
Mais recentemente, falamos sobre como implantar aplicativos escritos no Tarantool Cartridge . Porém, como a operação não termina na implantação, hoje atualizaremos nosso aplicativo e entenderemos como gerenciar a topologia, o sharding e a autorização, além de alterar a configuração das funções.
Inquisidor, por favor, corte!
Onde paramos
A última vez que configuramos a seguinte topologia:
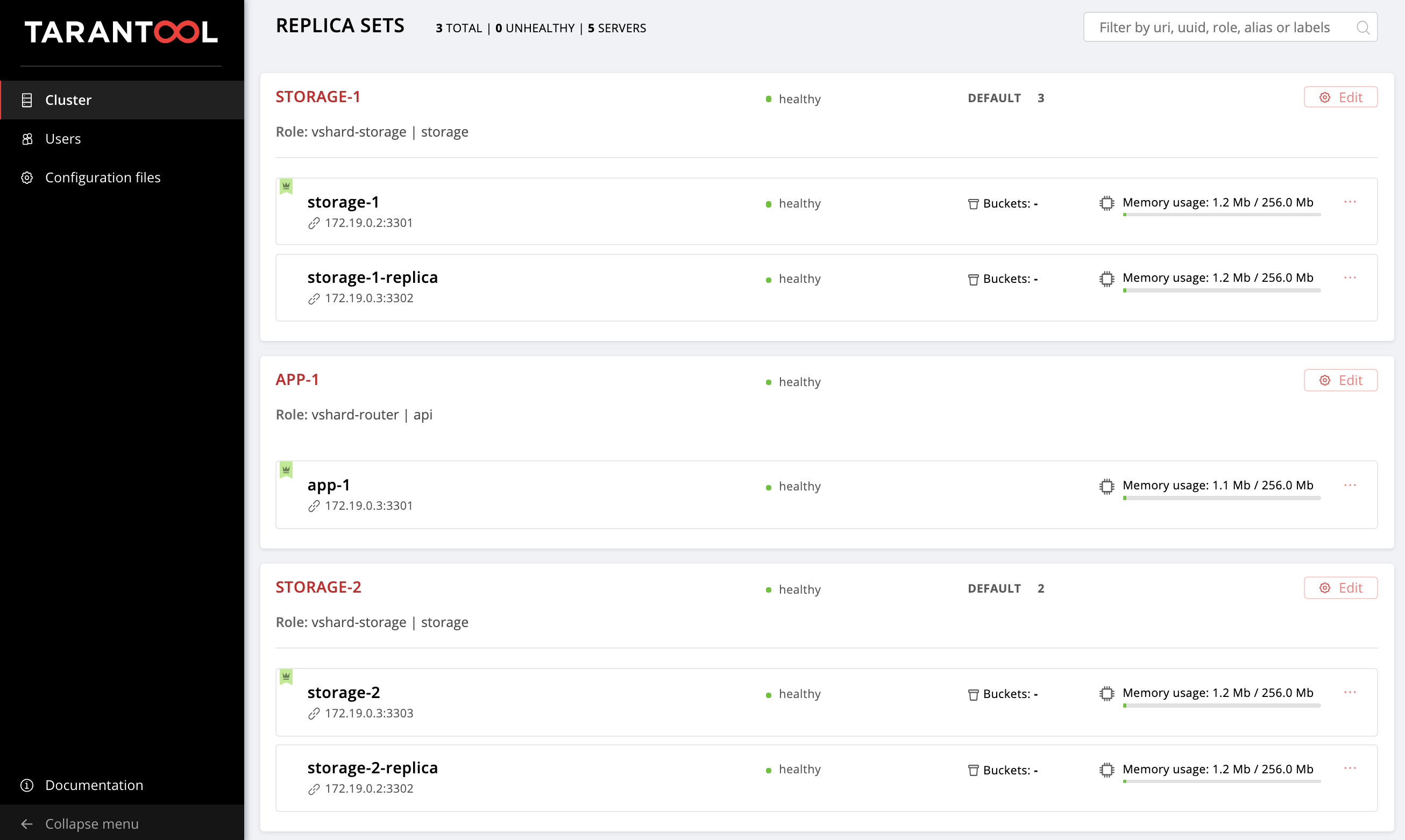
O repositório de exemplo conseguiu mudar um pouco, novos arquivos apareceram lá, getting-started-app-2.0.0-0.rpm e hosts.updated.2.yml . Você não precisa extrair a nova versão, basta fazer o download do pacote no link , e o hosts.updated.2.yml necessário apenas para que você possa espreitar lá em caso de dificuldades em alterar o inventário atual.
Se você concluiu todas as etapas da parte anterior deste tutorial, agora no hosts.yml hosts.yml há uma configuração de cluster com duas réplicas de storage (no repositório, este é hosts.updated.yml ).
Crie nossas máquinas virtuais:
$ vagrant up
Instale a nova versão do cartucho Tarantool de função Ansible (ele conseguiu mudar, é claro, para melhor):
$ ansible-galaxy install tarantool.cartridge,1.0.2
Portanto, a configuração atual do cluster:
--- all: vars: # common cluster variables cartridge_app_name: getting-started-app cartridge_package_path: ./getting-started-app-1.0.0-0.rpm # path to package cartridge_cluster_cookie: app-default-cookie # cluster cookie # common ssh options ansible_ssh_private_key_file: ~/.vagrant.d/insecure_private_key ansible_ssh_common_args: '-o IdentitiesOnly=yes -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no' # INSTANCES hosts: storage-1: config: advertise_uri: '172.19.0.2:3301' http_port: 8181 app-1: config: advertise_uri: '172.19.0.3:3301' http_port: 8182 storage-1-replica: config: advertise_uri: '172.19.0.3:3302' http_port: 8183 storage-2: config: advertise_uri: '172.19.0.3:3303' http_port: 8184 storage-2-replica: config: advertise_uri: '172.19.0.2:3302' http_port: 8185 children: # GROUP INSTANCES BY MACHINES host1: vars: # first machine connection options ansible_host: 172.19.0.2 ansible_user: vagrant hosts: # instances to be started on the first machine storage-1: storage-2-replica: host2: vars: # second machine connection options ansible_host: 172.19.0.3 ansible_user: vagrant hosts: # instances to be started on the second machine app-1: storage-1-replica: storage-2: # GROUP INSTANCES BY REPLICA SETS replicaset_app_1: vars: # replica set configuration replicaset_alias: app-1 failover_priority: - app-1 # leader roles: - 'api' hosts: # replica set instances app-1: replicaset_storage_1: vars: # replica set configuration replicaset_alias: storage-1 weight: 3 failover_priority: - storage-1 # leader - storage-1-replica roles: - 'storage' hosts: # replica set instances storage-1: storage-1-replica: replicaset_storage_2: vars: # replicaset configuration replicaset_alias: storage-2 weight: 2 failover_priority: - storage-2 - storage-2-replica roles: - 'storage' hosts: # replicaset instances storage-2: storage-2-replica:
Vá para http: // localhost: 8181 / admin / cluster / dashboard e verifique se o cluster está no estado correto.
Tudo é o mesmo da última vez: mudaremos gradualmente esse arquivo e observaremos como o cluster muda. Você sempre pode olhar para a versão final em hosts.updated.2.yml
Então aqui vamos nós!
Atualizando o aplicativo
Para começar, vamos atualizar nosso aplicativo. Verifique se você possui o arquivo getting-started-app-2.0.0-0.rpm no diretório atual (caso contrário, faça o download do repositório).
Especifique o caminho para a nova versão do pacote:
--- all: vars: cartridge_app_name: getting-started-app cartridge_package_path: ./getting-started-app-2.0.0-0.rpm # <== cartridge_enable_tarantool_repo: false # <==
Especificamos cartridge_enable_tarantool_repo: false para que a função não conecte o repositório ao pacote Tarantool, que já instalamos na última vez. Isso irá acelerar um pouco o processo de implantação, mas não é absolutamente necessário.
Inicie o manual com a tag de cartridge-instances :
$ ansible-playbook -i hosts.yml playbook.yml \ --tags cartridge-instances
E verificamos se o pacote foi atualizado:
$ vagrant ssh vm1 [vagrant@svm1 ~]$ sudo yum list installed | grep getting-started-app
Verifique se a versão se tornou 2.0.0 :
getting-started-app.x86_64 2.0.0-0 installed
Agora você pode experimentar com segurança a nova versão do aplicativo.
Ativar sharding
Vamos ativar o sharding para que possamos assumir o controle das réplicas de storage posteriormente. Isso é feito de maneira muito simples. Inclua a variável cartridge_bootstrap_vshard seção all.vars :
--- all: vars: ... cartridge_cluster_cookie: app-default-cookie # cluster cookie cartridge_bootstrap_vshard: true # <== ... hosts: ... children: ...
Lançamos:
$ ansible-playbook -i hosts.yml playbook.yml \ --tags cartridge-config
Observe que especificamos a etiqueta de cartridge-config do cartridge-config para executar apenas tarefas envolvidas na configuração do cluster.
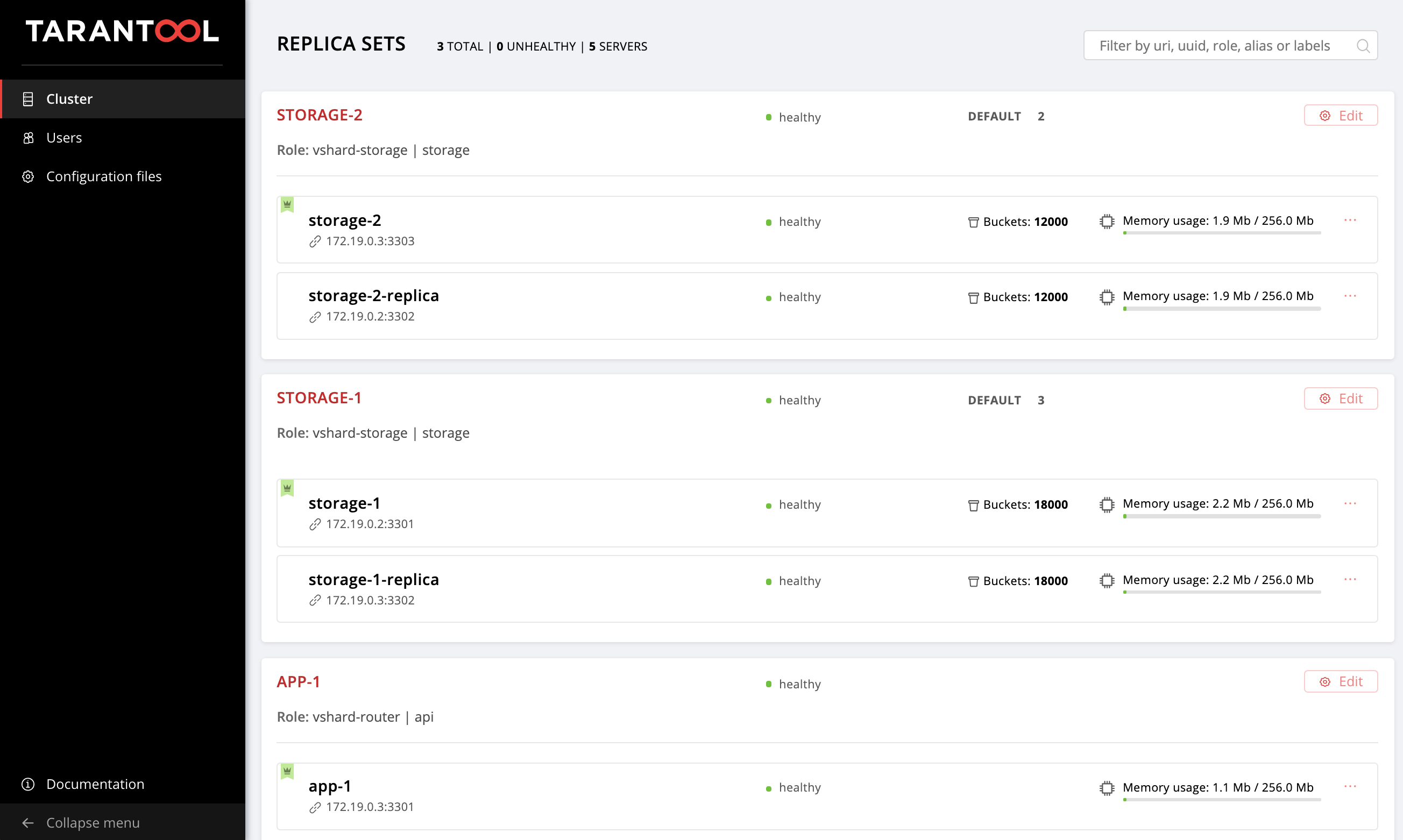
Abra a interface do usuário da Web http: // localhost: 8181 / admin / cluster / dashboard e verifique se nossos buckets são distribuídos pelos conjuntos de réplicas de armazenamento na proporção 2:3 (nós especificamos esses pesos para nossos conjuntos de réplicas, lembra?):
Ativar failover automático
E agora vamos ativar o modo de failover automático para que possamos descobrir o que é e como funciona um pouco mais tarde.
Adicione o sinalizador cartridge_failover à configuração:
--- all: vars: ... cartridge_cluster_cookie: app-default-cookie # cluster cookie cartridge_bootstrap_vshard: true cartridge_failover: true # <== ... hosts: ... children: ...
Novamente, iniciamos as tarefas de gerenciamento de cluster:
$ ansible-playbook -i hosts.yml playbook.yml \ --tags cartridge-config
Depois de concluir com êxito o manual, você pode acessar a interface da Web da Web e verificar se a opção Failover no canto superior direito está ativada. Para desativar o modo de failover automático, basta alterar o valor de cartridge_failover para false e executar o manual novamente.
É hora de descobrir que tipo de regime é esse e por que o ativamos.
Lidamos com failover
Você provavelmente notou a variável failover_priority que especificamos para cada replicaset. Vamos ver o que é.
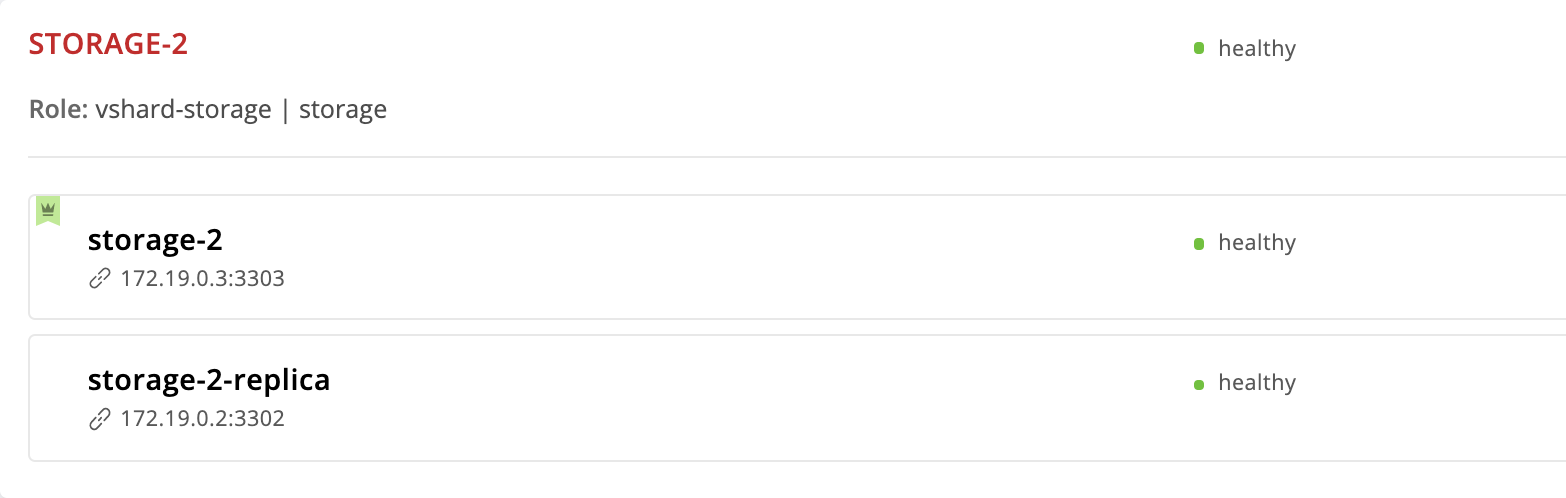
O cartucho Tarantool fornece um modo de failover automático. Cada replicaset possui um líder - a instância na qual está sendo gravada. Se algo acontecer com o líder, uma das observações assumirá seu papel. Qual? Vamos dar uma olhada no conjunto de réplicas de storage-2 :
--- all: ... children: ... replicaset_storage_2: vars: ... failover_priority: - storage-2 - storage-2-replica
A instância storage-2 que especificamos primeiro em failover_priority . Na interface da Web, ele aparece primeiro na lista de instâncias de replicaset e é marcado com uma coroa verde. Este é o líder - a primeira instância especificada em failover_priority :
Agora vamos ver o que acontece se algo acontecer com o líder do replicaset. Entramos na máquina virtual e paramos a instância do storage-2 :
$ vagrant ssh vm2 [vagrant@vm2 ~]$ sudo systemctl stop getting-started-app@storage-2
De volta à interface da Web:

A coroa na instância de storage-2 ficou vermelha - isso significa que o líder designado não é íntegro. Mas storage-2-replica tem uma coroa verde - essa instância assumiu as responsabilidades de liderança até o storage-2 retornar ao serviço. Este é um failover automático em ação.
Vamos reviver o storage-2 :
$ vagrant ssh vm2 [vagrant@vm2 ~]$ sudo systemctl start getting-started-app@storage-2
Tudo voltou à estaca zero:
Vamos mudar a ordem das instâncias na prioridade do failover. storage-2-replica instância do storage-2-replica um líder e removeremos o storage-2 da lista em geral:
--- all: vars: ... hosts: ... children: ... replicaset_storage_2: vars: # replicaset configuration ... failover_priority: - storage-2-replica # <== ...
Execute cartridge-replicasets para instâncias do grupo replicaset_storage_2 :
$ ansible-playbook -i hosts.yml playbook.yml \ --limit replicaset_storage_2 \ --tags cartridge-replicasets
Vamos para http: // localhost: 8181 / admin / cluster / dashboard e vemos que o líder mudou:
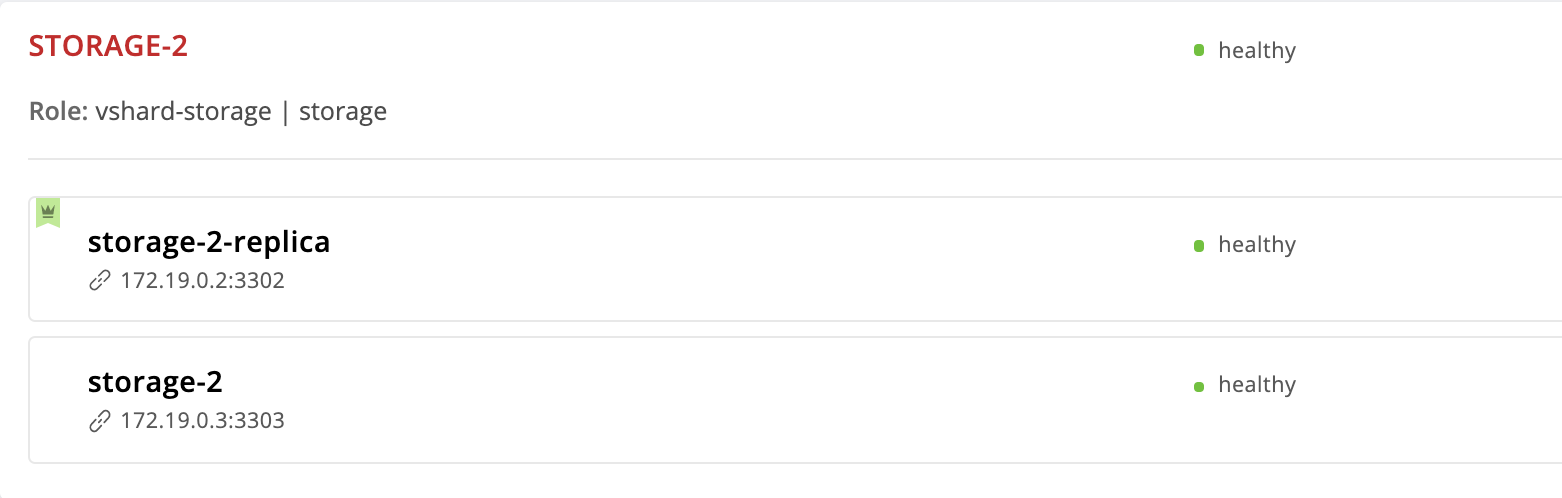
Mas removemos a instância storage-2 da configuração, por que ela ainda está aqui? O fato é que o Cartridge, recebendo um novo valor de failover_priority organiza as instâncias da seguinte maneira: a primeira instância da lista se torna a líder e as demais instâncias indicadas. Instâncias não mencionadas em failover_priority serão ordenadas pelo UUID e anexadas ao final.
Instância de exílio
Mas e se quisermos excluir a instância da topologia? Tudo é muito simples: você precisa passar a bandeira expelled . Vamos excluir a instância de storage-2-replica . Ele é o líder agora, então Cartridge não nos permitirá fazer isso. Mas não temos medo de dificuldades e ainda tentamos:
--- all: vars: ... hosts: storage-2-replica: config: advertise_uri: '172.19.0.2:3302' http_port: 8185 expelled: true # <== ...
Especificamos a cartridge-replicasets , pois expulsar uma instância é uma alteração na topologia:
$ ansible-playbook -i hosts.yml playbook.yml \ --limit replicaset_storage_2 \ --tags cartridge-replicasets
Execute o manual e veja o erro:

Como acabamos de ver, o Cartridge não justifica expulsar o atual líder do replicaset da topologia. Isso é bastante lógico, como a replicação é assíncrona, a exclusão de um líder provavelmente levará à perda de dados. Precisamos especificar outro líder e somente depois excluir a instância. A função primeiro aplicará a nova configuração do replicaset e depois lidará com a exceção. Portanto, alteramos failover_priority e executamos o manual novamente:
--- all: vars: ... hosts: ... children: ... replicaset_storage_2: vars: # replicaset configuration ... failover_priority: - storage-2 # <== ...
$ ansible-playbook -i hosts.yml playbook.yml \ --limit replicaset_storage_2 \ --tags cartridge-replicasets
Voila, a instância de storage-2-replica desapareceu da topologia!

Observe que o exílio da instância é realmente final e irrevogável. Após remover a instância da topologia, nossa função ansible interromperá o serviço systemd e excluirá todos os arquivos desta instância.

Se você mudar de idéia de repente e decidir que o replicaset de storage-2 ainda precisa de uma segunda instância, não poderá restaurá-lo. O cartucho lembra o UUID de todas as instâncias que deixaram a topologia e não permitirá que o exílio retorne. Você pode criar uma nova instância com o mesmo nome e configuração, mas obviamente ela terá um UUID diferente; portanto, o Cartucho permitirá a associação.
Removendo o Replicaset
Já descobrimos que não teremos permissão para expulsar o líder do replicaset. Mas e se quisermos remover permanentemente a réplica do storage-2 ? Existe, é claro, uma saída.
Para não perder dados, primeiro devemos transferir todos os buckets para o storage-1 , para isso definimos o peso do replicaet do storage-2 como 0 :
--- all: vars: ... hosts: ... children: ... replicaset_storage_2: vars: # replicaset configuration replicaset_alias: storage-2 weight: 0 # <== ... ...
Inicie o gerenciamento de topologia:
$ ansible-playbook -i hosts.yml playbook.yml \ --limit replicaset_storage_2 \ --tags cartridge-replicasets
Abra a interface do usuário da Web http: // localhost: 8181 / admin / cluster / dashboard e observe como todos os buckets fluem para o storage-1 :

Definimos o líder do storage-2 como o sinalizador expulso e nos despedimos deste replicaset:
--- all: vars: ... hosts: ... storage-2: config: advertise_uri: '172.19.0.3:3303' http_port: 8184 expelled: true # <== ...
$ ansible-playbook -i hosts.yml playbook.yml \ --tags cartridge-replicasets
Observe que desta vez não especificamos a opção de limit , pois pelo menos uma instância de todas para a qual lançamos o manual não deve ser marcada como expelled .
Então, retornamos à topologia original:
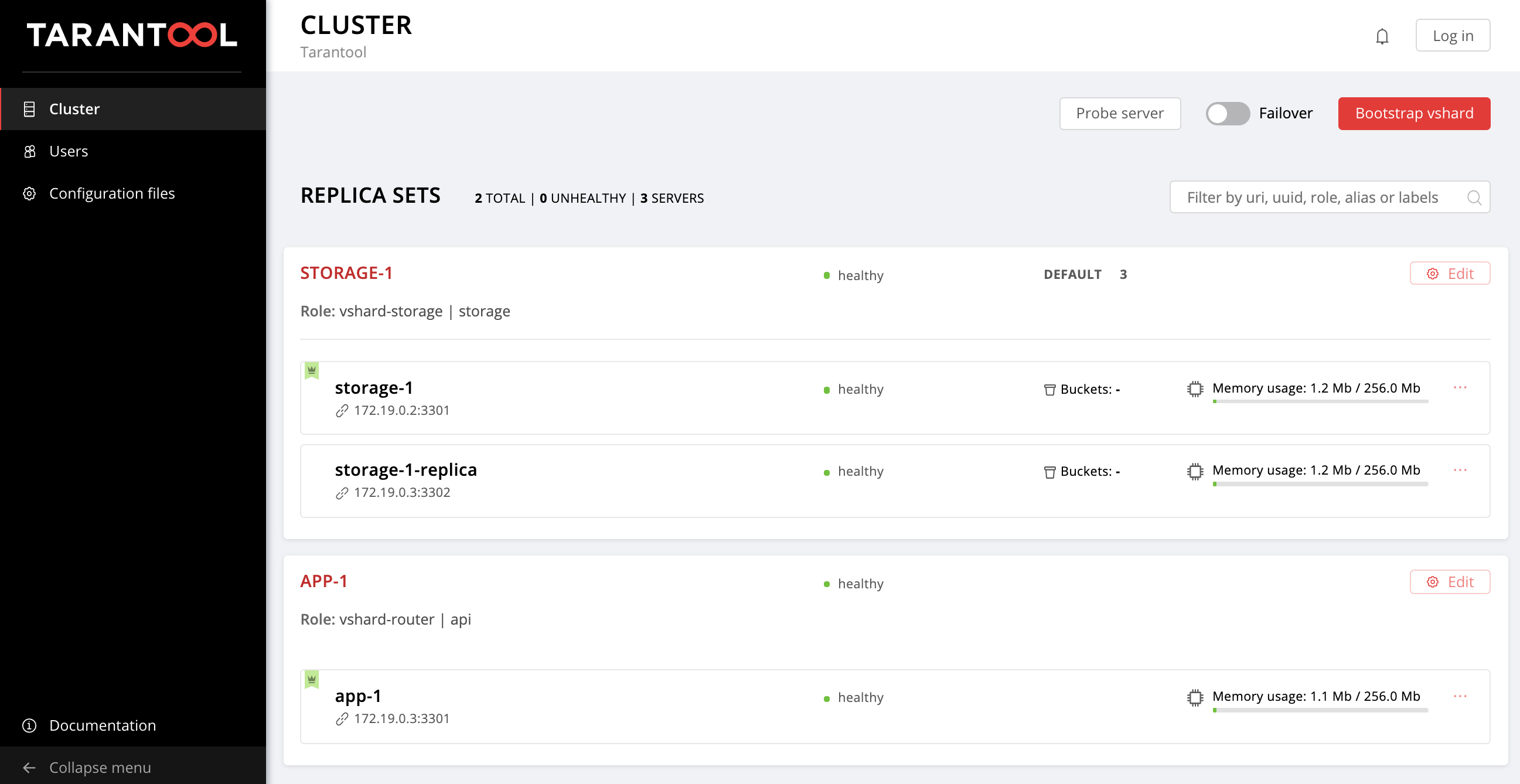
Entrar
Proponho me distrair do gerenciamento de conjuntos de réplicas e pensar em segurança. Agora, qualquer usuário não autorizado pode gerenciar o cluster por meio da interface da Web. Concordo, parece mais ou menos.
O cartucho oferece a capacidade de conectar seu próprio módulo de autorização, como LDAP (ou o que você tiver lá), e usá-lo para gerenciar usuários e seu acesso ao aplicativo. Mas usaremos o módulo de autorização interno, que o Cartucho usa por padrão. Este módulo permite executar operações básicas com os usuários (excluir, adicionar, editar) e implementa a função de verificação de senha.
Observe que nosso papel ansível requer o back-end de autorização para implementar todas essas funções.
Então, passamos da teoria para a prática. Primeiro, torne a autorização obrigatória, defina os parâmetros da sessão e adicione um novo usuário:
--- all: vars: ... # authorization cartridge_auth: # <== enabled: true # enable authorization cookie_max_age: 1000 cookie_renew_age: 100 users: # cartridge users to set up - username: dokshina password: cartridge-rullez fullname: Elizaveta Dokshina email: dokshina@example.com # deleted: true # uncomment to delete user ...
O gerenciamento da autorização é realizado como parte das tarefas de cartridge-config do cartridge-config esta tag:
$ ansible-playbook -i hosts.yml playbook.yml \ --tags cartridge-config
Em http: // localhost: 8181 / admin / cluster / dashboard, uma surpresa nos espera:
Você pode fazer login com o username e password nosso novo usuário ou como admin - o usuário padrão. Sua senha é cookie de cluster, nós especificamos esse valor na variável cartridge_cluster_cookie (este é o app-default-cookie , você não pode espiar).
Após um login bem-sucedido, abra a guia Users para garantir que tudo correu bem:

Experimente adicionar novos usuários e alterar suas configurações. Para excluir um usuário, especifique o sinalizador delete deleted: true para ele. Os valores de email e nome fullname não são usados pelo Cartucho, mas você pode especificá-los por conveniência.
Configuração da aplicação
Vamos lembrar como tudo começou.
Implementamos um pequeno aplicativo que armazena dados sobre clientes e suas contas bancárias. Como você se lembra, este aplicativo tem 2 funções: api e storage . A função de storage lida com armazenamento de dados e implementa sharding usando a vshard-storage . A segunda função, api , implementa um servidor HTTP com uma API para gerenciamento de dados e, dentro dela, está conectada outra função padrão, vshard-router , que controla o sharding.
Então, fazemos a primeira solicitação para a API do aplicativo. Adicione um novo cliente:
$ curl -X POST -H "Content-Type: application/json" \ -d '{"customer_id":1, "name":"Elizaveta", "accounts":[{"account_id": 1}]}' \ http://localhost:8182/storage/customers/create
Em resposta, temos algo parecido com isto:
{"info":"Successfully created"}
Observe que no URL especificamos a porta da instância app-1 , 8082 , porque ela implementa essa API.
Agora vamos atualizar o saldo do nosso novo usuário:
$ curl -X POST -H "Content-Type: application/json" \ -d "{\"account_id\": 1, \"amount\": \"1000\"}" \ http://localhost:8182/storage/customers/1/update_balance
Na resposta, vemos o saldo atualizado:
{"balance":"1000.00"}
Ótimo, tudo funciona! A API é implementada, o cartucho está envolvido no compartilhamento de dados, já configuramos a prioridade de failover para casos de emergência e até a autorização ativada. É hora de fazer a configuração do aplicativo.
A configuração atual do cluster é armazenada em um arquivo de configuração distribuído. Cada instância mantém uma cópia desse arquivo e o Cartucho garante sua sincronização entre todos os nós do cluster. Podemos especificar a configuração das funções de nosso aplicativo neste arquivo e o Cartridge cuidará da distribuição da nova configuração em todas as instâncias.
Vamos dar uma olhada no conteúdo atual deste arquivo. Vá para a guia Cofiguration files e clique no botão Download :

No config.yml config.yml baixado config.yml encontramos uma tabela vazia. Não é de admirar, porque ainda não especificamos nenhum parâmetro:
--- [] ...
De fato, o arquivo de configuração do nosso cluster não está vazio, ele armazena a topologia atual, as configurações de autorização e as configurações de sharding. Mas o Cartucho não será tão fácil de compartilhar essas informações, elas se destinam ao uso interno e, portanto, são armazenadas em seções ocultas do sistema, que não podemos editar.
Cada função de aplicativo pode usar uma ou mais seções de configuração. O download de uma nova configuração ocorre em dois estágios: primeiro, todas as funções verificam se estão prontas para aceitar novos parâmetros. Se não houver objeção, as alterações serão aplicadas; se alguém for contra, ocorrerá uma reversão.
Vamos voltar ao nosso aplicativo. A função da api usa a seção de max-balance , onde o saldo máximo permitido é armazenado em uma conta do cliente. Vamos configurar esta seção, mas, é claro, não manualmente, mas usando nossa função Ansible.
Portanto, agora a configuração do aplicativo (ou melhor, parte dela disponível para nós) é uma tabela vazia. Adicione uma seção de max-balance com um valor de 100000 . Escrevemos a variável cartridge_app_config em nosso arquivo de inventário:
--- all: vars: ... # cluster-wide config cartridge_app_config: # <== max-balance: # section name body: 1000000 # section body # deleted: true # uncomment to delete section max-balance ...
Especificamos o nome da seção, max-balance e seu conteúdo, body . O conteúdo de uma seção pode não ser apenas um número, também pode ser uma tabela ou uma linha, dependendo de como a função é escrita e que tipo de valor você deseja usar.
Lançamos:
$ ansible-playbook -i hosts.yml playbook.yml \ --tags cartridge-config
E verificamos se o saldo máximo permitido realmente mudou:
$ curl -X POST -H "Content-Type: application/json" \ -d "{\"account_id\": 1, \"amount\": \"1000001\"}" \ http://localhost:8182/storage/customers/1/update_balance
Em resposta, obtemos um erro, como queríamos:
{"info":"Error","error":"Maximum is 1000000"}
Você pode baixar novamente o arquivo de configuração na guia Configuraion files do Configuraion files para garantir que uma nova seção apareça lá:
--- max-balance: 1000000 ...
Tente adicionar novas seções à configuração do aplicativo, altere seu conteúdo ou exclua-o completamente (para isso, é necessário definir o sinalizador delete deleted: true na seção).
Você pode descobrir como usar uma configuração distribuída em funções na documentação do Tarantool Cartridge.
Lembre-se de chamar a vagrant halt para parar as vagrant halt quando terminar de trabalhar com elas.
Em conclusão
Na última vez, aprendemos como implantar aplicativos de cartucho Tarantool distribuídos usando uma função Ansible especial. Hoje atualizamos o aplicativo e também dominamos o gerenciamento da topologia, sharding, autorização e configuração do aplicativo.
Não pare por aí, aprenda diferentes abordagens para escrever manuais de Ansible e use seus aplicativos com o máximo conforto.
Se algo não funcionar para você ou se você tiver idéias sobre como melhorar nosso papel, sinta-se à vontade para iniciar um ticket . Sempre ajudaremos na solução do seu problema e teremos prazer em ofertas interessantes!