Por um longo tempo, muitos têm usado ou olhando ativamente ou ativamente o modelo de armazenamento e publicação de
documentação como código , isso significa aplicar as mesmas regras, ferramentas e procedimentos à documentação que o código do programa, por exemplo, armazená-lo no repositório, executar testes, compilar e liberar em CI / CD. Essa abordagem permite que você mantenha a documentação atualizada com o código, versão e controle as alterações usando ferramentas de desenvolvimento conhecidas.
No entanto, ao mesmo tempo, muitas empresas também possuem wikis há anos, nas quais outras equipes e funcionários, por exemplo, gerentes de projeto, têm acesso à documentação. E se você quisesse trazer armazenamento e publicação para uma única exibição, isto é, juntamente com as docas de publicação HTML no Confluence? Neste artigo, darei uma visão geral das soluções para a tarefa de publicação de documentos do repositório no Confluence.
Eu
uso ativamente uma solução há muito tempo na equipe de desenvolvimento de interfaces (pacote RST-Sphinx + sphinxcontribbuilder) e apresentarei as outras como alternativa. Farei imediatamente uma reserva de que, na prática, não as experimentei, apenas estudei a configuração.
Sphinx doc + sphinxcontribbuilder
Sphinx (que não deve ser confundido com o índice de pesquisa de mesmo nome) é um gerador de documentação escrito em Python e usado ativamente pela comunidade; funciona muito bem em outros ambientes também.
Nós não vamos insistir em configurá-lo em detalhes, só farei uma reserva de que, fora da caixa, ele pode gerar HTML estático, manual, pdf e vários outros formatos, e para a montagem e publicação corretas no repositório deve haver arquivos index.rst (layout da página principal), conf.py (arquivo de configuração) e Makefile (um arquivo que descreve o processo de geração de formatos, aqui é bem possível instalá-lo no docker e executar o comando
sphinx-build lá).
Pronto para uso, o Sphinx pode gerar estações a partir do layout leve * .rst (RestructuredText), mas adicionamos a capacidade de gravar no Markdown (sabor CommonMark) para os desenvolvedores mais confortáveis (a extensão
m2r que converte MD em RST nos ajudou) .
Já configuramos o ambiente inteiro para o Sphinx, e o conjunto da documentação é conectado a um estágio separado no
pipeline de Jenkins; portanto, seguimos em frente e usamos a extensão
sphinxcontrib.confluencebuilder , que pode coletar docas no formato nativo do Confluence e publicá-las. Confluência, neste caso, é um dos formatos de saída da documentação, juntamente com o HTML.

Para que isso funcione, você precisa conectar as extensões em conf.py, abaixo está o fragmento de configuração.
extensions = [ 'sphinxcontrib.confluencebuilder', 'm2r' ] templates_path = ['_templates'] source_suffix = ['.rst', '.md'] master_doc = 'index' exclude_patterns = [ u'docs/warning-plate.rst', u'FEATURE.md', u'CHANGELOG.md', u'builder/README.md' ]
E, em seguida, configure a extensão, ela tem um conjunto de configurações:
confluence_publish = True
O ponto importante é que, mesmo que a página (origem em .rst) não seja especificada em toc e não seja adicionada a exclude_patterns, ela ainda será publicada, mas fora da hierarquia.
Os nomes das páginas no Confluence corresponderão ao primeiro título da página, por exemplo, se você tiver o cabeçalho Exemplo no arquivo example.rst, sublinhado com sinais de igual, ele se tornará o nome da página no Confluence.
A regra de higiene, que é bastante óbvia, mas ainda assim: crie um bot com dados de autorização para os quais você publicará documentos, eles podem ser transferidos na forma de variáveis de ambiente na composição do docker, usada em pipelines.
Claro, existem armadilhas. Primeiramente, nem todas as sintaxes do RST são suportadas para publicação no Confluence (╯ ° □ °) ╯︵ ┻━┻), isso é inconveniente se você deseja coletar HTML e Confluence de uma fonte. As diretivas Container, hlist não são suportadas, quase todos os atributos de diretiva, por exemplo, destacando linhas no código de bloco, numerando no sumário, alinhando e largura para listable.
A lista do que é suportado é muito boa .
Das mais agradáveis, as inclusões são suportadas, isso permite reutilizar fragmentos de conteúdo entre diferentes documentos, autodoc para montar a documentação do código, matemática para fórmulas matemáticas, desenhar tickets e filtros da jira (para isso, você também precisará registrar um servidor Jira na configuração), cabeçalhos numerados e muito mais outro, literalmente, em 3 de janeiro, lançou uma
grande atualização .
A propósito, o suporte a Jira apareceu no multiconversor Pandoc, a partir da
versão 2.7.3 Pandoc suportou a marcação wiki da confluência correspondente.
Para aquelas macros e elementos do Confluence que não são suportados, há um hack sujo. O RST possui uma diretiva
... raw :: , e possui um atributo confluence, aceita marcação conf, se você realmente precisar de algum tipo de macro - você pode copiá-lo no modo de edição da página no Confluence (o modo de código-fonte está disponível no ícone <>) e cole seu código "bruto" lá. Mas eu não te ensinei isso.
.. raw:: confluence <ac:structured-macro ac:macro-id="c38bab13-b51e-4129-85ef-737eab8a1c47" ac:name="status" ac:schema-version=^_^quot quot^_^> <ac:parameter ac:name="colour">Green</ac:parameter> <ac:parameter ac:name="title">Is used</ac:parameter> </ac:structured-macro>
O resultado é o seguinte:

Por que precisamos configurar a publicação do repositório local para a página de teste, e não imediatamente para "prod"? O fato é que, quando você publica, todas as páginas são republicadas a cada vez e processa as alterações feitas manualmente ou os comentários na linha (em linha). Portanto, quando o documento estiver em andamento, decidimos publicá-lo em uma página separada, como o modo dev, para adicionar versões publicadas à revisão e coletar comentários.
No CI, a publicação é implementada como um estágio separado no pipeline Jenkins; dentro desse estágio, a imagem do docker é iniciada no registro remoto, que implementa o sphinx-build com a configuração desejada. É melhor pular imediatamente esta etapa.
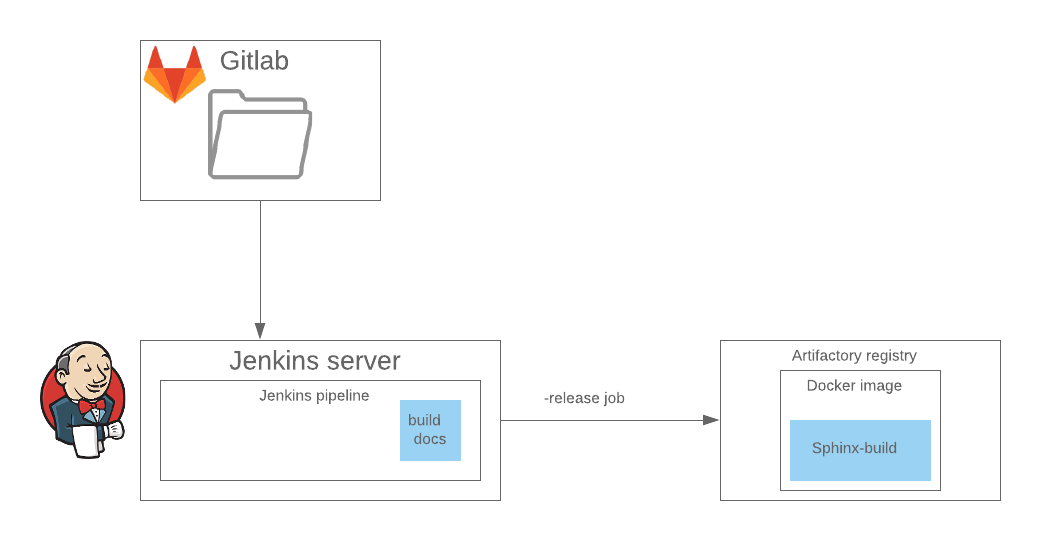
pipeline { agent { label "${AGENT_LABEL}" } stage("Documentation") { steps { ansiColor('xterm') { withCredentials([usernamePassword( credentialsId: "${DOCUMENTATION_BOT}", usernameVariable: 'CONFLUENCE_USERNAME', passwordVariable: 'CONFLUENCE_PASSWORD' )]) { sh "docker-compose -p $COMPOSE_ID run sphinx-doc confluence" } }} }
Dentro do palco, a
confluência do
docker-compose -p release-branch-name é executada sphinx-doc . Jenkinsfile, por sua vez, descreve as dependências e o ambiente em que a etapa será executada, o processo de montagem e atualização das informações no destino. A partir dos testes até agora, há apenas uma verificação de sintaxe de .md e .rst com doc8 e markdownlinter.
Outra nuance: toda vez que você publica uma sub-rede de páginas, o Sphinx atualiza a árvore inteira, cada página. Ou seja, mesmo que o conteúdo não tenha sido alterado, é criada uma alteração, se você tiver notificações configuradas no canal, ele ficará entupido com muitas notificações.
Mais algumas maneiras
Foliant com Confluence como um back-end
Ferramenta de documentação foliant com Mkdocs e muitos pré-processadores sob o capô e back-end na forma de Confluence. Você
pode ler mais aqui , mas, em resumo, ele usa o pandoc para converter md em HTML e depois o publica no Confluence. Você só precisa configurar o back-end e instalar o pandoc no ambiente como uma dependência.
Diferenças favoráveis da primeira solução: ele pode restaurar comentários embutidos nos mesmos locais em que estavam antes da publicação da página, permite criar páginas definindo-as na configuração, editar seus nomes e também inserir conteúdo em uma página existente. Para isso, é necessário definir manualmente âncora foliant na página em confluência.
Funciona apenas com a fonte no Markdown.
Metro
Uma ferramenta múltipla que publica uma ampla variedade de formatos de origem no Confluence, do Google Docs ao Salesforce Quip, e no Markdown também.
Para publicar, você precisa colocar o arquivo manifest.json na pasta em que seus arquivos .md estão localizados, especifique a pasta nela, o arquivo que você deseja publicar, para cada arquivo, especifique o ID da página de confluência. O título da página será o primeiro cabeçalho do arquivo (#). Essa ferramenta possui algumas perversões com a marcação Markdown, portanto, observe as
docas . Anexos e imagens precisam ser colocados na mesma pasta, e a ferramenta também permite que você especifique o uso do índice diretamente na configuração.
Gem md2conf
Ruby gem
md2conf , converte Markdown em nativo para Confluence XHTML. Em seguida, você pode escrever a tarefa Rake, que por sua vez pode ser chamada via Gitlab CI / Jenkins para enviar para o master e puxar a API do Confluence para publicar a página. Para não trazer o ambiente Ruby para você, agrupe as dependências dessa gema em um contêiner.
Como enviar solicitações para a API Confluence é descrito
aqui .
Funciona apenas com a fonte no Markdown.
De encontrado no Github
De fato, vários desses scripts ou ferramentas cli já foram executados na comunidade, mas eu apenas experimentei o md2conf, todos eles são divididos em dois grupos.
Aqueles que apenas convertem formatos (md, asciidoc, rst -> confluence / xhtml):O mais atencioso deles que vi foi este (https://github.com/rogerwelin/markdown2confluence-server), o autor escreveu imediatamente o Dockerfile, que eleva a ferramenta de cli como servidor REST, para que você possa enviar um pacote de solicitações de conversão. .
E aqueles que implementam imediatamente eles mesmos os pedidos para a API Confluence , você só precisa especificar a chave API na configuração:
Escolha qualquer uma das opções (dependendo da linguagem de marcação e da pilha) e colete seu pipeline, dependendo das tarefas que você enfrentar.
PS Se você compartilhar nos comentários outras soluções encontradas para o problema, ficarei muito grato.
E se você quiser conversar mais sobre esses tópicos comigo, visite o KnowledgeConf 2020 em 18 de maio.