 Tradução de um longread interessante dedicado à visualização de conceitos da teoria da informação. Na primeira parte, veremos como representar graficamente distribuições de probabilidade, sua interação e probabilidades condicionais. Em seguida, trataremos dos códigos de comprimento fixo e variável, veremos como o código ideal é construído e por que é assim. Como complemento, o paradoxo estatístico de Simpson é entendido visualmente.
Tradução de um longread interessante dedicado à visualização de conceitos da teoria da informação. Na primeira parte, veremos como representar graficamente distribuições de probabilidade, sua interação e probabilidades condicionais. Em seguida, trataremos dos códigos de comprimento fixo e variável, veremos como o código ideal é construído e por que é assim. Como complemento, o paradoxo estatístico de Simpson é entendido visualmente.A teoria da informação nos fornece uma linguagem precisa para descrever muitas coisas. Quanta incerteza existe em mim? Quanto conhecimento da resposta à pergunta A me diz sobre a resposta da pergunta B? Quão semelhante é um conjunto de crenças para outro? Eu tinha versões informais dessas idéias quando era criança, mas a teoria da informação as cristaliza em idéias precisas e poderosas. Essas idéias têm uma enorme variedade de aplicações, da compactação de dados à física quântica, aprendizado de máquina e as vastas áreas entre elas.
Infelizmente, a teoria da informação pode parecer intimidadora. Eu não acho que exista alguma razão para isso. De fato, muitas idéias importantes podem ser explicadas visualmente!
Visualização da Distribuição de Probabilidades
Antes de nos aprofundarmos na teoria da informação, vamos pensar em como você pode visualizar distribuições simples de probabilidade. Mais tarde, precisaremos delas; além disso, essas técnicas para visualizar probabilidades são úteis por si mesmas!
Eu estou na Califórnia. Às vezes chove, mas principalmente o sol! Digamos, 75% do tempo está ensolarado. É fácil descrever na figura:
Na maioria dos dias, visto uma camiseta, mas às vezes uso uma capa de chuva. Suponha que eu uso uma capa de chuva 38% do tempo. Isso também é fácil de retratar.
E se eu quiser visualizar os dois fatos ao mesmo tempo? É simples se eles não interagirem, ou seja, são independentes. Por exemplo, se: que eu uso uma camiseta ou uma capa de chuva hoje não depende do tempo na próxima semana. Podemos descrever isso usando um eixo para uma variável e um para a outra:

Preste atenção às linhas verticais e horizontais retas que atravessam. É assim que parece a independência! A probabilidade de eu usar uma capa de chuva não mudará devido ao fato de que em uma semana chove. Em outras palavras, a probabilidade de usar uma capa de chuva e chover na próxima semana é igual à probabilidade de usar uma capa de chuva vezes a probabilidade de chover. Eles não interagem.
Quando as variáveis interagem, a probabilidade pode aumentar para alguns pares de variáveis e diminuir para outros. Existe uma grande probabilidade de eu usar uma capa de chuva e chover porque as variáveis estão correlacionadas, elas se tornam mais prováveis. É mais provável que eu use uma capa de chuva em um dia em que chove do que a probabilidade de usar uma capa de chuva em um dia e chove em outro dia aleatório.
Visualmente, parece que alguns quadrados incham com uma probabilidade adicional, enquanto outros quadrados se estreitam, porque é improvável que ocorram alguns eventos simultaneamente:
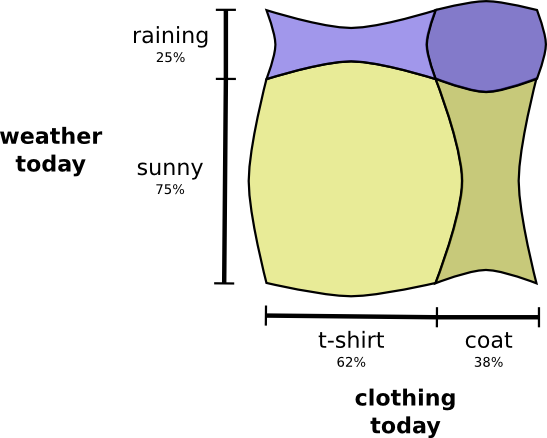
Mas, embora pareça legal, não é muito útil para entender o que está acontecendo.
Em vez disso, vamos nos concentrar em uma variável como o clima. Conhecemos as probabilidades de tempo ensolarado e chuvoso. Nos dois casos, podemos considerar probabilidades condicionais. Qual é a probabilidade de eu usar uma camiseta se estiver ensolarado? Qual é a probabilidade de usar uma capa de chuva se chover?
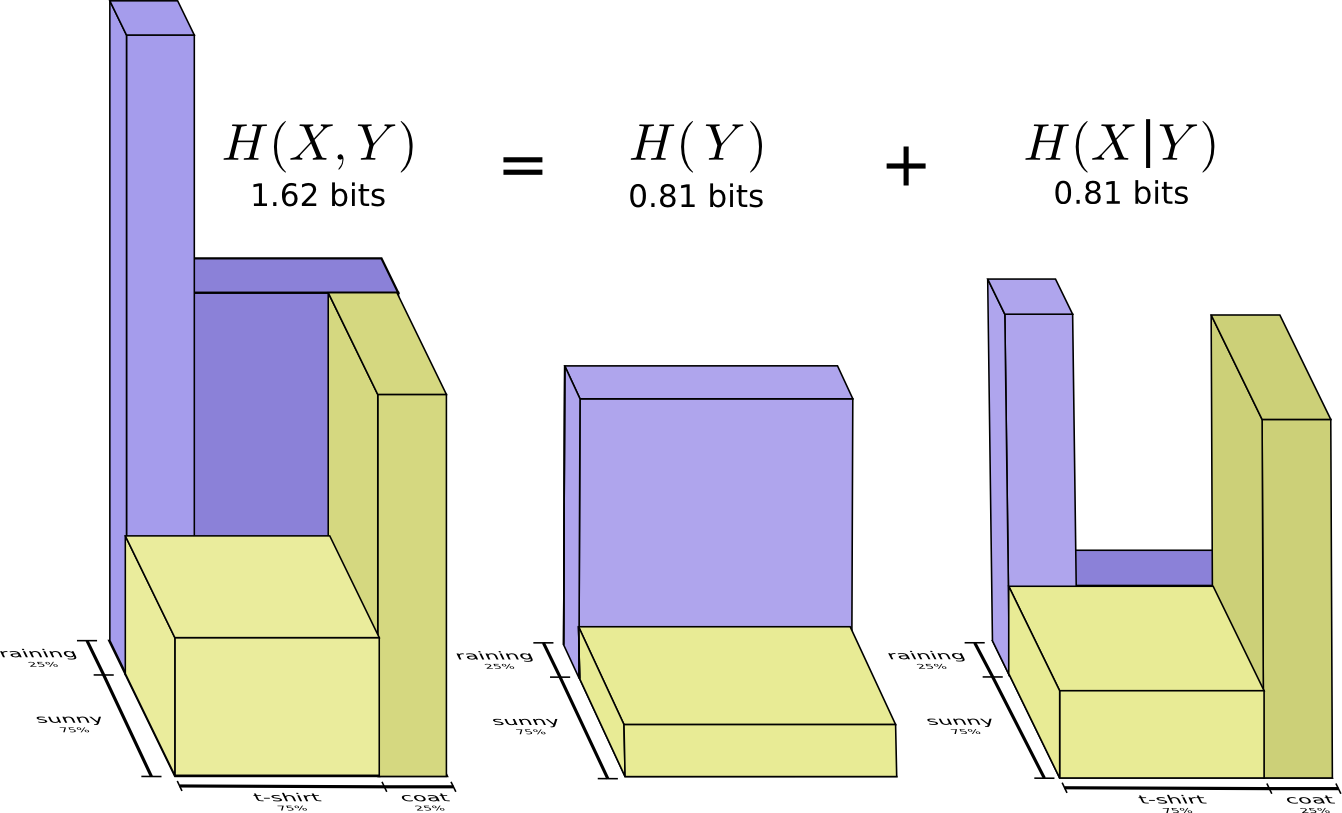
Com uma probabilidade de 25%, chove. Se chover, usarei uma capa de chuva com 75% de chance. Assim, a probabilidade de chover e de usar uma capa de chuva é de 25% a 75%, ou seja, aproximadamente 19%. A probabilidade de que esteja chovendo e eu estou usando uma capa de chuva é a probabilidade de que esteja chovendo multiplicado pela probabilidade de que eu usarei uma capa de chuva se estiver chovendo. Nós escrevemos assim:
Este é um exemplo de uma das identidades mais fundamentais da teoria das probabilidades:
Nós fatoramos a distribuição dividindo-a em um produto de duas partes. Primeiro, examinamos a probabilidade de uma variável, o clima, assumir um determinado valor. Depois, analisamos a probabilidade de outra variável, minhas roupas, assumir o valor devido à primeira variável.
Qual variável para começar não importa. Poderíamos começar com minhas roupas e depois ver o clima causado por isso. Isso pode parecer menos intuitivo, porque entendemos que existe uma relação causal entre o clima que afeta o que eu visto e não vice-versa ... mas funciona de qualquer maneira!
Vejamos um exemplo. Se escolhermos um dia aleatório, com uma probabilidade de 38%, usarei uma capa de chuva. Se sabemos que estou em uma capa de chuva, qual a probabilidade de chover? Prefiro usar uma capa de chuva na chuva do que no sol, mas a chuva na Califórnia é rara, e acontece que com 50% de chance de chover. Portanto, a probabilidade de estar chovendo e usar uma capa de chuva é a probabilidade de usar uma capa de chuva (38%), multiplicada pela probabilidade de chover se eu usar uma capa de chuva (50%), que é aproximadamente 19%.
Isso nos dá uma segunda maneira de visualizar a mesma distribuição de probabilidade.
Observe que os valores das etiquetas têm um significado ligeiramente diferente do que no diagrama anterior: agora uma camiseta e uma capa de chuva são as probabilidades limite, a probabilidade de usar essas roupas sem levar em consideração o clima. Por outro lado, agora existem duas marcas de chuva e sol, porque suas probabilidades dependem do fato de eu usar uma camiseta ou capa de chuva.
(Você pode ter ouvido falar do teorema de Bayes. Você pode imaginá-lo como uma maneira de transição entre essas duas maneiras diferentes de representar a distribuição de probabilidade!)
Caixa: O Paradoxo dos Simpson
Essas técnicas de visualização para distribuições de probabilidade são realmente úteis? Eu acho que sim! Um pouco mais, nós os usamos para visualizar a teoria da informação, mas por enquanto os usamos para estudar o paradoxo de Simpson. O paradoxo de Simpson é uma situação estatística extremamente intuitiva. É difícil de entender em um nível intuitivo. Michael Nielsen escreveu um excelente ensaio
Reinventing Explanation , que explica o paradoxo de várias maneiras. Quero tentar fazer isso sozinho, usando as técnicas que desenvolvemos na seção anterior.
Dois métodos para o tratamento de cálculos renais estão sendo testados. Metade dos pacientes recebe o tratamento A, enquanto a outra metade recebe o tratamento B. Os pacientes que receberam o tratamento B tiveram maior probabilidade de se recuperar do que aqueles que receberam o tratamento A.
No entanto, pacientes com pequenas pedras nos rins eram mais propensos a se recuperar se recebessem tratamento A. Os pacientes com grandes pedras nos rins também tinham maior probabilidade de se recuperar se recebessem o tratamento A! Como isso pode ser?
A essência do problema é que o estudo não foi adequadamente randomizado. Entre os pacientes que receberam o tratamento A, houve mais pacientes com grandes pedras nos rins, e entre os pacientes que receberam o tratamento B, houve mais com pequenas pedras nos rins.
Acontece que pacientes com pequenas pedras nos rins têm muito mais chances de se recuperar em geral.
Para entender melhor isso, podemos combinar os dois diagramas anteriores. O resultado é um gráfico tridimensional com uma taxa de recuperação dividida em pequenas e grandes pedras nos rins.
Agora vemos que, no caso de pedras pequenas e grandes, o tratamento A é superior ao tratamento B. O tratamento B parecia melhor apenas porque os pacientes aos quais foi aplicado tinham, em geral, mais chances de recuperação!
Códigos
Agora que temos maneiras de visualizar a probabilidade, podemos mergulhar na teoria da informação.
Deixe-me contar sobre meu amigo imaginário, Bob. Bob ama muito os animais. Ele constantemente fala sobre animais. De fato, ele fala apenas quatro palavras: "cachorro", "gato", "peixe" e "pássaro".
Algumas semanas atrás, apesar de Bob ser uma invenção da minha imaginação, ele se mudou para a Austrália. Além disso, ele decidiu que queria se comunicar apenas em formato binário. Todas as minhas mensagens (imaginárias) de Bob são assim:
Para nos comunicar, Bob e eu precisamos criar um sistema de codificação - uma maneira de exibir palavras em uma sequência de bits.
Para enviar uma mensagem, Bob substitui cada caractere (palavra) pela palavra-código correspondente e os combina para formar uma sequência codificada.
Códigos de comprimento variável
Infelizmente, os serviços de comunicação na Austrália imaginária são caros. Tenho que pagar US $ 5 por um pouco de cada mensagem que recebo de Bob. Eu mencionei que Bob gosta de conversar muito? Para não falir, Bob e eu decidimos descobrir se era possível reduzir de alguma forma o tamanho médio da mensagem.
Acontece que Bob não pronuncia todas as palavras com a mesma frequência. Bob ama muito cães. Ele fala sobre cães o tempo todo. Às vezes, ele fala sobre outros animais - especialmente um gato que seu cão gosta de perseguir -, mas principalmente ele fala sobre cães. Aqui está um gráfico da frequência de suas palavras:
Isso é encorajador. Nosso código antigo usa palavras de código de 2 bits, independentemente da frequência com que são usadas.
Existe uma boa maneira de visualizar isso. No diagrama a seguir, usamos o eixo vertical para visualizar a probabilidade de cada palavra
e um eixo horizontal para visualizar o comprimento da palavra de código correspondente
. Observe que a área resultante é o comprimento médio da palavra de código que enviamos, neste caso 2 bits.
Podemos ser mais inteligentes e tornar o código variável em tamanho, onde as palavras de código para palavras comuns são reduzidas. O problema é que há concorrência entre as palavras de código - tornando algumas mais curtas, somos forçados a prolongar outras. Para minimizar o tamanho da mensagem, o ideal é que todas as palavras-código sejam curtas, mas a mais curta deve ser amplamente usada. Portanto, o código resultante contém palavras de código mais curtas para palavras comuns (por exemplo, “cachorro”) e palavras de código mais longas para palavras raras (por exemplo, “pássaro”).
Vamos visualizar isso novamente. Observe que as palavras de código mais comuns são mais curtas e as mais raras, mais longas. Como resultado, conseguimos uma área menor. Isso corresponde a um menor comprimento esperado da palavra de código. O comprimento médio da palavra-código é agora de 1,75 bits!
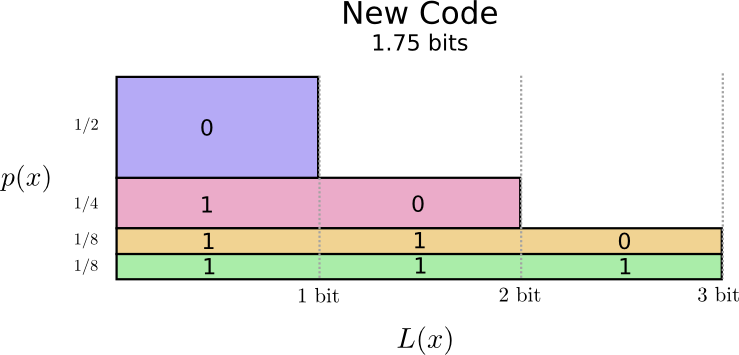
(Você pode se perguntar: por que não usar 1 separadamente como uma palavra de código? Infelizmente, isso causará ambiguidade ao decodificar seqüências de caracteres codificadas. Falaremos mais sobre isso mais adiante.)
Acontece que esse código é o melhor possível. Não há código para esta distribuição que nos daria um comprimento médio de palavra de código inferior a 1,75 bits.
Existe um limite fundamental. A transmissão do que foi dito, qual evento dessa distribuição ocorreu, exige que transmitamos uma média de pelo menos 1,75 bits. Não importa o quão inteligente seja nosso código, é impossível conseguir que o tamanho médio da mensagem seja menor. Chamamos esse limite fundamental de
entropia de distribuição - discutiremos mais detalhadamente abaixo.
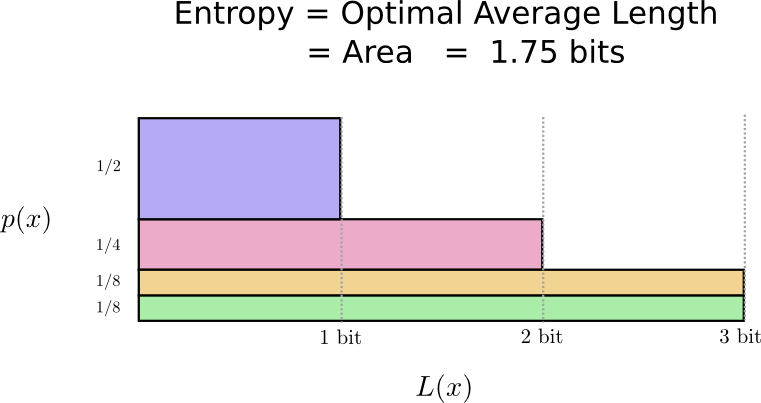
Se queremos entender esse limite, precisamos entender a relação entre manter algumas palavras de código curtas e outras longas. Depois de descobrirmos isso, podemos descobrir como são os melhores sistemas de codificação possíveis.
Espaço da palavra de código
Existem duas palavras de código com um comprimento de 1 bit: 0 e 1. Existem quatro palavras de código com um comprimento de 2 bits: 00, 01, 10 e 11. Cada bit adicionado duplica o número de palavras de código possíveis.
Estamos interessados em códigos de comprimento variável, onde algumas palavras de código são mais longas que outras. Podemos ter situações simples quando temos oito palavras de código com 3 bits de comprimento. Pode haver misturas mais complexas, por exemplo, duas palavras de código de comprimento 2 e quatro palavras de código de comprimento 3. O que decide quantas palavras de código de comprimentos diferentes podemos ter?
Lembre-se de que Bob transforma suas mensagens em seqüências criptografadas, substituindo cada palavra pelo código e concatenando-as.
Há uma pergunta sutil a ser cuidadosa ao criar códigos de tamanho variável. Como dividimos a sequência codificada em palavras de código? Quando todas as palavras de código têm o mesmo comprimento, é fácil - basta dividir a corda em pedaços desse comprimento. Mas como existem palavras de código de vários comprimentos, precisamos prestar atenção ao conteúdo.
Queremos que nosso código seja decodificado de forma única. E não queremos que seja ambíguo ao determinar quais palavras de código compõem a sequência codificada. Se tivéssemos um símbolo especial “fim da palavra de código”, seria simples. Mas não temos isso - enviamos apenas 0 e 1. Precisamos analisar a sequência de palavras de código e determinar onde cada uma delas termina.
É muito simples criar códigos que não podem ser descriptografados sem ambiguidade. Por exemplo, imagine que 0 e 01 são ambas as palavras de código. Não está claro qual é a primeira palavra de código da linha 0100111 - pode ser isso ou aquilo! A propriedade de que precisamos é que, se virmos uma palavra de código específica, ela não deverá ser incluída em outra palavra de código mais longa. Em outras palavras, nenhuma palavra de código deve ser um prefixo de outra palavra de código. Isso é chamado de propriedade de prefixo e os códigos que obedecem a ele são chamados de
códigos de prefixo .
Uma maneira útil de representar isso é que cada palavra de código requer sacrifícios do espaço de possíveis palavras de código. Se usarmos a palavra de código 01, perderemos a capacidade de usar qualquer palavra de código cujo prefixo seja. Não podemos mais usar 010 ou 011010110 por causa da ambiguidade - eles estão perdidos para nós.
Como um quarto de todas as palavras de código começa em 01, doamos um quarto de todas as palavras de código possíveis. Aqui está o preço que pagamos em troca do fato de termos uma palavra-código com apenas 2 bits! Por sua vez, esse sacrifício significa que todas as outras palavras de código devem ser um pouco mais longas. Sempre existe um tipo de compromisso entre os comprimentos das diferentes palavras de código. Uma palavra de código curta exige que você sacrifique a maior parte do espaço possível de palavras de código, o que impede a brevidade de outras palavras de código. O que precisamos descobrir é como se comprometer corretamente!
Codificação ideal
Você pode pensar nisso como um orçamento limitado que pode gastar para obter palavras curtas em código. Pagamos por uma palavra-código, sacrificando parte das possíveis palavras-código.
O custo da compra de uma palavra-código com o comprimento 0 é 1 - todas as palavras-código possíveis - se você deseja ter uma palavra-código com o comprimento 0, não pode ter nenhuma outra palavra-código. O custo de uma palavra de código com um comprimento de 1, por exemplo, "0", é 1/2, porque metade das palavras de código possíveis começa com "0". O custo de uma palavra de código de comprimento 2, por exemplo "01", é 1/4, porque um quarto de todas as palavras de código possíveis começa com "01". Em geral, o custo das palavras de código diminui exponencialmente com o aumento do comprimento da palavra de código.
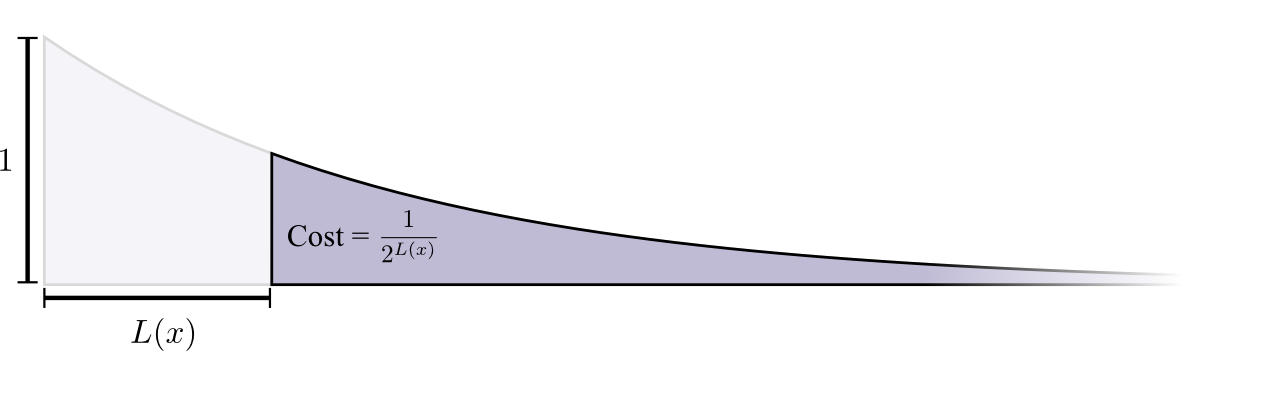
Observe que, se o custo diminuir como expositor (em espécie), isso significa altura e área! (
O exemplo usou um expoente com base 2 onde esse fato está incorreto, mas você pode alternar para o expoente natural, o que simplifica visualmente a prova. )
Precisamos de palavras de código curtas, porque queremos reduzir o tamanho médio das mensagens. Cada palavra de código aumenta o tamanho médio da mensagem pela probabilidade dessa palavra multiplicar por seu comprimento. Por exemplo, se precisarmos enviar uma palavra de código com 4 bits de comprimento 50% do tempo, o tamanho médio da mensagem será 2 bits mais longo do que se não enviámos essa palavra de código. Podemos imaginar isso como um retângulo.
Esses dois valores estão relacionados pelo comprimento da palavra de código. O preço que pagamos determina o tamanho da palavra-código. O comprimento da palavra-código determina quanto ela adiciona ao comprimento médio da mensagem. Podemos imaginá-los juntos assim.
As palavras curtas reduzem a duração média das mensagens, mas são caras, enquanto as longas aumentam a duração média das mensagens, mas são baratas.

Qual é a melhor maneira de usar nosso orçamento limitado? Quanto devemos gastar em uma palavra de código para cada evento?
Assim como uma pessoa deseja investir mais em ferramentas que usa regularmente, queremos gastar mais em palavras de código usadas com frequência. Há uma maneira particularmente natural de fazer isso: distribuir nosso orçamento na proporção da frequência com que o evento ocorre. Portanto, se um evento ocorrer em 50% dos casos, gastamos 50% do nosso orçamento na compra de uma palavra de código abreviada para ele. Mas se o evento ocorrer apenas 1% do tempo, gastamos apenas 1% do nosso orçamento, porque não estamos muito preocupados com o tamanho da palavra-código.
Isso é uma coisa bastante natural, mas é ideal? É assim, e eu vou provar!
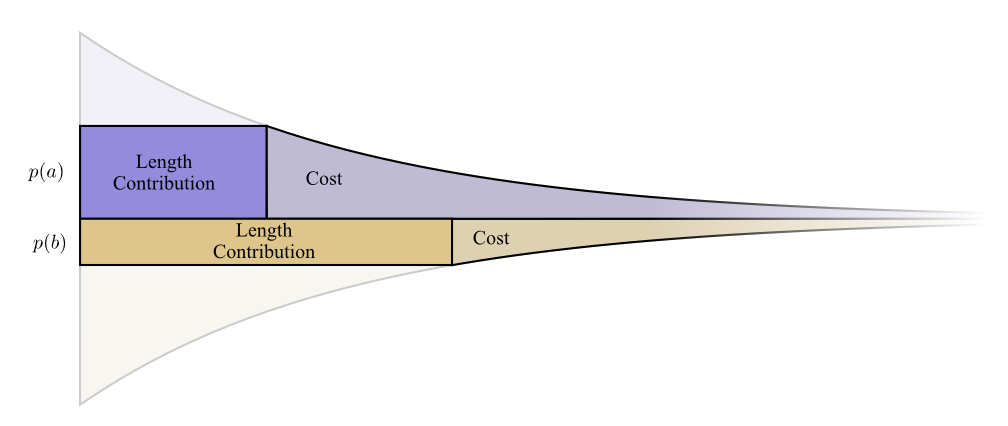
A prova a seguir é clara e deve ser entendida, mas será necessário algum trabalho para constar, e essa é definitivamente a parte mais difícil deste ensaio. Os leitores podem ignorá-lo com segurança, aceitando o fato sem provas e prosseguir para a próxima seção.Vejamos um exemplo específico em que precisamos dizer qual dos dois possíveis eventos aconteceu. Evento acontecendo hora e evento acontecendo hora. Alocamos nosso orçamento da maneira natural descrita acima, gastando nosso orçamento para uma palavra curta de código e
para receber uma palavra de código curta .
 Os limites de custo e comprimento estão alinhados lindamente. Isso significa alguma coisa?Considere o que acontece com a contribuição de custo e comprimento se alterarmos um pouco o comprimento da palavra-código. Se aumentarmos ligeiramente o comprimento da palavra-código, a contribuição do comprimento da mensagem aumentará proporcionalmente à sua altura na borda e o custo diminuirá proporcionalmente à sua altura na borda.
Os limites de custo e comprimento estão alinhados lindamente. Isso significa alguma coisa?Considere o que acontece com a contribuição de custo e comprimento se alterarmos um pouco o comprimento da palavra-código. Se aumentarmos ligeiramente o comprimento da palavra-código, a contribuição do comprimento da mensagem aumentará proporcionalmente à sua altura na borda e o custo diminuirá proporcionalmente à sua altura na borda. Assim, o custo de criar uma palavra-código mais curta é
Assim, o custo de criar uma palavra-código mais curta é .
Não estamos igualmente preocupados com o comprimento de cada palavra de código; eles nos interessam na proporção da frequência com que os usamos. Em caso de É isso .
Nosso ganho ao reduzir a palavra-código é proporcional .
Curiosamente, ambos os derivativos são os mesmos. Isso significa que nosso orçamento inicial tem uma característica interessante: se você tivesse um pouco mais de dinheiro, seria igualmente bom investir na redução de qualquer palavra de código. O que realmente importa é a relação custo / benefício - é isso que decide em que investir mais. Nesse caso, a proporção, que é igual a um. Não depende do valor de p (a) - é sempre igual à unidade. E podemos aplicar o mesmo argumento a outros eventos. O benefício / custo é sempre um, portanto, faz sentido investir um pouco mais em qualquer um dos eventos.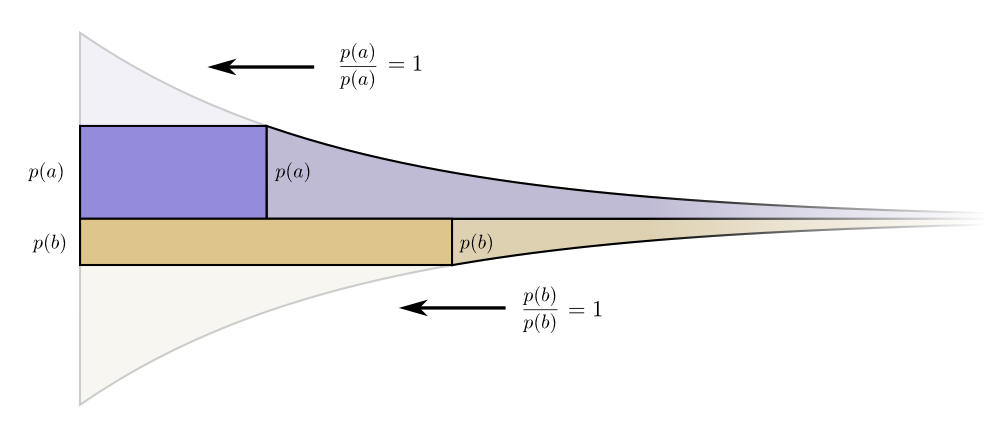 Em termos de infinitesimal, alterar o orçamento não faz sentido. Mas isso não prova que este é o melhor orçamento. Para provar isso, veremos um orçamento diferente, onde gastamos um pouco mais em uma palavra de código à custa de outra. Nós vamos gastar em menos por e adicione isso evento
Em termos de infinitesimal, alterar o orçamento não faz sentido. Mas isso não prova que este é o melhor orçamento. Para provar isso, veremos um orçamento diferente, onde gastamos um pouco mais em uma palavra de código à custa de outra. Nós vamos gastar em menos por e adicione isso evento .
Faz uma palavra de código para um pouco mais curto e a palavra-código para um pouco mais.Agora, o preço de compra de uma palavra-código mais curta para é igual a , e o preço de compra da palavra-código mais curta para é igual a .
Mas os benefícios são os mesmos. Isso leva ao fato de que a relação custo / benefício para a compra será que é menos de um. Por outro lado, a relação custo / benefício da compra b éisso é mais que um.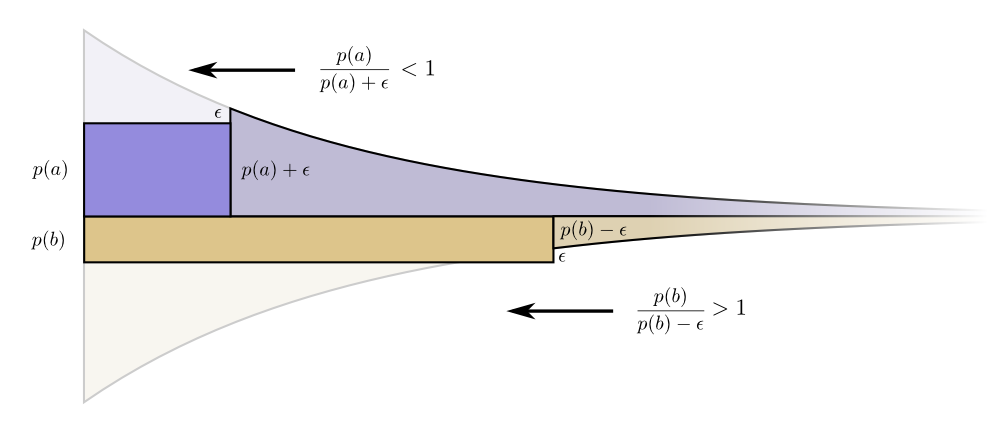 Os preços não são mais equilibrados. melhor negócio que
Os preços não são mais equilibrados. melhor negócio que .
Investidores gritam: "Compre !
Vender ! ”Estamos fazendo isso e retornando ao nosso plano de orçamento original. Todos os orçamentos podem ser aprimorados retornando ao nosso plano original.O orçamento inicial - investir em cada palavra de código na proporção da frequência com que o usamos - não era apenas uma opção natural, mas uma ótima. (Nossa prova funciona apenas para duas palavras de código; pode ser facilmente generalizada para um número maior.)(Um leitor atento pode ter notado que, no caso de um orçamento ideal, podem aparecer códigos com comprimento fracionário. O que isso significa? Na prática, se você deseja se comunicar enviando uma palavra de código, precisará arredondar o valor. Mas como veja mais adiante, há um sentido real no envio de palavras de código fracionárias quando enviamos muitas delas ao mesmo tempo!)PS A continuação é dedicada à entropia, entropia cruzada, informações mútuas, bits fracionários e outras coisas interessantes.