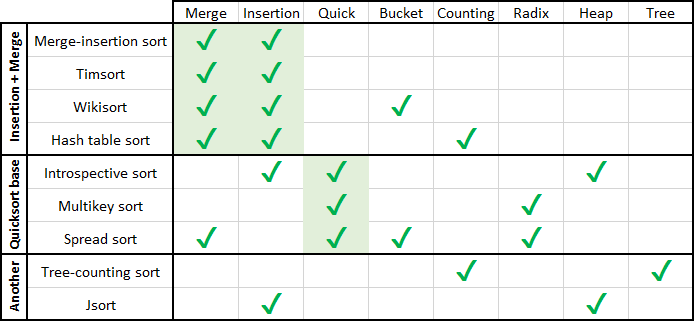
Como todos já sabem, a classificação pode ser baseada em trocas, inserções, seleção, mesclagem e distribuição.
Mas se métodos diferentes são combinados no algoritmo, ele pertence à classe dos tipos híbridos.

Este artigo foi escrito com o apoio da EDISON.
Estamos envolvidos na conclusão e manutenção de sites no 1C-Bitrix , bem como no desenvolvimento de aplicativos móveis Android e iOS .
Adoramos a teoria dos algoritmos! ;-)
Vamos relembrar rapidamente quais classes os algoritmos de classificação possuem e quais são os recursos de cada um deles.
Classificações de Câmbio
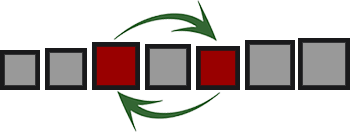
Os elementos da matriz são comparados em pares entre si e as trocas são feitas por pares desordenados.
O representante mais eficaz dessa classe é a
classificação rápida lendária.
Classificações de inserção
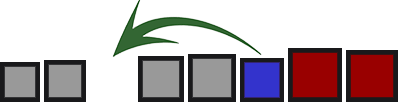
Os elementos da parte não classificada da matriz são inseridos em seus locais na área classificada.
Nesta classe, a
classificação por inserções simples é mais frequentemente usada. Embora esse algoritmo tenha uma complexidade média de O (
n 2 ), essa classificação funciona muito rapidamente com matrizes quase ordenadas - nelas, a complexidade atinge O (
n ). Além disso, essa classificação é uma das melhores opções para o processamento de pequenas matrizes.
A classificação usando a árvore de pesquisa binária também pertence a esta classe.
Classificar por seleção

Na área não ordenada, o elemento mínimo / máximo é selecionado, o qual é transferido para o final / início da parte não classificada da matriz.
A classificação com uma opção simples funciona muito lentamente (em média O (
n 2 )), mas nesta classe há uma
classificação difícil
por um monte (também conhecido como
classificação piramidal ), que possui uma complexidade de tempo de O (
n log
n ) - e, o que é muito valioso, Não há casos degenerados dessa classificação, quaisquer que sejam os dados recebidos. A propósito, essa classificação também não tem os melhores casos para os dados recebidos.
Mesclar classificações
As áreas classificadas são obtidas na matriz e são mescladas, ou seja, as sub-matrizes menores são combinadas em uma sub-matriz maior.
Se duas sub-matrizes forem classificadas, combiná-las é uma operação fácil de implementar e de tempo rápido. O outro lado da moeda é que a fusão quase sempre requer o custo da memória adicional O (
n ) - embora existam muito poucas opções muito sofisticadas para classificar com a fusão, onde o custo da memória é O (1).
Classificar por distribuição
Os elementos da matriz são distribuídos e redistribuídos em classes até que a matriz aceite um estado classificado.
Os elementos são espalhados em grupos, dependendo do seu valor (as chamadas classificações de
contagem ) ou do valor de dígitos individuais (essas já são classificações
bit a bit ).
A classificação de baldes também pertence a esta classe.
Uma característica da classificação por distribuição é que eles não usam comparações aos pares de elementos entre si, ou essas comparações estão presentes em pequena extensão. Portanto, a classificação por distribuição geralmente está à frente da velocidade, por exemplo, a classificação rápida. Por outro lado, a classificação por distribuição geralmente requer muita memória adicional, pois grupos de elementos constantemente redistribuídos precisam ser armazenados em algum lugar.
As disputas sobre qual é
a melhor classificação são muito frequentes, mas o fato é que não existe e não pode ser um algoritmo ideal para todas as ocasiões. Por exemplo, a classificação rápida é realmente muito rápida (mas não a mais rápida) na maioria das situações, mas também se depara com casos degenerados nos quais ocorre uma falha. A classificação por inserções simples é lenta, mas para matrizes quase ordenadas, ela ignora facilmente outros algoritmos. A classificação de heap funciona muito rapidamente com todos os dados recebidos, mas não tão rápido quanto outras classificações sob certas condições e não há como acelerar a pirâmide. A classificação de mesclagem é mais lenta que a classificação rápida; no entanto, se houver sub-matrizes classificadas na matriz, é mais rápido mesclá-las do que classificar por classificação rápida. Se a matriz tiver muitos elementos repetidos ou classificarmos as linhas, provavelmente a classificação por distribuição é a melhor opção. Cada método é especialmente bom em sua situação mais favorável.
No entanto, os programadores continuam inventando as classificações mais rápidas do mundo, sintetizando os métodos mais eficazes de diferentes classes. Vamos ver o quão bem sucedido é para eles.
Como muitos algoritmos não triviais são mencionados no artigo, apenas abordo brevemente os princípios básicos de seu trabalho, sem sobrecarregar o artigo com animações e explicações detalhadas. No futuro, haverá artigos separados, onde haverá cartuns para cada algoritmo e nuances sutis detalhadas.
Inserir + Mesclar
Uma conclusão puramente empírica é que a fusão e / ou inserção são mais frequentemente usadas em híbridos. Na maioria das classificações, um ou outro método é encontrado ou ambos juntos. E há uma explicação lógica para isso.
Os inventores de classificação geralmente se esforçam para criar algoritmos paralelos que ordenam simultaneamente diferentes partes de uma matriz. A melhor maneira de lidar com várias sub-matrizes ordenadas é mesclá-las - essa será a mais rápida.
Algoritmos modernos costumam usar recursão. Durante uma descida recursiva, a matriz geralmente é dividida em duas partes; no nível mais baixo, a matriz é ordenada. Ao retornar para níveis mais altos de recursão, surge a questão de combinar sub-matrizes classificadas em níveis mais baixos.
Quanto às inserções, em algoritmos híbridos, em certos estágios, geralmente são obtidos subarrays aproximadamente ordenados, que são melhor conduzidos à ordem final com a ajuda das inserções.
Este grupo contém classificações híbridas, nas quais há mesclagem e inserção, e esses métodos são usados de maneira muito diferente.
Classificação de inserção de mesclagem
Algoritmo Ford Johnson :: Algoritmo Ford-Johnson
Mesclar + Inserir

Uma maneira muito antiga, já em 1959. É descrito em detalhes no trabalho imortal de Donald Knuth, “A Arte da Programação”, Volume 3, “Classificação e Pesquisa”, Capítulo 5, “Classificação”, Seção 5.3, “Classificação Ótima”, subseção, “Classificação com um número mínimo de comparações” e parte “Classificação por Inserções e Mesclagem”. .
A classificação agora não tem valor prático, mas é interessante para aqueles que amam a teoria dos algoritmos. O problema de encontrar uma maneira de classificar
n elementos com o menor número de comparações é considerado. Uma modificação heurística não trivial da classificação de inserção (uma inserção que você não encontrará em nenhum outro lugar) usando
números Jacobstal é proposta para minimizar o número de comparações. Até o momento, também é sabido que essa não é a melhor opção e você pode se esquivar ainda mais habilmente e obter menos comparações. Em geral, a classificação acadêmica padrão não é de uso prático, mas para os conhecedores do gênero é um prazer desmontar esses truques com um viés algébrico.
Tim Sort :: Timsort
Inserir + Mesclar
 Postado por Tim Peters há 15 anos e agora
Postado por Tim Peters há 15 anos e agoraEssa classificação em Habré é lembrada com muita frequência.
Tese: em uma matriz, são procuradas pequenas sub-matrizes quase ordenadas, cuja classificação de inserção é usada. Essas sub-matrizes são mescladas usando a mesclagem.
A mesclagem no TimSort é a parte mais interessante: a mesclagem ascendente clássica é ainda mais otimizada para diferentes situações. Por exemplo, sabe-se que a mesclagem é mais eficiente se as sub-matrizes unidas tiverem aproximadamente o mesmo tamanho. No TimSort, se os tamanhos forem muito diferentes, após ações adicionais, haverá um ajuste (podemos dizer que a partir da sub-matriz maior, alguns dos elementos “fluirão” para uma menor, após o que a fusão continuará no modo padrão). Várias situações insidiosas também são fornecidas - por exemplo, se em um subarray todos os elementos forem menores que em outro. Nesse caso, a comparação dos elementos das duas sub-matrizes ficará inativa. O procedimento de fusão modificado "notará" um desenvolvimento indesejável de eventos no tempo e, se estiver "convencido" de uma opção pessimista usando pesquisa binária, passará para uma opção de processamento mais ideal.
Em média, essa classificação funciona um pouco mais lentamente que o QuickSort, no entanto, se a matriz recebida contiver um número suficiente de subsequências ordenadas de elementos, a velocidade aumentará significativamente e aqui o TimSort vai adiante do resto.
Classificação de mesclagem de bloco :: Classificação de mesclagem de bloco
Wiki-sort :: Wiki-sort
Classificação do Santo Graal :: Grailsort
Inserções + Mesclagem + Caçambas
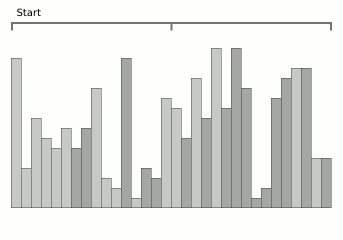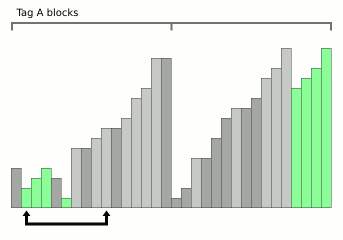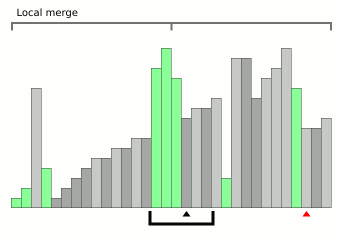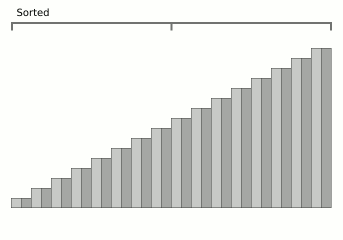 Bloqueie a animação de classificação por mesclagem da Wikipedia.
Bloqueie a animação de classificação por mesclagem da Wikipedia.Este é um algoritmo muito recente (2008) e ao mesmo tempo muito promissor. O fato é que o problema relativamente significativo da mesclagem é o custo da memória adicional. Normalmente, onde há mesclagem, também há O (
n ) complexidade de memória.
Mas o WikiSort foi projetado para que a mesclagem ocorra sem o uso de memória adicional - entre as classificações de mesclagem, a esse respeito, esse é um exemplo muito raro. Além disso, o algoritmo é estável. Bem, se a classificação de mesclagem convencional tem a melhor velocidade algorítmica O (
n log
n ), na classificação wiki esse indicador é O (
n ). Até recentemente, acreditava-se que a combinação da classificação com esse conjunto de características era impossível em princípio, mas os programadores chineses surpreenderam a todos.
O algoritmo é muito complicado de explicar em algumas frases. Mas um dia vou escrever uma matéria em separado sobre ele.
Inicialmente, o algoritmo foi denominado Block Merge Sort, no entanto, com a mão leve de Tim Peters, que estudou a classificação em detalhes (para determinar se algumas de suas idéias deveriam ser transferidas para o TimSort), o nome WikiSort preso a ele.
O haruiser prematuro Mrrl trabalhou independentemente por vários anos na classificação por mesclagem, o que seria simultaneamente rápido com qualquer dado recebido, econômico em memória e estável.
Suas pesquisas criativas foram bem -
sucedidas e mais tarde ele chamou o algoritmo desenvolvido de uma classificação do Santo Graal (uma vez que satisfaz todos os altos requisitos de "classificação perfeita"). A maioria das idéias desse algoritmo é semelhante às implementadas no WikiSort, embora esses tipos não sejam idênticos e sejam desenvolvidos independentemente um do outro.
Classificação da tabela de hash :: Classificação da tabela de hash
Distribuição + Inserir + Mesclar
A matriz é recursivamente dividida ao meio, até que o número de elementos nas sub-matrizes resultantes atinja um determinado valor limite. No nível mais baixo de recursão, ocorre uma distribuição aproximada (usando uma tabela de hash) e a sub-matriz é classificada por inserções. Depois, há um retorno recursivo para níveis mais altos, as metades ordenadas são combinadas por mesclagem.
Falei um pouco mais sobre esse algoritmo
há um
mês .
Classificação rápida como principal
Depois de mesclar e inserir, o terceiro lugar na parada de sucessos híbridos é firmemente mantido pela classificação rápida favorita de todos.
Este é um algoritmo muito eficiente, mas também existem casos degenerados. Alguns inventores estão tentando tornar o QuickSort completamente invulnerável a dados de entrada ruins e sugerem complementá-lo com idéias fortes de outros tipos.
Classificação introspectiva :: Introsort, classificação introspectiva, std :: sort
Inserções rápidas + heap +
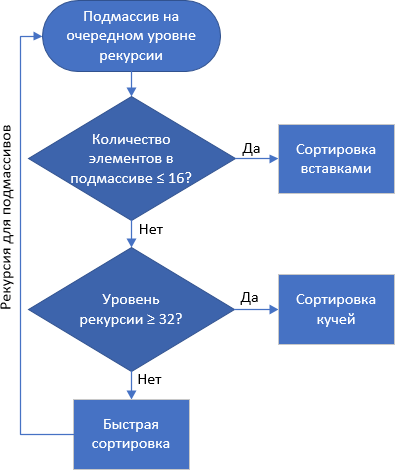
A classificação de heap funciona um pouco mais lenta que a classificação rápida, mas, ao mesmo tempo, diferente do QuickSort, ele não possui casos degenerados - a média, a melhor e a pior complexidade de tempo algorítmica é O (
n log
n ).
Portanto, David Musser propôs ser seguro durante a classificação rápida - se houver muito aninhamento, isso é considerado um ataque ao sistema, que caiu em uma matriz "ruim". A mudança para a classificação por um heap ocorre, que não é megabyte, mas também não é lenta para lidar
com os dados recebidos.
O C ++ possui um algoritmo chamado std :: sort, que é uma implementação da classificação introspectiva. Uma pequena adição - se, no próximo nível de recursão, o
número de elementos da sub-matriz for ≤ 16 , a classificação por inserção será aplicada à sub-matriz.
Classificação Multikey :: Classificação Multikey
Classificação Rápida Bitwise :: Classificação Rápida Radix
Fast + fileiras
Classificação rápida, apenas os valores dos elementos da matriz são comparados entre si, mas seus dígitos individuais (primeiro, organizamos os dígitos mais altos dessa maneira, passamos dos mais novos para eles).
Ou então - esta é a classificação bit a bit por ordem superior, a ordem dentro do próximo bit é realizada de acordo com o algoritmo de classificação rápida.
Classificação por Dispersão :: Spreadsort
Rápido + mesclagem + baldes + descargas
Gestalt de quicksort, classificação de mesclagem, classificação de bucket e classificação bit a bit.
Em poucas palavras, não explique. Analisaremos esse algoritmo em detalhes em um dos seguintes artigos.
Outros híbridos
Classificação de contagem de árvores
Contando + árvore
O algoritmo
proposto pelo usuário
AlexanderUsatov . Classificando a contagem, o número de chaves contadas é armazenado em uma árvore balanceada.
Classificação J :: Classificação J
Heap + inserções
Eu
já escrevi sobre essa classificação
há 5 anos . Tudo é bem simples - primeiro na matriz, você precisa criar uma pilha não crescente uma vez e depois fazer exatamente o oposto - criar uma vez não decrescente. Como resultado da primeira operação, o mínimo estará em primeiro lugar da matriz, e pequenos elementos como um todo passarão significativamente para o início. No segundo caso, o máximo estará em último lugar e os elementos grandes serão migrados para o final da matriz. Em geral, obtemos uma matriz quase classificada com a qual fazemos o quê? É isso mesmo - resolva as inserções.
Referências
 Inserção de mesclagem
Inserção de mesclagem ,
mesclagem de bloco ,
Tim ,
Introspective ,
Spread ,
Multikey Graal
Graal Graal
Graal ,
Hash Table ,
Contagem / Árvore ,
JArtigos da série:
De todas as classificações apresentadas aqui, no aplicativo AlgoLab excel, apenas para animação Jsort está atualmente implementada.