Os usuários do ClickHouse já sabem que sua maior vantagem é o processamento em alta velocidade de consultas analíticas. Mas reivindicações como essa precisam ser confirmadas com testes de desempenho confiáveis. É sobre isso que queremos falar hoje.
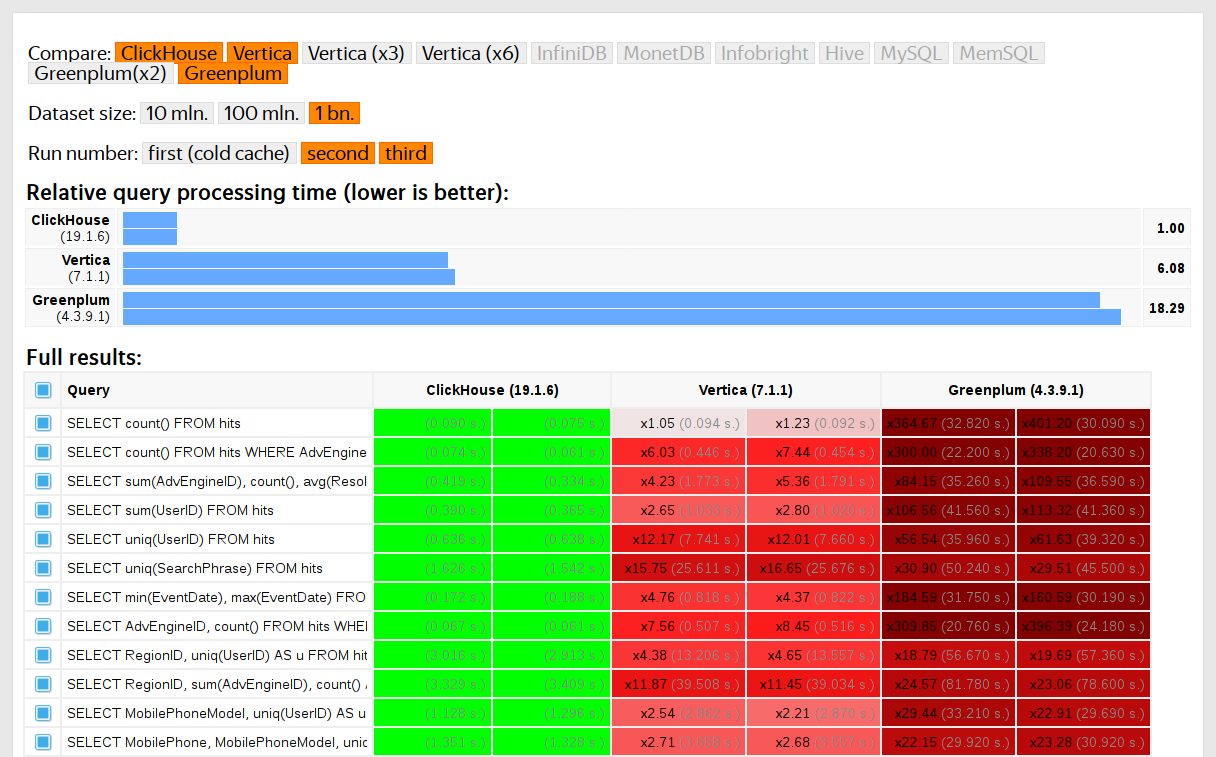
Começamos a executar testes em 2013, muito antes de o produto estar disponível como código aberto. Naquela época, assim como agora, nossa principal preocupação era a velocidade de processamento de dados no Yandex.Metrica. Estávamos armazenando esses dados no ClickHouse desde janeiro de 2009. Parte dos dados foi gravada em um banco de dados a partir de 2012 e parte foi convertida do
OLAPServer e Metrage (estruturas de dados usadas anteriormente pelo Yandex.Metrica). Para o teste, pegamos o primeiro subconjunto aleatoriamente dos dados para 1 bilhão de visualizações de página. O Yandex.Metrica não tinha nenhuma consulta naquele momento, então criamos consultas que nos interessavam, usando todas as formas possíveis para filtrar, agregar e classificar os dados.
O desempenho do ClickHouse foi comparado com sistemas semelhantes como Vertica e MonetDB. Para evitar viés, o teste foi realizado por um funcionário que não havia participado do desenvolvimento do ClickHouse, e casos especiais no código não foram otimizados até que todos os resultados fossem obtidos. Usamos a mesma abordagem para obter um conjunto de dados para testes funcionais.
Depois que o ClickHouse foi lançado como código aberto em 2016, as pessoas começaram a questionar esses testes.
Faltas de testes em dados privados
Nossos testes de desempenho:
- Não pode ser reproduzido de forma independente porque eles usam dados particulares que não podem ser publicados. Alguns dos testes funcionais não estão disponíveis para usuários externos pelo mesmo motivo.
- Precisa de mais desenvolvimento. O conjunto de testes precisa ser substancialmente expandido para isolar as alterações de desempenho em partes individuais do sistema.
- Não execute por confirmação ou para solicitações de recebimento individuais. Os desenvolvedores externos não podem verificar seu código para obter regressões de desempenho.
Poderíamos resolver esses problemas realizando os testes antigos e escrevendo novos com base em dados abertos, como
dados de voo para os EUA e
viagens de táxi em Nova York . Ou podemos usar benchmarks como TPC-H, TPC-DS e
Star Schema Benchmark . A desvantagem é que esses dados são muito diferentes dos dados do Yandex.Metrica e preferimos manter as consultas de teste.
Por que é importante usar dados reais
O desempenho deve ser testado apenas em dados reais de um ambiente de produção. Vejamos alguns exemplos.
Exemplo 1Digamos que você preencha um banco de dados com números pseudo-aleatórios distribuídos uniformemente. A compactação de dados não funcionará neste caso, embora a compactação de dados seja essencial para os bancos de dados analíticos. Não existe uma solução definitiva para o desafio de escolher o algoritmo de compactação correto e a maneira correta de integrá-lo ao sistema, pois a compactação de dados requer um compromisso entre a velocidade da compactação e descompactação e a potencial eficiência da compactação. Mas sistemas que não podem compactar dados são perdedores garantidos. Se seus testes usarem números pseudo-aleatórios distribuídos uniformemente, esse fator será ignorado e os resultados serão distorcidos.
Conclusão: os dados de teste devem ter uma taxa de compactação realista.
Cobri a otimização dos algoritmos de compactação de dados ClickHouse em
um post anterior .
Exemplo 2Digamos que estamos interessados na velocidade de execução desta consulta SQL:
SELECT RegionID, uniq(UserID) AS visitors FROM test.hits GROUP BY RegionID ORDER BY visitors DESC LIMIT 10
Esta é uma consulta típica para Yandex.Metrica. O que afeta a velocidade de processamento?
- Como GROUP BY é executado.
- Qual estrutura de dados é usada para calcular a função agregada uniq.
- Quantos RegionIDs diferentes existem e quanta RAM cada estado da função uniq requer.
Mas outro fator importante é que a quantidade de dados é distribuída de maneira desigual entre as regiões. (Provavelmente segue uma lei de energia. Coloquei a distribuição em um gráfico de log-log, mas não posso ter certeza.) Se for esse o caso, é importante que os estados do agregado uniq funcionem com menos valores. muito pouca memória. Quando existem muitas chaves de agregação diferentes, cada byte conta. Como podemos obter dados gerados com todas essas propriedades? A solução óbvia é usar dados reais.
Muitos DBMSs implementam a estrutura de dados HyperLogLog para uma aproximação de COUNT (DISTINCT), mas nenhum deles funciona muito bem porque essa estrutura de dados usa uma quantidade fixa de memória. O ClickHouse possui uma função que usa
uma combinação de três estruturas de dados diferentes , dependendo do tamanho do conjunto de dados.
Conclusão: Os dados de teste devem representar bem as propriedades de distribuição dos dados reais, significando cardinalidade (número de valores distintos por coluna) e cardinalidade entre colunas (número de valores diferentes contados em várias colunas diferentes).
Exemplo 3Em vez de testar o desempenho do DBMS do ClickHouse, vamos usar algo mais simples, como tabelas de hash. Para tabelas de hash, é essencial escolher a função de hash correta. Isso não é tão importante para std :: unordered_map, porque é uma tabela de hash baseada em encadeamento e um número primo é usado como o tamanho da matriz. A implementação da biblioteca padrão no GCC e no Clang usa uma função de hash trivial como a função de hash padrão para tipos numéricos. No entanto, std :: unordered_map não é a melhor opção quando procuramos velocidade máxima. Com uma tabela de hash de endereçamento aberto, não podemos simplesmente usar uma função de hash padrão. Escolher a função hash correta se torna o fator decisivo.
É fácil encontrar testes de desempenho da tabela de hash usando dados aleatórios que não levam em consideração as funções de hash usadas. Também há muitos testes de função de hash que se concentram na velocidade de cálculo e em certos critérios de qualidade, mesmo que ignorem as estruturas de dados usadas. Mas o fato é que as tabelas de hash e o HyperLogLog exigem diferentes critérios de qualidade da função de hash.
Você pode aprender mais sobre isso em
"Como as tabelas de hash funcionam no ClickHouse" (apresentação em russo). As informações estão um pouco desatualizadas, pois não cobrem
as tabelas suíças .
Desafio
Nosso objetivo é obter dados para testar o desempenho que tenha a mesma estrutura que os dados do Yandex.Metrica com todas as propriedades importantes para os benchmarks, mas de maneira que não restem vestígios de usuários reais do site nesses dados. Em outras palavras, os dados devem ser anonimizados e ainda preservar:
- Taxa de compressão.
- Cardinalidade (o número de valores distintos).
- Cardinalidade mútua entre várias colunas diferentes.
- Propriedades das distribuições de probabilidade que podem ser usadas para modelagem de dados (por exemplo, se acreditarmos que as regiões são distribuídas de acordo com uma lei de energia, o expoente - o parâmetro de distribuição - deve ser aproximadamente o mesmo para dados artificiais e dados reais).
Como podemos obter uma taxa de compactação semelhante para os dados? Se LZ4 for usado, as substrings nos dados binários devem ser repetidas aproximadamente à mesma distância e as repetições devem ter aproximadamente o mesmo comprimento. Para o ZSTD, a entropia por byte também deve coincidir.
O objetivo final é criar uma ferramenta disponível ao público que qualquer pessoa possa usar para anonimizar seus conjuntos de dados para publicação. Isso nos permitiria depurar e testar o desempenho nos dados de outras pessoas semelhantes aos nossos dados de produção. Também gostaríamos que os dados gerados fossem interessantes.
No entanto, esses são requisitos muito pouco definidos e não estamos planejando escrever uma declaração formal de problema ou especificação para esta tarefa.
Possíveis soluções
Não quero que pareça que esse problema seja particularmente importante. Na verdade, nunca foi incluído no planejamento e ninguém tinha a intenção de trabalhar nele. Eu apenas esperava que uma idéia surgisse algum dia e, de repente, eu estivesse de bom humor e conseguisse adiar todo o resto até mais tarde.
Modelos probabilísticos explícitos
A primeira idéia é pegar cada coluna da tabela e encontrar uma família de distribuições de probabilidade que o modele, depois ajuste parâmetros com base nas estatísticas de dados (ajuste de modelo) e use a distribuição resultante para gerar novos dados. Um gerador de números pseudo-aleatórios com uma semente predefinida pode ser usado para obter um resultado reproduzível.
Cadeias de Markov podem ser usadas para campos de texto. Este é um modelo familiar que pode ser implementado de forma eficaz.
No entanto, isso exigiria alguns truques:
- Queremos preservar a continuidade das séries temporais. Isso significa que, para alguns tipos de dados, precisamos modelar a diferença entre valores vizinhos e não o valor em si.
- Para modelar a "cardinalidade conjunta" de colunas, também precisamos refletir explicitamente as dependências entre as colunas. Por exemplo, geralmente há muito poucos endereços IP por ID do usuário, portanto, para gerar um endereço IP, usaríamos um valor de hash do ID do usuário como uma semente e também adicionaríamos uma pequena quantidade de outros dados pseudo-aleatórios.
- Não sabemos ao certo como expressar a dependência de o mesmo usuário visitar frequentemente URLs com domínios correspondentes aproximadamente ao mesmo tempo.
Tudo isso pode ser escrito em um "script" C ++ com as distribuições e dependências codificadas. No entanto, os modelos Markov são obtidos a partir de uma combinação de estatísticas com suavização e adição de ruído. Comecei a escrever um script como esse, mas depois de escrever modelos explícitos para dez colunas, ele se tornou insuportavelmente chato - e a tabela "hits" no Yandex.Metrica tinha mais de 100 colunas em 2012.
EventTime.day(std::discrete_distribution<>({ 0, 0, 13, 30, 0, 14, 42, 5, 6, 31, 17, 0, 0, 0, 0, 23, 10, ...})(random)); EventTime.hour(std::discrete_distribution<>({ 13, 7, 4, 3, 2, 3, 4, 6, 10, 16, 20, 23, 24, 23, 18, 19, 19, ...})(random)); EventTime.minute(std::uniform_int_distribution<UInt8>(0, 59)(random)); EventTime.second(std::uniform_int_distribution<UInt8>(0, 59)(random)); UInt64 UserID = hash(4, powerLaw(5000, 1.1)); UserID = UserID / 10000000000ULL * 10000000000ULL + static_cast<time_t>(EventTime) + UserID % 1000000; random_with_seed.seed(powerLaw(5000, 1.1)); auto get_random_with_seed = [&]{ return random_with_seed(); };
Essa abordagem foi um fracasso. Se eu tivesse me esforçado mais, talvez o script estivesse pronto agora.
Vantagens:
Desvantagens:
- Grande quantidade de trabalho necessária.
- A solução se aplica apenas a um tipo de dados.
E eu preferiria uma solução mais geral que possa ser usada para dados Yandex.Metrica, bem como para ofuscar qualquer outro dado.
De qualquer forma, esta solução pode ser melhorada. Em vez de selecionar modelos manualmente, poderíamos implementar um catálogo de modelos e escolher o melhor dentre eles (melhor ajuste mais alguma forma de regularização). Ou talvez possamos usar modelos Markov para todos os tipos de campos, não apenas para texto. Dependências entre dados também podem ser extraídas automaticamente. Isso exigiria o cálculo da
entropia relativa (quantidade relativa de informações) entre colunas. Uma alternativa mais simples é calcular cardinalidades relativas para cada par de colunas (algo como "quantos valores diferentes de A existem em média para um valor fixo B"). Por exemplo, isso deixará claro que o URLDomain depende totalmente do URL, e não o contrário.
Mas eu também rejeitei essa idéia, porque há muitos fatores a serem considerados e levaria muito tempo para ser escrito.
Redes neurais
Como já mencionei, essa tarefa não estava no topo da lista de prioridades - ninguém estava pensando em tentar resolvê-la. Mas, por sorte, nosso colega Ivan Puzirevsky lecionava na Escola Superior de Economia. Ele me perguntou se eu tinha problemas interessantes que funcionariam como tópicos de tese adequados para seus alunos. Quando lhe ofereci este, ele me garantiu que tinha potencial. Então, entreguei esse desafio a um cara legal "fora da rua" Sharif (ele tinha que assinar um NDA para acessar os dados).
Compartilhei todas as minhas idéias com ele, mas enfatizei que não havia restrições sobre como o problema poderia ser resolvido, e uma boa opção seria tentar abordagens sobre as quais não conheço nada, como usar o LSTM para gerar um despejo de dados em texto. Isso pareceu promissor após a publicação do artigo
A eficácia irracional das redes neurais recorrentes .
O primeiro desafio é que precisamos gerar dados estruturados, não apenas texto. Mas não estava claro se uma rede neural recorrente poderia gerar dados com a estrutura desejada. Existem duas maneiras de resolver isso. A primeira solução é usar modelos separados para gerar a estrutura e o "preenchedor" e usar apenas a rede neural para gerar valores. Mas essa abordagem foi adiada e nunca concluída. A segunda solução é simplesmente gerar um despejo de TSV como texto. A experiência mostrou que algumas das linhas no texto não correspondem à estrutura, mas essas linhas podem ser descartadas ao carregar os dados.
O segundo desafio é que a rede neural recorrente gera uma sequência de dados e, portanto, as dependências nos dados devem seguir na ordem da sequência. Mas, em nossos dados, a ordem das colunas pode potencialmente ser inversa às dependências entre elas.
Não fizemos nada para resolver este problema.
À medida que o verão se aproximava, tivemos o primeiro script Python que gerava dados. A qualidade dos dados parecia decente à primeira vista:

No entanto, deparamos com algumas dificuldades:
- O tamanho do modelo é de cerca de um gigabyte. Tentamos criar um modelo para dados com vários gigabytes de tamanho (para começar). O fato de o modelo resultante ser tão grande suscita preocupações. Seria possível extrair os dados reais nos quais eles foram treinados? Improvável. Mas eu não sei muito sobre aprendizado de máquina e redes neurais e não li o código Python desse desenvolvedor, então como posso ter certeza? Havia vários artigos publicados na época sobre como compactar redes neurais sem perda de qualidade, mas não foram implementadas. Por um lado, isso não parece ser um problema sério, pois podemos optar por não publicar o modelo e apenas publicar os dados gerados. Por outro lado, se ocorrer super ajuste, os dados gerados podem conter uma parte dos dados de origem.
- Em uma máquina com uma única CPU, a velocidade de geração de dados é de aproximadamente 100 linhas por segundo. Nosso objetivo era gerar pelo menos um bilhão de linhas. Os cálculos mostraram que isso não seria concluído antes da data da defesa da tese. Não fazia sentido usar hardware adicional, porque o objetivo era criar uma ferramenta de geração de dados que pudesse ser usada por qualquer pessoa.
Sharif tentou analisar a qualidade dos dados comparando estatísticas. Entre outras coisas, ele calculou a frequência de caracteres diferentes ocorrendo nos dados de origem e nos dados gerados. O resultado foi impressionante: os caracteres mais frequentes foram Ð e Ñ.
Não se preocupe com Sharif, no entanto. Ele defendeu com sucesso sua tese e, em seguida, nos esquecemos felizes da coisa toda.
Mutação de dados compactados
Vamos supor que a declaração do problema tenha sido reduzida a um único ponto: precisamos gerar dados com a mesma taxa de compactação que os dados de origem e os dados devem ser descomprimidos na mesma velocidade. Como podemos conseguir isso? Precisamos editar bytes de dados compactados diretamente! Isso nos permite alterar os dados sem alterar o tamanho dos dados compactados, além de tudo funcionar rápido. Eu queria experimentar essa idéia imediatamente, apesar do fato de que o problema que ela resolve não é o mesmo que começamos. Mas é assim que sempre é.
Então, como editamos um arquivo compactado? Digamos que estamos interessados apenas no LZ4. Os dados compactados do LZ4 são compostos por sequências, que por sua vez são cadeias de bytes não compactados (literais), seguidas por uma cópia de correspondência:
- Literais (copie os seguintes N bytes como estão).
- Corresponde a um comprimento mínimo de repetição de 4 (N bytes de repetição que estavam no arquivo a uma distância de M).
Dados de origem:
Hello world Hello .
Dados compactados (exemplo arbitrário):
literals 12 "Hello world " match 5 12 .
No arquivo compactado, deixamos "match" como está e alteramos os valores de byte em "literais". Como resultado, após a descompactação, obtemos um arquivo no qual todas as seqüências repetidas de pelo menos 4 bytes também são repetidas na mesma distância, mas consistem em um conjunto diferente de bytes (basicamente, o arquivo modificado não contém um único byte que foi retirado do arquivo de origem).
Mas como mudamos os bytes? A resposta não é óbvia, porque além dos tipos de coluna, os dados também têm sua própria estrutura implícita e interna que gostaríamos de preservar. Por exemplo, o texto geralmente é armazenado na codificação UTF-8 e queremos que os dados gerados também sejam UTF-8 válidos. Eu desenvolvi uma heurística simples que envolve atender a vários critérios:
- Bytes nulos e caracteres de controle ASCII são mantidos como estão.
- Alguns caracteres de pontuação permanecem como estão.
- O ASCII é convertido em ASCII e, para todo o resto, o bit mais significativo é preservado (ou um conjunto explícito de instruções "if" é gravado para diferentes comprimentos UTF-8). Em uma classe de bytes, um novo valor é escolhido uniformemente aleatoriamente.
- Fragmentos como
https:// são preservados, caso contrário, parece um pouco bobo.
A única ressalva a essa abordagem é que o modelo de dados são os próprios dados de origem, o que significa que não podem ser publicados. O modelo é adequado apenas para gerar quantidades de dados não maiores que a fonte. Pelo contrário, as abordagens anteriores fornecem modelos que permitem gerar dados de tamanho arbitrário.
Exemplo para um URL:
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXeAyAx
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXe
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwdbknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu-702130
Os resultados foram positivos e os dados foram interessantes, mas algo não estava certo. Os URLs mantinham a mesma estrutura, mas em alguns deles era muito fácil reconhecer "yandex" ou "avito" (um mercado popular na Rússia), então criei uma heurística que troca alguns bytes.
Havia outras preocupações também. Por exemplo, informações confidenciais poderiam residir em uma coluna FixedString na representação binária e, potencialmente, consistir em caracteres de controle ASCII e pontuação, que decidi preservar. No entanto, não levei em consideração os tipos de dados.
Outro problema é que, se uma coluna armazena dados no formato "comprimento, valor" (é assim que as colunas String são armazenadas), como posso garantir que o comprimento permaneça correto após a mutação? Quando tentei consertar isso, perdi o interesse imediatamente.
Permutações aleatórias
Infelizmente, o problema não foi resolvido. Realizamos alguns experimentos, e ficou pior. A única coisa que restava era ficar sentado sem fazer nada e navegar na web aleatoriamente, já que a mágica se fora. Felizmente, me deparei com uma página que
explicava o algoritmo para renderizar a morte do personagem principal no jogo Wolfenstein 3D.

A animação é realmente muito boa - a tela se enche de sangue. O artigo explica que essa é realmente uma permutação pseudo-aleatória. Uma permutação aleatória de um conjunto de elementos é uma transformação bijetiva (um a um) escolhida aleatoriamente do conjunto, ou um mapeamento em que cada elemento derivado corresponde exatamente a um elemento original (e vice-versa). Em outras palavras, é uma maneira de iterar aleatoriamente todos os elementos de um conjunto de dados. E esse é exatamente o processo mostrado na figura: cada pixel é preenchido em ordem aleatória, sem repetição. Se escolhermos apenas um pixel aleatório em cada etapa, levará muito tempo para chegar ao último.
O jogo usa um algoritmo muito simples para permutação pseudo-aleatória chamado registro de deslocamento de feedback linear (
LFSR ). Semelhante a geradores de números pseudo-aleatórios, permutações aleatórias, ou melhor, suas famílias, podem ser criptograficamente fortes quando parametrizados por uma chave. É exatamente isso que precisamos para a transformação de dados. No entanto, os detalhes podem ser mais complicados. Por exemplo, a criptografia criptograficamente forte de N bytes a N bytes com uma chave pré-determinada e um vetor de inicialização parece funcionar para uma permutação pseudo-aleatória de um conjunto de cadeias de caracteres de N bytes. De fato, essa é uma transformação individual e parece ser aleatória. Mas se usarmos a mesma transformação para todos os nossos dados, o resultado poderá ser suscetível à criptoanálise, porque o mesmo vetor de inicialização e valor da chave são usados várias vezes. É semelhante ao modo de operação do
livro de
códigos eletrônico para uma cifra de bloco.
Quais são as formas possíveis de obter uma permutação pseudo-aleatória? Podemos realizar transformações individuais simples e criar uma função complexa que parece aleatória. Aqui estão algumas das minhas transformações individuais favoritas:
- Multiplicação por um número ímpar (como um grande número primo) na aritmética do complemento de dois.
- Deslocamento
x ^= x >> N : x ^= x >> N - CRC-N, onde N é o número de bits no argumento.
Por exemplo, três multiplicações e duas operações xorshift são usadas para o finalizador de
sopro . Esta operação é uma permutação pseudo-aleatória. No entanto, devo salientar que as funções de hash não precisam ser um para um (mesmo hashes de N bits a N bits).
Ou aqui está outro
exemplo interessante
da teoria elementar dos números no site de Jeff Preshing.
Como podemos usar permutações pseudo-aleatórias para resolver nosso problema? Podemos usá-los para transformar todos os campos numéricos para preservar as cardinalidades e cardinalidades mútuas de todas as combinações de campos. Em outras palavras, COUNT (DISTINCT) retornará o mesmo valor que antes da transformação e, além disso, com qualquer GROUP BY.
Vale ressaltar que a preservação de todas as cardinalidades contradiz de alguma forma nosso objetivo de anonimização dos dados. Digamos que alguém saiba que os dados de origem das sessões do site contêm um usuário que visitou sites de 10 países diferentes e desejam encontrar esse usuário nos dados transformados. Os dados transformados também mostram que o usuário visitou sites de 10 países diferentes, o que facilita a busca. Mesmo que eles descubram em que o usuário foi transformado, isso não será muito útil, porque todos os outros dados também foram transformados, para que eles não consigam descobrir em quais sites o usuário visitou ou qualquer outra coisa. Mas essas regras podem ser aplicadas em cadeia. Por exemplo, se alguém sabe que o site que ocorre com mais frequência em nossos dados é o Yandex, com o Google em segundo lugar, ele pode usar a classificação para determinar quais identificadores de site transformados realmente significam Yandex e Google. Não há nada de surpreendente nisso, pois estamos trabalhando com uma declaração informal de problemas e estamos apenas tentando encontrar um equilíbrio entre o anonimato dos dados (ocultação de informações) e a preservação das propriedades dos dados (revelação de informações). Para obter informações sobre como abordar o problema de anonimização de dados com mais confiabilidade, leia este
artigo .
Além de manter a cardinalidade original dos valores, também quero manter a ordem de magnitude dos valores. O que quero dizer é que, se os dados de origem contiverem números abaixo de 10, desejo que os números transformados também sejam pequenos. Como podemos conseguir isso?
Por exemplo, podemos dividir um conjunto de valores possíveis em classes de tamanho e executar permutações dentro de cada classe separadamente (mantendo as classes de tamanho). A maneira mais fácil de fazer isso é usar a potência mais próxima de duas ou a posição do bit mais significativo no número como a classe de tamanho (estas são a mesma coisa). Os números 0 e 1 sempre permanecerão como estão. Os números 2 e 3 às vezes permanecem como estão (com probabilidade de 1/2) e às vezes são trocados (com probabilidade de 1/2). O conjunto de números 1024. 2047 será mapeado para um dos 1024! variantes (fatoriais) e assim por diante. Para números assinados, manteremos o sinal.
Também é duvidoso que precisamos de uma função individual. Provavelmente, podemos apenas usar uma função hash criptograficamente forte. A transformação não será individual, mas a cardinalidade será próxima da mesma.
No entanto, precisamos de uma permutação aleatória criptograficamente forte para que, quando definirmos uma chave e derivarmos uma permutação com essa chave, seria difícil restaurar os dados originais dos dados reorganizados sem conhecê-la.
Há um problema: além de não saber nada sobre redes neurais e aprendizado de máquina, também sou bastante ignorante quando se trata de criptografia. Isso deixa apenas minha coragem. Eu ainda estava lendo páginas aleatórias da web e encontrei um link no
Hackers News para uma discussão na página de Fabien Sanglard. Tinha um link para um
post do desenvolvedor do Redis, Salvatore Sanfilippo, que falava sobre o uso de uma maneira genérica maravilhosa de obter permutações aleatórias, conhecida como
rede Feistel .
A rede Feistel é iterativa, composta por rodadas. Cada rodada é uma transformação notável que permite que você obtenha uma função individual de qualquer função. Vamos ver como isso funciona.
- Os bits do argumento são divididos em duas metades:
arg: xxxxyyyy
arg_l : xxxx
arg_r : yyyy - A metade direita substitui a esquerda. Em seu lugar, colocamos o resultado de XOR no valor inicial da metade esquerda e o resultado da função aplicada ao valor inicial da metade direita, assim:
res: yyyyzzzz
res_l = yyyy = arg_r
res_r = zzzz = arg_l ^ F( arg_r )
Há também uma alegação de que, se usarmos uma função pseudo-aleatória criptograficamente forte para F e aplicar uma rodada de Feistel pelo menos 4 vezes, obteremos uma permutação pseudo-aleatória criptograficamente forte.
Isso é como um milagre: pegamos uma função que produz lixo aleatório com base em dados, inserimos na rede Feistel e agora temos uma função que produz lixo aleatório com base em dados, mas, no entanto, é invertível!
A rede Feistel está no centro de vários algoritmos de criptografia de dados. O que vamos fazer é algo como criptografia, só que é muito ruim. Há duas razões para isso:
- Estamos criptografando valores individuais de forma independente e da mesma maneira, semelhante ao modo de operação do Electronic Codebook.
- Estamos armazenando informações sobre a ordem de magnitude (a potência mais próxima de duas) e o sinal do valor, o que significa que alguns valores não mudam.
Dessa forma, podemos ofuscar os campos numéricos enquanto preservamos as propriedades necessárias. Por exemplo, depois de usar o LZ4, a taxa de compactação deve permanecer aproximadamente a mesma, porque os valores duplicados nos dados de origem serão repetidos nos dados convertidos e nas mesmas distâncias entre si.
Modelos de Markov
Os modelos de texto são usados para compactação de dados, entrada preditiva, reconhecimento de fala e geração aleatória de cadeias. Um modelo de texto é uma distribuição de probabilidade de todas as seqüências possíveis. Digamos que temos uma distribuição de probabilidade imaginária dos textos de todos os livros que a humanidade poderia escrever. Para gerar uma string, apenas pegamos um valor aleatório com essa distribuição e retornamos a string resultante (um livro aleatório que a humanidade poderia escrever). Mas como descobrimos a distribuição de probabilidade de todas as seqüências possíveis?
Primeiro, isso exigiria muita informação. Existem 256 ^ 10 sequências possíveis com 10 bytes de comprimento e seria necessário bastante memória para escrever explicitamente uma tabela com a probabilidade de cada sequência. Segundo, não temos estatísticas suficientes para avaliar com precisão a distribuição.
É por isso que usamos uma distribuição de probabilidade obtida de estatísticas aproximadas como modelo de texto. Por exemplo, podemos calcular a probabilidade de cada letra que ocorre no texto e, em seguida, gerar strings selecionando cada letra seguinte com a mesma probabilidade. Esse modelo primitivo funciona, mas as strings ainda são muito antinaturais.
Para melhorar um pouco o modelo, também poderíamos fazer uso da probabilidade condicional da ocorrência da letra se ela for precedida por N letras específicas. N é uma constante predefinida. Digamos N = 5 e estamos calculando a probabilidade da letra "e" ocorrer após as letras "compr". Esse modelo de texto é chamado de modelo Order-N Markov.
P(cat a | cat) = 0.8
P(cat b | cat) = 0.05
P(cat c | cat) = 0.1
...Vejamos como os modelos de Markov funcionam no site
da Hay Kranen . Diferentemente das redes neurais LSTM, os modelos têm memória suficiente para um pequeno contexto de N de comprimento fixo, gerando textos engraçados e sem sentido. Os modelos Markov também são usados em métodos primitivos para gerar spam, e os textos gerados podem ser facilmente distinguidos dos reais contando estatísticas que não se encaixam no modelo. Há uma vantagem: os modelos de Markov funcionam muito mais rápido que as redes neurais, que é exatamente o que precisamos.
Exemplo de título (nossos exemplos estão em turco devido aos dados utilizados):
Hyunday Butter'dan anket shluha - Politika head manşetleri | STALKER BOXER Livro de luxo - Yanudistkarışmanlı Mı Kanal | League el Digitalika Haberler Haberleri - Haberlerisi - Hotéis com Centry'ler Neden babah.com
Podemos calcular estatísticas a partir dos dados de origem, criar um modelo de Markov e gerar novos dados com ele. Observe que o modelo precisa de suavização para evitar a divulgação de informações sobre combinações raras nos dados de origem, mas isso não é um problema. Eu uso uma combinação de modelos de 0 a N. Se as estatísticas forem insuficientes para o modelo da ordem N, o modelo N-1 será usado.
Mas ainda queremos preservar a cardinalidade dos dados. Em outras palavras, se os dados de origem tiverem 123456 valores de URL exclusivos, o resultado deverá ter aproximadamente o mesmo número de valores exclusivos. Podemos usar um gerador de números aleatórios inicializado deterministicamente para conseguir isso. A maneira mais fácil de fazer isso é usar uma função de hash e aplicá-la ao valor original. Em outras palavras, obtemos um resultado pseudo-aleatório que é explicitamente determinado pelo valor original.
Outro requisito é que os dados de origem possam ter muitos URLs diferentes que começam com o mesmo prefixo, mas não são idênticos. Por exemplo:
https://www.yandex.ru/images/cats/?id=xxxxxx . Queremos que o resultado também tenha URLs que todos começam com o mesmo prefixo, mas um diferente. Por exemplo:
http://ftp.google.kz/cgi-bin/index.phtml?item=xxxxxx . Como um gerador de números aleatórios para gerar o próximo caractere usando um modelo de Markov, usaremos uma função hash de uma janela móvel de 8 bytes na posição especificada (em vez de removê-la de toda a cadeia).
https://www.yandex.ru/ images/c ats/?id=12345
^^^^^^^^
distribution: [aaaa][b][cc][dddd][e][ff][g g ggg][h]...
hash(" images/c ") % total_count: ^
http://ftp.google.kz/c g ...Acontece ser exatamente o que precisamos. Aqui está o exemplo dos títulos das páginas:
PhotoFunia - Haber7 - Hava mükemment.net Oynamak içinde şaşıracak haber, Oyunu Oynanılmaz • apród.hu kínálatában - RT Arabic
PhotoFunia - Kinobar.Net - abr: Ingyenes | Posti
PhotoFunia - Peg Perfeo - Castika, Sıradışı Deniz Lokoning Your Code, senhor Eminema.tv/
PhotoFunia - TUT.BY - Seu Ayakkanın ve Son Dakika Spor,
PhotoFunia - grande filme, Del Meireles offilim, Samsung DealeXtreme Değerler NEWSru.com.tv, Smotri.com Celular
PhotoFunia 5 | Galaxy, gt, după ce analgi yarak Ceza RE050A V-Stranç
PhotoFunia :: Vídeo de Miami Haberler Oyun Young
PhotoFunia Monstelli'nin Em İyi kisa.com.tr - Star Thunder Ekranı
PhotoFunia Seks - Política, Economia, Spor GTA SANAYİ VE
TVFunia Starker Rating Star Resmi Söylenen Yatağa każdy dzież wierzchnie
PhotoFunia TourIndex.Marketime oyunu Oyna Geldoll Mynet Spor, Magazin, Haberler yerel Haberleri ve Solvia, colaboração Ev SahneTv
Todo o PhotoFunia no fotograma de Partida alegre grátis
PhotoFunian Dünyasın takımız halles en kulları - TEZ
Resultados
Depois de tentar quatro métodos, fiquei tão cansado desse problema que chegou a hora de escolher algo, transformá-lo em uma ferramenta utilizável e anunciar a solução. Eu escolhi a solução que usa permutações aleatórias e modelos de Markov parametrizados por uma chave. É implementado como o programa
clickhouse-obfuscator , que é muito fácil de usar. A entrada é um despejo de tabela em
qualquer formato suportado (como CSV ou JSONEachRow) e os parâmetros da linha de comandos especificam a estrutura da tabela (nomes e tipos de colunas) e a chave secreta (qualquer sequência que você possa esquecer imediatamente após o uso). A saída é o mesmo número de linhas de dados ofuscados.
O programa é instalado com o clickhouse-client, não possui dependências e funciona em praticamente qualquer sabor do Linux. Você pode aplicá-lo a qualquer despejo de banco de dados, não apenas ao ClickHouse. Por exemplo, você pode gerar dados de teste dos bancos de dados MySQL ou PostgreSQL ou criar bancos de dados de desenvolvimento semelhantes aos bancos de dados de produção.
clickhouse-obfuscator \
--seed "$(head -c16 /dev/urandom | base64)" \
--input-format TSV --output-format TSV \
--structure 'CounterID UInt32, URLDomain String, \
URL String, SearchPhrase String, Title String' \
< table.tsv > result.tsv
clickhouse-obfuscator --help
Obviamente, tudo não é tão fácil de cortar e secar, porque os dados transformados por esse programa são quase completamente reversíveis. A questão é se é possível executar a transformação reversa sem conhecer a chave. Se a transformação usasse um algoritmo criptográfico, essa operação seria tão difícil quanto uma pesquisa de força bruta. Embora a transformação use algumas primitivas criptográficas, elas não são usadas da maneira correta e os dados são suscetíveis a certos métodos de análise. Para evitar problemas, esses problemas são abordados na documentação do programa (acesse-o usando
--help ).
No final, transformamos o conjunto de dados que precisamos
para testes funcionais e de desempenho e o Yandex VP de publicação aprovada em segurança de dados.
clickhouse-datasets.s3.yandex.net/hits/tsv/hits_v1.tsv.xzclickhouse-datasets.s3.yandex.net/visits/tsv/visits_v1.tsv.xzOs desenvolvedores que não são Yandex usam esses dados para testes de desempenho reais ao otimizar algoritmos dentro do ClickHouse. Usuários de terceiros podem nos fornecer seus dados ofuscados para que possamos tornar o ClickHouse ainda mais rápido para eles. Também lançamos um benchmark aberto independente para fornecedores de hardware e nuvem com base
nesses dados:
clickhouse.yandex/benchmark_hardware.html