Continuamos a lidar com o trabalho do GraalVM e, desta vez, temos uma tradução do artigo de Aleksandar Prokopec "Sob o capô das otimizações do GraalVM JIT", publicado originalmente no blog Medium . O artigo tem alguns links interessantes, depois tentaremos traduzir esses artigos também.

Da última vez no Medium, analisamos os problemas de desempenho da API do Java Streams no GraalVM em comparação com o Java HotSpot VM. O GraalVM é caracterizado pelo alto desempenho e nessas experiências alcançamos uma aceleração de 1,7 a 5 vezes. Obviamente, os valores específicos do ganho de desempenho sempre dependerão do código que está sendo executado e dos dados de carregamento; portanto, antes de tirar conclusões, você deve tentar executar seu código no GraalVM.
Neste artigo, iremos aprofundar o interior do GraalVM e ver como a compilação JIT acontece.
Otimizações de JIT no GraalVM
Vamos dar uma olhada em várias otimizações de alto nível que o compilador GraalVM usa. Neste artigo, abordaremos apenas as otimizações mais interessantes, juntamente com exemplos específicos de seus trabalhos. Se você quiser aprofundar, uma boa visão geral das otimizações do compilador GraalVM está no trabalho intitulado “ Otimizando as operações de coleta com a compilação agressiva do JIT” .
Inlining
Se você não tocar no assembly com antecedência, a maioria dos compiladores JIT nas modernas máquinas virtuais faz análises internas. Isso significa que, a cada momento específico, há uma análise de um método. Por esse motivo, a análise intraprocedural é muito mais rápida que a análise interprocedural de todo o programa, que normalmente não tem tempo para concluir no tempo alocado para o trabalho do compilador JIT. Em um compilador que usa otimizações intra-processuais (por exemplo, otimizando um método de cada vez), uma das otimizações fundamentais mais importantes é a inclusão. A inclusão de linhas é importante porque aumenta efetivamente o método, o que significa que o compilador pode ver mais oportunidades de otimizar simultaneamente vários trechos de código usados em métodos aparentemente não relacionados.
Pegue, por exemplo, o método volleyballStars de um artigo anterior:
@Benchmark public double volleyballStars() { return Arrays.stream(people) .map(p -> new Person(p.hair, p.age + 1, p.height)) .filter(p -> p.height > 198) .filter(p -> p.age >= 18 && p.age <= 21) .mapToInt(p -> p.age) .average().getAsDouble(); }
Neste diagrama, vemos partes da representação intermediária (IR) desse método no GraalVM, no momento imediatamente após a análise do bytecode Java correspondente.

Você pode pensar nesse IR como algum tipo de árvore de sintaxe abstrata em esteróides - graças a isso, algumas otimizações são mais fáceis de executar. Não importa como essa RI funcione, mas se você quiser entender mais profundamente esse tópico, poderá ver um documento chamado "RI Graal: uma representação intermediária declarativa extensível" .
A principal conclusão aqui é que o fluxo de controle do método indicado pelos nós amarelos do gráfico e pelas linhas vermelhas executa sequencialmente os métodos da interface do Stream : Stream.filter , Stream.mapToInt , IntStream.average . Não tendo conhecimento preciso do que está no código desses métodos, o compilador não é capaz de simplificar o método - e aqui o inlining vem em socorro!
Uma transformação chamada inlining é uma coisa muito compreensível: apenas procura lugares para chamar métodos e os substitui pelo corpo do método inline correspondente, incorpora-os por dentro. Vamos dar uma olhada no IR do método volleyballStars depois de incluir parte dos métodos. Somente a parte que segue a chamada IntStream.average é IntStream.average :

O diagrama mostra que a chamada para getAsDouble (nó número 71) desapareceu do IR. Observe que o método getAsDouble do objeto getAsDouble retornado de IntStream.average (a última chamada no método volleyballStars ) é definido no JDK da seguinte maneira:
public double getAsDouble() { if (!isPresent) { throw new NoSuchElementException("No value present"); } return value; }
Aqui podemos encontrar o carregamento do campo isPresent (número do nó 190, LoadField ) e a leitura do campo do value . No entanto, não há rastreamento à esquerda da exceção NoSuchElementException e não há mais código que a lança.
Isso ocorre porque o compilador GraalVM adivinha: o método volleyballStars nunca lançará uma exceção. Esse conhecimento geralmente não está disponível durante a compilação getAsDouble - ele pode ser chamado de vários locais diferentes do programa e, em outros casos, a exceção ainda funcionará. No entanto, em um método específico volleyballStars , é improvável que ocorra uma exceção porque o conjunto de possíveis estrelas do vôlei nunca está vazio. Por esse motivo, o GraalVM remove a ramificação e insere o FixedGuard - um nó que des otimiza o código em caso de violação de nossa suposição. Este é um exemplo bastante minimalista e, na vida real, há casos muito mais complicados de como o inlining ajuda outras otimizações.
Sabemos que a árvore de chamadas do programa geralmente é muito profunda ou talvez até infinita. Portanto, o alinhamento em algum momento precisa ser interrompido - ele possui restrições muito específicas sobre o tempo de operação e o tamanho da memória. Sabendo disso, fica claro: determinar o que e quando alinhar é muito difícil.
Embutimento polimórfico
Inlining funciona apenas se o compilador puder determinar o método específico ao qual a operação de chamada de método se destina. Porém, em Java, geralmente há muitas chamadas indiretas para os métodos cujas implementações são desconhecidas em estática, que são pesquisadas em tempo de execução usando o despacho virtual.
Por exemplo, IntStream.average método IntStream.average . Sua implementação típica é assim:
@Override public final OptionalDouble average() { long[] avg = collect( () -> new long[2], (ll, i) -> { ll[0]++; ll[1] += i; }, (ll, rr) -> { ll[0] += rr[0]; ll[1] += rr[1]; }); return avg[0] > 0 ? OptionalDouble.of((double) avg[1] / avg[0]) : OptionalDouble.empty(); }
Não deixe a aparente simplicidade do código enganar você! Este método é definido em termos de chamadas a collect , e a mágica acontece aqui. A árvore de chamadas deste método (por exemplo, a hierarquia de chamadas) cresce rapidamente à medida que caímos mais na collect . Basta dar uma olhada neste diagrama:
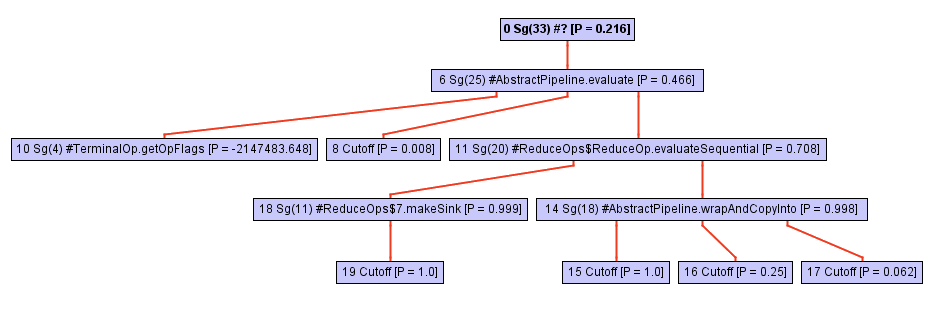
A partir de algum ponto do processo de atravessar a árvore de chamadas, o inliner se apoia na chamada opWrapSink da estrutura de opWrapSink Java, que é um método abstrato:

abstract<P_IN> Sink<P_IN> wrapSink(Sink<P_OUT> sink);
Normalmente, um inliner não vai mais longe, porque é uma chamada indireta. A determinação de um método específico ocorrerá apenas durante a execução do programa, e agora o inlayner simplesmente não sabe no que trabalhar a seguir.
No caso do GraalVM, algo mais acontece: ele salva um perfil do tipo do método de destino para cada ponto de chamada indireto. Esse perfil é essencialmente apenas uma tabela que informa com que frequência cada uma das implementações wrapSink foi wrapSink . No nosso caso, o perfil conhece três implementações diferentes em classes anônimas: ReferencePipeline$2 , ReferencePipeline$3 , ReferencePipeline$4 ReferencePipeline$3 , ReferencePipeline$4 . Essas implementações são chamadas com uma probabilidade de 50%, 25% e 25%, respectivamente.
0.500000: Ljava/util/stream/ReferencePipeline$2; 0.250000: Ljava/util/stream/ReferencePipeline$4; 0.250000: Ljava/util/stream/ReferencePipeline$3; notRecorded: 0.000000
Essas informações fornecem assistência inestimável ao compilador, permitindo que você gere o comutador de tipos - uma breve switch que verifica o tipo do método em tempo de execução e, em seguida, chama um método específico para cada um dos casos acima. A imagem abaixo mostra uma parte da exibição intermediária, mostrando o comutador de tipos (três if ), com uma verificação para verificar se o tipo de destinatário é alguém do ReferencePipeline$2 , ReferencePipeline$3 ou ReferencePipeline$4 . Agora, cada chamada direta na ramificação bem-sucedida de cada uma das verificações InstanceOf pode ser incorporada ou conectar algumas otimizações adicionais. Se nenhum dos tipos passar no teste, o código será desativado no nó Deopt (como alternativa, você pode executar o despacho virtual).

Se você deseja entender inlining polimórfico mais profundamente, recomendo o trabalho clássico sobre este tópico, "Inlining of Virtual Methods" .
Análise de escape parcial
Vamos voltar ao nosso exemplo de vôlei. Observe que nenhum dos objetos Person alocados dentro da lambda transmitidos para a função map escapa do escopo do método volleyballStars . Em outras palavras, no momento em que o método volleyballStars termina, não existe uma área de memória que aponte para objetos do tipo Person . Em particular, o registro do valor getHeight é usado ainda mais apenas para filtragem de altura.
Em algum momento durante a compilação do método volleyballStars , chegamos ao IR mostrado no diagrama abaixo. O bloco que começa com o nó Begin -1621 começa com a alocação do objeto Person (no nó Alloc ), que é inicializado com o valor do campo age com um incremento de 1 e o valor anterior do campo height . O campo de height é lido anteriormente no nó LoadField -1539. O resultado da alocação é encapsulado em AllocatedObject -2137 e enviado para a chamada do método -1625. O compilador não pode fazer mais nada neste momento - do ponto de vista dele, o objeto escapou do método volleyballStars . ( Nota do tradutor: "fugir de um objeto" é chamado de "escape" em inglês; portanto, o nome da otimização é "análise de escape" ).

Depois disso, o compilador decide alinhar a chamada de accept - isso parece razoável. Como resultado, chegamos ao seguinte RI:
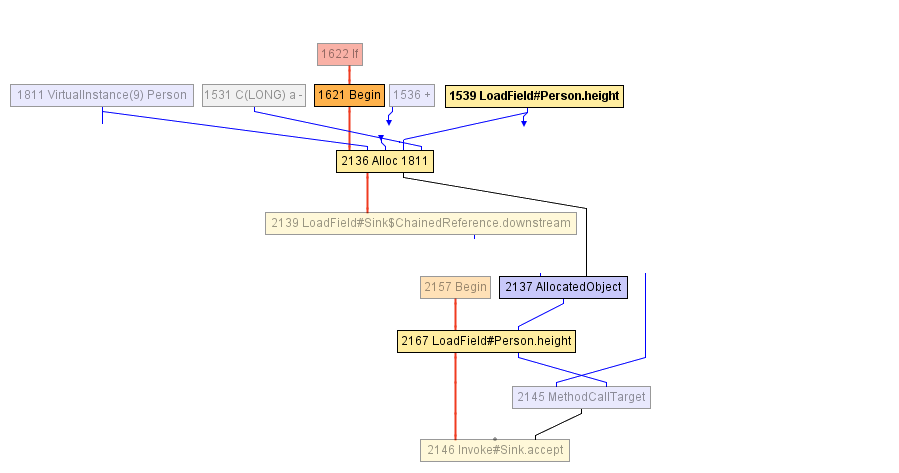
E aqui o compilador JIT inicia uma análise de escape parcial: percebe que AllocatedObject usado apenas para ler o campo height (recordação, height usada apenas na condição de filtragem, verifique se a altura é maior que 198). Portanto, o compilador pode reatribuir a leitura do campo height -2167 para trabalhar diretamente com o nó que foi gravado anteriormente no objeto Person (nó Alloc -2136), e este é nosso LoadField -1539. Além disso, o nó Alloc daqui em diante não vai para a entrada de nenhum outro nó, então você pode simplesmente excluí-lo - este é um código morto!
Essa otimização é, de fato, a principal razão pela qual o exemplo do volleyballStars sofreu uma aceleração de cinco vezes depois de mudar para o GraalVM. Mesmo que todos os objetos Person não sejam necessários e sejam descartados imediatamente após a criação, eles ainda precisam ser alocados no heap, sua memória ainda precisa ser inicializada. A análise de escape parcial permite eliminar alocações ou adiá-las, movendo-as para as ramificações de código onde os objetos realmente fogem e que acontecem com muito menos frequência.
Você pode obter uma compreensão mais profunda da análise de escape parcial em um documento chamado Análise de escape parcial e substituição escalar para Java .
Sumário
Neste artigo, analisamos três otimizações do GraalVM: inlining, inline polimórfico e análise de escape parcial. Existem muitas otimizações diferentes: promoção e divisão de ciclos, duplicação de caminhos, numeração de valores globais, convolução de constantes, remoção de código morto, execução especulativa e assim por diante.
Se você quiser saber mais sobre como o GraalVM funciona, não hesite em abrir a página da publicação . Se você quiser ter certeza de que o GraalVM pode acelerar o seu código, faça o download dos binários e tente você mesmo.
Do tradutor: materiais adicionais
Nas conferências, o JPoint e o Joker costumam falar sobre o GraalVM. Por exemplo, no último JPoint 2019, Thomas Wuerthinger (diretor de pesquisa do Oracle Labs, responsável pelo GraalVM) e Oleg Shelaev, um dos dois evangelistas oficiais de tecnologia, nos visitaram.
Você pode assistir a esses e outros vídeos em nosso canal do YouTube:
Lembramos que o próximo JPoint será realizado de 15 a 16 de maio de 2020 em Moscou, e os ingressos já podem ser adquiridos no site oficial .