capítulos anteriores
30. Interpretação da curva de aprendizado: grande viés
Suponha que sua curva de erro em uma amostra de validação tenha a seguinte aparência:
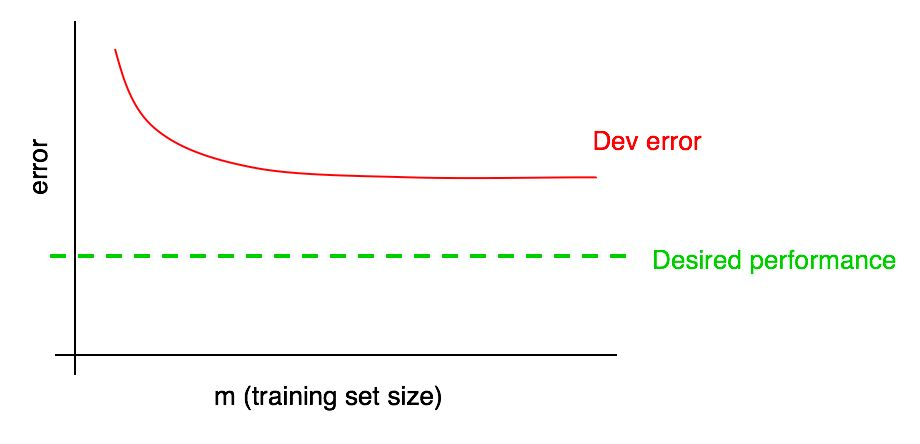
Já dissemos que, se um erro de algoritmo na amostra de validação atingir um platô, é improvável que você atinja o nível de qualidade desejado simplesmente adicionando dados.
Mas é difícil imaginar como será a extrapolação da curva da dependência da qualidade do algoritmo na amostra de validação (erro de desenvolvimento) ao adicionar dados. E se a amostra de validação for pequena, responder a essa pergunta é ainda mais difícil devido ao fato de a curva ser barulhenta (com uma grande variedade de pontos).
Suponha que adicionamos ao nosso gráfico uma curva da dependência da magnitude do erro na quantidade de dados da amostra de teste e obtivemos a seguinte imagem:
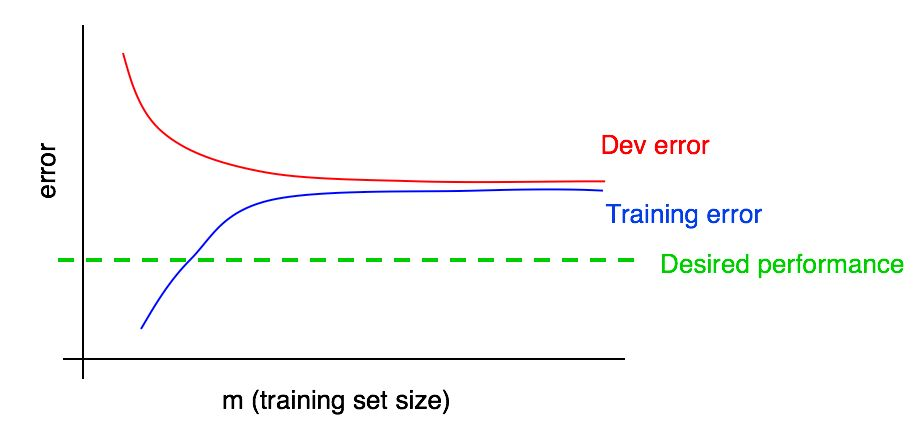
Observando essas duas curvas, você pode ter certeza absoluta de que a adição de novos dados por si só não produzirá o efeito desejado (não permitirá aumentar a qualidade do algoritmo). Onde essa conclusão pode ser tirada?
Vamos lembrar os dois pontos a seguir:
- Se adicionarmos mais dados ao conjunto de treinamento, o erro do algoritmo no conjunto de treinamento poderá aumentar apenas. Assim, a linha azul do nosso gráfico não muda ou aumenta rapidamente e se afasta do nível de qualidade desejado do nosso algoritmo (linha verde).
- A linha de erro vermelha na amostra de validação geralmente é maior que a linha de erro azul do algoritmo na amostra de treinamento. Assim, sob quaisquer circunstâncias concebíveis, a adição de dados não levará a uma diminuição adicional na linha vermelha, nem a aproximará do nível de erro desejado. Isso é quase impossível, pois mesmo o erro na amostra de treinamento é maior que o desejado.
A consideração de ambas as curvas da dependência do erro do algoritmo na quantidade de dados nas amostras de validação e treinamento no mesmo gráfico permite extrapolar com mais confiança a curva de erro do algoritmo de aprendizado da quantidade de dados na amostra de validação.
Suponha que tenhamos uma estimativa da qualidade desejada do algoritmo na forma de um nível ótimo de erros em nosso sistema. Nesse caso, os gráficos acima são uma ilustração de um caso "manual" padrão de como a curva de aprendizado se parece com um alto nível de viés removível. No maior tamanho de amostra de treinamento, presumivelmente correspondendo a todos os dados que temos à nossa disposição, existe uma grande lacuna entre o erro do algoritmo na amostra de treinamento e a qualidade desejada do algoritmo, o que indica um alto nível de viés evitado. Além disso, a diferença entre o erro na amostra de treinamento e o erro na amostra de validação é pequena, o que indica uma pequena dispersão.
Anteriormente, discutimos os erros de algoritmos treinados em amostras de treinamento e validação apenas no ponto mais à direita acima do gráfico que corresponde ao uso de todos os dados de treinamento disponíveis. A curva das dependências do erro na quantidade de dados da amostra de treinamento, construída para diferentes tamanhos da amostra usada para treinamento, fornece uma imagem mais completa da qualidade do algoritmo treinado em diferentes tamanhos da amostra de treinamento.
31. Interpretação da curva de aprendizado: outros casos
Considere a curva de aprendizado:
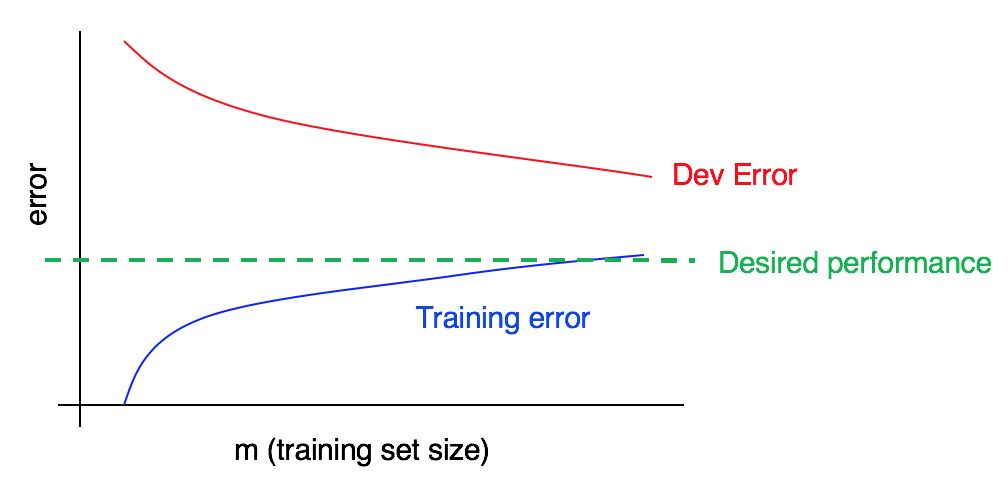
Existe um viés alto, uma análise alta ou os dois ao mesmo tempo?
A curva de erro azul nos dados de treinamento é relativamente baixa, a curva de erro vermelha nos dados de validação é significativamente maior que o erro azul nos dados de treinamento. Portanto, neste caso, o viés é pequeno, mas a propagação é grande. Adicionar mais dados de treinamento pode ajudar a fechar a lacuna entre o erro na amostra de validação e o erro na amostra de treinamento.
Agora considere este gráfico:
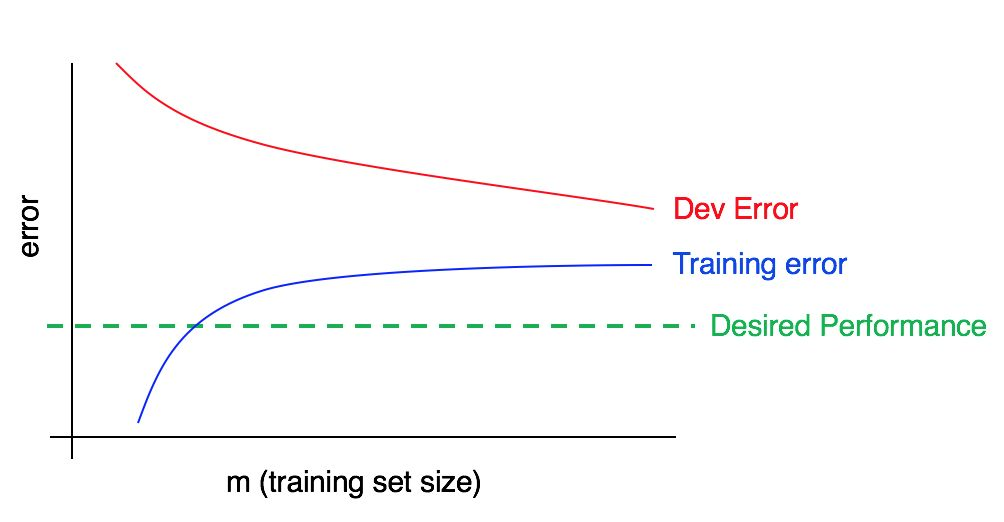
Nesse caso, o erro na amostra de treinamento é grande, é significativamente maior que o algoritmo correspondente ao nível de qualidade desejado. O erro na amostra de validação também é significativamente maior que o erro na amostra de treinamento. Assim, estamos lidando com viés e dispersão simultaneamente grandes. Você deve procurar maneiras de reduzir, compensar e dispersar seu algoritmo.
32. Construindo curvas de aprendizado
Suponha que você tenha uma amostra de treinamento muito pequena, consistindo em apenas 100 exemplos. Você treina seu algoritmo usando um subconjunto selecionado aleatoriamente de 10 exemplos, depois de 20 exemplos, depois de 30 e assim por diante para 100, aumentando o número de exemplos com um intervalo de dez exemplos. Então, usando esses 10 pontos, você constrói sua curva de aprendizado. Você pode achar que a curva parece barulhenta (valores maiores ou menores que o esperado) para amostras de treinamento menores.
Quando você treina o algoritmo com apenas 10 exemplos selecionados aleatoriamente, pode não ter sorte e isso se tornará uma subamostra de treinamento particularmente "ruim", com uma parcela maior de exemplos ambíguos / marcados incorretamente. Ou, inversamente, você pode encontrar uma subamostra de treinamento particularmente “boa”. A presença de uma pequena amostra de treinamento implica que o valor dos erros nas amostras de validação e treinamento pode estar sujeito a flutuações aleatórias.
Se os dados usados para o seu aplicativo usando o aprendizado de máquina forem fortemente direcionados a uma classe (como no problema de classificação de gatos, em que a proporção de exemplos negativos é muito maior que a proporção de positivo), ou se estamos lidando com um grande número de classes (como reconhecimento de 100 espécies diferentes de animais), então a chance de obter uma amostra de treinamento particularmente “não representativa” ou ruim também aumenta. Por exemplo, se 80% dos seus exemplos são negativos (y = 0) e apenas 20% são positivos (y = 1), há uma boa chance de que um subconjunto de treinamento de 10 exemplos contenha apenas exemplos negativos, neste caso muito é difícil obter algo razoável do algoritmo treinado.
Se, devido ao ruído da curva de aprendizado na amostra de treinamento, for difícil fazer uma avaliação das tendências, é possível propor as duas soluções a seguir:
Em vez de treinar apenas um modelo para 10 exemplos de treinamento, selecione com substituição várias (por exemplo, 3 a 10) subamostras de treinamento aleatório diferentes da amostra inicial, composta por 100 exemplos. Treine o modelo em cada um deles e calcule para cada um desses modelos o erro na amostra de validação e treinamento. Conte e plote o erro médio nas amostras de treinamento e validação.
Observação do autor: uma amostra com uma substituição significa o seguinte: selecione aleatoriamente os 10 primeiros exemplos diferentes de 100 para formar a primeira subamostra de treinamento. Então, para formar a segunda subamostra de treinamento, mais uma vez tomamos 10 exemplos, mas sem levar em conta aqueles selecionados na primeira subamostra (novamente entre as centenas de exemplos completos). Assim, um exemplo específico pode aparecer nas duas subamostras. Isso distingue uma amostra com uma substituição de uma amostra sem substituição; no caso de uma amostra sem substituição, a segunda subamostra de treinamento seria selecionada de apenas 90 exemplos que não se enquadravam na primeira subamostra. Na prática, o método de seleção de exemplos com ou sem substituição não deve ser de grande importância, mas a seleção de exemplos com substituição é prática comum.
Se sua amostra de treinamento for direcionada para uma das classes, ou se incluir muitas, selecione uma subamostra "equilibrada" que consiste em 10 exemplos de treinamento, selecionados aleatoriamente de 100 amostras. Por exemplo, você pode ter certeza de que 2/10 exemplos são positivos e 8/10 negativos. Para resumir, você pode ter certeza de que a proporção de exemplos de cada classe no conjunto de dados observado é o mais próxima possível de sua participação na amostra de treinamento inicial.
Eu não me incomodaria com nenhum desses métodos até que o gráfico das curvas de erro leve à conclusão de que essas curvas são excessivamente barulhentas, o que não nos permite ver tendências compreensíveis. Se você tem uma grande amostra de treinamento - digamos cerca de 10.000 exemplos e a distribuição de suas aulas não é muito tendenciosa, talvez você não precise desses métodos.
Finalmente, a construção de uma curva de aprendizado pode ser cara do ponto de vista computacional: por exemplo, você precisa treinar dez modelos, nos primeiros 1000 exemplos, no segundo 2000 e assim por diante até o último contendo 10.000 exemplos. O treinamento do modelo em pequenas quantidades de dados é muito mais rápido que o treinamento do modelo em amostras grandes. Portanto, em vez de distribuir uniformemente os tamanhos das subamostras de treinamento em uma escala linear, conforme descrito acima (1000, 2000, 3000, ..., 10000), você pode treinar modelos com um aumento não linear no número de exemplos, por exemplo, 1000, 2000, 4000, 6000 e 10.000 exemplos. Mesmo assim, deve fornecer uma compreensão clara da tendência da dependência da qualidade do modelo no número de exemplos de treinamento nas curvas de aprendizado. Obviamente, essa técnica é relevante apenas se o custo computacional do treinamento de modelos adicionais for alto.
continuação