 A segunda parte da tradução do Longrid dedicada à visualização de conceitos da teoria da informação. A segunda parte trata da entropia, entropia cruzada, divergência de Kullback-Leibler, informações mútuas e bits fracionários. Todos os conceitos são fornecidos com excelentes explicações visuais.
A segunda parte da tradução do Longrid dedicada à visualização de conceitos da teoria da informação. A segunda parte trata da entropia, entropia cruzada, divergência de Kullback-Leibler, informações mútuas e bits fracionários. Todos os conceitos são fornecidos com excelentes explicações visuais.Para completar, antes de ler a segunda parte, recomendo que você
se familiarize com a primeira .
Cálculo de entropia
Lembre-se de que o custo de uma mensagem é longo
L é igual a
frac12L . podemos inverter esse valor para obter o tamanho da mensagem que vale o valor especificado:
log2( frac1cost) . Desde que gastamos
p(x) por palavra-código para
x , o comprimento será igual
log2( frac1p(x)) . Na figura, a escolha dos melhores comprimentos de palavras de código.
Discutimos anteriormente que há um limite fundamental para o quão curta uma mensagem média pode ser para transmitir eventos de uma determinada distribuição de probabilidade
p . esse limite, o tamanho médio da mensagem ao usar o melhor sistema de codificação, é chamado entropia
p,H(p) . Agora que sabemos o tamanho ideal da palavra de código, podemos calculá-lo!
H(p)= sumxp(x) log2 Bigg( frac1p(x) Bigg)
(Muitas vezes, a entropia é escrita como
H(p)=− somap(x) log2(p(x)) usando igualdade
log(1/a)=− log(a) . Parece-me que a primeira versão é mais intuitiva, por isso continuaremos a usá-la.)
Se eu quiser relatar o evento que aconteceu, não importa o que eu faça, em média eu preciso enviar tantos bits.
A quantidade média de informações necessárias para transmitir algo tem consequências diretas para a compactação. Mas existem outras razões pelas quais devemos cuidar disso? Sim Descreve minha incerteza e torna possível quantificar informações.
Se eu soubesse com certeza o que aconteceria, não precisaria enviar nenhuma mensagem! Se houver duas coisas que podem acontecer com uma probabilidade de 50%, eu preciso enviar apenas 1 bit. Mas se houver 64 eventos diferentes que podem ocorrer com a mesma probabilidade, terei que enviar 6 bits. Quanto mais concentrada a probabilidade, mais oportunidades tenho para criar código inteligente com mensagens curtas e médias. Quanto mais vaga a probabilidade, mais longas devem ser as minhas postagens.
Quanto mais incerto o resultado, mais eu aprendo em média quando eles me dizem o que aconteceu.
Entropia cruzada
Pouco antes de se mudar para a Austrália, Bob se casou com Alice, também imaginária. Para minha surpresa, assim como para a surpresa de outros personagens na minha cabeça, Alice não era uma amante de cães. Ela era uma amante de gatos. Apesar disso, eles foram capazes de encontrar uma linguagem comum em sua obsessão geral por animais e em seu vocabulário muito limitado.
Esses dois usam as mesmas palavras, apenas com frequências diferentes. Bob fala sobre cães o tempo todo, Alice fala sobre gatos o tempo todo.
Alice primeiro me enviou mensagens usando o código de Bob. Infelizmente, suas postagens foram mais longas do que o necessário. O código de Bob foi otimizado para sua distribuição de probabilidade. Alice tem uma distribuição de probabilidade diferente e o código não é ideal para ela. O comprimento médio da palavra de código quando Bob usa seu código é de 1,75 bits; quando Alice usa, em seguida, 2,25. Seria ainda pior se os dois não fossem tão parecidos!
O tamanho médio da mensagem de uma distribuição com o código ideal para outra distribuição é chamado de entropia cruzada. Formalmente, podemos definir entropia cruzada da seguinte maneira:
Hp(q)= sumxq(x) log2 Bigg( frac1p(x) Bigg)
Nesse caso, estamos falando sobre a entropia cruzada da frequência de palavras do verme de Alice em relação à frequência de palavras do amante de cães de Bob.
Para reduzir o custo de nossa conexão, pedi a Alice para usar seu próprio código. Para meu alívio, isso reduziu o tamanho médio das mensagens. Mas isso criou um novo problema: às vezes, Bob acidentalmente usava o código de Alice. Surpreendentemente, é pior quando Bob usa o código de Alice do que quando Alice usa o código de Bob!
Então agora temos quatro possibilidades:
- Bob usa código nativo ( H(p)=1,75 pouco)
- Alice usa o código de Bob ( Hp(q)=2,25 pouco)
- Alice usa seu próprio código ( H(q)=1,75 pouco)
- Bob usa o código de Alice ( Hq(p)=2.375 pouco)
Isso não é tão intuitivo quanto se pode pensar. Por exemplo, podemos ver que
Hp(q)≠Hq(p) . De alguma forma, podemos ver como esses quatro significados se relacionam?
No diagrama a seguir, cada subgráfico representa uma dessas 4 possibilidades. As ilustrações visualizam o comprimento médio de uma mensagem. Eles são organizados em um quadrado, de modo que, se as mensagens são da mesma distribuição, os gráficos estão próximos e, se eles usam os mesmos códigos, ficam um em cima do outro. Isso permite combinar visualmente distribuições e códigos.
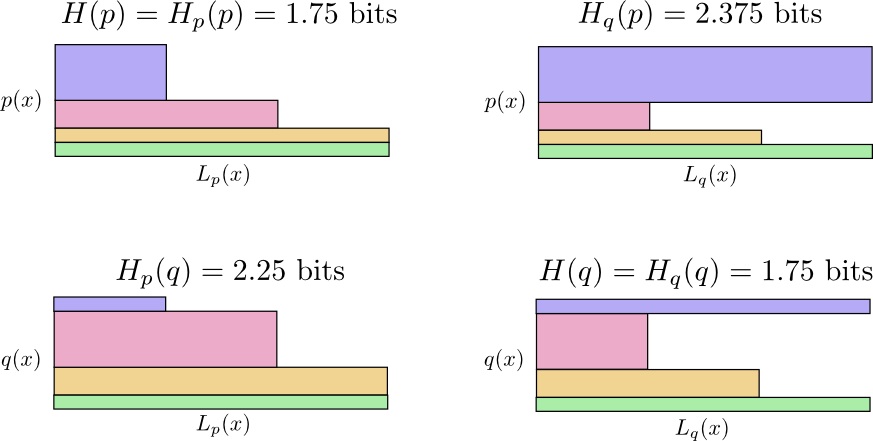
Veja porque
Hp(q)≠Hq(p) ?
Hq(p) tão grande, porque o evento marcado em azul ocorre frequentemente quando
p mas obtém uma palavra de código longa, porque é muito raro para
q . Por outro lado, eventos frequentes com
q menos comum com
p mas a diferença é menos dramática, portanto
Hp(q)Hp(q) um pouco menos.
A entropia cruzada não é simétrica.
Então, por que você deveria se preocupar com entropia cruzada? A entropia cruzada nos dá uma maneira de expressar quão diferentes são as duas distribuições de probabilidade. Quanto mais diferentes as distribuições
p e
q a maior entropia cruzada
p a respeito
q haverá mais entropia
p .
Da mesma forma, quanto mais
q diferente de
p a maior entropia cruzada
q a respeito
p haverá mais entropia
q .
O mais interessante é a diferença entre entropia e entropia cruzada. Essa diferença é igual à duração de nossas postagens, porque usamos código otimizado para outra distribuição. Se as distribuições forem iguais, essa diferença será zero. À medida que as diferenças aumentam, ele se torna maior.
Chamamos essa diferença de divergência de Kullback-Leibler, ou simplesmente divergência de KL. Divergência KL
p a respeito
q ,
Dq(p) definido da seguinte forma:
Dq(p)=Hq(p)−H(p)
A grande vantagem da divergência KL é que ela se parece com a distância entre duas distribuições. Mede o quão diferentes eles são! (Se você levar essa ideia a sério, chegará à geometria da informação.)
Entropia cruzada e divergência de KL são incrivelmente úteis no aprendizado de máquina. Muitas vezes, queremos que uma distribuição esteja próxima de outra. Por exemplo, podemos querer que a distribuição prevista esteja próxima da verdade subjacente. A divergência de KL nos fornece uma maneira natural de fazer isso e, portanto, ela se manifesta em todos os lugares.
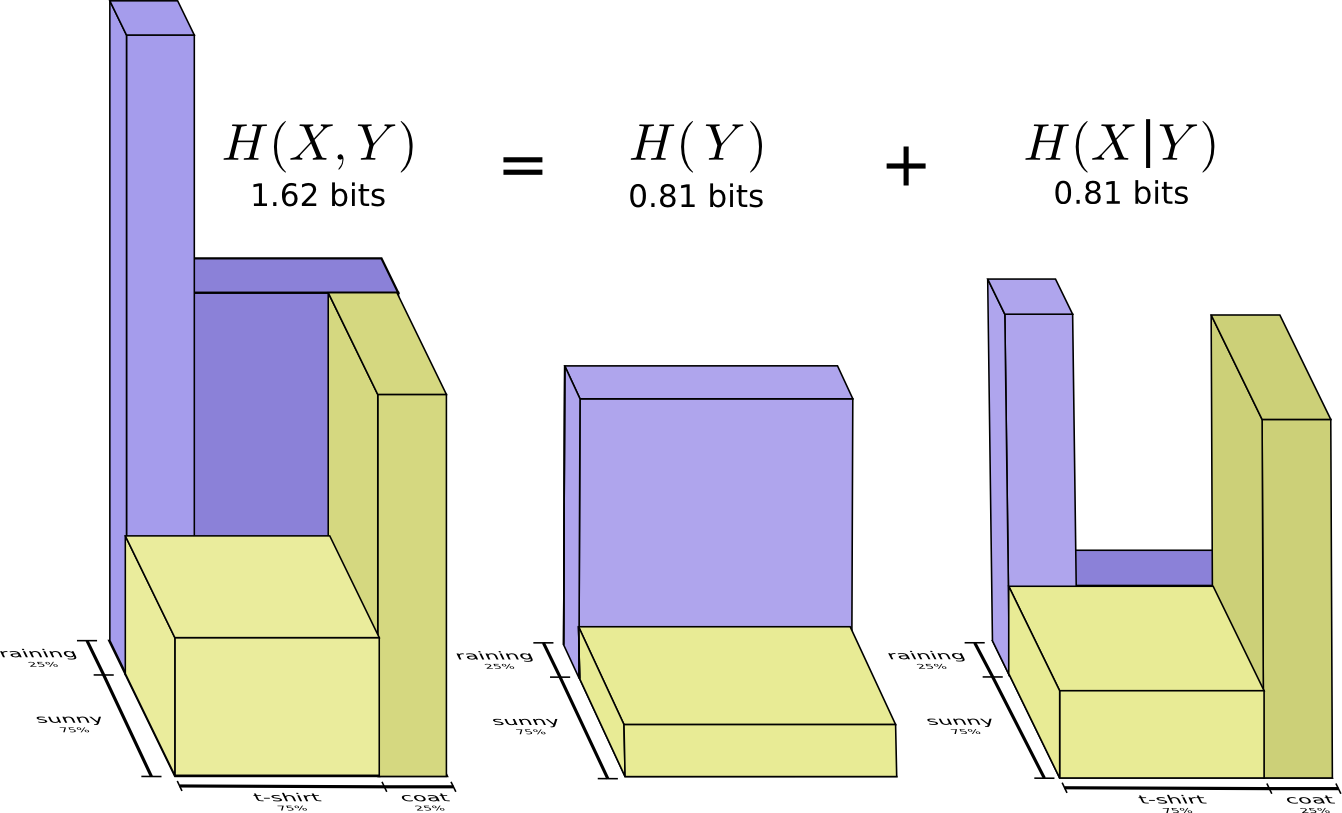
Entropia e várias variáveis
Vamos voltar ao nosso exemplo de clima e vestuário, dado anteriormente:
Minha mãe, como muitos pais, às vezes se preocupa por não me vestir adequadamente para o clima. (Ela tem um bom motivo para suspeitar - às vezes não uso capa de chuva no inverno.) Portanto, ela muitas vezes quer saber o tempo e o que estou vestindo. Quantos bits devo mandá-la para relatar isso?
A maneira mais fácil de pensar sobre isso é equilibrar a distribuição de probabilidade:
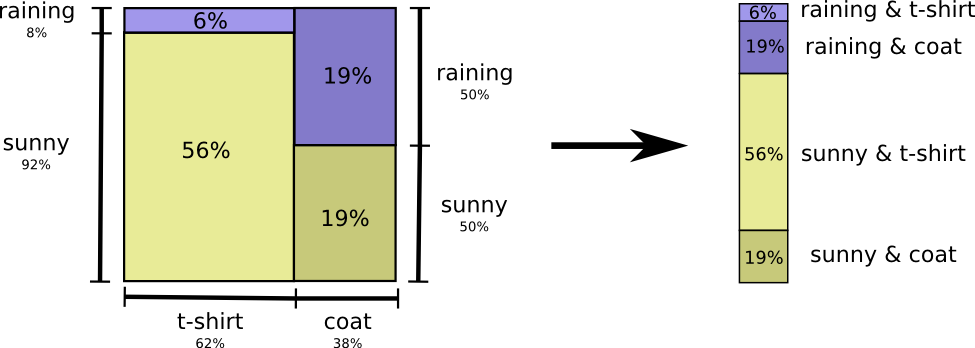
Agora podemos calcular as palavras de código ideais para eventos com essas probabilidades e calcular o tamanho médio da mensagem:
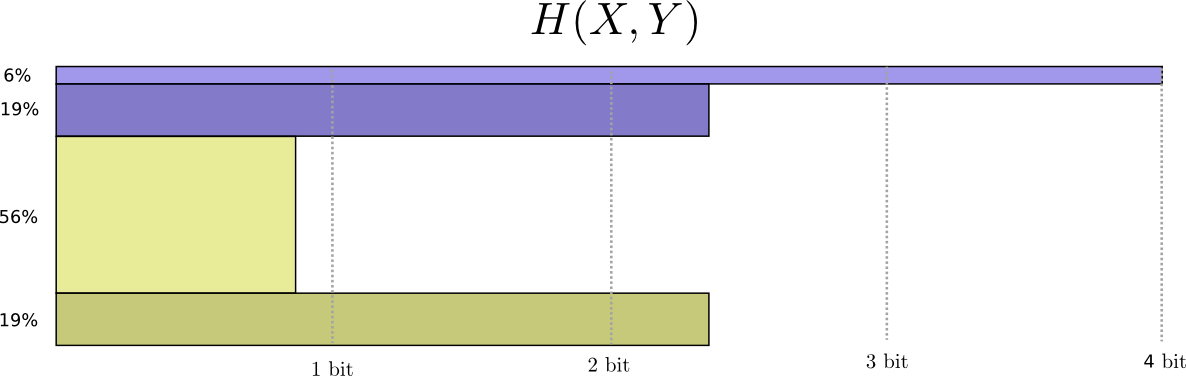
Chamamos isso de entropia conjunta
X e
Y definido da seguinte forma:
H(X,Y)= sumx,yp(x,y) log2 bigg( frac1p(x,y) bigg)
Isso coincide com a nossa definição usual, com exceção de duas variáveis em vez de uma.
Uma imagem um pouco melhor disso, sem igualar a distribuição, é obtida representando o comprimento da palavra de código na terceira dimensão. Agora entropia é volume!
Mas suponha que minha mãe já saiba o tempo. Ela pode vê-la no noticiário. Quanta informação eu preciso fornecer?
Parece que preciso enviar informações suficientes para me dizer quais roupas estou usando. Mas, na verdade, preciso enviar menos informações, porque o clima que vou vestir depende muito do clima! Vejamos o caso da chuva e do sol separadamente.
Nos dois casos, não preciso enviar muitas informações em média, porque o tempo me dá um bom palpite sobre qual será a resposta correta. Quando o sol, posso usar um código especial otimizado para o sol e, quando chove, posso usar o código otimizado para a chuva. Nos dois casos, envio menos informações do que se eu usasse código comum para ambos. Para obter a quantidade média de informações que preciso enviar para minha mãe, basta juntar esses dois casos ...
Chamamos isso de entropia condicional. Se você formalizá-lo em uma equação, obtém:
H(X|Y)= sumyp(y) sumxp(x|y) log2 bigg( frac1p(x|y) bigg)
= sumx,yp(x,y) log2 bigg( frac1p(x|y) bigg)
Informação mútua
Na seção anterior, descobrimos que conhecer uma variável pode significar que menos informações são necessárias para comunicar o valor de outra variável.
Uma boa maneira de pensar sobre isso é imaginar a quantidade de informações na forma de listras. Essas bandas se sobrepõem se houver informações comuns entre elas. Por exemplo, algumas das informações em
X e
Y comum, portanto
H(X) e
H(A) são listras sobrepostas. E desde
H(X,Y) É a informação de ambas as variáveis, então esta é a união das bandas
H(X) e
H(A) .
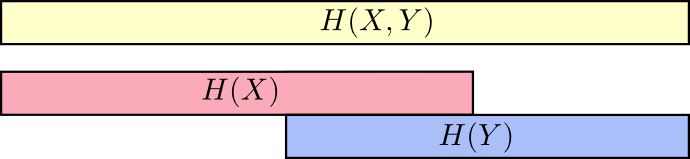
Quando pensamos nas coisas dessa maneira, muito fica mais fácil de ver.
Por exemplo, já observamos que transmitir informações como
X então e
Y ("Entropia conjunta",
H(X,Y) ) são necessárias mais informações do que apenas para transmissão
X ("Entropia final",
H(X) ) Mas se você já sabe
Y então para transmissão
X ("Entropia condicional",
H(X|Y) ) são necessárias menos informações do que se você não soubesse disso!
Parece complicado, mas se você se traduz em bandas, tudo acaba sendo muito simples.
H(X|Y) As informações que devemos enviar para informar
X quem já conhece
Y informação em
X que também não está
Y . Visualmente, isso significa que
H(X|Y) - isso faz parte da tira
H(X) que não se sobrepõe a
H(A) .
Agora você pode ler a desigualdade
H(X,Y)≥H(X)≥H(X|Y) bem no próximo gráfico.
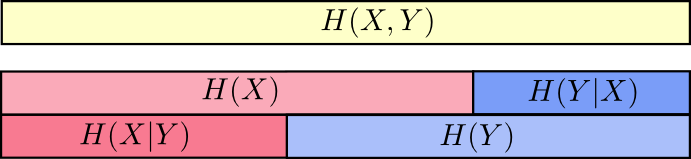
Outra igualdade é a seguinte -
H(X,Y)=H(Y)+H(X|Y) . I.e. informação em
X e
Y isso é informação em
Y além de informações em
X que não está em
Y .
Novamente, isso é difícil de ver nas equações, mas fácil de ver se você pensa em termos de faixas de informações sobrepostas.
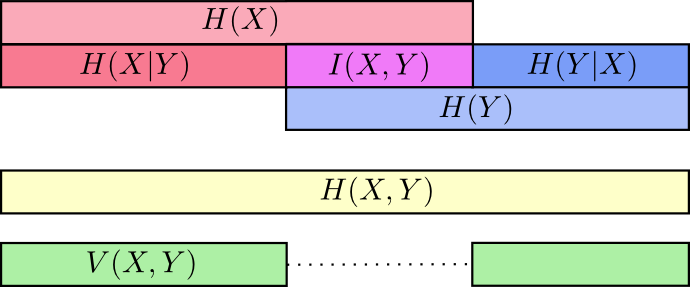
Nesse ponto, dividimos as informações em
X e
Y de várias maneiras. Conhecemos as informações em cada variável,
H(X) e
H(A) . Sabemos a combinação de informações em ambos
H(X,Y) . Temos informações que estão em uma variável, mas não em outra,
H(X|Y) e
H(Y|X) . Muito disso gira em torno de informações comuns a variáveis - a interseção de suas informações. Chamamos isso de "informação mútua"
I(x,y) definido como:
I(X,Y)=H(X)+H(Y)−H(X,Y)
Essa definição é verdadeira porque
H(X)+H(Y) contém duas cópias de informações mútuas, pois também estão localizadas em
X e em
Y enquanto
H(X,Y) contém apenas uma cópia. (veja o diagrama anterior)
A variação da informação está intimamente relacionada à informação mútua. Variação de informação é uma informação que não é comum a variáveis. Podemos defini-lo assim:
V(X,Y)=H(X,Y)−I(X,Y)
A variação da informação é interessante, pois nos fornece uma métrica, o conceito da distância entre diferentes variáveis. A variação das informações entre duas variáveis é igual a zero se o conhecimento do valor de uma variável indicar o significado da outra e aumentar, à medida que se tornarem mais independentes.
Como isso se relaciona com a divergência de KL, que também nos dá o conceito de distância? A divergência de KL é a distância entre duas distribuições sobre a mesma variável ou conjunto de variáveis. Pelo contrário, a variação de informações nos dá a distância entre duas variáveis co-distribuídas. A divergência de KL é uma discrepância entre distribuições, uma variação de informações dentro de uma distribuição.
Podemos reunir tudo isso em um único diagrama vinculando todos esses tipos diferentes de informações:
Bits de frações
Uma coisa muito pouco intuitiva na teoria da informação é que podemos ter números fracionários de bits. Isso é bem estranho. O que significa meio bit?
Aqui está uma resposta simples: geralmente estamos interessados no tamanho médio de uma mensagem, e não no tamanho de uma mensagem específica. Se na metade dos casos um bit for enviado e na metade dos casos dois, então, em média, um bit e meio será enviado. Não há nada estranho no fato de que as médias podem ser fracionárias.
Mas com esta resposta, evitamos a pergunta. Muitas vezes, os comprimentos ideais das palavras de código também são fracionários. O que isso significa?
Para ser específico, vejamos a distribuição de probabilidade, onde um evento,
a acontece 71% das vezes, e outro evento,
b ocorre 29% do tempo.
O código ideal usará 0,5 bits para representar
a e 1,7 bits para representar
b . Bem, se queremos enviar apenas uma dessas palavras de código, essa representação é impossível. Somos forçados a arredondar para um número inteiro de bits e enviar uma média de 1 bit.
... Mas se enviarmos várias mensagens ao mesmo tempo, podemos fazer melhor. Vamos considerar a transmissão de dois eventos dessa distribuição. Se os enviassemos de forma independente, teríamos que enviar dois bits. Como melhoramos isso?
Na metade dos casos, precisamos enviar
aa , em 21% dos casos -
ab ou
ba e em 8% dos casos -
bb . Novamente, um código ideal inclui bits fracionários.
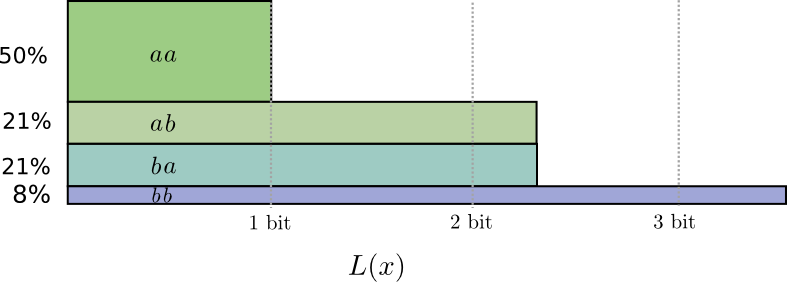
Se arredondarmos os comprimentos das palavras de código, obteremos algo assim:
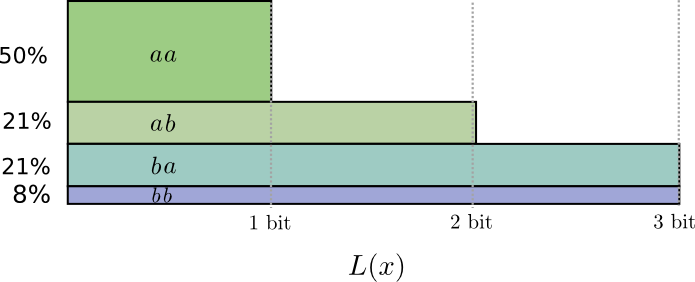
Esses códigos nos fornecem um tamanho médio de mensagem de 1,8 bits. Isso é inferior a 2 bits quando enviamos mensagens independentemente. I.e. nesse caso, enviamos em média 0,9 bits para cada evento. Se enviarmos mais eventos de uma só vez, a média seria ainda menor. At
n tendendo ao infinito, a sobrecarga associada ao arredondamento de nosso código desaparecerá e o número de bits por palavra de código convergirá para entropia.
Em seguida, observe que o comprimento ideal da palavra de código para o evento
a era de 0,5 bits e o comprimento ideal para a palavra-código
aa - 1 bit. Os comprimentos ideais das palavras de código aumentam, mesmo que sejam fracionários! Portanto, se relatarmos vários eventos de uma só vez, os comprimentos aumentarão.
Como podemos ver, existe um significado real para quantidades fracionárias de bits de informação, mesmo que os códigos reais possam usar apenas números inteiros.
(Na prática, as pessoas usam certos esquemas de codificação que são eficazes em diferentes casos. O código Huffman, que é realmente o tipo de código que esboçamos aqui, não lida com bits fracionários com muita elegância - você deve agrupar os caracteres como fizemos acima, ou usar truques mais complexos para se aproximar do limite de entropia. A codificação aritmética é um pouco diferente, ela processa elegantemente bits fracionários para ser assintoticamente ideal.)
Conclusão
Se estamos preocupados com a transferência de informações para o número mínimo de bits, essas idéias são, é claro, fundamentais. Se nos preocupamos com a compactação de dados, a teoria da informação resolve os principais problemas e fornece abstrações fundamentalmente corretas. Mas e se não nos importamos - isso não é exótico?
As idéias da teoria da informação aparecem em muitos contextos: aprendizado de máquina, física quântica, genética, termodinâmica e até jogos de azar. Os profissionais nessas áreas não se preocupam com a teoria da informação porque desejam compactar informações. Eles se preocupam com o fato de ter uma conexão irresistível com sua área. O entrelaçamento quântico pode ser descrito por entropia. Muitos resultados em mecânica estatística e termodinâmica podem ser obtidos assumindo a máxima entropia sobre coisas que você não conhece. Os ganhos e perdas de jogadores estão diretamente relacionados à divergência de KL, em particular, configurações iteradas.
A teoria da informação aparece em todos esses lugares porque oferece formalizações fundamentais e concretas para muitas coisas que devemos expressar. Ele nos fornece maneiras de medir e expressar incerteza, quão diferentes são os dois conjuntos de crenças e que a resposta a uma pergunta nos diz sobre a outra: quão dispersa é a probabilidade, a distância entre as distribuições de probabilidade e quão dependentes são as duas variáveis. Existem idéias alternativas e similares? Claro. Mas as idéias da teoria da informação são puras, possuem realmente boas propriedades e são baseadas em princípios. Em alguns casos, essas idéias são exatamente o que você precisa e, em outros casos, são um mediador conveniente em um mundo caótico.
O aprendizado de máquina é o que eu sei melhor, então vamos falar sobre isso um minuto. Um tipo muito comum de tarefa no aprendizado de máquina é a classificação. Suponha que desejemos olhar para uma figura e prever se será a figura de um cachorro ou gato. Nosso modelo pode dizer algo como: "Há uma probabilidade de 80% de ser uma imagem de um cachorro e uma probabilidade de 20% de ser um gato". Suponha que a resposta correta seja um cachorro - quão boa ou ruim é o que dissemos ser a probabilidade de um cachorro. O que é um cão 80%? Quanto melhor diria 85%?
Essa é uma pergunta importante porque precisamos de algumas dicas sobre o quão bom ou ruim é o nosso modelo, a fim de otimizá-lo para o sucesso. O que devemos otimizar? A resposta correta, na verdade, depende do motivo pelo qual usamos o modelo: nos preocupamos apenas se nosso palpite estava certo ou se preocupamos com a confiança que temos na resposta certa?
Quão ruim é ser confundido com confiança? Não existe uma resposta correta para isso. E, muitas vezes, é impossível encontrar a resposta certa, porque não sabemos exatamente como o modelo será usado para formalizar o que nos excita. Há situações em que a entropia cruzada é exatamente o que nos preocupa, mas esse nem sempre é o caso. Com mais frequência, não sabemos exatamente o que nos preocupa, e a entropia cruzada é realmente uma boa proxy.As informações nos fornecem uma nova base forte para pensar sobre o mundo. Às vezes, é ideal para uma determinada tarefa; em outros casos, não exatamente, mas ainda extremamente útil. Este ensaio apenas arranhou a superfície da teoria da informação - existem tópicos principais, como códigos de correção de erros, sobre os quais não tocamos, mas espero ter demonstrado que a teoria da informação é um assunto maravilhoso que não deve ser intimidador.