Todo mundo fala sobre os processos de desenvolvimento e teste, treinamento da equipe, motivação crescente, mas esses processos são poucos quando um minuto de inatividade do serviço custa espaço em dinheiro. O que fazer quando você realiza transações financeiras sob um SLA rígido? Como aumentar a confiabilidade e a tolerância a falhas de seus sistemas, descrevendo o desenvolvimento e os testes?

A próxima conferência HighLoad ++ será realizada nos dias 6 e 7 de abril de 2020 em São Petersburgo. Detalhes e ingressos
aqui . 9 de novembro, 18:00. HighLoad ++ Moscou 2018, Delhi + Calcutta Hall. Resumos e
apresentação .
Evgeny Kuzovlev (a seguir denominada CE): - Amigos, olá! Meu nome é Kuzovlev Evgeny. Eu sou da EcommPay, uma divisão específica é a EcommPay IT, uma divisão de TI de um grupo de empresas. E hoje falaremos sobre períodos de inatividade - como evitá-los, como minimizar suas consequências, se você não puder evitá-las. O tema é: "O que fazer quando um minuto de inatividade custa US $ 100.000?" Para nós, olhando para o futuro, os números são comparáveis.
O que o EcommPay IT faz?
Quem somos Por que estou na sua frente? Por que tenho o direito de lhe dizer uma coisa aqui? E sobre o que falaremos com mais detalhes aqui?

O Grupo de Empresas EcommPay é um adquirente internacional. Processamos pagamentos em todo o mundo - na Rússia, na Europa e no Sudeste Asiático (em todo o mundo). Temos 9 escritórios, 500 funcionários no total e cerca de um pouco menos da metade deles são especialistas em TI. Tudo o que fazemos, tudo em que ganhamos dinheiro, fizemos nós mesmos.
Temos todos os nossos produtos (e muitos deles - na linha de grandes produtos de TI, temos cerca de 16 componentes diferentes) que escrevemos; nós nos escrevemos, nos desenvolvemos. E, no momento, estamos realizando cerca de um milhão de transações por dia (milhões - provavelmente será correto dizer isso). Somos uma empresa jovem o suficiente - temos apenas seis anos de idade.
Há 6 anos, era uma startup tão grande quando os caras vieram junto com o negócio. Eles estavam unidos por uma idéia (não havia mais nada além de uma idéia), e nós corremos. Como qualquer startup, corremos mais rápido ... Para nós, a velocidade era mais importante que a qualidade.
Em algum momento, paramos: percebemos que não podíamos mais viver nessa velocidade e com essa qualidade, e precisávamos fazer qualidade em primeiro lugar. Nesse ponto, decidimos escrever uma nova plataforma que seja correta, escalável e confiável. Eles começaram a escrever essa plataforma (começaram a investir, desenvolver desenvolvimento, testar), mas em algum momento perceberam que o desenvolvimento e o teste não permitiam alcançar um novo nível de qualidade de serviço.
Você cria um novo produto, coloca-o em produção, mas ainda em algum lugar, algo dá errado. E hoje falaremos sobre como alcançar um novo nível qualitativo (como o alcançamos, sobre nossa experiência), tirando o desenvolvimento e os testes de cena; falaremos sobre o que está disponível para exploração - o que a exploração pode fazer por si só, o que ela pode oferecer testes para afetar a qualidade.
Paradas. Os mandamentos da exploração.
Sempre a principal pedra angular da qual falaremos hoje é o tempo de inatividade. Palavra assustadora. Se tivemos um tempo de inatividade, tudo está ruim conosco. Estamos correndo para aumentar, os administradores estão mantendo o servidor - Deus o livre, ele não cai, como naquela música. É sobre isso que falaremos hoje.

Quando começamos a mudar nossa abordagem, formamos 4 mandamentos. Eles são apresentados nos meus slides:
Esses mandamentos são bastante simples:

- Identifique rapidamente o problema.
- Livre-se ainda mais rápido.
- Ajude a entender o motivo (posteriormente, para desenvolvedores).
- E padronizar abordagens.
Chamo sua atenção para o ponto número 2. Nós nos livramos do problema, mas não o resolvemos. Decidir é a segunda vez. A principal coisa para nós é que o usuário está protegido contra esse problema. Ele existirá em um determinado ambiente isolado, mas esse ambiente não entrará em contato com ele. Na verdade, passaremos por esses quatro grupos de problemas (para alguns com mais detalhes, para outros com menos detalhes), vou lhe dizer o que usamos, que tipo de experiência temos na solução.
Solução de problemas: quando eles acontecem e o que fazer com eles?
Mas vamos começar fora de ordem, começamos com o ponto número 2 - como se livrar rapidamente do problema? Há um problema - precisamos corrigi-lo. "O que devemos fazer com isso?" É a questão principal. E quando começamos a pensar em como corrigir o problema, desenvolvemos alguns requisitos que a solução de problemas deveria seguir.

Para formular esses requisitos, decidimos nos perguntar: "E quando temos problemas"? E os problemas, como se viu, são encontrados em quatro casos:

- Mau funcionamento do hardware.
- Falha nos serviços externos.
- Alteração da versão do software (a mesma implantação).
- Crescimento de carga explosiva.
Nós não vamos falar sobre os dois primeiros. Um mau funcionamento do hardware é resolvido de maneira simples: você deve duplicar tudo. Se estes são discos - os discos devem ser montados no RAID, se for um servidor - o servidor deve ser duplicado, se você tiver uma infraestrutura de rede - você deve colocar uma segunda cópia da infraestrutura de rede, ou seja, pegar e duplicar. E se algo falhar com você, você muda para reservar capacidades. É difícil dizer mais aqui.
O segundo é a falha de serviços externos. Para a maioria, o sistema não é um problema, mas não para nós. Como processamos pagamentos, somos um agregador que fica entre o usuário (que insere os detalhes do cartão) e os bancos, sistemas de pagamento ("Visa", "MasterCard", "World" do mesmo). Nossos serviços externos (sistemas de pagamento, bancos) tendem a falhar. Nem nós nem você (se você tiver esses serviços) podemos influenciar isso.
O que fazer então? Existem duas opções. Primeiro, se você puder, você deve duplicar este serviço de alguma forma. Por exemplo, se pudermos, transferimos o tráfego de um serviço para outro: processamos, por exemplo, cartões através do Sberbank, o Sberbank tem problemas - transferimos o tráfego [condicionalmente] para o Raiffeisen. A segunda coisa que podemos fazer é notar rapidamente a falha de serviços externos e, portanto, falaremos sobre a velocidade da reação na próxima parte do relatório.
De fato, desses quatro, podemos afetar especificamente a alteração das versões de software - para executar ações que levarão a uma melhoria no contexto de implantações e no contexto de crescimento explosivo de carga. Na verdade, nós fizemos isso. Aqui, novamente, uma pequena observação ...
Desses quatro problemas, vários são resolvidos imediatamente se você tiver uma nuvem. Se você estiver nas nuvens Microsoft Azhur, Ozone, use nossas nuvens, do Yandex ou do Mail, pelo menos um mau funcionamento do hardware se tornará um problema e tudo imediatamente se tornará bom no contexto de um mau funcionamento do hardware.
Somos uma empresa pouco padronizada. Aqui todo mundo está falando sobre Kubernets, sobre nuvens - não temos nem Kubernets, nem nuvens. Mas temos racks com ferro em muitos data centers e somos forçados a viver com esse ferro, somos forçados a responder por tudo. Portanto, neste contexto, conversaremos. Então, sobre os problemas. Os dois primeiros estão entre colchetes.
Mude a versão do software. Bases
Nossos desenvolvedores não têm acesso à produção. Porque Mas somos simplesmente certificados pelo PCI DSS, e nossos desenvolvedores simplesmente não têm o direito de entrar no "prod". É isso aí, ponto final. Absolutamente. Portanto, a responsabilidade do desenvolvimento termina exatamente no momento em que o desenvolvimento passou a construção para o release.

Nossa segunda base, que temos, que também nos ajuda muito, é a falta de conhecimento único e não documentado. Espero que você faça o mesmo. Porque se não for assim, você terá problemas. Os problemas surgirão quando esse conhecimento único e não documentado não estiver presente no momento certo, no lugar certo. Suponha que você tenha uma pessoa que saiba como implantar um componente específico - não há ninguém, ele esteja de férias ou adoeceu - isso é tudo, você tem problemas.
E a terceira base para a qual chegamos. Chegamos a ele com dor, sangue, lágrimas - chegamos à conclusão de que qualquer uma de nossas construções contém erros, mesmo que sem erros. Decidimos isso por nós mesmos: quando implementamos algo, quando lançamos algo no produto - temos uma compilação com erros. Nós formamos os requisitos que nosso sistema deve atender.
Requisitos de alteração de versão de software
Existem três destes requisitos:

- Devemos reverter rapidamente a implantação.
- Devemos minimizar o impacto de uma implantação malsucedida.
- E precisamos ser capazes de ficar presos rapidamente em paralelo.
Nessa ordem! Porque Porque, em primeiro lugar, ao implantar a nova versão, a velocidade não é importante, mas é importante para você, se algo der errado, reverta rapidamente e tenha um impacto mínimo. Mas se você tiver um conjunto de versões na produção, para as quais ocorreu um erro (como neve em sua cabeça, não houve implantação, mas o erro está contido) - a velocidade da implantação subsequente é importante para você. O que fizemos para atender a esses requisitos? Recorremos a essa metodologia:
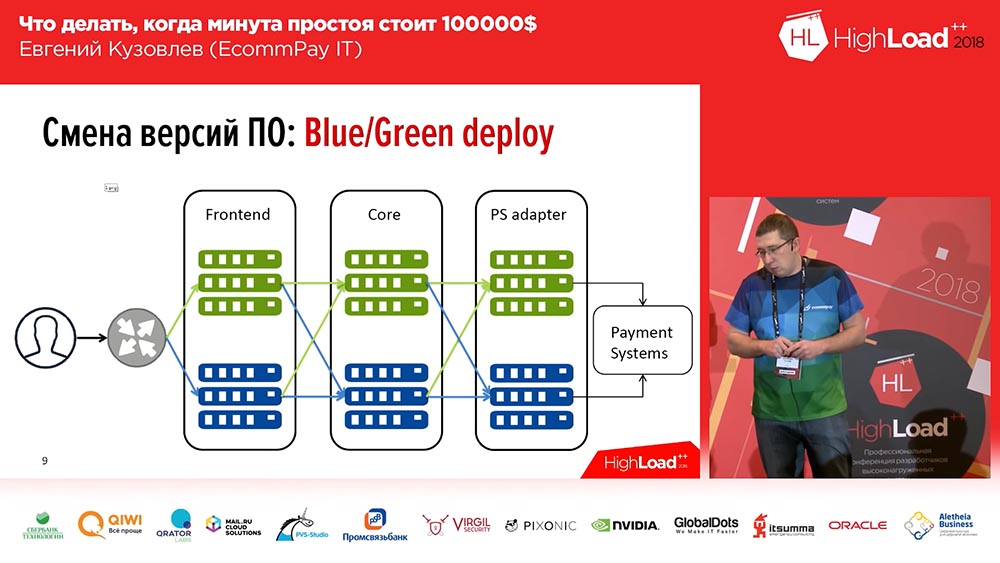
É sabido que não inventamos uma única vez - esse é o implante azul / verde. O que é isso Você deve ter uma cópia para cada grupo de servidores nos quais seus aplicativos estão instalados. A cópia está “quente”: não há tráfego, mas a qualquer momento esse tráfego pode ser enviado para esta cópia. Esta cópia contém a versão anterior. E no momento da implantação, você lança o código em uma cópia inativa. Em seguida, alterne parte do tráfego (ou todo) para a nova versão. Portanto, para alterar o fluxo de tráfego da versão antiga para a nova, você só precisa executar uma ação: você precisa alterar o balanceador no upstream, alterar a direção - de um upstream para outro. Isso é muito conveniente e resolve o problema de troca rápida e reversão rápida.
Aqui, a solução para a segunda pergunta é a minimização: você pode colocar em uma nova linha, em uma linha com um novo código, apenas parte do seu tráfego (deixe, por exemplo, 2%). E esses 2% - eles não são 100%! Se você perdeu 100% do tráfego durante uma implantação malsucedida - isso é assustador, se você perdeu 2% do tráfego - isso é desagradável, mas não é assustador. Além disso, os usuários provavelmente nem perceberão isso, porque em alguns casos (nem todos) o mesmo usuário, pressionando F5, ele chegará a outra versão funcional.
Implantação azul / verde. Encaminhamento
Além disso, nem tudo é tão simples "Implantação Azul / Verde" ... Todos os nossos componentes podem ser divididos em três grupos:
- Este é o frontend (páginas de pagamento que nossos clientes veem);
- núcleo de processamento;
- um adaptador para trabalhar com sistemas de pagamento (bancos, MasterCard, Visa ...).
E há uma nuance - a nuance é o roteamento entre as linhas. Se você simplesmente alternar 100% do tráfego, não terá esses problemas. Mas se você deseja alternar 2%, as perguntas começam: “Como fazer isso?” A coisa mais simples na testa: você pode, aleatoriamente, configurar Round Robin no nginx, e você tem 2%, 98% - para a direita. Mas isso nem sempre é adequado.
Aqui, por exemplo, o usuário interage com o sistema em mais de uma solicitação. Isso é normal: 2, 3, 4, 5 consultas - seus sistemas podem ser os mesmos. E se for importante para você que todas as solicitações do usuário cheguem à mesma linha em que a primeira solicitação chegou, ou (no segundo momento) todas as solicitações do usuário cheguem a uma nova linha após a troca (ele poderia trabalhar mais cedo com o sistema, antes da troca), - então essa distribuição aleatória não combina com você. Depois, existem as seguintes opções:

A primeira opção, a mais fácil - com base nos parâmetros básicos do cliente (IP Hash). Você tem um IP e compartilha da direita para a esquerda por IP. Então, o segundo caso descrito por mim funcionará para você quando houver uma implantação, o usuário já poderá começar a trabalhar com seu sistema e, a partir do momento da implantação, todas as solicitações serão direcionadas para uma nova linha (por exemplo, a mesma).
Se, por algum motivo, isso não lhe agradar e você precisar enviar solicitações para a linha em que a solicitação íntima principal do usuário veio, você tem duas opções ...
A primeira opção: você pode receber nginx + pago. Existe um mecanismo de sessões fixas, que, mediante solicitação inicial do usuário, expõe uma sessão ao usuário e a vincula a um determinado montante. Todas as solicitações subsequentes do usuário durante a vida útil da sessão irão para o mesmo upstream em que a sessão foi configurada.
Isso não nos convinha, porque já tínhamos nginx normal. Mudar o nginx + não é caro, apenas foi um pouco doloroso para nós e não muito certo. Por exemplo, “Sticks Sessions” não funcionou para nós pelo simples motivo de que “Sticks Sessions” não oferece uma oportunidade de roteamento com base em “Eli-or”. Lá, você pode especificar o que fazemos "Sessões permanentes", por exemplo, por IP ou IP e por cookie ou por parâmetro de postagem, mas "Eli-or" já é mais complicado lá.
Portanto, chegamos à quarta opção. Pegamos o nginx em "esteróides" (isto é openresty) - este é o mesmo nginx que também oferece suporte à inclusão dos últimos scripts. Você pode escrever um último script, deslizar para “aberto” e esse último script será executado quando uma solicitação do usuário chegar.
E nós escrevemos, de fato, um script desse tipo, nos definimos como "openrest" e nesse script classificamos 6 parâmetros diferentes para a concatenação de "Or". Dependendo da disponibilidade deste ou daquele parâmetro, sabemos que o usuário chegou a uma página ou a outra, a uma linha ou a outra.
Implantação azul / verde. Vantagens e desvantagens
É claro que provavelmente poderíamos facilitar um pouco (use as mesmas “sessões fixas”), mas ainda temos uma nuance que não apenas o usuário interage conosco no âmbito de um processamento de uma transação ... Mas os sistemas de pagamento também interagem conosco: depois de processarmos a transação (enviando uma solicitação ao sistema de pagamento), obtemos um retorno de chamada.
E suponha que, dentro do nosso circuito, possamos executar o endereço IP do usuário em todas as solicitações e separar usuários com base no endereço IP, então não diremos o mesmo “Visa”: “Caras, somos uma empresa tão retro, somos meio internacionais (no site e em Da Rússia) ... E, por favor, dê uma olhada no endereço IP do usuário em um campo adicional, seu protocolo é padronizado! ” Negócio claro, eles não vão concordar.

Portanto, para nós, não se encaixava - nós abrimos espaço. Assim, com o roteamento, chegamos assim:
O Blue / Green Deploy tem, respectivamente, as vantagens de que falei e as desvantagens.
Desvantagem dois:
- você precisa se preocupar com o roteamento;
- a segunda principal desvantagem é o custo.
Você precisa do dobro de servidores, do dobro de recursos operacionais, do esforço para manter todo esse zoológico.
A propósito, entre as vantagens, há outra coisa que eu não mencionei antes: você tem uma reserva em caso de aumento de carga. Se você tiver um crescimento explosivo de carga, um grande número de usuários cairá sobre você, basta incluir a segunda linha na distribuição de 50 a 50 - e você terá imediatamente 2 servidores no cluster até resolver o problema de ter servidores ainda.
Como fazer uma implantação rápida?
Falamos sobre como resolver o problema de minimização e reversão rápida, mas a pergunta permanece: "Como implantar rapidamente?"

Aqui é breve e simples.
- Você deve ter um sistema de CD (Entrega contínua) - sem ele, em lugar nenhum. Se você tiver um servidor, poderá ficar preso com canetas. Temos cerca de mil e meio servidores e 1.500 alças, é claro - podemos plantar um departamento do tamanho desta sala, apenas para implantar.
- A implantação deve ser paralela. Se você tem uma implantação consistente, tudo está ruim. Um servidor é normal, você implantará mil e meio servidores o dia todo.
- Novamente, para acelerar, isso não é mais necessário, provavelmente. Quando desploey geralmente constrói o projeto. Você tem um projeto da Web, existe uma parte de front-end (você faz um pacote da Web lá, o npm coleta algo assim) e esse processo, em princípio, tem vida curta - 5 minutos, mas esses 5 minutos podem ser críticos. Portanto, por exemplo, não fazemos isso: removemos esses 5 minutos, implantamos artefatos.
O que é um artefato? Um artefato é uma construção montada na qual toda a peça da montagem já foi concluída. Armazenamos esse artefato no armazenamento de artefatos. Usamos dois desses armazenamentos ao mesmo tempo - era o Nexus e agora o jFrog Artifactory.) Inicialmente, usamos o Nexus porque começamos a praticar essa abordagem em aplicativos java (ela se adaptou bem). Então eles colocam a parte dos aplicativos escritos pelo PHP lá; e o Nexus não era mais adequado e, portanto, escolhemos o jFrog Artefactory, que pode criar quase tudo. Chegamos até ao fato de que, nesse armazenamento de artefatos, armazenamos nossos próprios pacotes binários, que coletamos para servidores.
Crescimento de carga explosiva
Nós conversamos sobre mudar a versão do software. A próxima coisa que temos é um crescimento explosivo de carga. Aqui eu provavelmente entendo que o crescimento explosivo da carga não é a coisa certa ...
Escrevemos um novo sistema - ele é orientado a serviços, bonito e elegante, em todos os lugares, em todos os lugares, em todas as filas, em todos os lugares assincronia. E nesses sistemas, os dados podem ter um fluxo diferente. Para a primeira transação, o 1º, 3º e 10º trabalhador pode estar envolvido, para a segunda transação - 2º, 4º, 5º. E hoje, digamos, de manhã, você tem um fluxo de dados que usa os três primeiros trabalhadores e, à noite, muda drasticamente, e tudo usa os outros três trabalhadores.
E aqui acontece que você precisa de alguma forma escalar os trabalhadores, de alguma forma escalar seus serviços, mas, ao mesmo tempo, impedir o aumento de recursos.

Determinamos os requisitos para nós mesmos. : Service discovery, – , – . , , . «», «», .
? . 70 . «», «» , , . 100 «», 100 . . , – 24/7 , , , 70 , .
«», IP Scale-Nomad – ScaleNo, : . , : « ?» – , .
, , , , , – , . 3-5 – .

Como isso funciona? ! : : , – , – , – .
, . 45 – . 2 , ( – , ). – , 5-10 , .
«», , «» . , , – . . № 2 – « ».
. ?
– « ?» ! . ?

!
, , . . , . « ». :

«» «», . «» . «» «» , , – «» «», – «» «» Telegraf.
New Relic. , . , . 1,5 , , : « ». , , . «-» , 15 «-». .
, – Debugger. «», , , «». O que é isso , 15-30 , « » , .
, ( ) – , . , «» – , «» . – , , , .
?
? ?

- Response time / RPS – . , - .
- .
- .
- .
– «», «» . , - , . – ( ). - 5-10-15 – , ( ).
– :
– 6 , – . – RPS, RTS. – «». «» , - … , .
, – . OpenTracing – , , , ; . OpenTracing- , . , , . , , .

, 3 – . , , 20-30 .
, – .
, , , , . , .

? , : (, «»); , . , , … – -. , : « »?
… -, ( ) , . : – , , ( ). , - . ! . .
, .
, – , , , , , - . , , .

( – ), ELK Stack – . -, , ELK, , ELK. .
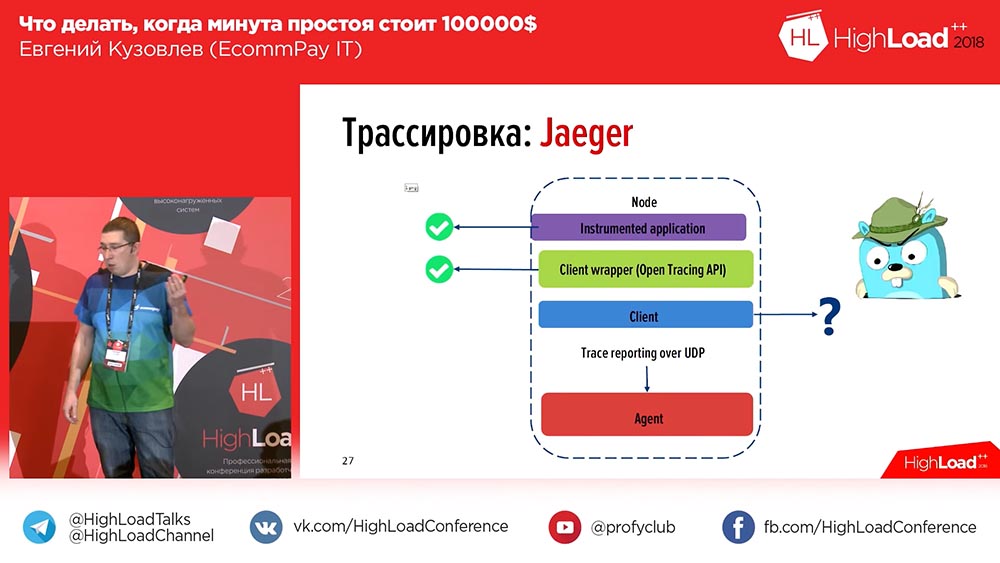
. , , , , «», id- ( ). . Porque , , . , – OpenTracing, .
, , – «» (Zipkin) «» (Jaeger). «» – , «». «» , , , , . «» .
«»: , Api ( Api PHP , , – , ), . «», – , . ? :
«» span'. , , (1-2-3 – , ). , . , Error. Error , . , span:

. , , . : – , , .
, . , . , «» PHP – , welcome to use, :

– OpenTracing Api, php-extention, . . , . : , extention up to you.
. – . ? :

«»? , ! «» , , , . ?

- . , . 60 , . , , – , .
- . , , RnD-. , (, ) , , .
- , – , . .
- Temos tolerâncias. Por exemplo, não consideramos o tempo de inatividade se perdermos 2% do tráfego em dois minutos. Isso, em princípio, não se enquadra em nossas estatísticas. Se mais em porcentagem ou tempo, já contamos.
- E sempre escrevemos post-mortem. O que quer que aconteça conosco, qualquer situação em que ele se comporte de maneira inadequada no local de produção será refletida no potencial de venda. Um post-mortem é um documento no qual você escreve o que aconteceu com você, o tempo detalhado do que você fez para corrigi-lo e (este é um bloco obrigatório!) O que você fará para impedir que isso aconteça no futuro. Isso é necessário, necessário para análises subsequentes.
O que considerar no tempo de inatividade?

A que tudo isso levou?
Isso levou ao fato de que (tivemos alguns problemas de estabilidade, isso não era adequado para nós ou clientes) nos últimos 6 meses, nosso indicador de estabilidade foi de 99,97. Podemos dizer que isso não é muito. Sim, temos algo pelo que lutar. Cerca de metade desse indicador é a estabilidade, por assim dizer, não a nossa, mas o firewall de aplicativos da web, que está diante de nós e é usado como um serviço, mas isso não importa para os clientes.
Aprendemos a dormir à noite. Finalmente! Seis meses atrás, não sabíamos como. E nesta nota com os resultados, quero fazer uma observação. Ontem à noite houve um relatório maravilhoso sobre um sistema de controle de reatores nucleares. Se as pessoas que escreveram esse sistema me ouvirem, esqueça o que eu disse sobre "2% não é tempo de inatividade". Para você, 2% é tempo de inatividade, mesmo que por dois minutos "!
Isso é tudo! Suas perguntas.

Sobre balanceadores e migração de banco de dados
Pergunta da platéia (doravante - B): - Boa noite. Muito obrigado por esse relatório de administrador! A pergunta é curta sobre o assunto de seus balanceadores. Você mencionou que possui WAF, ou seja, pelo que entendi, você usa algum tipo de balanceador externo ...
: - Não, usamos nossos serviços como balanceador. Nesse caso, o WAF é para nós apenas uma ferramenta de proteção contra DDoS.
P: - Você poderia dizer algumas palavras sobre os balanceadores?
EK: - Como eu disse, este é um grupo de servidores em openresty. Agora temos 5 grupos de grupos redundantes que respondem exclusivamente ... ou seja, um servidor no qual fica exclusivamente aberto, apenas proxyiza o tráfego. Portanto, para entender o quanto mantemos: agora temos um fluxo de tráfego regular - são várias centenas de megabits. Eles conseguem, se sentem bem, nem se esforçam.
P: - Também é uma pergunta simples. Há uma implantação azul / verde. E o que você faz, por exemplo, com migrações do banco de dados?
EK: - Boa pergunta! Olha, nós na implantação Azul / Verde temos linhas separadas para cada linha. Ou seja, se estamos falando sobre as linhas de eventos que são transmitidas do trabalhador para o trabalhador, existem linhas separadas para a linha azul e a linha verde. Se estamos falando sobre o próprio banco de dados, reduzimos deliberadamente, como pudemos, colocar tudo quase na linha, temos apenas uma pilha de transações no banco de dados. E temos uma única pilha de transações para todas as linhas. Com um banco de dados nesse contexto: não o compartilhamos em azul e verde, porque as duas versões do código devem saber o que está acontecendo com a transação.
Amigos, ainda tenho um prêmio tão pequeno para estimular você - um livro. E preciso entregá-la para a melhor pergunta.
Q: - Olá. Obrigado pelo relatório. A questão é essa. Você monitora pagamentos, monitora os serviços com os quais se comunica ... Mas como você monitora para que uma pessoa de alguma forma chegue à sua página de pagamento, faça um pagamento e o projeto lhe dê dinheiro? Ou seja, como você monitora se o marchant está disponível e aceita seu retorno de chamada?
Nota: - "Comerciante" para nós, neste caso, é exatamente o mesmo serviço externo que o sistema de pagamento. Monitoramos a velocidade de resposta do "comerciante".
Sobre criptografia de banco de dados
Q: - Olá. Eu tenho um pouco de pergunta. Você possui dados sensíveis do PCI DSS. Eu queria saber como você armazena os PANs em filas nas quais precisa jogar? Você usa alguma criptografia? A partir daqui, surge a seguinte segunda pergunta: no PCI DSS, é necessário criptografar o banco de dados periodicamente em caso de alterações (dispensa de administradores e assim por diante) - como, neste caso, acontece com a acessibilidade?

EK: - Pergunta maravilhosa! Em primeiro lugar, não armazenamos PANs nas filas. Não temos o direito de armazenar o PAN em qualquer lugar de forma clara, em princípio, portanto, usamos um serviço especial (chamamos de “Kademon”) - este é um serviço que faz apenas uma coisa: recebe uma mensagem e envia uma mensagem criptografada. E nós armazenamos tudo com essa mensagem criptografada. Consequentemente, o comprimento da chave para nós é inferior a kilobytes, para que seja direto, sério e confiável.
P: - Você precisa de 2 kilobytes agora?
EK: - Parece que ontem tinha 256 ... Bem, onde mais ?!
Consequentemente, este é o primeiro. E segundo, a solução que existe, suporta o processo de re-criptografia - existem dois pares de "bolos" (chaves) que fornecem "decks" que criptografam (chave são chaves, dek são derivados de chaves que criptografam). E no caso do início do procedimento (ocorre regularmente, de 3 meses a ± alguns), enviamos um novo par de “bolos” e os dados são criptografados novamente. Temos serviços separados que separam todos os dados e os criptografam de uma nova maneira; os dados são armazenados ao lado do identificador de chave com o qual são criptografados. Assim, assim que nossos dados são criptografados com novas chaves, excluímos a chave antiga.
Às vezes, você precisa fazer pagamentos manualmente ...
P: - Ou seja, se um retorno ocorreu para alguma operação, decifre-o com a chave antiga?
CE: - Sim.
Q: - Então, mais uma pequena pergunta. Quando há algum tipo de falha, queda, incidente, é necessário enviar a transação no modo manual. Existe uma situação dessas.
EK: - Sim, faz.
P: - De onde você tira esses dados? Ou você mesmo vai com canetas para esta loja?
EK: - Não, bem, é claro - nós temos algum tipo de sistema de back-office que contém uma interface para nosso suporte. Se não soubermos em que status a transação está (por exemplo, enquanto o sistema de pagamento não respondeu com um tempo limite), não sabemos a priori, ou seja, atribuímos o status final apenas com total confiança. Nesse caso, transferimos a transação para um status especial para processamento manual. De manhã, no dia seguinte, assim que o suporte recebe informações de que essas transações permanecem no sistema de pagamento, elas as processam manualmente nessa interface.

P: - Eu tenho algumas perguntas. Uma delas é a continuação da zona PCI DSS: como você obtém os logs de loop? Essa pergunta, porque o desenvolvedor pode colocar qualquer coisa nos logs! Segunda pergunta: como você lança hotfixes? As canetas no banco de dados são uma opção, mas pode haver correções gratuitas - qual é o procedimento? E a terceira pergunta provavelmente está relacionada ao RTO, RPO. Sua disponibilidade era 99,97, quase quatro noves, mas, pelo que entendi, você tem um segundo data center, um terceiro data center e um quinto data center ... Como você lida com a sincronização, replicação e tudo mais?
EK: - Vamos começar do primeiro. A primeira pergunta sobre os logs foi? Quando escrevemos logs, temos uma camada que mascara todos os dados confidenciais. Ela olha para a máscara e os campos adicionais. Assim, nossos logs são lançados com dados já mascarados e um loop PCI DSS. Essa é uma das tarefas regulares atribuídas ao departamento de testes. Eles são obrigados a verificar todas as tarefas, incluindo os logs que escrevem, e essa é uma das tarefas regulares na revisão de código, para controlar se o desenvolvedor não escreveu nada. A verificação subsequente disso é realizada regularmente pelo departamento de segurança da informação uma vez por semana: os logs são selecionados seletivamente no último dia e são executados através de um analisador de scanner especial dos servidores de teste para verificar tudo isso.
Sobre hot fixes. Isso está incluído no nosso cronograma de implantação. Temos um item separado sobre hotfixes. Acreditamos que implantamos hotfixes o tempo todo quando precisamos. Assim que a versão for montada, assim que for executada, assim que tivermos o artefato, colocaremos o administrador do sistema de prontidão no suporte e ele a implantará no momento em que for necessário.
Sobre os "quatro noves". O número que temos agora, realmente foi alcançado, e o procuramos em outro data center. Agora temos um segundo data center, e estamos começando a rotear entre eles, e a questão do centro de replicação de dados cruzados é realmente uma questão não trivial. Tentamos resolvê-lo no devido tempo por diferentes meios: tentamos usar a mesma "Tarântula" - não funcionou para nós, estou dizendo imediatamente. Portanto, chegamos ao fato de fazermos a ordem da "sensação" manualmente. De fato, temos todas as aplicações no modo assíncrono das unidades de sincronização "alteradas" necessárias entre os datacenters.
P: - Se você possui um segundo, por que não um terceiro? Porque ninguém ainda tem cérebro dividido ...
: - E não temos um cérebro dividido. Devido ao fato de que cada aplicativo dirige um multimaster, não importa para nós qual o centro da solicitação. Estamos prontos para o fato de que, no caso de um data center travar (estamos deitados nele) e no meio da solicitação de um usuário alternar para um segundo data center, estaremos realmente prontos para perder esse usuário; mas serão unidades, unidades absolutas.
Q: - Boa noite. Obrigado pelo relatório. Você falou sobre seu depurador, que conduz algumas transações de teste na produção. Mas conte-nos sobre transações de teste! Qual a profundidade?
CE: - Passa por todo o ciclo de todo o componente. Não há diferenças entre a transação de teste e a de combate para o componente. E, do ponto de vista da lógica, este é apenas um projeto separado no sistema, no qual apenas as transações de teste são perseguidas.
Q: - E onde você cortou? Então o Core enviou ...
:: - Estamos atrás de "Kor", neste caso, para transações de teste ... Temos um roteamento: "Kor" sabe para qual sistema de pagamento enviar - enviamos para um sistema de pagamento falso, que simplesmente fornece uma resposta http e é tudo .
P: - Diga-me, por favor, você teve o aplicativo escrito em um monolito enorme ou o cortou em alguns serviços ou mesmo microsserviços?
Nota: - Não temos um monólito, é claro, temos um aplicativo orientado a serviços. Temos uma piada de que temos um serviço de monólitos - eles são realmente muito grandes. A chamada de microsserviços nesse idioma não muda de maneira alguma, mas esses são os serviços nos quais os trabalhadores de máquinas distribuídos trabalham.
Se o serviço no servidor estiver comprometido ...
Q: - Então eu tenho a seguinte pergunta. Mesmo que fosse um monólito, você ainda disse que possui muitos desses servidores instantâneos, todos eles processam os dados em princípio, e a pergunta é: “Se um dos servidores instantâneos ou o aplicativo, qualquer link específico estiver comprometido Eles têm algum tipo de controle de acesso? Qual deles pode fazer o que? Com quem entrar em contato, para quais dados?

EK: - Sim, claro. Os requisitos de segurança são bastante sérios. Em primeiro lugar, temos tráfego de dados abertos e as portas são apenas aquelas nas quais antecipamos o tráfego com antecedência. Se o componente se comunicar com o banco de dados (digamos, “Muskul”) em 5-4-3-2, apenas 5-4-3-2 e outras portas estarão abertas para ele, outras direções de tráfego não estarão disponíveis. Além disso, devemos entender que, na produção, temos cerca de 10 loops de segurança diferentes. E mesmo que o aplicativo tenha sido comprometido de alguma forma, Deus o permita, um invasor não poderá acessar o console de gerenciamento do servidor, porque esta é outra zona de segurança da rede.
P: - E neste contexto, estou mais interessado no momento em que você tem alguns contratos com serviços - o que eles podem fazer, por meio de quais "ações" eles podem entrar em contato ... E no fluxo normal, alguns serviços específicos perguntam quais uma série, uma lista de "ação" em outro. Eles não parecem se voltar para os outros em uma situação normal e têm outras áreas de responsabilidade. Se um deles estiver comprometido, ele será capaz de executar a "ação" desse serviço?
EK: - Eu entendo. Se em uma situação normal com outro servidor a comunicação geralmente era permitida, então sim. De acordo com o contrato de SLA, não monitoramos se você tem apenas as 3 primeiras "ações" e 4 "ações" não são permitidas. Isso provavelmente é redundante para nós, porque temos um sistema de proteção de quatro níveis, em princípio, para circuitos. Preferimos defender com contornos do que no interior.
Como funcionam Visa, MasterCard e Sberbank
P: - Quero esclarecer um momento sobre a troca de um usuário de um data center para outro. Até onde eu sei, "Visa" e "MasterCard" funcionam no protocolo síncrono binário 8583, existem misturas. E eu queria saber, agora quero dizer mudar - é diretamente "Visa" e "MasterCard" ou para sistemas de pagamento, para processamentos?
EK: - Depende das misturas. Misturas que temos em um data center.
P: - Grosso modo, você tem um ponto de conexão?
:: - “ Visor ” e “MasterCard” - sim. Só porque "Visa" e "MasterCard" exigem investimentos bastante sérios em infraestrutura para concluir contratos separados para receber um segundo par de mixagens, por exemplo. Eles são reservados na estrutura de um datacenter, mas, se Deus proibir, o datacenter em que as misturas de conexão com o "Visa" e o "MasterCard" estão mortos, teremos uma conexão com o "Visa" e o "MasterCard" perdido ...
P: - Como eles podem ser reservados? Eu sei que o "Visa" permite que apenas uma conexão seja mantida em princípio!
EK: - Eles próprios fornecem equipamentos. De qualquer forma, recebemos equipamentos com redundância interna.
P: - Ou seja, o rack do Connects Orange?
CE: - Sim.
P: - Mas, como neste caso: se o seu data center desaparecer, você deve usá-lo ainda mais? Ou é só parar o tráfego?
CE: - Não. Nesse caso, simplesmente mudamos o tráfego para outro canal, o que, obviamente, será mais caro para nós, mais caro para os clientes. Mas o tráfego não passará por nossa conexão direta com o "Visa", "MasterCard", mas pelo "Sberbank" convencional (muito exagerado).
Sinto muito por machucar os funcionários do Sberbank. Mas, de acordo com nossas estatísticas, o Sberbank está caindo com mais frequência dos bancos russos. Em menos de um mês, algo não caiu no Sberbank.

Um pouco de publicidade :)
Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando aos seus amigos VPS baseado em nuvem para desenvolvedores a partir de US $ 4,99 , um analógico exclusivo de servidores básicos que foi inventado por nós para você: Toda a verdade sobre o VPS (KVM) E5-2697 v3 (6 núcleos) 10GB DDR4 480GB SSD 1Gbps de 10GB de US $ 19 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
Dell R730xd 2 vezes mais barato no data center Equinix Tier IV em Amsterdã? Somente temos 2 TVs Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV a partir de US $ 199 na Holanda! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - a partir de US $ 99! Leia sobre Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?