Para dominar completamente o Kubernetes, você precisa conhecer as várias maneiras de dimensionar os recursos do cluster: de acordo
com os desenvolvedores do sistema , esta é uma das principais tarefas do Kubernetes. Preparamos uma revisão de alto nível dos mecanismos de dimensionamento automático horizontal e vertical e redimensionamento de cluster, bem como recomendações sobre como usá-los de maneira eficaz.
Um artigo do
Kubernetes Autoscaling 101: Autoscaler de cluster, Horizontal Autoescaler e Vertical Pod Autoscaler foi traduzido por uma equipe que implementou o
autoescalonamento no
Kubernetes aaS do Mail.ru.Por que é importante pensar em escala
Kubernetes é uma ferramenta de gerenciamento e orquestração de recursos. Obviamente, é bom mexer com funções interessantes de implantação, monitoramento e gerenciamento de pods (o módulo pod é um grupo de contêineres que são lançados em resposta a uma solicitação).
No entanto, você deve pensar sobre esses problemas:
- Como escalar módulos e aplicativos?
- Como manter os contêineres operacionais e eficientes?
- Como responder a mudanças constantes no código e nas cargas de trabalho dos usuários?
A configuração de clusters do Kubernetes para equilibrar recursos e desempenho pode ser um desafio, pois requer conhecimento especializado dos componentes internos do Kubernetes. A carga de trabalho em seu aplicativo ou serviço pode variar ao longo do dia ou até uma hora, para que o equilíbrio seja melhor representado como um processo contínuo.
Níveis de escala automática do Kubernetes
O dimensionamento automático eficaz requer coordenação entre dois níveis:
- Nível do pod, incluindo horizontal (Autoscaler Horizontal Pod, HPA) e dimensionamento automático vertical (Autoscaler Vertical Pod, VPA). Isso está dimensionando os recursos disponíveis para seus contêineres.
- O nível do cluster, que é controlado pelo Autoscaler do Cluster, CA, aumenta ou diminui o número de nós no cluster.
Módulo de escala automática horizontal (HPA)
Como o nome sugere, o HPA escala o número de réplicas de pod. Como um gatilho para alterar o número de réplicas, a maioria dos devops usa CPU e carga de memória. No entanto, você pode dimensionar o sistema com base em
métricas personalizadas , suas
combinações ou até
métricas externas .
Fluxo de trabalho HPA de alto nível:
- O HPA verifica continuamente os valores métricos especificados durante a instalação com um intervalo padrão de 30 segundos.
- HPA tenta aumentar o número de módulos se o limite especificado for atingido.
- HPA atualiza o número de réplicas no controlador de implantação / replicação.
- O controlador de implantação / replicação implementa todos os módulos complementares necessários.
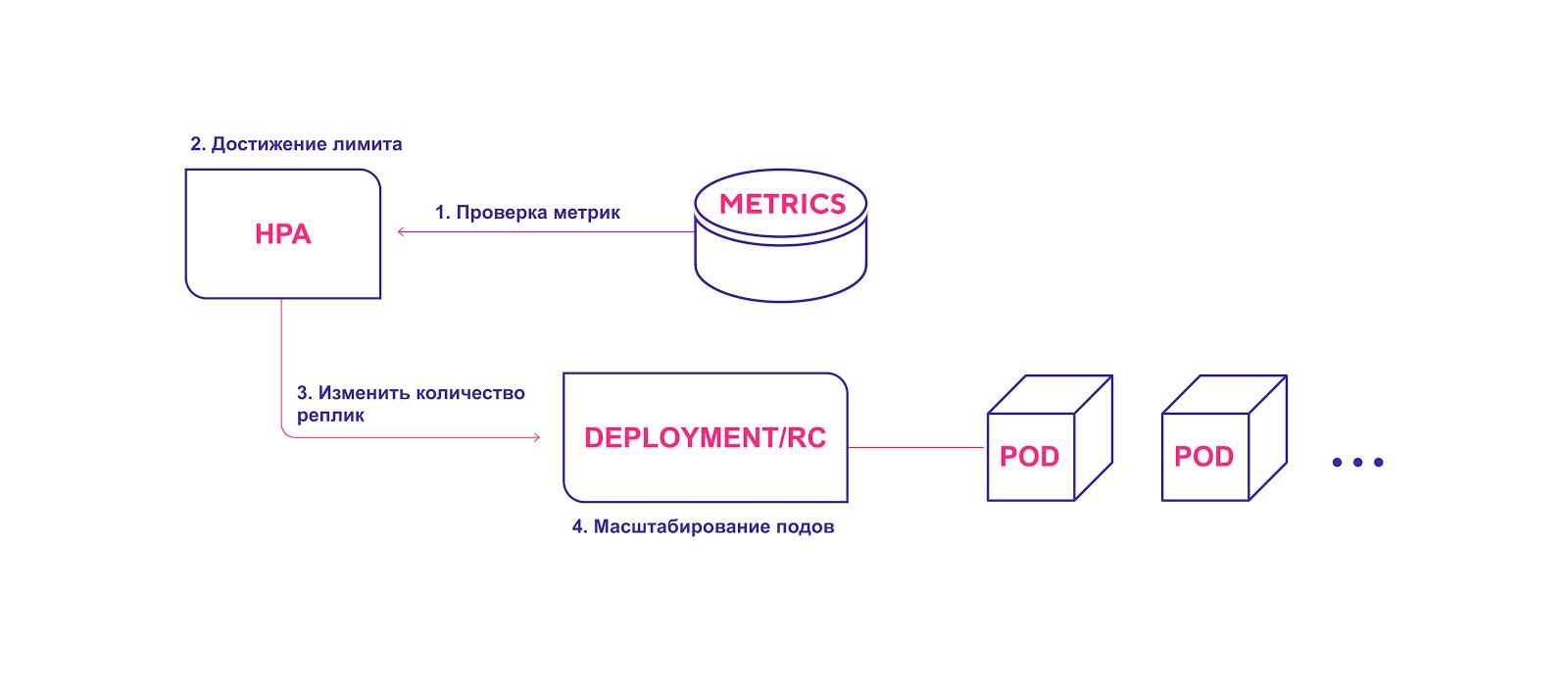 HPA inicia o processo de implantação do módulo quando o limite de métricas é atingido
HPA inicia o processo de implantação do módulo quando o limite de métricas é atingidoAo usar o HPA, considere o seguinte:
- O intervalo de validação padrão do HPA é 30 segundos. É definido com o sinalizador horizontal-pod-autoscaler-sync-period no gerenciador do controlador.
- O erro relativo padrão é 10%.
- Após o último aumento no número de módulos, a HPA espera que as métricas se estabilizem em três minutos. Esse intervalo é definido pelo sinalizador horizontal-pod-autoscaler-upscale-delay .
- Após a última redução no número de módulos, o HPA espera estabilizar por cinco minutos. Esse intervalo é definido pelo sinalizador horizontal-pod-autoscaler-downscale-delay .
- O HPA funciona melhor com objetos de implantação, não com controladores de replicação. O dimensionamento automático horizontal não é compatível com atualizações contínuas, que manipulam diretamente controladores de replicação. Ao implantar, o número de réplicas depende diretamente dos objetos de implantação.
Escalonamento automático vertical de pods
A Escala Automática Vertical (VPA) aloca mais (ou menos) tempo de processador ou memória para os pods existentes. É adequado para pods com ou sem apátrida sem estado, mas se destina principalmente a serviços com estado. No entanto, você pode aplicar o VPA para módulos sem estado se precisar ajustar automaticamente a quantidade de recursos alocados originalmente.
O VPA também responde a eventos do OOM (falta de memória, falta de memória). Para alterar o tempo do processador e o tamanho da memória, é necessário reiniciar o pod. Ao reiniciar, o VPA respeita o
orçamento de distribuição de pods (PDB ) para garantir o número mínimo de módulos.
Você pode definir a quantidade mínima e máxima de recursos para cada módulo. Portanto, você pode limitar a quantidade máxima de memória alocada a um limite de 8 GB. Isso é útil se os nós atuais simplesmente não puderem alocar mais de 8 GB de memória por contêiner. Especificações detalhadas e mecanismos operacionais são descritos no
wiki oficial do VPA .
Além disso, o VPA possui uma função de recomendação interessante (VPA Recommendender). Ele rastreia a utilização de recursos e eventos OOM de todos os módulos para oferecer novos valores de memória e tempo do processador com base em um algoritmo inteligente, levando em consideração métricas históricas. Há também uma API que pega um descritor de pod e retorna os valores de recursos propostos.
Vale ressaltar que o VPA Recommendender não monitora o "limite" de recursos. Isso pode fazer com que o módulo monopolize recursos dentro dos nós. É melhor definir um valor limite no nível do espaço para nome para evitar um enorme desperdício de memória ou tempo do processador.
Esquema de alto nível do VPA:
- O VPA verifica continuamente os valores métricos especificados durante a instalação com um intervalo padrão de 10 segundos.
- Se o limite especificado for atingido, o VPA tentará alterar a quantidade alocada de recursos.
- O VPA atualiza a quantidade de recursos no controlador de implantação / replicação.
- Quando você reinicia os módulos, todos os novos recursos são aplicados às instâncias criadas.
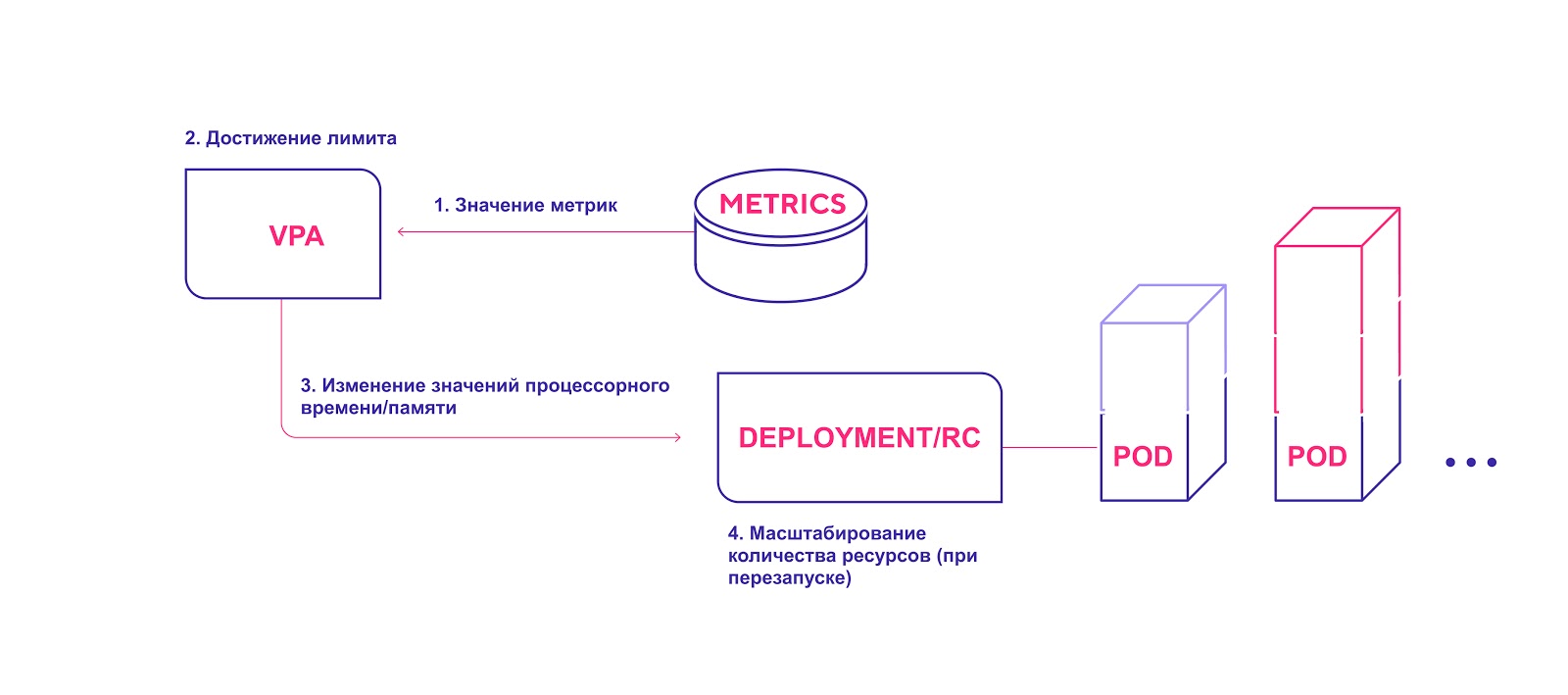 O VPA adiciona a quantidade necessária de recursos
O VPA adiciona a quantidade necessária de recursosConsidere os seguintes pontos ao usar o VPA:
- A escala requer uma reinicialização obrigatória do pod. Isso é necessário para evitar operações instáveis depois de fazer alterações. Para confiabilidade, os módulos são reiniciados e distribuídos entre os nós com base nos recursos recém-alocados.
- O VPA e o HPA ainda não são compatíveis entre si e não podem funcionar nos mesmos pods. Se você usar os dois mecanismos de dimensionamento no mesmo cluster, verifique se as configurações não permitirão que sejam ativadas nos mesmos objetos.
- O VPA configura solicitações de contêiner para recursos com base apenas no uso passado e atual. Não estabelece limites para o uso de recursos. Pode haver problemas com a operação incorreta de aplicativos que começarão a aproveitar cada vez mais recursos, isso fará com que o Kubernetes desligue esse pod.
- O VPA ainda está em um estágio inicial de desenvolvimento. Esteja preparado para que em um futuro próximo o sistema possa sofrer algumas alterações. Você pode ler sobre as limitações conhecidas e os planos de desenvolvimento . Portanto, nos planos para implementar o trabalho conjunto da VPA e HPA, bem como a implantação de módulos, juntamente com uma política vertical de auto-dimensionamento para eles (por exemplo, um rótulo especial 'exige VPA').
Escalonamento automático do cluster Kubernetes
O escalonador automático de cluster (CA) altera o número de nós com base no número de pods em espera. O sistema verifica periodicamente os módulos pendentes - e aumenta o tamanho do cluster se mais recursos forem necessários e se o cluster não exceder os limites estabelecidos. A CA interage com o provedor de serviços em nuvem, solicita nós adicionais a ele ou libera os inativos. A primeira versão do CA disponível ao público foi introduzida no Kubernetes 1.8.
Esquema de operação de alto nível CA:
- A CA verifica os módulos no estado de espera com um intervalo padrão de 10 segundos.
- Se um ou vários módulos estiverem em estado de espera devido aos recursos insuficientes disponíveis no cluster para sua distribuição, ele tentará preparar um ou vários nós adicionais.
- Quando o provedor de serviços em nuvem aloca o nó necessário, ele ingressa no cluster e está pronto para servir os módulos de pod.
- O Kubernetes Scheduler distribui os módulos pendentes para um novo host. Se depois disso, alguns módulos ainda permanecerem no estado de espera, o processo será repetido e novos nós serão adicionados ao cluster.
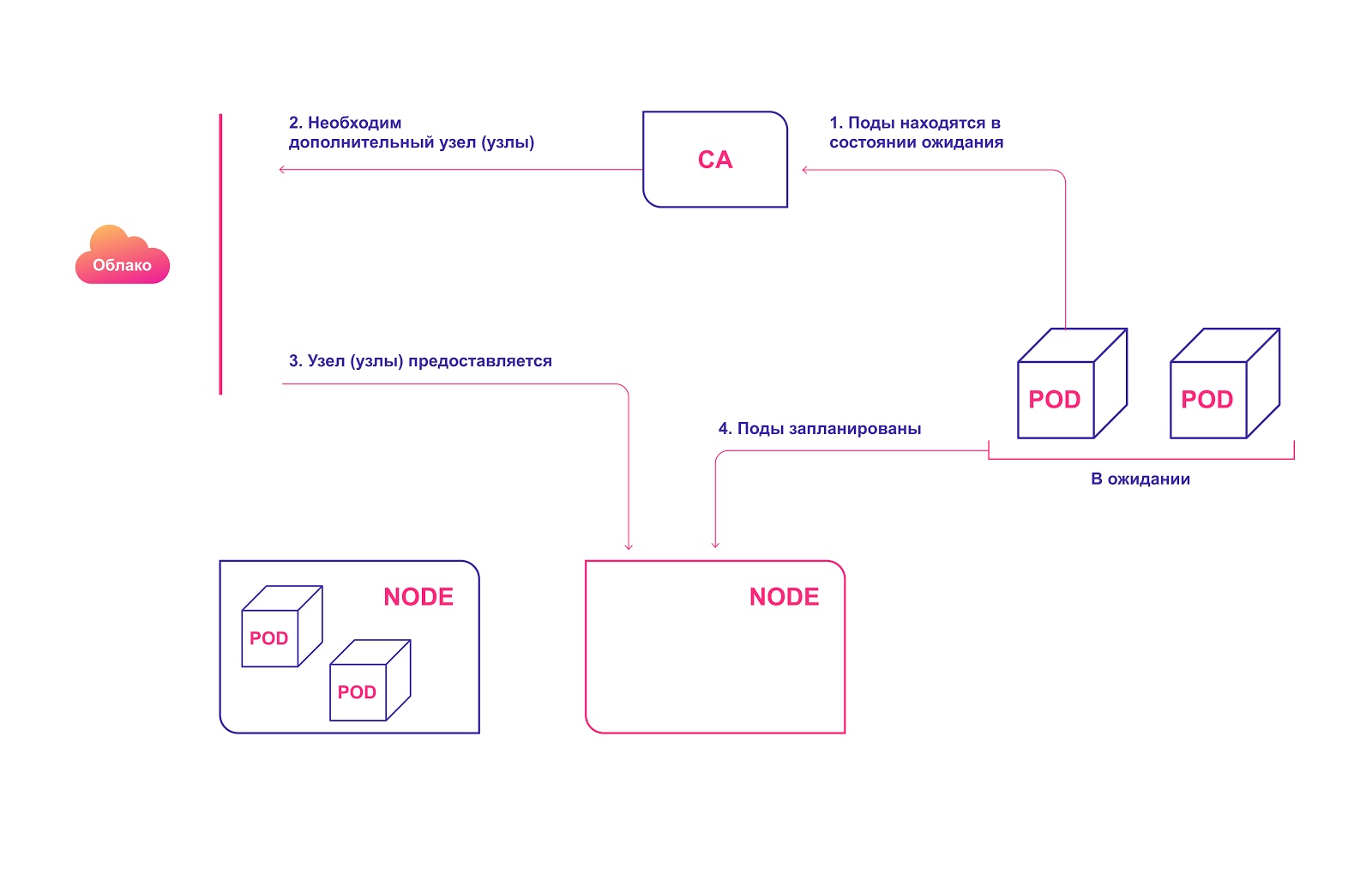 Alocação automática de nós de cluster na nuvem
Alocação automática de nós de cluster na nuvemConsidere o seguinte ao usar o CA:
- A CA garante que todos os módulos no cluster tenham um local para executar, independentemente da carga do processador. Além disso, ele tenta garantir que não haja nós desnecessários no cluster.
- A CA registra a necessidade de dimensionamento após cerca de 30 segundos.
- Depois que o nó se torna desnecessário, a CA, por padrão, aguarda 10 minutos antes de dimensionar o sistema.
- No sistema de escala automática, existe o conceito de expansores. Essas são estratégias diferentes para escolher um grupo de nós aos quais novos serão adicionados.
- Use com responsabilidade a opção cluster-autoscaler.kubernetes.io/safe-to-evict (true) . Se você instalar muitos pods, ou se muitos deles estiverem espalhados por todos os nós, você perderá bastante a capacidade de reduzir o tamanho do cluster.
- Use PodDisruptionBudgets para impedir a remoção de pods, pois uma parte do seu aplicativo pode falhar completamente.
Como os sistemas de autoescala Kubernetes interagem
Para uma perfeita harmonia, o dimensionamento automático deve ser aplicado no nível do pod (HPA / VPA) e no nível do cluster. Eles simplesmente interagem entre si:
- O HPA ou o VPA atualiza as réplicas ou recursos de pods alocados aos pods existentes.
- Se não houver nós suficientes para o dimensionamento planejado, a CA notará a presença de pods no estado ocioso.
- A CA aloca novos nós.
- Os módulos são distribuídos para novos nós.
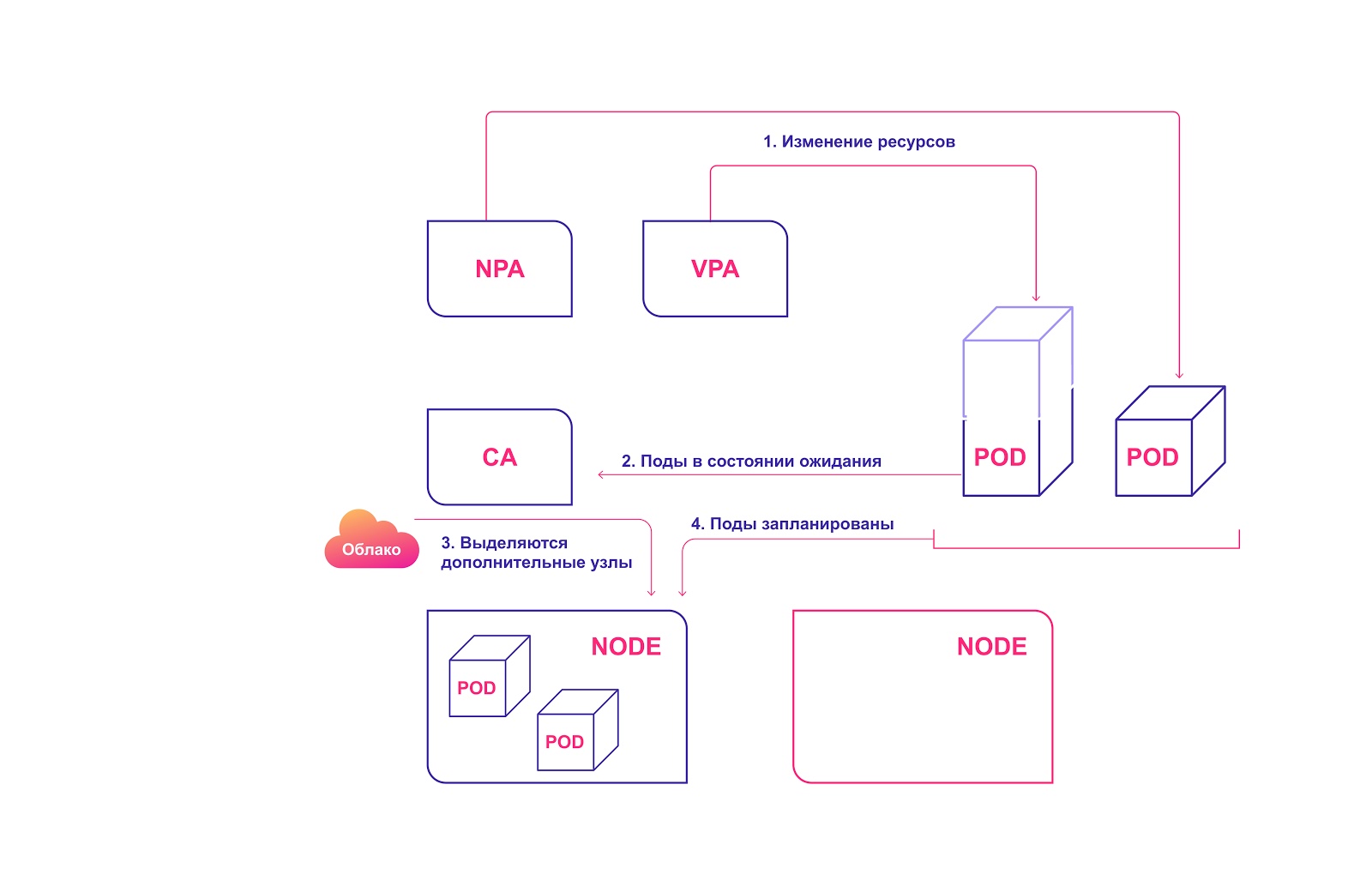 Sistema de dimensionamento colaborativo Kubernetes
Sistema de dimensionamento colaborativo KubernetesErros comuns de dimensionamento automático do Kubernetes
Existem vários problemas típicos que os desenvolvedores encontram ao tentar aplicar o dimensionamento automático.
HPA e VPA dependem de métricas e de alguns dados históricos. Se recursos insuficientes forem alocados, os módulos serão recolhidos e não poderão gerar métricas. Nesse caso, o dimensionamento automático nunca ocorrerá.
A operação de dimensionamento em si é sensível ao tempo. Queremos que os módulos e o cluster sejam dimensionados rapidamente - antes que os usuários percebam quaisquer problemas ou falhas. Portanto, o tempo médio de dimensionamento dos pods e cluster deve ser levado em consideração.
Cenário ideal - 4 minutos:
- 30 segundos Atualização das métricas de destino: 30 a 60 segundos.
- 30 segundos HPA verifica valores métricos: 30 segundos.
- Menos de 2 segundos. Os módulos de pod são criados e entram no estado de espera: 1 segundo.
- Menos de 2 segundos. A CA vê módulos pendentes e envia chamadas para preparar nós: 1 segundo.
- 3 minutos O provedor de nuvem aloca nós. Os K8s aguardam até que estejam prontos: até 10 minutos (depende de vários fatores).
Pior cenário (mais realista) - 12 minutos:
- 30 segundos Atualização de métricas de destino.
- 30 segundos HPA valida valores métricos.
- Menos de 2 segundos. Os módulos de pod são criados e entram no estado de espera.
- Menos de 2 segundos. A CA vê módulos pendentes e envia chamadas para preparar nós.
- 10 minutos O provedor de nuvem aloca nós. K8s espera até que estejam prontos. O tempo de espera depende de vários fatores, como o atraso do fornecedor, o atraso do SO, o trabalho de ferramentas auxiliares.
Não confunda os mecanismos de dimensionamento do provedor de nuvem com nossa CA. O último trabalha dentro do cluster Kubernetes, enquanto o mecanismo do provedor de nuvem trabalha com base na alocação de nós. Ele não sabe o que está acontecendo com seus pods ou aplicativos. Esses sistemas funcionam em paralelo.
Como gerenciar o dimensionamento no Kubernetes
- Kubernetes é uma ferramenta de gerenciamento e orquestração de recursos. As operações de gerenciamento de recursos e pod de cluster são um marco importante no desenvolvimento do Kubernetes.
- Aprenda a lógica de escalabilidade do pod para HPA e VPA.
- A CA deve ser usada apenas se você entender bem as necessidades de seus pods e contêineres.
- Para uma configuração ideal do cluster, você precisa entender como os vários sistemas de dimensionamento funcionam juntos.
- Ao avaliar os tempos de escala, lembre-se dos piores e melhores cenários.