Se você ler o treinamento sobre codificadores automáticos no site keras.io, uma das primeiras mensagens é mais ou menos assim: na prática, os codificadores automáticos quase nunca são usados, mas são frequentemente mencionados nos treinamentos e as pessoas aparecem, por isso decidimos escrever nosso próprio tutorial:
Sua principal reivindicação à fama vem do fato de aparecer em muitas aulas introdutórias de aprendizado de máquina disponíveis on-line. Como resultado, muitos recém-chegados ao campo amam absolutamente os auto-codificadores e não conseguem obter o suficiente deles. Esta é a razão pela qual este tutorial existe!
No entanto, uma das tarefas práticas para as quais elas podem ser aplicadas é a busca de anomalias, e eu pessoalmente precisei disso no âmbito do projeto noturno.
Na Internet, existem muitos tutoriais sobre codificadores automáticos, o que escrever mais um? Bem, para ser sincero, havia várias razões para isso:
- Havia um sentimento de que, de fato, os tutoriais eram cerca de 3 ou 4, todos os demais foram reescritos com suas próprias palavras;
- Quase tudo - no longânimo MNIST'e com fotos 28x28;
- Na minha humilde opinião - eles não desenvolvem uma intuição sobre como tudo isso deve funcionar, mas simplesmente se oferecem para repetir;
- E o fator mais importante - pessoalmente, quando substituí o MNIST pelo meu próprio conjunto de dados - tudo estupidamente parou de funcionar .
A seguir, descrevemos meu caminho no qual os cones são recheados. Se você pegar qualquer um dos modelos planos não convolucionais da massa de tutoriais e colá-lo estupidamente, nada surpreendentemente não funcionará. O objetivo do artigo é entender o porquê e, ao que me parece, obter algum tipo de entendimento intuitivo de como tudo isso funciona.
Não sou especialista em aprendizado de máquina e uso as abordagens com as quais estou acostumado no trabalho diário. Para cientistas de dados experientes, provavelmente este artigo inteiro será uma loucura, mas para iniciantes, parece-me, algo novo pode surgir.
que tipo de projetoEm poucas palavras sobre o projeto, embora o artigo não seja sobre ele. Existe um receptor ADS-B, que captura dados das aeronaves que voam e as grava, aeronaves, coordenadas na base. Às vezes, os aviões se comportam de maneira incomum - eles circulam para queimar combustível antes do pouso, ou simplesmente voos particulares passam por rotas padrão (corredores). É interessante isolar cerca de mil aeronaves por dia daquelas que não se comportaram como as demais. Admito plenamente que os desvios básicos podem ser calculados com mais facilidade, mas estava interessado em tentar a magia redes neurais.
Vamos começar. Eu tenho um conjunto de dados de 4000 imagens em preto e branco de 64x64 pixels, é algo como isto:

Apenas algumas linhas em um fundo preto e na imagem de 64x64 cerca de 2% dos pontos são preenchidos. Se você observar muitas fotos, é claro que a maioria das linhas é bem parecida.
Não vou entrar em detalhes de como o conjunto de dados foi carregado, processado, porque o objetivo do artigo, novamente, não é esse. Apenas mostre um pedaço assustador de código.
Aqui, por exemplo, é o primeiro modelo proposto com o keras.io, no qual eles trabalharam e treinaram no mnist:
No meu caso, o modelo é definido assim:
model = tf.keras.Sequential() model.add(tf.keras.Input(shape=(64,64,1))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(64*64/10, activation='relu')) model.add(tf.keras.layers.Dense(64*64, activation="sigmoid")) model.add(tf.keras.layers.Reshape(target_shape=(64,64,1)))
Existem pequenas diferenças que eu aplico e remodelo diretamente no modelo, e que eu "compresso" não 25 vezes, mas apenas 10. Isso não deve afetar nada.
Como uma função de perda - erro quadrático médio, o otimizador não é fundamental, deixe Adam. A seguir, treinamos 20 épocas, 100 etapas por época.
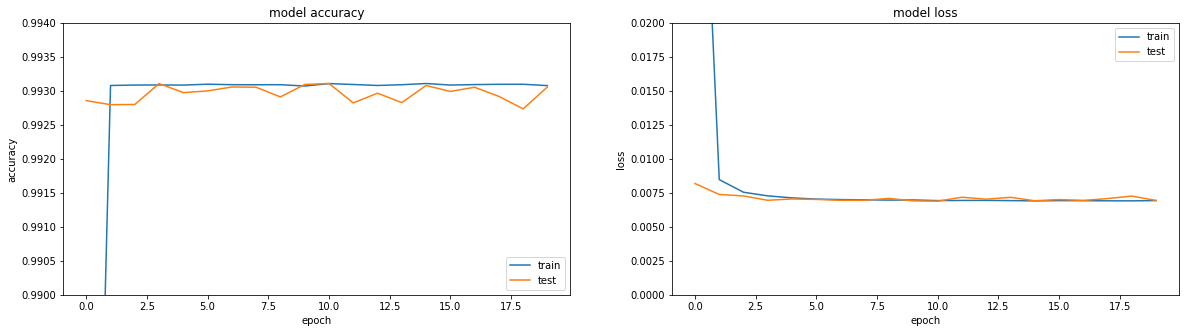
Se você olhar para as métricas - tudo está pegando fogo. Precisão == 0,993. Se você observar os horários de treinamento - tudo é um pouco mais triste, chegamos a um platô na região da terceira era.
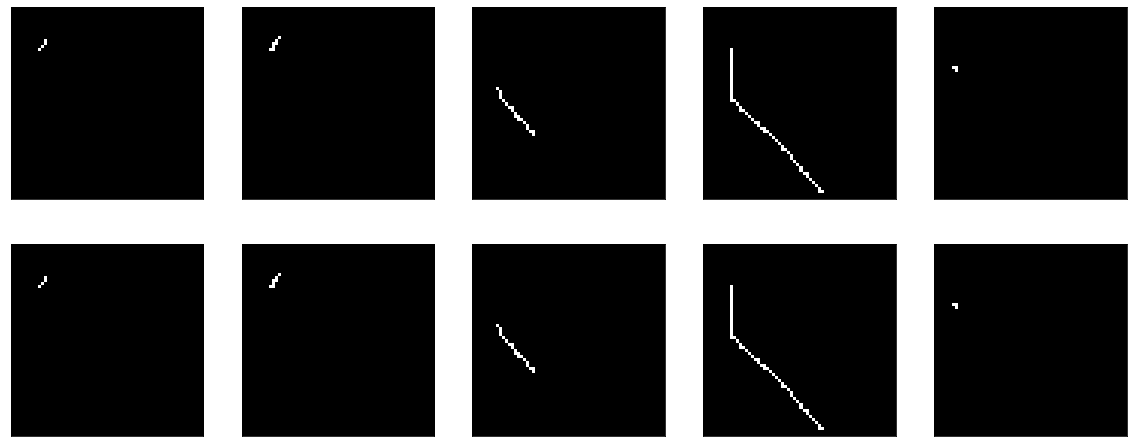
Bem, se você olhar diretamente para o resultado do codificador, obtém uma imagem geralmente triste (o original está no topo e o resultado da decodificação de codificação está abaixo):

Em geral, quando você tenta descobrir por que algo não está funcionando, é uma abordagem suficientemente boa para dividir toda a funcionalidade em blocos grandes e verificar cada um deles isoladamente. Então vamos lá.
No original do tutorial - dados simples são fornecidos à entrada do modelo e são obtidos na saída. Por que não conferir minhas ações achatar e remodelar. Aqui está um modelo não operacional:
model = tf.keras.Sequential() model.add(tf.keras.Input(shape=(64,64,1))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Reshape(target_shape=(64,64,1)))
Resultado:
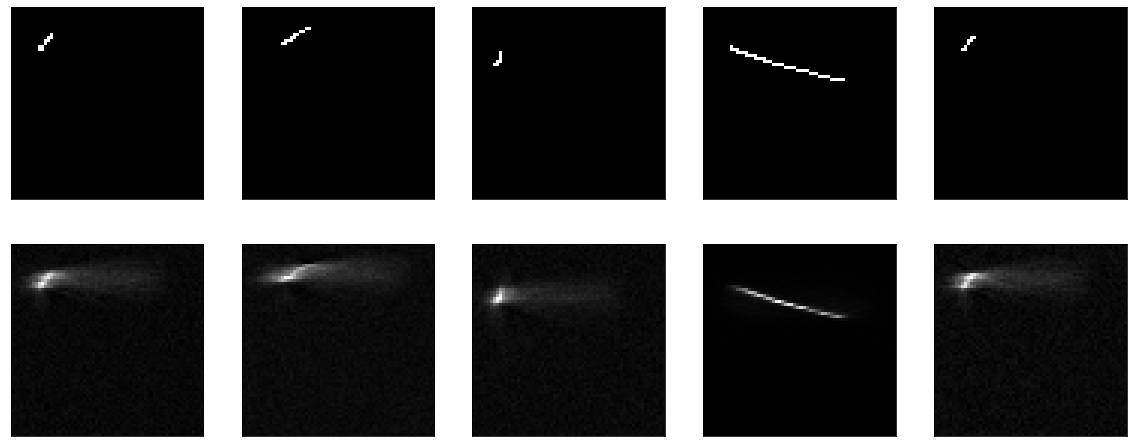
Não há nada a ser ensinado aqui. Bem, ao mesmo tempo, provou que minha função de visualização também funciona.
Em seguida, tente tornar o modelo não operacional, mas o mais burro possível - apenas recorte a camada de compressão, deixe uma camada do tamanho da entrada. Como eles dizem em todos os tutoriais, eles dizem que é muito importante que seu modelo aprenda recursos, e não apenas uma função de identidade. Bem, é exatamente isso que tentaremos obter, vamos apenas passar a imagem resultante para a saída.
model = tf.keras.Sequential() model.add(tf.keras.Input(shape=(64,64,1))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(64*64, activation="sigmoid")) model.add(tf.keras.layers.Reshape(target_shape=(64,64,1)))
Ela está aprendendo algo, precisão == 0,995 e novamente tropeça em um platô.
Mas, em geral, é claro que isso não funciona muito bem. Enfim - o que aprender lá, passe pela entrada da saída e pronto.
Se você ler a documentação do keras sobre camadas densas, ele descreverá o que eles fazem: output = activation(dot(input, kernel) + bias)
Para que a saída coincida com a entrada, duas coisas simples são suficientes - viés = 0 e kernel - a matriz de identidade (é importante não deixar a matriz cheia de unidades aqui - são coisas muito diferentes). Felizmente, isso e aquilo podem ser feitos com bastante facilidade a partir da documentação para o mesmo Dense .
model = tf.keras.Sequential() model.add(tf.keras.Input(shape=(64,64,1))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(64*64, activation = "sigmoid", use_bias=False, kernel_initializer = tf.keras.initializers.Identity())) model.add(tf.keras.layers.Reshape(target_shape=(64,64,1)))
Porque definimos o peso imediatamente, então você não pode aprender nada - logo é bom:
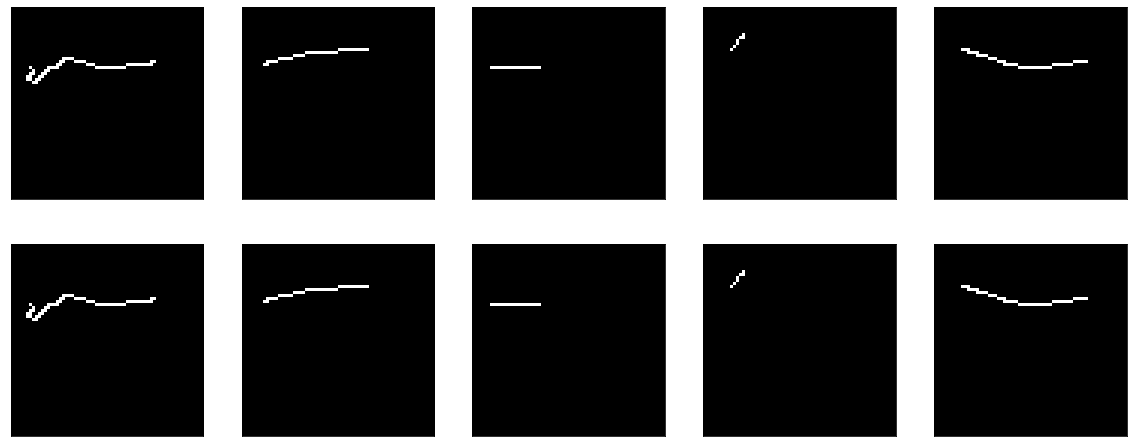
Mas se você começar a treinar, ele começará, à primeira vista, surpreendentemente - o modelo começa com precisão == 1,0, mas cai rapidamente.
Avalie o resultado antes do treinamento: 8/Unknown - 1s 140ms/step - loss: 0.2488 - accuracy: 1.0000[0.24875330179929733, 1.0] . Treinamento:
Epoch 1/20 100/100 [==============================] - 6s 56ms/step - loss: 0.1589 - accuracy: 0.9990 - val_loss: 0.0944 - val_accuracy: 0.9967 Epoch 2/20 100/100 [==============================] - 5s 51ms/step - loss: 0.0836 - accuracy: 0.9964 - val_loss: 0.0624 - val_accuracy: 0.9958 Epoch 3/20 100/100 [==============================] - 5s 50ms/step - loss: 0.0633 - accuracy: 0.9961 - val_loss: 0.0470 - val_accuracy: 0.9958 Epoch 4/20 100/100 [==============================] - 5s 48ms/step - loss: 0.0520 - accuracy: 0.9961 - val_loss: 0.0423 - val_accuracy: 0.9961 Epoch 5/20 100/100 [==============================] - 5s 48ms/step - loss: 0.0457 - accuracy: 0.9962 - val_loss: 0.0357 - val_accuracy: 0.9962
Sim, e não está muito claro, já temos um modelo ideal - a imagem sai 1 em 1 e a perda (erro quadrático médio) mostra quase 0,25.
A propósito, essa é uma pergunta frequente nos fóruns - a perda está caindo, mas a precisão não está aumentando, como pode ser isso?
Aqui vale a pena recordar mais uma vez a definição da camada Densa: output = activation(dot(input, kernel) + bias) e a palavra ativação mencionada, que eu ignorei com sucesso acima. Com pesos da matriz de identidade e sem viés, obtemos output = activation(input) .
Na verdade, a função de ativação em nosso código fonte já está indicada, sigmoide, eu a copiei estupidamente e é isso. E nos tutoriais, é aconselhável usá-lo em qualquer lugar. Mas você tem que descobrir.
Para iniciantes, você pode ler na documentação o que eles escrevem sobre isso: The sigmoid activation: (1.0 / (1.0 + exp(-x))) . Pessoalmente, isso não me diz nada, porque eu não sou fantasma uma vez para criar esses gráficos na minha cabeça.
Mas você pode construir com canetas:
import matplotlib.ticker as plticker range_tensor = tf.range(-4, 4, 0.01, dtype=tf.float32) fig, ax = plt.subplots(1,1) plt.plot(range_tensor.numpy(), tf.keras.activations.sigmoid(range_tensor).numpy()) ax.grid(which='major', linestyle='-', linewidth='0.5', color='red') ax.grid(which='minor', linestyle=':', linewidth='0.5', color='black') ax.yaxis.set_major_locator(plticker.MultipleLocator(base=0.5) ) plt.minorticks_on()
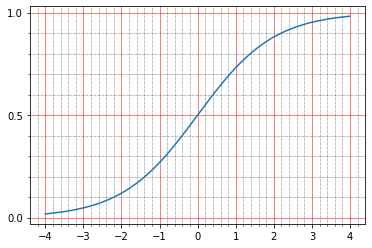
E aqui fica claro que em zero o sigmóide assume o valor 0,5 e na unidade - em torno de 0,73. E os pontos que temos são pretos (0,0) ou brancos (1,0). Portanto, o erro quadrado médio da função de identidade permanece diferente de zero.
Você pode até olhar as canetas, aqui está uma linha da imagem resultante:
array([0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.7310586, 0.7310586, 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 ], dtype=float32)
E isso é tudo, de fato, muito legal, porque várias perguntas aparecem ao mesmo tempo:
- por que isso não era visível na visualização acima?
- Por que, então, precisão == 1,0, porque as imagens originais são 0 e 1.
Com a visualização, tudo é surpreendentemente simples. Para exibir as imagens, usei matplotlib: plt.imshow(res_imgs[i][:, :, 0]) . E, como de costume, se você for para a documentação, tudo será escrito lá: The Normalize instance used to scale scalar data to the [0, 1] range before mapping to colors using cmap. By default, a linear scaling mapping the lowest value to 0 and the highest to 1 is used. The Normalize instance used to scale scalar data to the [0, 1] range before mapping to colors using cmap. By default, a linear scaling mapping the lowest value to 0 and the highest to 1 is used. I.e. a biblioteca normalizou cuidadosamente meus 0,5 e 0,73 no intervalo de 0 a 1. Altere o código:
plt.imshow(res_imgs[i][:, :, 0], norm=matplotlib.colors.Normalize(0.0, 1.0))

E aqui está a pergunta com precisão. Para começar, por hábito, vamos à documentação, leia tf.keras.metrics.Accuracy e parece que eles escrevem compreensível:
For example, if y_true is [1, 2, 3, 4] and y_pred is [0, 2, 3, 4] then the accuracy is 3/4 or .75.
Mas, nesse caso, nossa precisão deveria ter sido 0. Eu, como resultado, me enterrei na fonte e é bastante claro para mim:
When you pass the strings 'accuracy' or 'acc', we convert this to one of `tf.keras.metrics.BinaryAccuracy`, `tf.keras.metrics.CategoricalAccuracy`, `tf.keras.metrics.SparseCategoricalAccuracy` based on the loss function used and the model output shape. We do a similar conversion for the strings 'crossentropy' and 'ce' as well.
Além disso, na documentação do site, por algum motivo, este parágrafo não está na descrição de .compile .
Aqui está um pedaço de código de https://github.com/tensorflow/tensorflow/blob/66c48046f169f3565d12e5fea263f6d731f9bfd2/tensorflow/python/keras/engine/compile_utils.py
y_t_rank = len(y_t.shape.as_list()) y_p_rank = len(y_p.shape.as_list()) y_t_last_dim = y_t.shape.as_list()[-1] y_p_last_dim = y_p.shape.as_list()[-1] is_binary = y_p_last_dim == 1 is_sparse_categorical = ( y_t_rank < y_p_rank or y_t_last_dim == 1 and y_p_last_dim > 1) if metric in ['accuracy', 'acc']: if is_binary: metric_obj = metrics_mod.binary_accuracy elif is_sparse_categorical: metric_obj = metrics_mod.sparse_categorical_accuracy else: metric_obj = metrics_mod.categorical_accuracy
y_t é y_true, ou a saída esperada, y_p é y_predicted, ou o resultado previsto.
Temos o formato de dados: shape=(64,64,1) , portanto, a precisão é considerada como precisão binária. Interesse em prol de como é considerado:
def binary_accuracy(y_true, y_pred, threshold=0.5): threshold = math_ops.cast(threshold, y_pred.dtype) y_pred = math_ops.cast(y_pred > threshold, y_pred.dtype) return K.mean(math_ops.equal(y_true, y_pred), axis=-1)
É engraçado que aqui tenhamos sorte - por padrão, tudo é considerado uma unidade com mais de 0,5 e 0,5 e menos - zero. Portanto, a precisão sai cem por cento para o nosso modelo de identidade, embora, na verdade, os números não sejam iguais. Bem, está claro que, se realmente queremos, podemos corrigir o limiar e reduzir a precisão a zero, por exemplo, apenas isso não é realmente necessário. Essa é uma métrica, não afeta o treinamento, você só precisa entender que pode calculá-la de mil maneiras diferentes e obter indicadores completamente diferentes. Apenas como exemplo, você pode extrair várias métricas com canetas e transferir nossos dados para elas:
m = tf.keras.metrics.BinaryAccuracy() m.update_state(x_batch, res_imgs) print(m.result().numpy())
Nos dará 1.0 .
E aqui
m = tf.keras.metrics.Accuracy() m.update_state(x_batch, res_imgs) print(m.result().numpy())
Nos dará 0.0 nos mesmos dados.
A propósito, o mesmo trecho de código pode ser usado para brincar com funções de perda e entender como elas funcionam. Se você ler os tutoriais sobre codificadores automáticos, basicamente eles sugerem o uso de uma das duas funções de perda: erro quadrado médio ou 'binary_crossentropy'. Você também pode vê-los ao mesmo tempo.
Lembro que para mse já dei modelos de evaluate :
8/Unknown - 2s 221ms/step - loss: 0.2488 - accuracy: 1.0000[0.24876083992421627, 1.0]
I.e. perda == 0,2488. Vamos ver porque é isso. Parece-me pessoalmente que é o mais simples e mais compreensível: a diferença entre y_true e y_predict é subtraída pixel por pixel, cada resultado é elevado ao quadrado e, em seguida, a média é pesquisada.
tf.keras.backend.mean(tf.math.squared_difference(x_batch[0], res_imgs[0]))
E na saída:
<tf.Tensor: shape=(), dtype=float32, numpy=0.24826494>
Aqui a intuição é muito simples - a maioria dos pixels vazios, o modelo produz 0,5, obtém 0,25 - diferença ao quadrado para eles.
Com a crossenttrtopy binária, as coisas são um pouco mais complicadas, e há artigos completos sobre como isso funciona, mas pessoalmente sempre foi mais fácil para mim ler as fontes, e parece algo assim:
if from_logits: return nn.sigmoid_cross_entropy_with_logits(labels=target, logits=output) if not isinstance(output, (ops.EagerTensor, variables_module.Variable)): output = _backtrack_identity(output) if output.op.type == 'Sigmoid':
Para ser sincero, trabalhei muito nessas poucas linhas de código por muito tempo. Primeiro, fica imediatamente claro que duas implementações podem funcionar: sigmoid_cross_entropy_with_logits será chamado ou o último par de linhas funcionará. A diferença é que sigmoid_cross_entropy_with_logits trabalha com logits (como o nome indica, doh) e o código principal trabalha com probabilidades.
Quem são os logits? Se você ler um milhão de artigos diferentes sobre o assunto, eles mencionarão definições matemáticas, fórmulas, outra coisa. Na prática, tudo parece surpreendentemente simples (me corrija se estiver errado). A saída bruta da previsão é de logits. Bem, ou log-odds, as probabilidades logarítmicas que são medidas no logistic un its - papagaios logísticos.
Há uma pequena digressão - por que existem logaritmosAs probabilidades são a proporção do número de eventos que precisamos para o número de eventos que não precisamos (em contraste com a probabilidade, que é a proporção dos eventos que precisamos para o número de todos os eventos em geral). Por exemplo - o número de vitórias de nossa equipe e o número de suas derrotas. E há um problema. Continuando o exemplo com as vitórias das equipes, nossa equipe pode perder no meio e ter a chance de vencer 1/2 (um a dois), e talvez extremamente perdedor - e ter a chance de ganhar 1/100. E na direção oposta - íngreme médio e 2/1, mais íngreme que as montanhas mais altas - e depois 100/1. E acontece que toda a gama de equipes perdedoras é descrita por números de 0 a 1 e equipes legais - de 1 ao infinito. Como resultado, é inconveniente comparar, não há simetria, trabalhar com isso em geral é inconveniente para todos, a matemática é feia. E se você tomar o logaritmo das probabilidades, tudo se tornará simétrico:
ln(1/2) == -0.69 ln(2/1) == 0.69 ln(1/100) == -4.6 ln(100/1) == 4.6
No caso do tensorflow, isso é bastante arbitrário, porque, estritamente falando, a saída da camada não é matematicamente sem log-odds, mas já é aceita. Se o valor bruto for de -∞ a + ∞ -, o logit Então eles podem ser convertidos em probabilidades. Existem duas opções para isso: softmax e seu caso especial, sigmóide. Softmax - Pegue um vetor de logits e converta-os em um vetor de probabilidades, e mesmo assim a soma da probabilidade de todos os eventos contenha 1. Sigmoid (no caso de tf) também aceita um vetor de logits, mas converte cada um deles em probabilidades separadamente, independentemente do resto.
Você pode olhar dessa maneira. Existem tarefas de classificação de vários rótulos, há tarefas de classificação de vários tipos. Multiclasse - isto é, se você precisar determinar as maçãs na imagem ou as laranjas e talvez até os abacaxis. E o rótulo múltiplo é quando pode haver um vaso de frutas na foto e você precisa dizer que ele tem maçãs e laranjas, mas não há abacaxi. Se queremos multiclasse - precisamos de softmax, se queremos multilabel - precisamos de sigmóide.
Aqui temos o caso de multilabel - é necessário que cada pixel individual (classe) diga se está instalado.
Voltando ao fluxo tensor e por que na entropia cruzada binária (pelo menos em outras funções de entropia cruzada é a mesma coisa), existem dois ramos globais. A crossentropy sempre funciona com probabilidades, falaremos sobre isso um pouco mais tarde. Depois, há simplesmente duas maneiras: as probabilidades já entram na entrada ou os logits chegam à entrada - e depois o sigmoide é aplicado primeiro a elas para obter a probabilidade. Aconteceu que a aplicação de entropia cruzada sigmóide e de cálculo acabou sendo melhor do que apenas calcular entropia cruzada a partir de probabilidades (a saída matemática das razões está na fonte da função sigmoid_cross_entropy_with_logits , além dos curiosos, é possível pesquisar no Google 'estabilidade numérica entropia cruzada'), portanto, mesmo os desenvolvedores do fluxo tensorial recomendam não passar a probabilidade para insira funções de crossentropy e retorne logits brutos. Bem, no código, as funções de perda são verificadas se a última camada é sigmóide, então elas a cortam e recebem a entrada de ativação, em vez de sua saída, para calcular, enviando tudo a ser considerado em sigmoid_cross_entropy_with_logits .
Ok, resolvido, agora binary_crossentropy. Existem duas explicações "intuitivas" populares que medem a entropia cruzada.
Mais formal: imagine que existe um certo modelo que para n classes conhece a probabilidade de ocorrência (y 0 , y 1 , ..., y n ). E agora na vida, cada uma dessas classes surgiu k n vezes (k 1 , k 1 , ..., k n ). A probabilidade de tal evento é o produto da probabilidade para cada classe individual - (y 1 ^ k 1 ) (y 2 ^ k 2 ) ... (y n ^ k n ). Em princípio - essa já é uma definição normal de entropia cruzada - a probabilidade de um conjunto de dados é expressa em termos da probabilidade de outro conjunto de dados. O problema com essa definição é que ela passará de 0 a 1 e geralmente será muito pequena; não é conveniente comparar esses valores.
Se tirarmos o logaritmo disso, k 1 log (y 1 ) + k 2 log (y 2 ) sairá e assim por diante. O intervalo de valores passa de -∞ a 0. Multiplique tudo isso por -1 / n - e o intervalo de 0 a + ∞ sai, além disso, porque é expressa como a soma dos valores para cada classe, a mudança em cada classe é refletida no valor geral de uma maneira muito previsível.
Mais simples: a entropia cruzada mostra quantos bits extras são necessários para expressar a amostra em termos do modelo original. Se estivéssemos lá para fazer um logaritmo com base 2, então iríamos diretamente para os bits. Usamos logaritmos naturais em todos os lugares, para que eles mostrem o número de nat ( https://en.wikipedia.org/wiki/Nat_(unit )), não bits.
A entropia cruzada binária, por sua vez, é um caso especial de entropia cruzada comum quando o número de classes é duas. Então, temos conhecimento suficiente da probabilidade de ocorrência de uma classe - y 1 , e a probabilidade de ocorrência da segunda será (1-y 1 ).
Mas, me parece, um pouco derrapou em mim. Deixe-me lembrá-lo, da última vez que tentamos criar um codificador automático de identidade, ele nos mostrou uma imagem bonita e até precisão de 1,0, mas, na verdade, os números foram horríveis. Para o experimento, você pode realizar mais alguns testes:
1) a ativação pode ser totalmente removida, haverá uma identidade limpa
2) você pode tentar outras funções de ativação, por exemplo, o mesmo
Sem ativação:
model = tf.keras.Sequential() model.add(tf.keras.Input(shape=(64,64,1))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(64*64, use_bias=False, kernel_initializer=tf.keras.initializers.Identity())) model.add(tf.keras.layers.Reshape(target_shape=(64,64,1)))
Temos o modelo de identidade perfeito:
model.evaluate(x=val.map(lambda x: (x,x)).batch(BATCH_SIZE, drop_remainder=True))
O treinamento, a propósito, não levará a nada, porque a perda == 0,0.
Agora com relu. O gráfico dele fica assim:
import matplotlib.ticker as plticker range_tensor = tf.range(-4, 4, 0.01, dtype=tf.float32) fig, ax = plt.subplots(1,1) plt.plot(range_tensor.numpy(), tf.keras.activations.relu(range_tensor).numpy()) ax.grid(which='major', linestyle='-', linewidth='0.5', color='red') ax.grid(which='minor', linestyle=':', linewidth='0.5', color='black') ax.yaxis.set_major_locator(plticker.MultipleLocator(base=1) ) plt.minorticks_on()
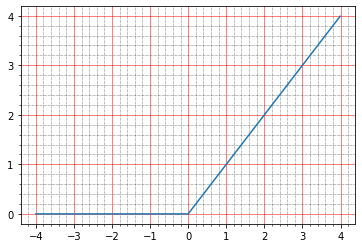
Abaixo de zero - zero, acima - y = x, ou seja, em teoria, devemos obter o mesmo efeito que na ausência de ativação - um modelo ideal.
model = tf.keras.Sequential() model.add(tf.keras.Input(shape=(64,64,1))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(64*64, activation='relu', use_bias=False, kernel_initializer=tf.keras.initializers.Identity())) model.add(tf.keras.layers.Reshape(target_shape=(64,64,1))) model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["accuracy"]) model.evaluate(x=val.map(lambda x: (x,x)).batch(BATCH_SIZE, drop_remainder=True))
Certo, descobrimos o modelo de identidade, mesmo com alguma parte da teoria que ficou mais clara. Agora vamos tentar treinar o mesmo modelo para que ele se torne identidade.
Por diversão, conduzirei esse experimento em três funções de ativação. Para começar - relu, porque ele se mostrou bem mais cedo (tudo está como antes, mas o kernel_initializer é removido, então, por padrão, será glorot_uniform ):
model = tf.keras.Sequential() model.add(tf.keras.Input(shape=(64,64,1))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(64*64, activation='relu', use_bias=False)) model.add(tf.keras.layers.Reshape(target_shape=(64,64,1)))
Aprende maravilhosamente:
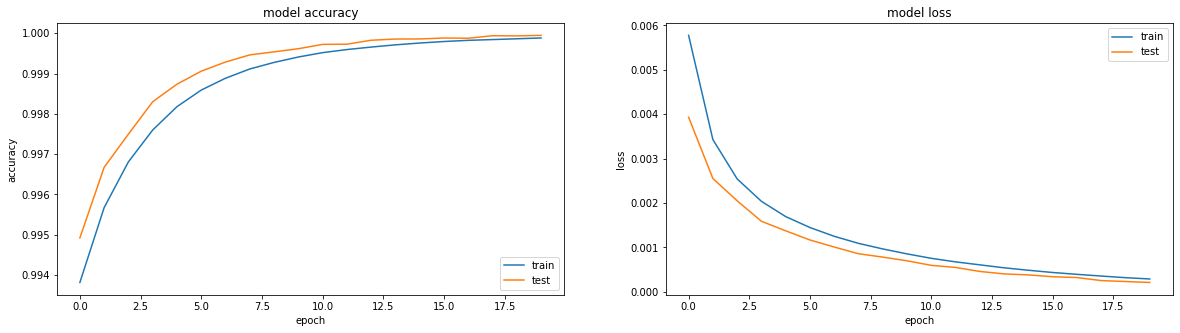
O resultado foi muito bom, precisão: 0,9999, perda (mse): 2e-04 após 20 eras e você pode treinar mais.

Em seguida, tente com sigmoide:
model = tf.keras.Sequential() model.add(tf.keras.Input(shape=(64,64,1))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(64*64, activation='sigmoid', use_bias=False)) model.add(tf.keras.layers.Reshape(target_shape=(64,64,1)))
Eu já ensinei algo semelhante antes, com a única diferença é que o viés é desativado aqui. Ele estuda minuciosamente, fica em um platô na região da era 50, precisão: 0,9970, perda: 0,01 após 60 épocas.
O resultado novamente não é impressionante:
Bem, verifique também tanh:
model = tf.keras.Sequential() model.add(tf.keras.Input(shape=(64,64,1))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(64*64, activation='tanh', use_bias=False)) model.add(tf.keras.layers.Reshape(target_shape=(64,64,1)))
O resultado é comparável ao relu - precisão: 0,9999, perda: 6e-04 após 20 eras e você pode treinar ainda mais:
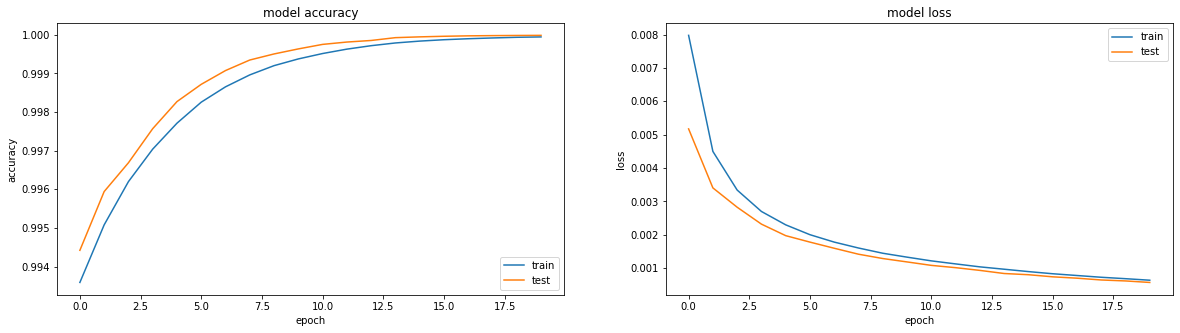

De fato, estou atormentado com a questão de saber se algo pode ser feito para fazer com que o sigmoide mostre um resultado comparável. Exclusivamente por interesse esportivo.
Por exemplo, você pode tentar adicionar BatchNormalization:
model = tf.keras.Sequential() model.add(tf.keras.Input(shape=(64,64,1))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(64*64, activation='sigmoid', use_bias=False)) model.add(tf.keras.layers.BatchNormalization()) model.add(tf.keras.layers.Reshape(target_shape=(64,64,1)))
E então algum tipo de mágica acontece. Na 13ª era, precisão: 1.0. E os resultados ardentes:
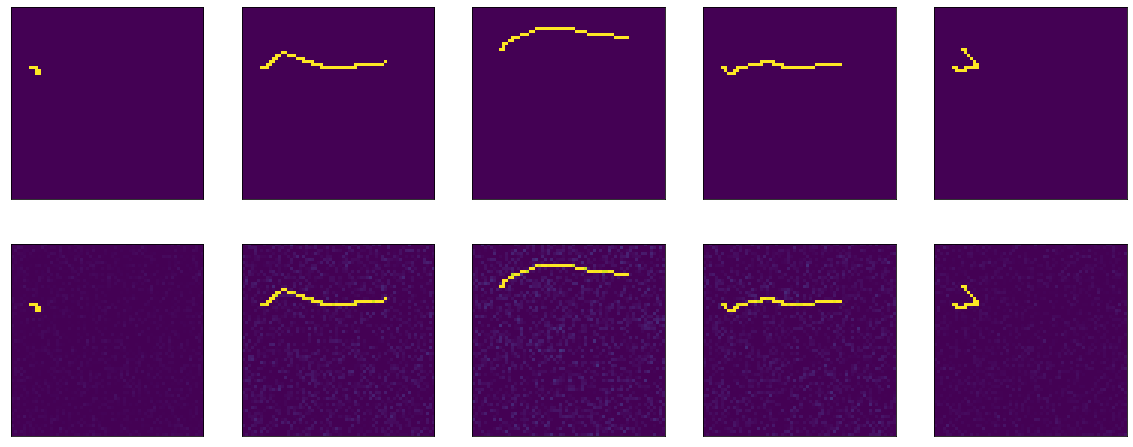
Iiiii ... neste cabide, terminarei a primeira parte, pois o texto já é muito engraçado, e não está claro se alguém precisa ou não. Na segunda parte, vou entender o que aconteceu com a mágica, experimentar diferentes otimizadores, tentar construir um codificador-decodificador honesto, bater a cabeça na mesa. Espero que alguém esteja interessado e útil.