Se você escrever
consultas SQL sem analisar o algoritmo que elas devem implementar, isso geralmente não leva a nada de bom em termos de desempenho.
Tais solicitações
gostam de "comer" o tempo do processador e ler ativamente os dados quase do nada. Além disso, isso não é necessariamente algum tipo de consulta complexa, pelo contrário - quanto mais simples for escrita, maior a chance de obter problemas. E se o operador JOIN entrar em jogo ...
Por si só, unir tabelas não é prejudicial nem útil - é apenas uma ferramenta, mas você deve poder usá-la.
Agrupamento de supervisão
Primeiro, tome um exemplo muito simples.
Há um "dicionário" de 100 entradas (por exemplo, são regiões da Federação Russa):
CREATE TABLE tbl_dict AS SELECT generate_series(0, 100) k; ALTER TABLE tbl_dict ADD PRIMARY KEY(k);
... e anexada a ela, há uma tabela de "fatos" relacionados por 100 mil entradas:
CREATE TABLE tbl_fact AS SELECT (random() * 100)::integer k , (random() * 1000)::integer v FROM generate_series(1, 100000); CREATE INDEX ON tbl_fact(k);
Agora vamos tentar calcular a soma dos valores para cada "região".
Como é ouvido, está escrito
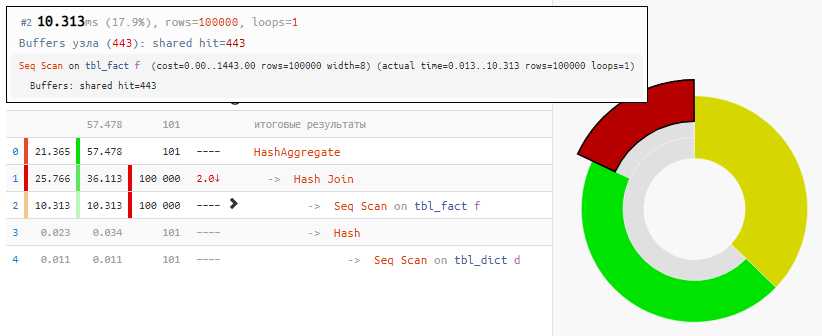
SELECT dk , sum(fv) FROM tbl_fact f NATURAL JOIN tbl_dict d GROUP BY 1;
A leitura dos dados em si levou apenas 18% do tempo, o restante foi processado:
 [veja em explicar.tensor.ru]
[veja em explicar.tensor.ru]E tudo porque o Hash Join e o Hash Aggregate tiveram que processar 100 mil registros cada um por causa do nosso desejo de
agrupar pelo campo da tabela vinculada .
Usamos engenhosidade
Mas o valor desse campo é igual ao valor do campo na tabela agregada! Ou seja, ninguém nos incomoda em
primeiro agrupar os "fatos" e só então fazer uma conexão :
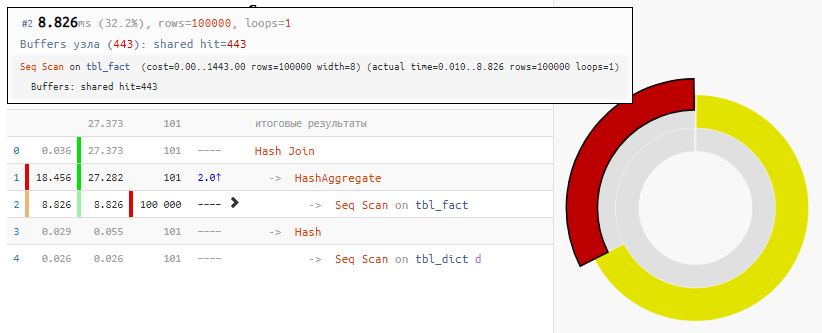
SELECT dk , f.sum FROM ( SELECT k , sum(v) FROM tbl_fact GROUP BY 1 ) f NATURAL JOIN tbl_dict d;
 [veja em explicar.tensor.ru]
[veja em explicar.tensor.ru]Obviamente, o método não é universal, mas, para o nosso caso de "JOIN usual"
, o ganho de tempo é 2 vezes com uma modificação mínima da solicitação - simplesmente devido ao Hash Join "nulo", que recebeu apenas 100 entradas em vez de 100 mil entradas.
Condições Desiguais
Agora vamos complicar a tarefa: temos 3 tabelas conectadas por um identificador - a principal e duas auxiliares com alguns dados do aplicativo, pelos quais filtraremos.
Uma observação pequena, mas muito importante: mesmo com base no conhecimento "aplicado" da tarefa de destino, já sabemos que as condições serão satisfeitas
na primeira tabela - quase sempre (por definição - 3: 4) e
na segunda - muito raramente (1: 8 )
Queremos selecionar a partir da tabela principal e da primeira tabela auxiliar os
100 primeiros registros por id com valores de identificadores pares para os quais as
condições em todas as tabelas são atendidas . Todos os registros nas tabelas, vamos estar novamente em 100K.
Gerador de scripts CREATE TABLE base( id integer PRIMARY KEY , val integer ); INSERT INTO base SELECT id , (random() * 1000)::integer FROM generate_series(1, 100000) id; CREATE TABLE ext1( id integer PRIMARY KEY , conda boolean ); INSERT INTO ext1 SELECT id , (random() * 4)::integer <> 0
Como é ouvido, está escrito
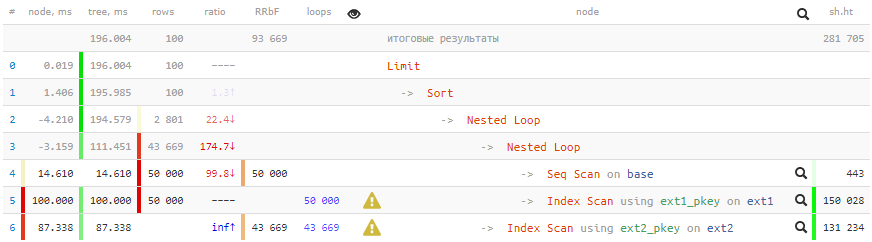
SELECT base.* , ext1.* FROM base NATURAL JOIN ext1 NATURAL JOIN ext2 WHERE id % 2 = 0 AND conda AND condb ORDER BY base.id LIMIT 100;
 [veja em explicar.tensor.ru]
[veja em explicar.tensor.ru]Tempos negativos em termosTantos ciclos passaram por alguns nós que os erros de arredondamento de alguns foram levados a menos. Sobre artefatos semelhantes nos planos, falarei no
PGConf.Russia .
200ms e mais 2 GB de dados bombeados - não muito bom para 100 registros!
Usamos engenhosidade
Usamos as seguintes abordagens para obter aceleração:
- Para começar, entendemos que faz sentido verificar todas as condições de tabelas vinculadas somente quando as condições da tabela principal forem atendidas (para o ID par).
- A saída deve ser classificada por base.id e, para isso, a chave primária desta tabela é perfeita para nós!
- Não precisamos de dados do ext2 e somos usados apenas para verificar a condição. Isso significa que todo o trabalho com esta tabela pode ser removido com segurança da parte JOIN para a parte WHERE . E use EXISTS para verificação, caso contrário, e se não houver esse registro?
- Precisamos recuperar pelo menos alguns dados do ext1 somente se as verificações restantes na base e no ext2 forem aprovadas com êxito . Ou seja, a conexão com ext1 deve ocorrer após todas as ações com base / ext2, que podem ser obtidas usando LATERAL.
- Para que o planejador de consultas não tente transformar a verificação aninhada no ext2 em JOIN, a subconsulta "ocultar sob CASE" .
SELECT base.* , ext1.* FROM base , LATERAL(
 [veja em explicar.tensor.ru]
[veja em explicar.tensor.ru]O pedido, é claro, ficou mais complicado, mas
ganhar 13 vezes no tempo e 350 em "gula" vale a pena!
Deixe-me lembrá-lo novamente que nem todos os métodos são usados e nem sempre, mas o conhecimento não será supérfluo.Também será interessante: