigado!
Nosso github está aqui . Com "Clickhouse", seu cabelo ficará macio e sedoso. Apresentador: - Amigos, e agora perguntas. Imediatamente após apresentarmos uma carta de agradecimento e seu relatório sobre VHS.Yuri Nasretdinov (a seguir denominada ONU): - E como você poderia registrar meu relatório sobre o VHS, se este acabou?
Apresentador: - Amigos, e agora perguntas. Imediatamente após apresentarmos uma carta de agradecimento e seu relatório sobre VHS.Yuri Nasretdinov (a seguir denominada ONU): - E como você poderia registrar meu relatório sobre o VHS, se este acabou? Anfitrião: “Você também não pode determinar completamente como o“ Clickhouse ”funcionará ou não! Amigos, 5 minutos para perguntas!
Anfitrião: “Você também não pode determinar completamente como o“ Clickhouse ”funcionará ou não! Amigos, 5 minutos para perguntas!Perguntas
Pergunta da platéia (a seguir - H): - Boa tarde. Muito obrigado pelo relatório. Eu tenho duas perguntas Vou começar com um frívolo: o número de letras t no nome “Kittenhouse” nos esquemas (3, 4, 7 ...) afeta a satisfação dos gatos?
ONU: - A quantidade de quê?
Z: - As letras t. Existem três t, em algum lugar três t.
ONU: - Eu realmente corrigi isso? Bem, é claro que sim! Estes são produtos diferentes - eu menti para você esse tempo todo. Ok, estou brincando - não. Ah aqui! Não, é a mesma coisa, estou selado.
 Z:
Z: - obrigado. A segunda pergunta é séria. Tanto quanto eu entendo, em "Clickhouse", as tabelas de buffer vivem exclusivamente na memória, não são armazenadas em buffer no disco e, portanto, não são persistentes.
ONU: - Sim.
Z: - E, ao mesmo tempo, no seu cliente é realizado o buffer no disco, o que implica alguma garantia de entrega desses mesmos logs. Mas na Clickhouse, isso não é garantido. Explique como é realizada a garantia, devido a quê? .. Esse mecanismo é mais detalhado
ONU: - Sim, teoricamente não há contradições, porque você pode detectar um milhão de maneiras diferentes quando o "Clickhouse" cai. Se o “Clickhouse” travar (se não for concluído corretamente), você poderá, grosso modo, rebobinar o seu registro que anotou um pouco e começar a partir do momento em que tudo estava bem. Vamos retroceder um minuto atrás, ou seja, acredita-se que exibiu tudo em um minuto.
Z: - Ou seja, o Kittenhouse mantém a janela mais longa e, em caso de queda, pode reconhecê-la e desenrolá-la?
ONU: - Mas isso é em teoria. Na prática, não fazemos isso, e a entrega confiável é de zero a infinito. Mas em média um. Estamos satisfeitos que, se o "Clickhouse" travar por algum motivo ou os servidores "reiniciarem", perderemos um pouco. Em todos os outros casos, nada acontecerá.
Z: - Olá. Desde o início, pareceu-me que você realmente usaria o UDP desde o início do relatório. Você tem http, tudo isso ... E a maioria dos problemas que você descreveu, pelo que entendi, foram causados por essa solução específica ...
ONU: - O que usamos TCP?
Z: - De fato, sim.
ONU: - Não.
Z: - Foi com o fasthttp que você teve problemas, com a conexão você teve problemas. Se você apenas usasse o UDP, economizaria tempo. Bem, haveria problemas com mensagens longas ou outra coisa ...
ONU: - Com o quê?
 Z:
Z: - Com mensagens longas, uma vez que pode não caber no MTU, outra coisa ... Bem, aí podem surgir seus problemas. A questão é: por que não é UDP?
ONU: - Acredito que os autores que desenvolveram o TCP / IP são muito mais espertos do que eu e sabem como serializar pacotes melhor (assim vão), ao mesmo tempo, ajustam a janela de envio, não sobrecarregam a rede e dão feedback sobre o que lê, sem contar do outro lado ... Todos esses problemas, na minha opinião, também estariam no UDP, apenas eu teria que escrever ainda mais código do que já escrevi para implementar a mesma coisa e provavelmente seria ruim. Eu nem gosto de escrever em C, não gosto daqui ...
Z: - Apenas conveniente! Enviado ok e não espere nada - você tem absolutamente de forma assíncrona. Voltou um aviso de que está tudo bem - isso significa que chegou; não veio - isso significa ruim.
ONU: - Preciso disso e de outro - Preciso poder enviar ambos com garantia de entrega e sem garantia de entrega. Esses são dois cenários diferentes. Alguns logs eu não preciso perder ou não perder dentro do razoável.
Z: - Não vou demorar. Isso deve ser discutido por mais tempo. Obrigada
Apresentador: - Quem tem perguntas - canetas no céu!
 Z:
Z: - Oi, eu sou Sasha. Em algum lugar no meio do relatório, havia a sensação de que era possível, além do TCP, usar uma solução pronta - algum tipo de "Kafka".
ONU: “Bem ... eu disse que não quero usar servidores intermediários, porque ... para Kafka - acontece que temos dez mil hosts; de fato, temos mais - dezenas de milhares de hosts. Com Kafka, sem proxies, também pode doer. Além disso, o mais importante é que ainda fornece "latência", fornece os hosts extras que você precisa ter. E eu não quero tê-los - eu quero ...
Z: - Mas no final acabou assim mesmo.
ONU: - Não, não há anfitriões! Tudo funciona nos hosts Clickhouse.
Z: - Mas e o Kittenhouse, cujo reverso é - onde ele mora?
 ONU:
ONU: - No host de Klickhouse, ele não escreve nada no disco.
Z: - Bem, digamos.
Apresentador: - Satisfaz você? Podemos dar um salário?
Z: - Sim sim. De fato, existem muitas muletas para obter a mesma coisa e agora - a resposta anterior sobre o tópico do TCP contradiz, na minha opinião, essa situação. Parece que você pode fazer tudo em seu joelho em muito menos tempo.
ONU: - E por que eu não quis usar o "Kafka", porque houve muitas reclamações no telegrama "Clickhouse" no Telegram de que, por exemplo, as mensagens de "Kafka" foram perdidas. Não da própria Kafka, mas na integração da Kafka e Klikhaus; ou algo não se conectou lá. Grosso modo, seria necessário que o cliente Kafka escrevesse então. Eu não acho que uma solução mais simples e confiável seria obtida.
Z: - Diga-me, por que você não experimentou algumas linhas ou um ônibus tão comum? Como você diz que foi possível com você assincronamente dirigir pela fila os próprios logs e também obter assincronamente pela fila em resposta?
 ONU:
ONU: - Por favor, sugira quais filas podem ser usadas?
Z: - Qualquer, mesmo sem garantia de que eles estão indo em ordem. Qualquer Redis, RMQ ...
ONU: - Sinto que o Redis provavelmente não conseguirá extrair esse volume de inserção nem em um host (no sentido de vários servidores) que retire o Clickhouse. Não posso confirmar isso com nenhuma evidência (não a fiz como referência), mas me parece que o Redis não é a melhor solução aqui. Em princípio, você pode considerar esse sistema como uma fila de mensagens improvisadas, mas que é apenas para "Clickhouse"
Apresentador: - Yuri, muito obrigado. Proponho terminar as perguntas e respostas sobre isso e dizer qual das pessoas que fizeram a pergunta nos dará um livro.
ONU: - Gostaria de dar um livro para a primeira pessoa que fez uma pergunta.
Apresentador: - Ótimo! Ótimo! Ótimo! Muito obrigado!
Um pouco de publicidade :)
Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando aos seus amigos o
VPS baseado em nuvem para desenvolvedores a partir de US $ 4,99 , um
analógico exclusivo de servidores básicos que foi inventado por nós para você: Toda a verdade sobre o VPS (KVM) E5-2697 v3 (6 núcleos) 10 GB DDR4 480 GB SSD 1 Gbps de US $ 19 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
Dell R730xd 2 vezes mais barato no data center Equinix Tier IV em Amsterdã? Somente temos
2 TVs Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV a partir de US $ 199 na Holanda! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - a partir de US $ 99! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?