Olá Habr! Meu nome é Denis Kopyrin e hoje quero falar sobre como resolvemos o problema de backup sob demanda no macOS. De fato, uma tarefa interessante que encontrei no instituto acabou se transformando em um grande projeto de pesquisa sobre como trabalhar com o sistema de arquivos. Todos os detalhes estão sob o corte.

Não vou começar de longe, só posso dizer que tudo começou com um projeto no Instituto de Física e Tecnologia de Moscou, que desenvolvi com meu supervisor no departamento da Acronis. Tivemos a tarefa de organizar o armazenamento remoto de arquivos, ou melhor, manter o status atual de seus backups.
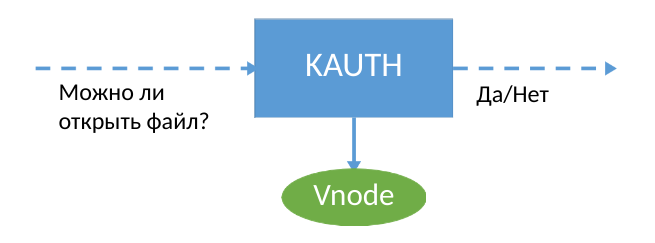
Para garantir a segurança dos dados, usamos a extensão do kernel do macOS, que coleta informações sobre eventos no sistema. O KPI para desenvolvedores tem uma API do KAUTH, que permite receber notificações sobre como abrir e fechar um arquivo - é tudo. Se você usar o KAUTH, salve o arquivo completamente ao abri-lo para gravação, porque os eventos de gravação no arquivo não estão disponíveis para os desenvolvedores. Essa informação não foi suficiente para nossas tarefas. De fato, para complementar permanentemente uma cópia de backup dos dados, você precisa entender exatamente onde o usuário (ou malware :) gravou os novos dados no arquivo.
Mas qual dos desenvolvedores estava assustado com as restrições do sistema operacional? Se a API do kernel não permitir que você obtenha informações sobre operações de gravação, será necessário criar sua própria maneira de interceptar através de outras ferramentas do kernel.
A princípio, não queríamos consertar o núcleo e suas estruturas. Em vez disso, eles tentaram criar um volume virtual inteiro que nos permitisse interceptar todas as solicitações de leitura e gravação que passassem por ele. Mas ele revelou um recurso desagradável do macOS: o sistema operacional acredita que não possui 1, mas 2 unidades flash USB, dois discos e assim por diante. E pelo fato de o segundo volume mudar ao trabalhar com o primeiro, o macOS começa a funcionar incorretamente com as unidades. Havia tantos problemas com esse método que tive que abandoná-lo.
Procure outra solução
Apesar das limitações do KAUTH, esse KPI permite que você seja notificado sobre o uso de um arquivo para gravação antes de todas as operações. Os desenvolvedores têm acesso à abstração do arquivo BSD no kernel - vnode. Por incrível que pareça, o patch do vnode é mais fácil do que usar a filtragem de volume. A estrutura vnode possui uma tabela de funções que fornecem trabalho com arquivos reais. Portanto, tivemos a ideia de substituir esta tabela.
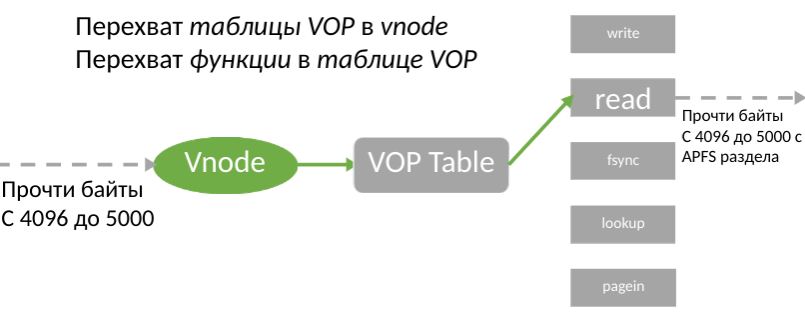
A ideia foi imediatamente considerada uma boa ideia, mas para sua implementação foi necessário encontrar a própria tabela na estrutura do vnode, pois a Apple não documenta sua localização em nenhum lugar. Para fazer isso, foi necessário estudar o código de máquina do kernel e também descobrir se é possível gravar nesse endereço para que o sistema não morra depois disso.
Se a tabela for encontrada, basta copiá-la na memória, substituir o ponteiro e colar o link da nova tabela no vnode existente. Graças a isso, todas as operações com arquivos passarão pelo nosso driver e poderemos registrar todas as solicitações de usuários, incluindo leitura e gravação. Portanto, a busca pela tabela estimada se tornou nosso principal objetivo.
Dado que a Apple realmente não quer isso, para resolver o problema, você precisa tentar "adivinhar" o local da tabela usando heurísticas para o local relativo dos campos ou assumir uma função já conhecida, desmontá-lo e procurar um desvio dessas informações.
Como procurar um deslocamento: uma maneira fácilA maneira mais simples de encontrar desvios de tabela no vnode é uma heurística baseada na localização dos campos em uma estrutura (
link para o Github ).
struct vnode { ... int (**v_op)(void *); mount_t v_mount; ... }
Usaremos a suposição de que o campo v_op de que precisamos é exatamente 8 bytes removidos do v_mount. O valor deste último pode ser obtido usando KPI público (
link para Github ):
mount_t vnode_mount(vnode_t vp);
Conhecendo o valor de v_mount, começaremos a procurar uma “agulha no palheiro” - perceberemos o valor do ponteiro para o vnode 'vp' como uintptr_t *, o valor de vnode_mount (vp) como uintptr_t. Isso é seguido por iterações para o valor "razoável" de i, até que a condição 'palheiro [i] == agulha' seja cumprida. E se a suposição sobre a localização dos campos estiver correta, o deslocamento v_op será i-1.
void* getVOPPtr(vnode_t vp) { auto haystack = (uintptr_t*) vp; auto needle = (uintptr_t) vnode_mount(vp); for (int i = 0; i < ATTEMPTCOUNT; i++) { if (haystack[i] == needle) { return haystack + (i - 1); } } return nullptr; }
Como procurar um deslocamento: desmontagemApesar de sua simplicidade, o primeiro método tem uma desvantagem significativa. Se a Apple alterar a ordem dos campos na estrutura do vnode, o método simples será interrompido. Um método mais universal, mas menos trivial, é desmontar dinamicamente o kernel.
Por exemplo, considere a função desmontada do kernel VNOP_CREATE (
link para Github ) no macOS 10.14.6. As instruções que são interessantes para nós são marcadas com uma seta ->.
_VNOP_CREATE:
1 push rbp
2 mov rbp, rsp
3 push r15
4 push r14
5 push r13
6 push r12
7 push rbx
8 sub rsp, 0x48
9 mov r15, r8
10 mov r12, rdx
11 mov r13, rsi
-> 12 mov rbx, rdi
13 lea rax, qword [___stack_chk_guard]
14 mov rax, qword [rax]
15 mov qword [rbp+-48], rax
-> 16 lea rax, qword [_vnop_create_desc] ; _vnop_create_desc
17 mov qword [rbp+-112], rax
18 mov qword [rbp+-104], rdi
19 mov qword [rbp+-96], rsi
20 mov qword [rbp+-88], rdx
21 mov qword [rbp+-80], rcx
22 mov qword [rbp+-72], r8
-> 23 mov rax, qword [rdi+0xd0]
-> 24 movsxd rcx, dword [_vnop_create_desc]
25 lea rdi, qword [rbp+-112]
-> 26 call qword [rax+rcx*8]
27 mov r14d, eax
28 test eax, eax
…. errno_t VNOP_CREATE(vnode_t dvp, vnode_t * vpp, struct componentname * cnp, struct vnode_attr * vap, vfs_context_t ctx) { int _err; struct vnop_create_args a; a.a_desc = &vnop;_create_desc; a.a_dvp = dvp; a.a_vpp = vpp; a.a_cnp = cnp; a.a_vap = vap; a.a_context = ctx; _err = (*dvp->v_op[vnop_create_desc.vdesc_offset])(&a;); …
Analisaremos as instruções do assembler para encontrar a mudança no vnode dvp. O "objetivo" do código do assembler é chamar uma função da tabela v_op. Para fazer isso, o processador deve seguir estas etapas:
- Carregar dvp para se registrar
- Desreferenciando-o para obter v_op (linha 23)
- Obter vnop_create_desc.vdesc_offset (linha 24)
- Chamar uma função (linha 26)
Se tudo estiver claro nos passos 2 a 4, surgirão dificuldades no primeiro passo. Como entender em que registro o dvp foi carregado? Para fazer isso, usamos um método de emular uma função que monitora os movimentos do ponteiro desejado. De acordo com a convenção de chamada do System V x86_64, o primeiro argumento é passado no registro rdi. Portanto, decidimos acompanhar todos os registros que contêm rdi. No meu exemplo, esses são os registros rbx e rdi. Além disso, uma cópia do registro pode ser salva na pilha, encontrada na versão de depuração do kernel.
Sabendo que os registradores rbx e rdi armazenam dvp, descobrimos que a linha 23 desreferenciou vnode para obter v_op. Portanto, assumimos que o deslocamento na estrutura é 0xd0. Para confirmar a decisão correta, continuamos a digitalizar e garantir que a função seja chamada corretamente (linhas 24 e 26).
Este método é mais seguro, mas, infelizmente, também tem desvantagens. Temos que confiar no fato de que o padrão da função (ou seja, os quatro passos que falamos acima) serão os mesmos. No entanto, a probabilidade de alterar o padrão da função é uma ordem de magnitude menor que a probabilidade de alterar a ordem dos campos. Então decidimos parar no segundo método.
Substitua os ponteiros na tabela
Depois de encontrar v_op, surge a pergunta: como usar esse ponteiro? Existem duas maneiras diferentes - substituir a função na tabela (terceira seta na figura) ou substituir a tabela no vnode (segunda seta na figura).
A princípio, parece que a primeira opção é mais lucrativa, porque precisamos apenas substituir um ponteiro. No entanto, esta abordagem tem 2 desvantagens significativas. Primeiramente, a tabela v_op é a mesma para todos os vnode de um determinado sistema de arquivos (v_op para HFS +, v_op para APFS, ...), portanto, a filtragem por vnode é necessária, o que pode ser muito caro - você terá que filtrar vnode extra em cada operação de gravação. Em segundo lugar, a tabela está gravada na página Somente Leitura. Essa limitação pode ser contornada se você usar a gravação via IOMappedWrite64, ignorando as verificações do sistema. Além disso, se o kext com o driver do sistema de arquivos for enviado, será difícil descobrir como remover o patch.
A segunda opção acaba sendo mais direcionada e segura - o interceptador será chamado apenas para o vnode necessário, e a memória vnode inicialmente permite operações de leitura e gravação. Como toda a tabela está sendo substituída, é necessário alocar um pouco mais de memória (80 funções em vez de uma). E como o número de tabelas geralmente é igual ao número de sistemas de arquivos, o limite de memória é completamente insignificante.
É por isso que o kext usa o segundo método, embora, repito, à primeira vista, parece que essa opção seja pior.
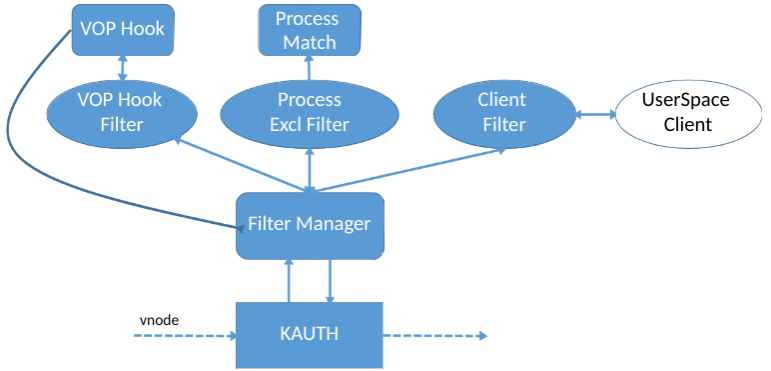
Como resultado, nosso driver funciona da seguinte maneira:
- A API do KAUTH fornece vnode
- Estamos substituindo a tabela vnode. Se necessário, interceptamos operações apenas para o vnode "interessante", por exemplo, documentos do usuário
- Ao interceptar, verificamos qual processo está gravando, filtramos "nosso"
- Enviamos uma solicitação síncrona do UserSpace ao cliente, que decide o que exatamente precisa ser salvo.
O que aconteceu
Hoje, temos um módulo experimental, que é uma extensão do kernel do macOS e leva em consideração as alterações no sistema de arquivos no nível granular. Vale ressaltar que no macOS 10.15, a Apple introduziu uma nova estrutura (
link para EndpointSecurity ) para receber notificações sobre alterações no sistema de arquivos, planejadas para uso no Active Protection, portanto, a solução descrita no artigo foi declarada obsoleta.