Este artigo discutirá o projeto nginx-log-collector , que lerá os logs do nginx e os enviará para o cluster Clickhouse. Geralmente para logs, use o ElasticSearch. Clickhouse requer menos recursos (espaço em disco, RAM, CPU). Clickhouse registra dados mais rapidamente. A Clickhouse compacta os dados, tornando os dados do disco ainda mais compactos. Os benefícios do Clickhouse são visíveis em 2 slides do relatório Como o VK insere dados no ClickHouse de dezenas de milhares de servidores.


Para visualizar a análise de log, crie um painel para o Grafana.
Quem se importa, bem-vindo ao gato.
Instale o nginx, grafana da maneira padrão.
Instale o cluster da clickhouse usando o ansible-playbook de Denis Proskurin .
Criando bancos de dados e tabelas no Clickhouse
Este arquivo descreve consultas SQL para criar bancos de dados e tabelas para o nginx-log-collector no Clickhouse.
Por sua vez, fazemos cada solicitação em cada servidor do cluster Clickhouse.
Nota importante. Nesta linha, logs_cluster deve ser substituído pelo nome do cluster no arquivo clickhouse_remote_servers.xml entre "remote_servers" e "shard".
ENGINE = Distributed('logs_cluster', 'nginx', 'access_log_shard', rand())
Instalando e configurando nginx-log-collector-rpm
O Nginx-log-collector não possui rpm. Aqui https://github.com/patsevanton/nginx-log-collector-rpm crie rpm para ele. As rpm serão coletadas usando o Fedora Copr
Instale o pacote rpm nginx-log-collector-rpm
yum -y install yum-plugin-copr yum copr enable antonpatsev/nginx-log-collector-rpm yum -y install nginx-log-collector systemctl start nginx-log-collector
Edite o arquivo config /etc/nginx-log-collector/config.yaml:
....... upload: table: nginx.access_log dsn: http://ip---clickhouse:8123/ - tag: "nginx_error:" format: error # access | error buffer_size: 1048576 upload: table: nginx.error_log dsn: http://ip---clickhouse:8123/
Configuração do Nginx
Configuração geral do nginx:
user nginx; worker_processes auto;
O host virtual é um:
vhost1.conf:
upstream backend { server ip----stub_http_server:8080; server ip----stub_http_server:8080; server ip----stub_http_server:8080; server ip----stub_http_server:8080; server ip----stub_http_server:8080; } server { listen 80; server_name vhost1; location / { proxy_pass http://backend; } }
Adicione hosts virtuais ao arquivo / etc / hosts:
ip----nginx vhost1
Emulador de servidor HTTP
Como um emulador de servidor HTTP, usaremos nodejs-stub-server de Maxim Ignatenko
O Nodejs-stub-server não possui rpm. Aqui https://github.com/patsevanton/nodejs-stub-server crie o rpm para ele. As rpm serão coletadas usando o Fedora Copr
Instale o pacote nodejs-stub-server no nginx rpm upstream
yum -y install yum-plugin-copr yum copr enable antonpatsev/nodejs-stub-server yum -y install stub_http_server systemctl start stub_http_server
Teste de carga
Teste realizado usando o benchmark Apache.
Instale-o:
yum install -y httpd-tools
Começamos a testar usando o benchmark Apache em 5 servidores diferentes:
while true; do ab -H "User-Agent: 1server" -c 10 -n 10 -t 10 http://vhost1/; sleep 1; done while true; do ab -H "User-Agent: 2server" -c 10 -n 10 -t 10 http://vhost1/; sleep 1; done while true; do ab -H "User-Agent: 3server" -c 10 -n 10 -t 10 http://vhost1/; sleep 1; done while true; do ab -H "User-Agent: 4server" -c 10 -n 10 -t 10 http://vhost1/; sleep 1; done while true; do ab -H "User-Agent: 5server" -c 10 -n 10 -t 10 http://vhost1/; sleep 1; done
Grafana Setup
No site oficial da Grafana, você não encontrará um painel.
Portanto, vamos entregá-lo.
Você pode encontrar meu painel salvo aqui .
Você também precisa criar uma variável de tabela com o conteúdo de nginx.access_log .
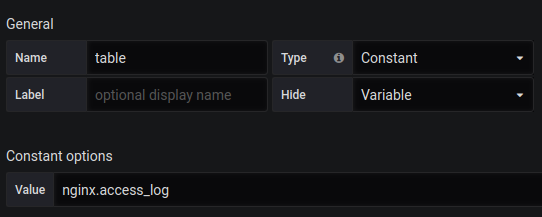
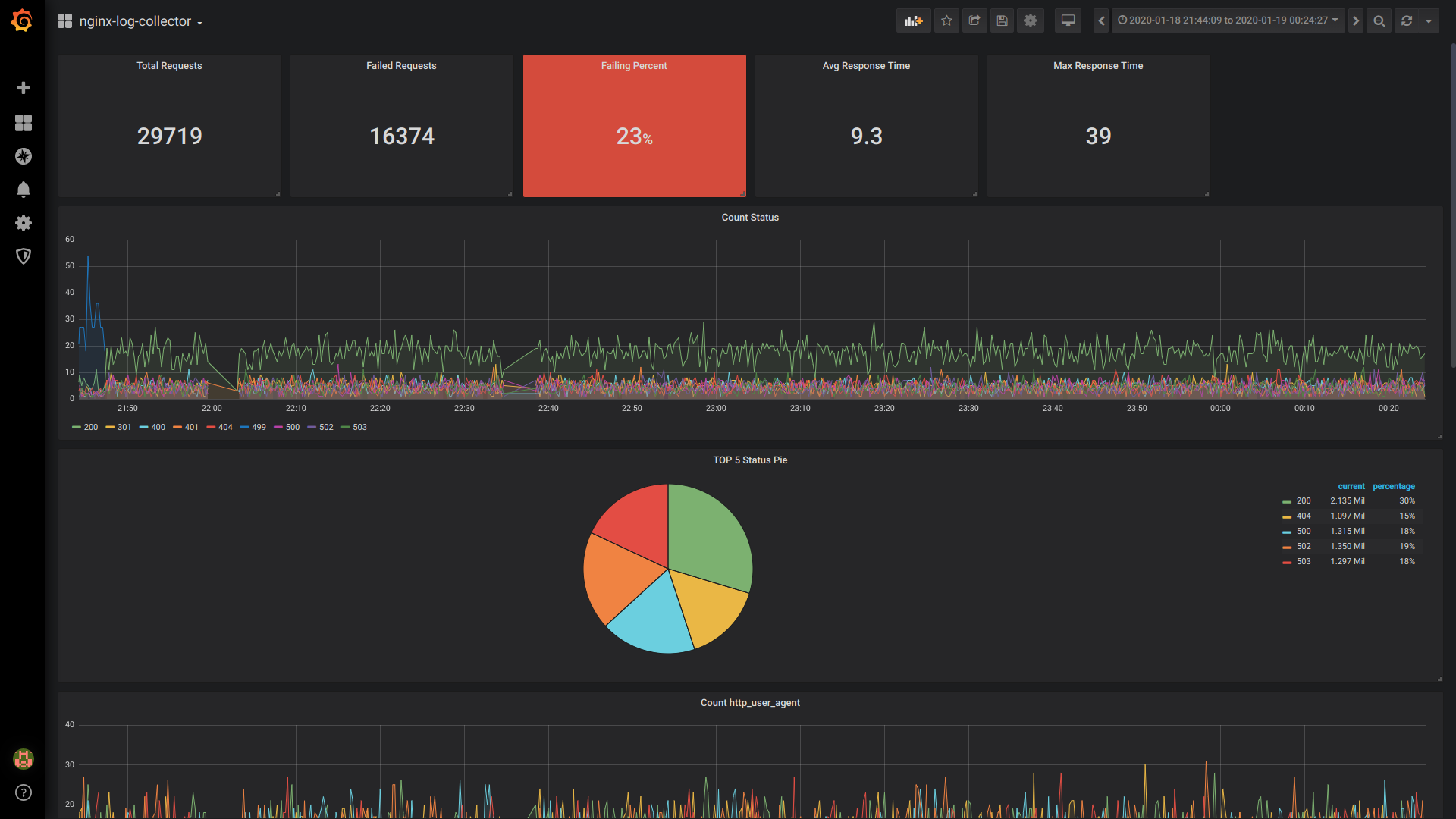
Total de solicitações de Singlestat:
SELECT 1 as t, count(*) as c FROM $table WHERE $timeFilter GROUP BY t
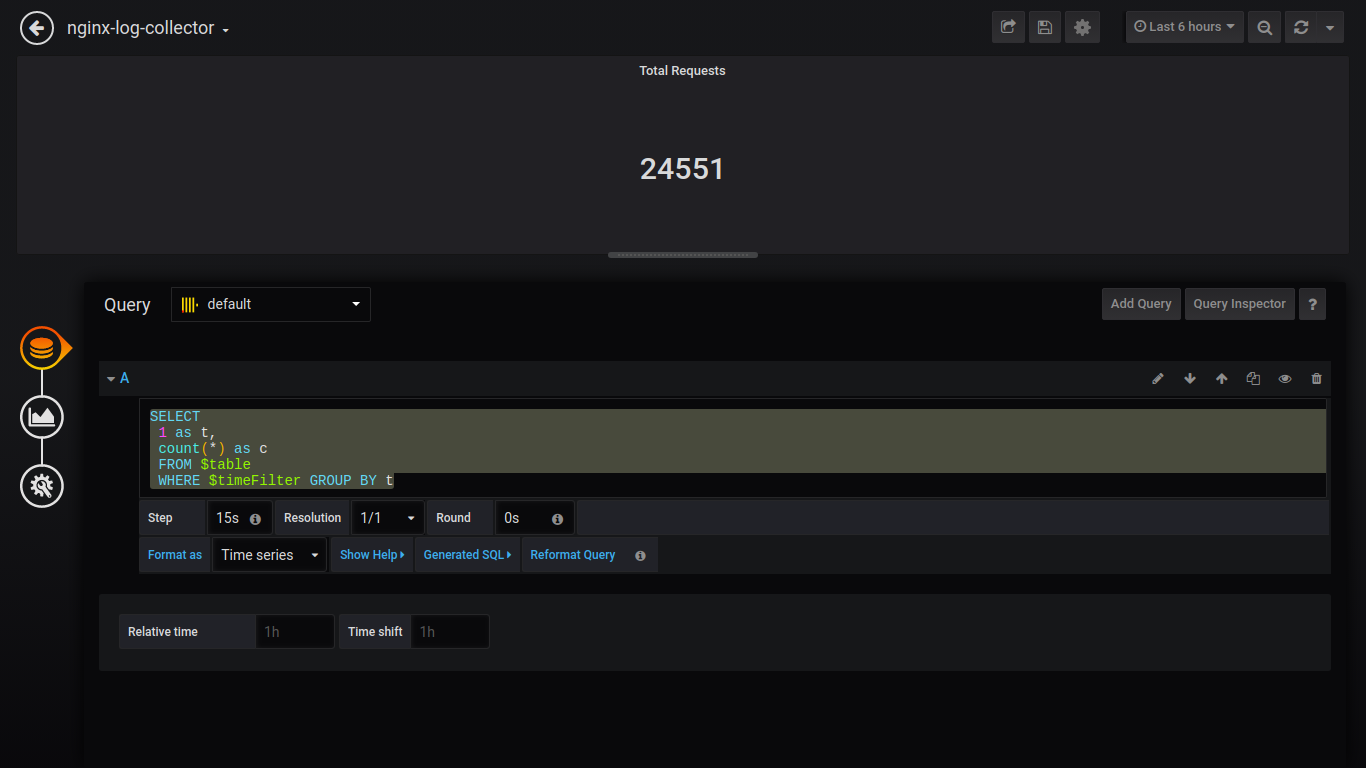
Solicitações com falha de Singlestat:
SELECT 1 as t, count(*) as c FROM $table WHERE $timeFilter AND status NOT IN (200, 201, 401) GROUP BY t
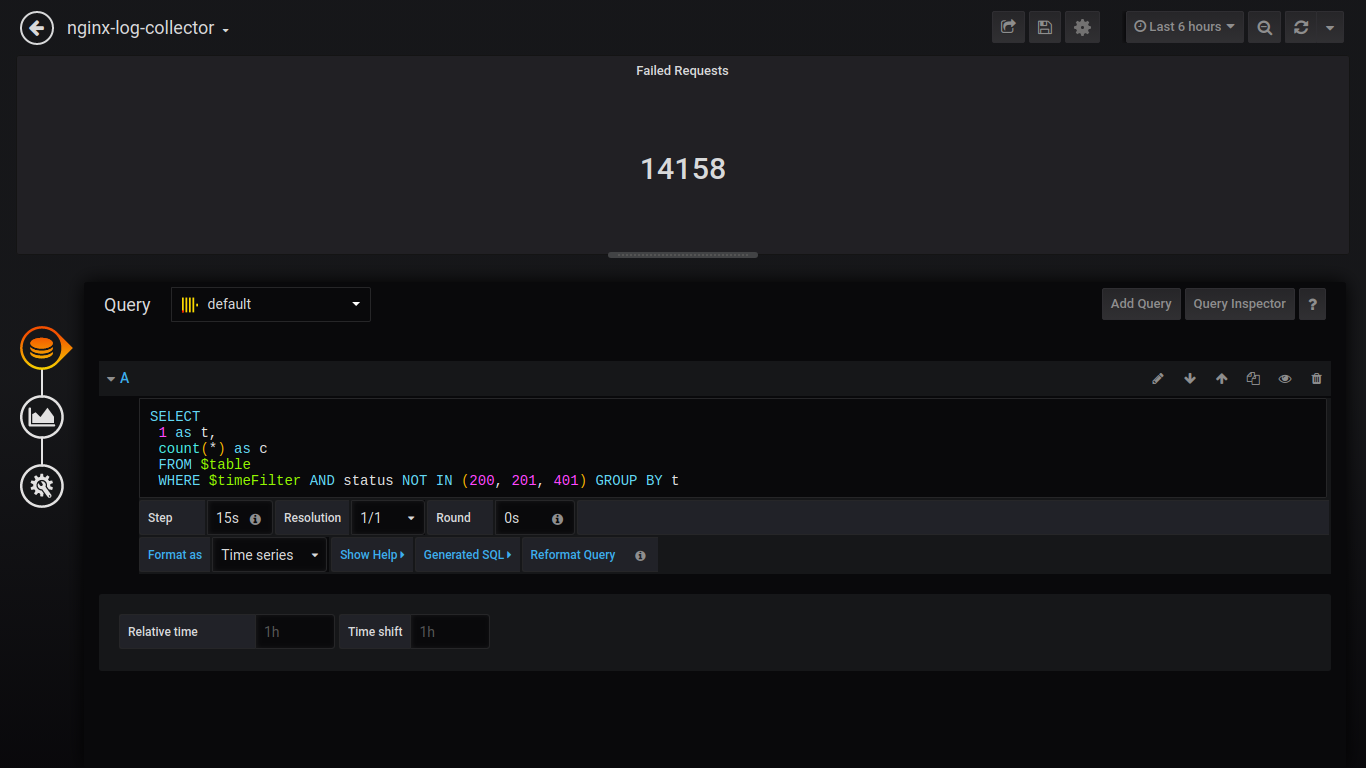
Porcentagem de falha de Singlestat:
SELECT 1 as t, (sum(status = 500 or status = 499)/sum(status = 200 or status = 201 or status = 401))*100 FROM $table WHERE $timeFilter GROUP BY t
Tempo médio de resposta de Singlestat:
SELECT 1, avg(request_time) FROM $table WHERE $timeFilter GROUP BY 1
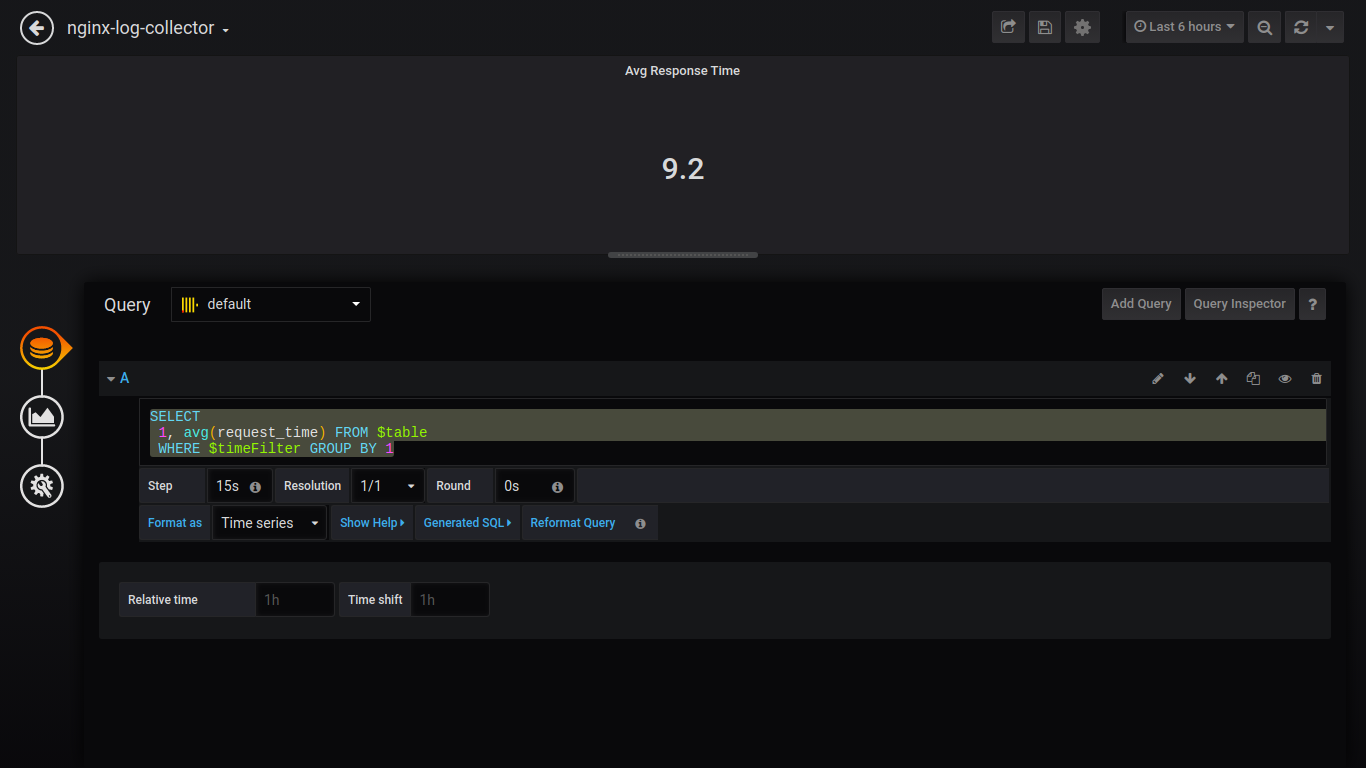
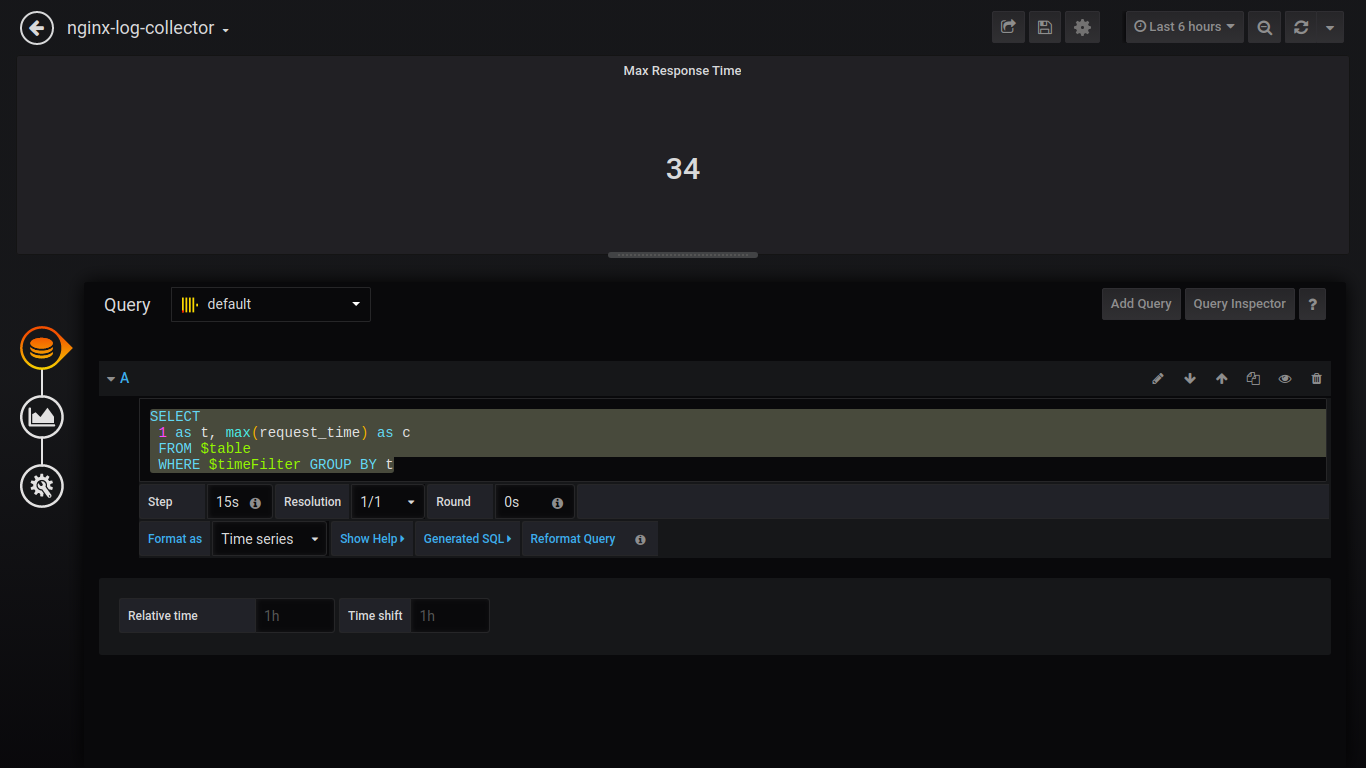
Tempo máximo de resposta de Singlestat:
SELECT 1 as t, max(request_time) as c FROM $table WHERE $timeFilter GROUP BY t
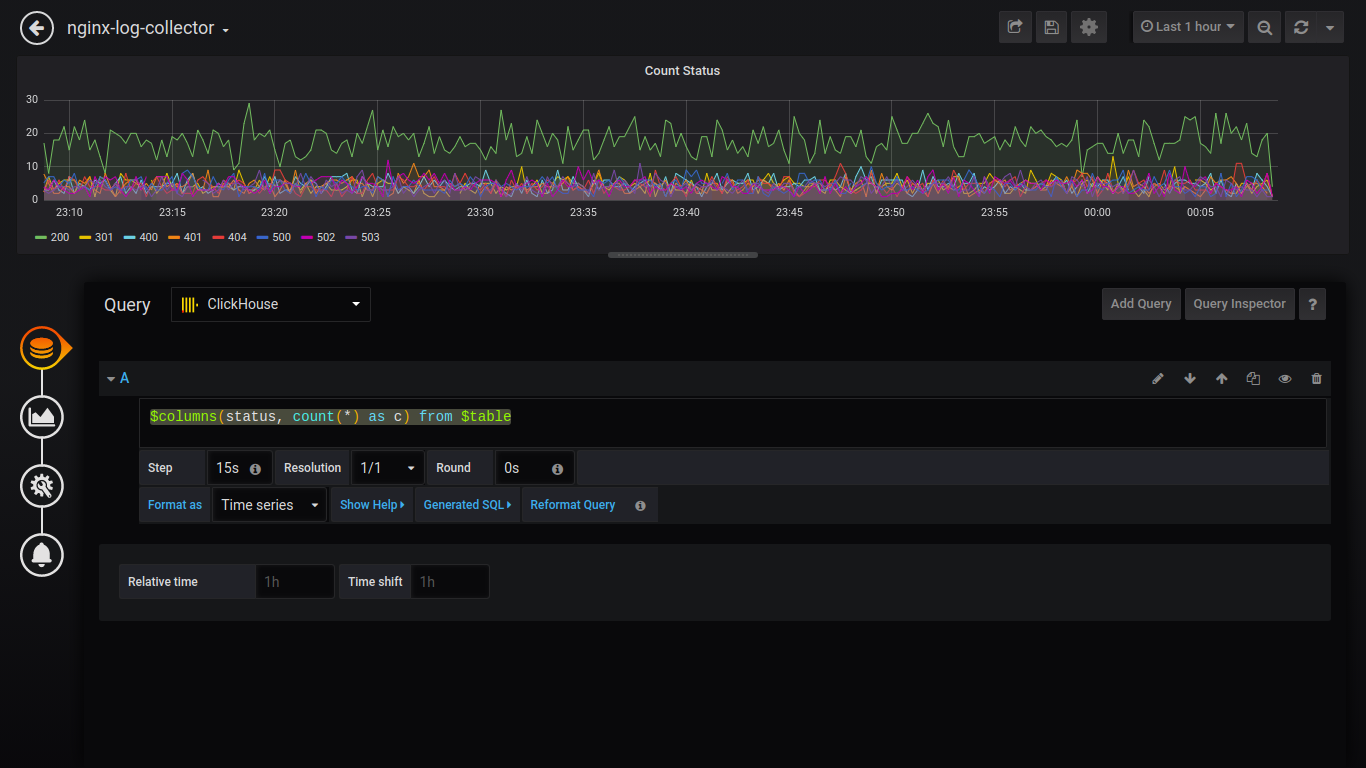
Status da contagem:
$columns(status, count(*) as c) from $table
Para gerar dados como uma torta, é necessário instalar o plug-in e reiniciar o grafana.
grafana-cli plugins install grafana-piechart-panel service grafana-server restart
Torta TOP 5 Status:
SELECT 1, status, sum(status) AS Reqs FROM $table WHERE $timeFilter GROUP BY status ORDER BY Reqs desc LIMIT 5
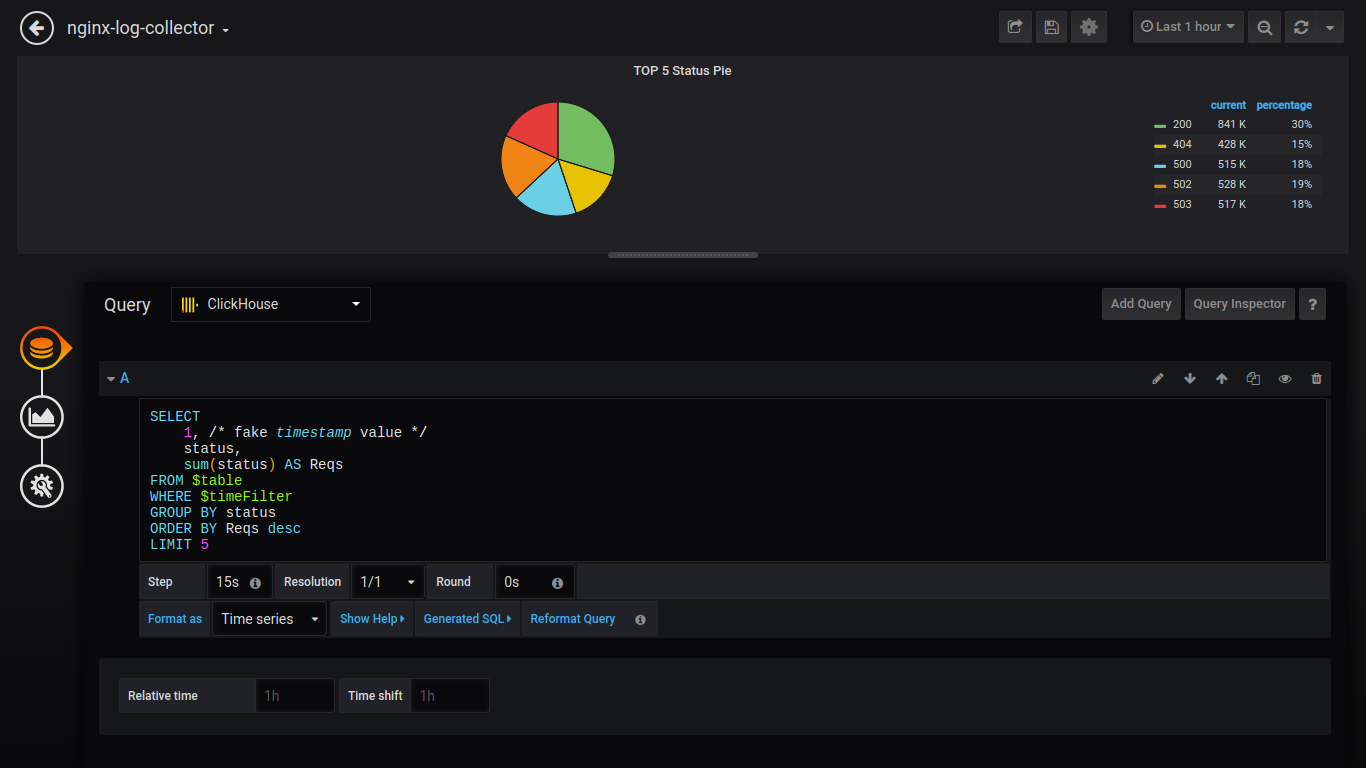
Além disso, darei solicitações sem capturas de tela:
Contagem http_user_agent:
$columns(http_user_agent, count(*) c) FROM $table
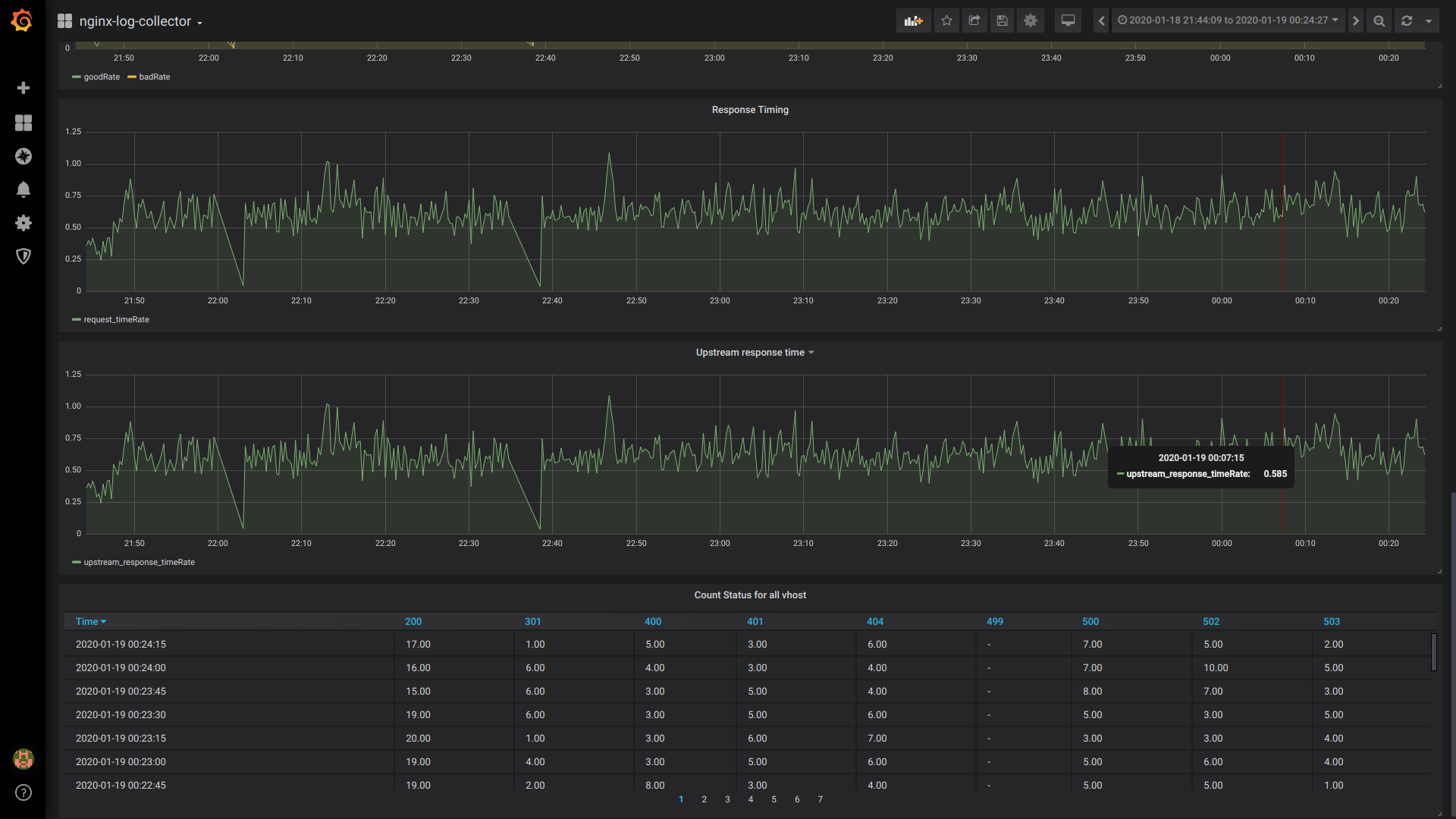
GoodRate / BadRate:
$rate(countIf(status = 200) AS good, countIf(status != 200) AS bad) FROM $table
Tempo de resposta:
$rate(avg(request_time) as request_time) FROM $table
Tempo de resposta a montante (tempo de resposta da 1ª a montante):
$rate(avg(arrayElement(upstream_response_time,1)) as upstream_response_time) FROM $table
Status da contagem de tabelas para todos os vhost:
$columns(status, count(*) as c) from $table
Vista geral do painel

Comparando avg () e quantile ()
média ()

quantil ()

Conclusão:
Espero que a comunidade se envolva no desenvolvimento / teste e no uso do nginx-log-collector.
E alguém, quando ele implementa o nginx-log-collector, lhe dirá quanto ele salvou o disco, RAM, CPU.
Canais de telegrama:
Milissegundos:
Para quem os milissegundos são importantes, escreva ou vote, por favor, nesta edição .