Durante muito tempo, escrevi um artigo sobre numba e sobre como comparar sua velocidade com si. Artigo de Haskell “ Mais rápido que C ++; mais lento que o PHP "acionado. Nos comentários deste artigo, eles mencionaram a biblioteca numba e ela pode aproximar magicamente a velocidade de execução do código em python à velocidade em s. Neste artigo, após uma breve revisão sobre numba (parte 1), uma análise um pouco mais detalhada dessa situação ( parte 2 ).

A principal desvantagem de um python é considerada a sua velocidade. O overclock de python com sucesso variado começou quase desde os primeiros dias de sua existência: pele de vaca , psico , superficial sem carga , periquito , theano , nuitka , pythran , cython , pypy , numba .
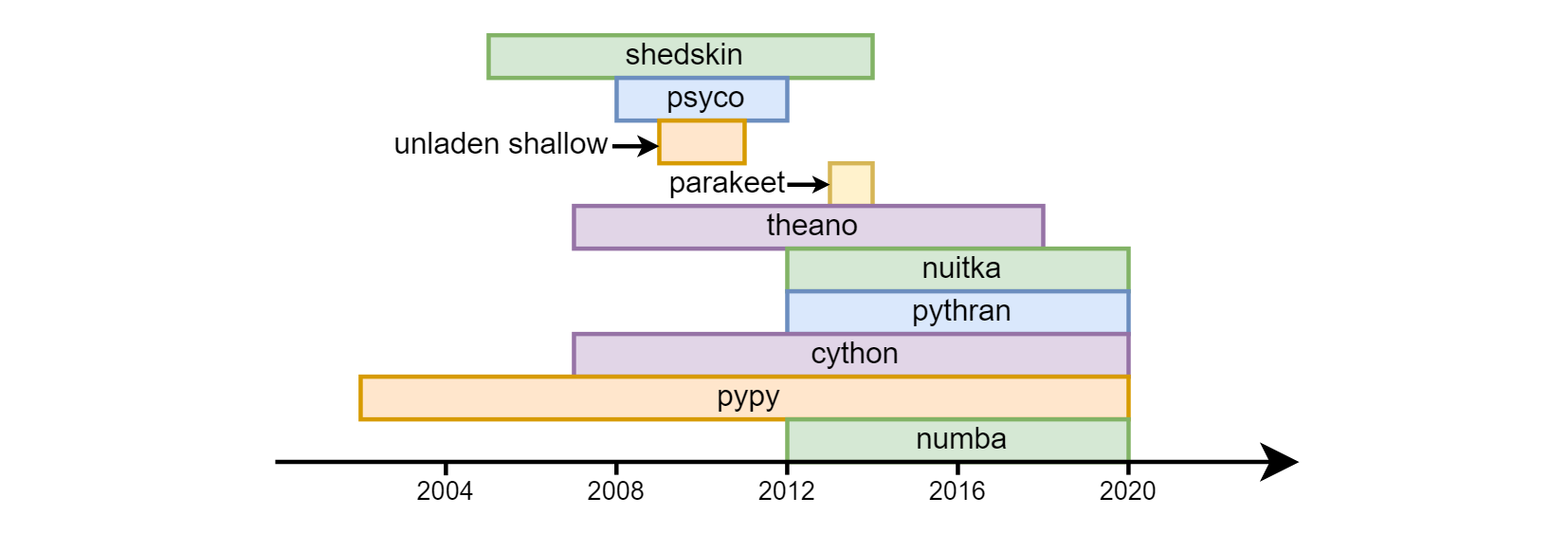
Até o momento, os três últimos são mais procurados. Cython (não deve ser confundido com cpython) - é bastante diferente semanticamente do python comum. De fato, essa é uma linguagem separada - um híbrido de C e python. Quanto ao pypy (uma implementação alternativa do tradutor python usando compilação jit) e numba (uma biblioteca para compilação de código no llvm), eles foram de diferentes maneiras. pypy declarou inicialmente o suporte para todas as construções do python. Em numba, eles procederam do fato de que geralmente requer cálculos matemáticos da CPU, respectivamente, identificaram a parte da linguagem associada aos cálculos e começaram a fazer overclock, aumentando gradualmente a "cobertura" (por exemplo, até recentemente não havia suporte de linha , agora ela apareceu). Consequentemente, nem todo o programa está com overclock no numba , mas funções separadas , isso permite combinar alta velocidade e compatibilidade com versões anteriores com bibliotecas que o numba (ainda) não suporta. O Numpy é suportado (com restrições menores) em pypy e numba .
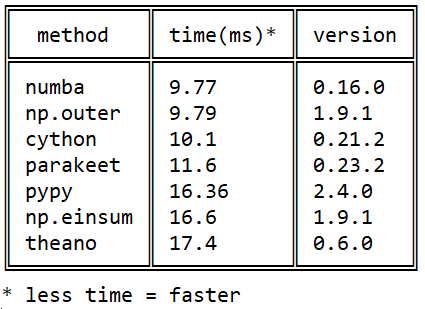 Meu conhecimento com o Numba começou em 2015 com esta pergunta sobre stackoverflow sobre a velocidade de multiplicação de matrizes em python: Produto externo eficiente em python
Meu conhecimento com o Numba começou em 2015 com esta pergunta sobre stackoverflow sobre a velocidade de multiplicação de matrizes em python: Produto externo eficiente em python
Desde então, muitos eventos ocorreram em cada uma das bibliotecas, mas a imagem em relação ao numba / cython / pypy não mudou numba : o numba supera o cython usando instruções do processador nativo (o cython não pode jit) e o pypy devido à execução mais eficiente do bytecode do llvm .
O Numba é útil para mim no trabalho (processamento de imagens hiperespectrais) e no ensino (integração numérica, solução de equações diferenciais).
como definir
Há alguns anos, houve problemas com a instalação, agora tudo foi resolvido: ele é instalado igualmente bem através do pip install numba e do conda install numba . O llvm é apertado e instalado automaticamente.
como acelerar
Para acelerar uma função, você deve inserir o decorador njit antes de defini-la:
from numba import njit @njit def f(n): s = 0. for i in range(n): s += sqrt(i) return s
Aceleração de 40 vezes.
A raiz é necessária, porque caso contrário o numba reconhecerá a soma da progressão aritmética (!) E a calculará em tempo constante.
jit vs njit
Anteriormente, apenas o modo @jit (não @njit ) era relevante. O ponto é que, nesse modo, você pode usar operações não suportadas pelo numba: o numba em alta velocidade atinge a primeira operação desse tipo, depois diminui a velocidade e até o final da execução da função continuar na velocidade usual do Python, mesmo que nada mais "proibido" seja encontrado na função ( o chamado modo de objeto), que é obviamente irracional. Agora que @jit abandonando gradualmente o @jit , é sempre recomendável usar o @njit (ou em sua forma completa @jit(nopython=True) ): nesse modo, o numba jura com exceções nesses locais - é melhor reescrevê-los para não perder velocidade.
o que pode acelerar
Nas funções com overclock, apenas parte da funcionalidade python e numba pode ser usada. Todos os operadores, funções e classes são divididos em duas partes em relação ao numba: aqueles que o numba "entende" e aqueles que "não entendem".
Existem duas listas na documentação do numba (com exemplos):
- um subconjunto da funcionalidade python familiar para numerbe e
- um subconjunto do numpy funcional familiar ao numbe.
Do notável nestas listas:
- numba "entende" listas de Python com acréscimos rápidos (amortizados O (1)) ao final que numpy "não entende" (embora apenas homogêneos de elementos do mesmo tipo),
- matrizes de numpy que não estão no python base. Compreende também
- tuplas: elas podem, como um python comum, conter elementos de tipos diferentes.
- dicionários: numba possui sua própria implementação de um dicionário digitado. Todas as chaves devem ser do mesmo tipo, exatamente como os valores. O dict python não pode ser passado para numba, mas o numba
numba.typed.Dict pode ser criado em python e transferido para / de numba (enquanto em python ele funciona um pouco mais devagar que python). - recentemente str e bytes, no entanto, apenas como parâmetros de entrada não podem ser criados (ainda?).
Ela não entende nenhuma outra biblioteca (em particular, scipy e pandas).
Mas mesmo esse subconjunto da linguagem que ela entende é suficiente para fazer o overclock da maior parte do código para aplicativos científicos nos quais o numba é focado principalmente.
importante!
Das funções com overclock, somente as funções com overclock e não com overclock podem ser chamadas.
(embora as funções com overclock possam ser chamadas de overclock e não com overclock).
globais
Nas funções com overclock, as variáveis globais se tornam constantes: seu valor é fixo no momento em que a função é compilada ( exemplo ). => Não use variáveis globais em funções com overclock (exceto constantes).
assinaturas
No número de cada função, um ou vários tipos de argumentos de entrada e saída são mapeados, ou seja, assinaturas. Quando a função é chamada pela primeira vez, a assinatura é gerada e o código da função binária correspondente é compilado automaticamente. Quando iniciadas com outros tipos de argumentos, novas assinaturas e novos binários serão criados (os antigos são preservados). Assim, ocorre "sair para o modo" em termos de velocidade de execução para cada assinatura, iniciando na segunda execução com esses tipos de argumentos. Então também
- "Aquecer o cache" iniciando com pequenos tamanhos de matrizes de entrada ou
- especifique o argumento
@jit(cache=True) para salvar o código compilado em disco com seu carregamento automático durante os lançamentos subseqüentes do programa (embora na prática hoje este primeiro lançamento ainda seja um pouco mais lento que os subsequentes, mas mais rápido que sem cache=True ) .
Existe uma terceira via. As assinaturas podem ser definidas manualmente:
from numba import int16, int32 @njit(int32(int16, int16)) def f(x, y): return x + y >>> f.signatures [(int16, int16)]
Quando você executa uma função com a assinatura especificada no decorador, a primeira execução é rápida: a compilação ocorrerá no momento em que o python visualizar a definição da função e não no primeiro início. Pode haver várias assinaturas, a ordem da sequência é importante.
Aviso: este último método não é seguro para o futuro. Os autores da numba alertam que a sintaxe para especificar tipos pode mudar no futuro. @jit / @njit sem assinaturas é uma opção mais segura nesse sentido.
f.signatures começam a mostrar assinaturas somente quando o python as descobre, ou seja, após a primeira chamada de função ou se elas são definidas manualmente.
Além de f.signatures assinaturas podem ser visualizadas através de f.inspect_types() - além dos tipos de parâmetros de entrada, esta função mostrará os tipos de parâmetros de saída, bem como os tipos de todas as variáveis locais.
Além dos tipos de parâmetros de entrada e saída, é possível especificar manualmente os tipos de variáveis locais:
from numba import int16, int32 @njit(int32(int16, int16), locals={'z': int32}) def f(x, y): z = y + 10 return x + z
int
No numba, os números inteiros não têm aritmética longa como no python "simples", mas existem tipos padrão de várias larguras, de int8 a int64 ( tabela de tipos na documentação). Também existem tipos int_ (assim como float_ ), com os quais você dá ao numba a oportunidade de escolher a largura do campo ideal (do ponto de vista dela).
aulas
Geralmente, há suporte para as aulas (@jitclass), mas até agora é experimental, por isso é melhor evitar usá-las por enquanto (no momento, na minha experiência, é muito mais lento com elas do que sem elas).
tipos personalizados
O Numba suporta uma certa alternativa às classes de matrizes numpy - estruturadas ou, em outras palavras, de tipos personalizados. Eles funcionam na mesma velocidade que matrizes numpy regulares, são um pouco mais convenientes para indexar (por exemplo, a['y2'] mais legível que a[3] ). Curiosamente, em numba, ao contrário de numpy, um a.y2 mais conciso a.y2 permitido junto com a sintaxe usual a['y2'] . Mas, em geral, seu apoio à numba deixa muito a desejar, e algumas operações, mesmo óbvias na numpy, com elas na numba são registradas de maneira não trivial.
GPU
É capaz de executar código com overclock na GPU e, ao contrário do mesmo, por exemplo, pycuda ou pytorch, não apenas na nvidia, mas também nas placas amd'shnyh. Com isso, até agora tenho pouco conhecimento. Aqui está um artigo sobre a Comparação Habre 2016 do desempenho dos cálculos de GPU em Python e C. Lá, foi obtida uma velocidade comparável a C.
compilação antecipada
Existe um modo de compilação ( documentação ) normal (ou seja, não apenas jit) na numba, mas esse modo não é o principal, eu não entendi.
paralelização automática
Algumas tarefas (por exemplo, multiplicar uma matriz por um número) são paraleladas naturalmente. Mas existem tarefas cuja implementação não pode ser paralelizada. Com o decorador @njit(parallel=True) numba analisa o código da função de overclock, encontra essas seções, cada uma das quais não pode ser paralelizada sozinha, e as executa simultaneamente em diferentes núcleos da CPU ( documentação ). Anteriormente, era possível paralelizar funções manualmente usando @vectorize ( documentação ), o que exigia alterações de código.
Na prática, fica assim: add parallel=True , meça a velocidade, se tivermos sorte e ela for mais rápida - nós a deixamos mais devagar - nós a removemos. (** Atualização Conforme observado no comentário da segunda parte do artigo, esse sinalizador possui muitos bugs abertos)
Liberação GIL
Funções decoradas com @jit(nogil=True) e executando em diferentes threads podem ser executadas em paralelo. Para evitar condições de corrida, você deve usar a sincronização de threads.
a documentação
Numbe ainda carece de documentação sensata. Ela é, mas nem tudo está nela.
otimização
Há alguma imprevisibilidade ao otimizar o código manualmente: o código não-tônico geralmente roda mais rápido que o pitão.
Para os interessados no tópico, posso recomendar um vídeo de uma aula de mestre numba da conferência scipy 2017 (existem códigos-fonte no github). É realmente longo e parcialmente desatualizado (por exemplo, seqüências de caracteres já são suportadas), mas ajuda a ter uma idéia geral: contém, em particular, sobre pitônico / não-sintético, jit (paralelo = True), etc.
Na segunda parte, consideraremos o uso de numba usando o código do artigo mencionado no início do artigo.