Há momentos em que você precisa restringir o acesso dos usuários a alguns dados no cubo. Parece que não há nada de complicado: instale os filtros de linha em funções e pronto, mas há um problema - o filtro apara os dados da tabela e acontece que você pode ver a velocidade apenas pelas linhas disponíveis e precisamos de toda a velocidade, mas os detalhes devem estar disponíveis para alguns deles.
Por exemplo, o usuário deve ver a rotatividade de todos os produtos, com a possibilidade de obter detalhes completos sobre eles, mas, ao mesmo tempo, os clientes não devem exibir todos, mas apenas alguns, ou todos os clientes, mas com dados parcialmente ocultos em alguns atributos (campos).
Para impedir que o usuário visualize a rotatividade em termos de clientes, você pode superar isso através de fórmulas em medidas e exibir um valor vazio se o usuário tentar ver a rotatividade de um cliente específico, uma dessas opções é descrita
aqui . No entanto, este não é o caso. Quando algumas dezenas de medidas, escreva uma fórmula em cada uma delas ... e se você esquecer? Mas você certamente esquecerá isso algum dia ... E se o usuário precisar de dados do cartão de um cliente específico, nada o impedirá de ver isso sem escolher uma medida de filtragem. O que fazer?
Precisávamos alcançar essa exibição:
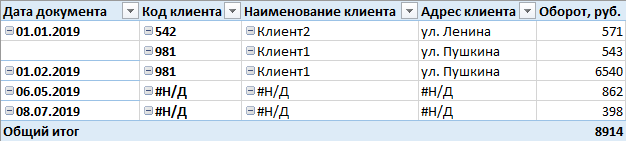
Todo o princípio que permite obter um resultado semelhante é baseado em um pequeno truque e consiste em adicionar linhas sintéticas à tabela (clientes, neste caso) para que o registro sobre a mesma entidade seja duplicado pelo menos uma vez - o primeiro conterá informações completas e a segunda na maioria das colunas é preenchida com um plug-in
# N / A , mas os identificadores são os mesmos para os dois registros. Além disso, usando o filtro em funções e uma coluna especial pela qual a filtragem é realizada, deixamos certas linhas disponíveis para o usuário - uma linha com campos completamente preenchidos ou com stubs. E desde Como o cubo tem o recurso de "recolher" dados repetidos e o usuário não pode acessar outros atributos que fornecem valores exclusivos, na tabela resultante todos os clientes com o código
# N / A se transformarão em uma linha. Eu acho que nesta fase tudo já está muito claro, você não pode mais ler. O resultado está no título do artigo.
Mas se alguém precisar de detalhes - eu os tenho.
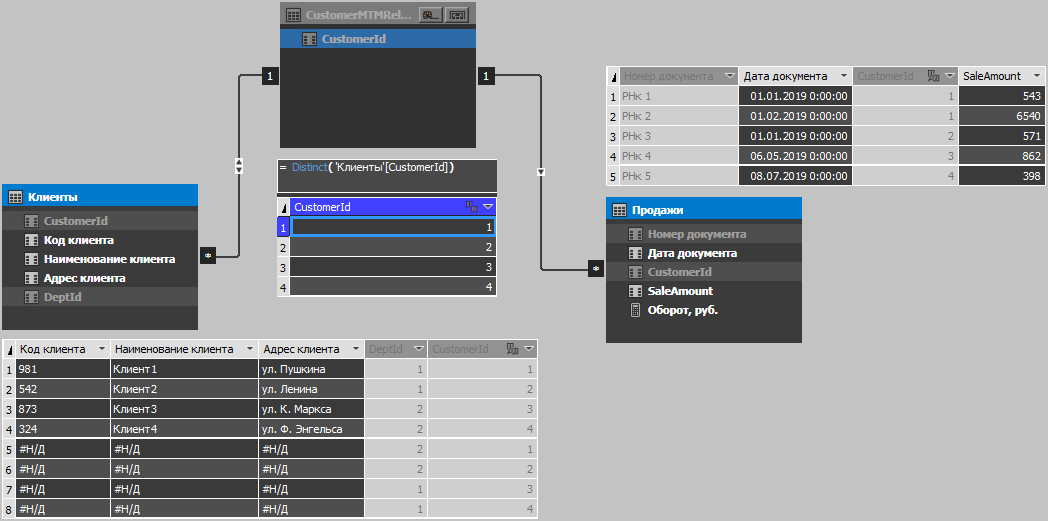
Os modelos de tabela até a versão 1400 (inclusive SQL 2017) não permitem a criação de relacionamentos muitos-para-muitos, mas, no caso de duplicatas, precisamos desse relacionamento; portanto, criaremos através de uma tabela intermediária contendo apenas uma coluna com identificadores exclusivos de clientes. A tabela é inicialmente incompressível, pois ele contém apenas valores únicos, para que você possa calculá-lo, porque nesse caso não ganharemos nada se o preenchermos com t-sql (lembre-se do princípio de processamento e da ordem de compactação da tabela?). Apenas devido à capacidade do mecanismo de compactar dados duplicados, a quantidade de dados no cubo aumentará um pouco e, devido à filtragem na função, a sessão do usuário tem um conjunto reduzido de registros, ou seja, o número final de registros após a filtragem do conjunto permanecerá como estava sem duplicatas. Portanto, não se preocupe, mesmo que a tabela seja inicialmente grande o suficiente, a adição de duplicatas não afetará o desempenho e o volume de maneira significativa (é claro, os casos são diferentes, mas na maioria deles tudo será exatamente isso).
A figura a seguir mostra o modelo do cubo e o conteúdo da tabela:
Por exemplo, adicione um filtro simples:

Só isso.
Gostaria de alertar sobre um recurso do uso dessa abordagem. Usuários que são administradores no servidor SSAS, por padrão, entram no cubo ignorando todos os tipos de funções, mesmo que seus nomes sejam especificados nessas funções. Isso leva ao fato de que os filtros de função não funcionam e, sob o administrador, todas as duplicatas são visíveis. Mas não se desespere, basta na cadeia de conexão indicar explicitamente qual papel usar e tudo se encaixa; além disso, ao testar, você precisará alternar entre os papéis mais de uma vez.
Como você entende, você pode fazer várias combinações do mesmo registro com diferentes graus de plenitude das colunas com dados reais. Você também pode criar uma tabela oculta separada no cubo, que será preenchida com contas via ADSI, distribuir usuários para diferentes grupos de domínio e preencher esta tabela dependendo das combinações de associação de usuários em determinados grupos. Nós escrevemos os links nos filtros de função linha por linha nesta tabela, o que nos permitirá controlar as medições e também podemos nos referir a ele em medidas, para que, se necessário, algumas medidas mostrem vazio. Com essa organização, é obtido o ajuste fino dos direitos de acesso aos dados e tudo é armazenado em um só lugar. Mas há uma nuance nas medidas: se um usuário avançado escreve consultas no próprio cubo, nada o impede de usar sua medida, sem indicadores, desde que ele saiba os nomes das colunas base e da fórmula ... Embora, se desejado, você pode fazê-lo aqui restrição, mas esse é outro tópico.