Olá pessoal! Sou desenvolvedor de back-end, escrevendo microsserviços em Java + Spring. Trabalho em uma das equipes internas de desenvolvimento de produtos da Tinkoff.

Nossa equipe geralmente levanta a questão da otimização de consulta no DBMS. Você sempre quer um pouco mais rápido, mas nem sempre pode se dar bem com índices bem projetados - é necessário procurar algumas soluções alternativas. Durante uma dessas andanças pela rede em busca de otimizações razoáveis ao trabalhar com o banco de dados, encontrei o blog infinitamente útil de Marcus Vinand , autor do SQL Performance Explained. Este é o tipo muito raro de blog em que você pode ler todos os artigos em uma linha.
Quero traduzir para você um pequeno artigo de Marcus. Pode ser chamado, até certo ponto, de um manifesto que procura chamar a atenção para a questão antiga, mas ainda relevante, do desempenho da operação de compensação de acordo com o padrão SQL.
Em alguns lugares, complementarei o autor com explicações e observações. Vou designar todos esses lugares como "aprox." Para maior clareza.
Pequena introdução
Acho que muitas pessoas sabem o quão problemático e inibitório é trabalhar com seletores paginais por meio de deslocamento. Mas você sabia que ele pode ser simplesmente substituído por um design mais produtivo?
Portanto, a palavra-chave offset informa ao banco de dados para ignorar as primeiras n entradas na solicitação. No entanto, o banco de dados ainda precisa ler esses primeiros n registros do disco e na ordem especificada (nota: aplique a classificação se um for especificado) e somente depois disso será possível retornar registros a partir de n + 1 em diante. O mais interessante é que o problema não está na implementação concreta no DBMS, mas na definição inicial de acordo com o padrão:
... as linhas são classificadas primeiro de acordo com a <ordem pela cláusula> e, em seguida, limitadas, descartando o número de linhas especificadas na <cláusula de deslocamento do resultado> desde o início ...
-SQL: 2016, Parte 2, 4.15.3 Tabelas derivadas (nota: agora o padrão mais utilizado)
O ponto principal aqui é que o deslocamento requer um único parâmetro - o número de registros a serem ignorados, e é isso. Seguindo essa definição, um DBMS pode obter apenas todos os registros e descartar os desnecessários. Obviamente, essa definição de deslocamento obriga a fazer um trabalho extra. E nem importa se é SQL ou NoSQL.
Um pouco mais de dor
Problemas de deslocamento não param por aí, e aqui está o porquê. Se outra operação inserir um novo registro entre a leitura de duas páginas de dados do disco, o que acontecerá neste caso?
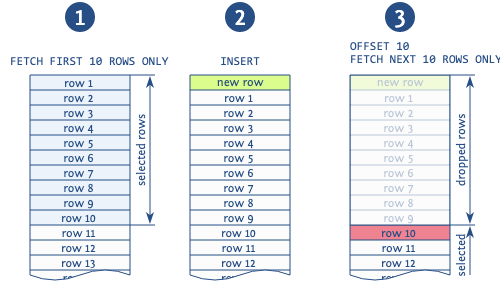
Quando deslocamento é usado para pular registros de páginas anteriores, na situação de adicionar um novo registro entre as operações de leitura de páginas diferentes, provavelmente você receberá duplicatas (nota: isso é possível quando lemos página por página usando a ordem por construção, então no meio de nossa saída pode obter um novo registro).
A figura mostra claramente essa situação. A base lê os 10 primeiros registros, após o qual um novo registro é inserido, que muda todos os registros lidos por 1. Em seguida, a base pega uma nova página dos 10 registros seguintes e começa não a partir do dia 11 como deveria, mas do dia 10, duplicando esse registro. Existem outras anomalias associadas ao uso dessa expressão, mas essa é a mais comum.
Como já descobrimos, esses não são problemas de um DBMS específico ou de sua implementação. O problema é a definição de paginação de acordo com o padrão SQL. Dizemos ao DBMS qual página obter ou quantos registros devem ser ignorados. A base simplesmente não é capaz de otimizar essa solicitação, pois há muito pouca informação para isso.
Também é importante esclarecer que esse não é um problema específico de palavra-chave, mas a semântica da consulta. Existem várias sintaxes idênticas em termos de problematicidade:
- A palavra-chave offset, conforme mencionado anteriormente.
- A construção das duas palavras-chave limit [offset] (embora o próprio limite não seja tão ruim).
- Filtrar por limites inferiores com base na numeração de linhas (por exemplo, número_da_filme (), rownum etc.).
Todas essas expressões dizem simplesmente quantas linhas a serem ignoradas, nenhuma informação ou contexto adicional.
Posteriormente neste artigo, a palavra-chave offset é usada como uma generalização de todas essas opções.
Vida sem uma compensação
Agora imagine como seria o nosso mundo sem todos esses problemas. Acontece que a vida sem deslocamento não é tão complicada: você pode selecionar apenas as linhas que não vimos (nota: ou seja, aquelas que não estavam na última página) usando a condição em que.
Nesse caso, construímos o fato de que as seleções são executadas em um conjunto ordenado (boa ordem antiga por). Como temos um conjunto ordenado, podemos usar um filtro bastante simples para obter apenas os dados que estão por trás do último registro da página anterior:
SELECT ... FROM ... WHERE ... AND id < ?last_seen_id ORDER BY id DESC FETCH FIRST 10 ROWS ONLY
Esse é todo o princípio dessa abordagem. Obviamente, ao classificar por várias colunas, tudo se torna mais divertido, mas a ideia é a mesma. É importante observar que essa construção é aplicável a muitas soluções N o S Q L.
Essa abordagem é chamada de método de busca ou paginação do conjunto de chaves. Ele resolve o problema com um resultado flutuante (nota: a situação com a escrita entre as leituras da página, descrita anteriormente) e, é claro, que todos gostamos, trabalha mais rápido e mais estável que o deslocamento clássico. A estabilidade está no fato de que o tempo de processamento da consulta não aumenta proporcionalmente ao número da tabela solicitada (nota: se você quiser aprender mais sobre o trabalho de diferentes abordagens de paginação, pode ver a apresentação do autor . Também é possível encontrar referências comparativas usando métodos diferentes).
Um dos slides informa que a paginação de chave, é claro, não é onipotente - ela tem suas próprias limitações. Mais significativo - ela não tem a capacidade de ler páginas aleatórias (nota: inconsistentemente). No entanto, na era da rolagem sem fim (nota: no front-end), isso não é um problema. A especificação do número da página para um clique é, em qualquer caso, uma má decisão ao desenvolver uma interface do usuário (nota: opinião do autor do artigo).
E as ferramentas?
A paginação de chaves geralmente não é adequada devido à falta de suporte instrumental para esse método. A maioria das ferramentas de desenvolvimento, incluindo várias estruturas, não permite escolher de que maneira a paginação será executada.
A situação é agravada pelo fato de que o método descrito requer suporte de ponta a ponta nas tecnologias usadas - do DBMS à execução da solicitação AJAX no navegador com rolagem sem fim. Em vez de especificar apenas o número da página, agora você precisa especificar um conjunto de chaves para todas as páginas de uma só vez.
No entanto, o número de estruturas que suportam a paginação de chaves está aumentando gradualmente. Aqui está o que está no momento:
(Observação: alguns links foram removidos devido ao fato de que, no momento da tradução, algumas bibliotecas não foram atualizadas de 2017 a 2018. Se estiver interessado, você pode consultar a fonte.)
É neste momento que sua ajuda é necessária. Se você está desenvolvendo ou suportando uma estrutura que de alguma forma usa paginação, peço, peço, que ore para que você faça suporte nativo à paginação de chaves. Se você tiver alguma dúvida ou precisar de ajuda, terei prazer em ajudar ( fórum , Twitter , formulário de contato ) (observação: na minha experiência com Markus, posso dizer que ele está realmente entusiasmado com a divulgação deste tópico).
Se você usar soluções prontas que você acha que merecem suporte para paginação de chaves, crie uma solicitação ou ofereça uma solução pronta, se possível. Você também pode especificar este artigo no link.
Conclusão
A razão pela qual uma abordagem tão simples e útil como a paginação de chaves não é generalizada não é que seja difícil na implementação técnica ou exija algum esforço. A principal razão é que muitos estão acostumados a ver e trabalhar com deslocamento - essa abordagem é ditada pelo próprio padrão.
Como resultado, poucas pessoas pensam em mudar a abordagem da paginação e, por causa disso, o suporte instrumental de estruturas e bibliotecas está se desenvolvendo mal. Portanto, se você estiver próximo da idéia e objetivo da paginação sem complicações, ajude a espalhá-la!
Fonte: https://use-the-index-luke.com/no-offset
Publicado por: Markus Winand