 Aqui está uma lista atualizada dos mais maravilhosos "brindes" Unicode, bem como pacotes e recursos
Aqui está uma lista atualizada dos mais maravilhosos "brindes" Unicode, bem como pacotes e recursosUnicode é incrível! Antes de sua aparição, a comunicação internacional era exaustiva: cada um definia seu próprio conjunto de caracteres estendidos separado na metade superior do ASCII (as chamadas páginas de código). Isso criou conflito. Basta pensar que os alemães tiveram que negociar com os coreanos, onde está a página de códigos de quem. Felizmente, o Unicode apareceu e introduziu um padrão comum. O Unicode 8.0 cobre mais de 120.000 caracteres de mais de 129 scripts. Moderno e antigo, e ainda não decifrado. O Unicode suporta texto da esquerda para a direita e da direita para a esquerda, sobrepõe caracteres e inclui uma variedade de símbolos culturais e políticos, religiosos e emojis. O Unicode é incrivelmente humano e suas capacidades são muito subestimadas.
Conteúdo
Breve introdução
Quais caracteres estão incluídos no Unicode Standard?
O padrão Unicode define códigos para caracteres nos principais idiomas modernos. São scripts alfabéticos europeus, scripts do Oriente Médio da direita para a esquerda e muitos scripts asiáticos.
O padrão também contém sinais de pontuação, diacríticos, símbolos matemáticos, símbolos técnicos, setas, símbolos, emojis etc. Ele fornece códigos para diacríticos que alteram sinais de caracteres, como til (~). Eles são usados em combinação com os básicos para representar caracteres acentuados (por exemplo, ñ). Em geral, o Unicode versão 9.0 fornece códigos para 128.172 caracteres de alfabetos mundiais, conjuntos de ideogramas e coleções de caracteres.
Os caracteres mais comuns são colocados nos primeiros pontos de código de 64 K, uma área do espaço de código chamada plano multilíngue principal ou BMP, abreviado. Existem dezesseis outros planos adicionais disponíveis para codificar outros caracteres, com mais de 850.000 pontos de código não utilizados. Eles podem ser úteis para adicionar novos personagens a versões futuras do padrão.
O padrão Unicode também reserva pontos de código para uso privado. Fornecedores ou usuários finais podem designá-los em seus próprios sistemas para seus personagens ou usá-los com fontes especializadas. O BMP possui 6400 pontos de código para uso privado e outros 131 068 pontos de código adicionais para uso privado, se 6400 não for suficiente para aplicativos específicos.
Codificações de caracteres Unicode
Os padrões de codificação de caracteres determinam não apenas a identidade de cada caractere e seu valor numérico ou ponto de código, mas também como esse valor é representado em bits.
O padrão Unicode define três formas de codificação que permitem a transmissão dos mesmos dados: um byte, uma palavra e uma palavra dupla (ou seja, 8, 16 ou 32 bits por unidade de código). Todos os três formulários codificam o mesmo conjunto de caracteres comum e podem ser efetivamente convertidos um no outro sem perda de dados. O Consórcio Unicode endossa totalmente o uso de qualquer um desses formulários de codificação como uma maneira acordada de implementar o Padrão Unicode.
UTF-8 é popular para protocolos HTML e similares. UTF-8 é uma maneira de converter todos os caracteres Unicode em uma codificação variável de comprimento de bytes. Sua vantagem é que os caracteres Unicode que correspondem ao conjunto ASCII familiar têm os mesmos valores de bytes que o ASCII, e os caracteres Unicode convertidos em UTF-8 podem ser usados com muitos softwares existentes, sem grandes modificações.
O UTF-16 é popular em muitos ambientes em que é necessário equilibrar o acesso eficiente a caracteres com armazenamento econômico. É bastante compacto e todos os caracteres usados com freqüência são colocados em um bloco de código de 16 bits, enquanto todos os outros caracteres estão disponíveis através de pares de blocos de código de 16 bits.
UTF-32 é útil quando a quantidade de memória não é uma preocupação, mas requer acesso a caracteres em um único código de largura fixa. Aqui, cada caractere Unicode é codificado em um único bloco de código de 32 bits.
Todas as três formas de codificação requerem não mais que 4 bytes (ou 32 bits) para cada caractere.
Fale sobre números
O conjunto de caracteres Unicode é dividido em 17 segmentos principais (planos), que são divididos em blocos. Em cada plano, há um lugar para 65 536 (2
16 ) pontos de código, o que cria um total de 1.114.112 pontos de código. Existem dois "planos de uso privado" (nº 16 e nº 17) que são alocados para uso a critério das empresas / usuários. Eles possuem 131.072 pontos de código.
O primeiro plano é chamado de principal plano multilíngue ou BMP. Ele contém pontos de código de U + 0000 a U + FFFF, ou seja, os caracteres mais usados. Os dezesseis planos restantes (U + 010000 → U + 10FFFF) são chamados adicionais ou astrais.
Pares substitutos UTF-16
Símbolos fora do plano principal, como um tetragrammaton que significa o centro (U + 1D306), podem ser codificados em UTF-16 com apenas duas unidades de código de 16 bits: 0xD834 0xDF06. Isso é chamado de par substituto. Observe que um par substituto representa apenas um caractere.
A primeira unidade de código de um par substituto está sempre no intervalo de 0xD800 a 0xDBFF e é chamada de parte superior do par.
A segunda unidade de código do par substituto está sempre no intervalo de 0xDC00 a 0xDFFF e é chamada de parte inferior do par.
Matthias Binens
Par substituto: uma representação de um símbolo abstrato, consistindo em uma sequência de duas unidades de código de 16 bits, em que o primeiro valor do par é a unidade de código substituto superior e o segundo é a unidade de código substituto inferior. Pares substitutos são usados apenas no UTF-16.
Unicode 8.0 Capítulo 3.8 - Substitutos
Cálculo de pares substitutos
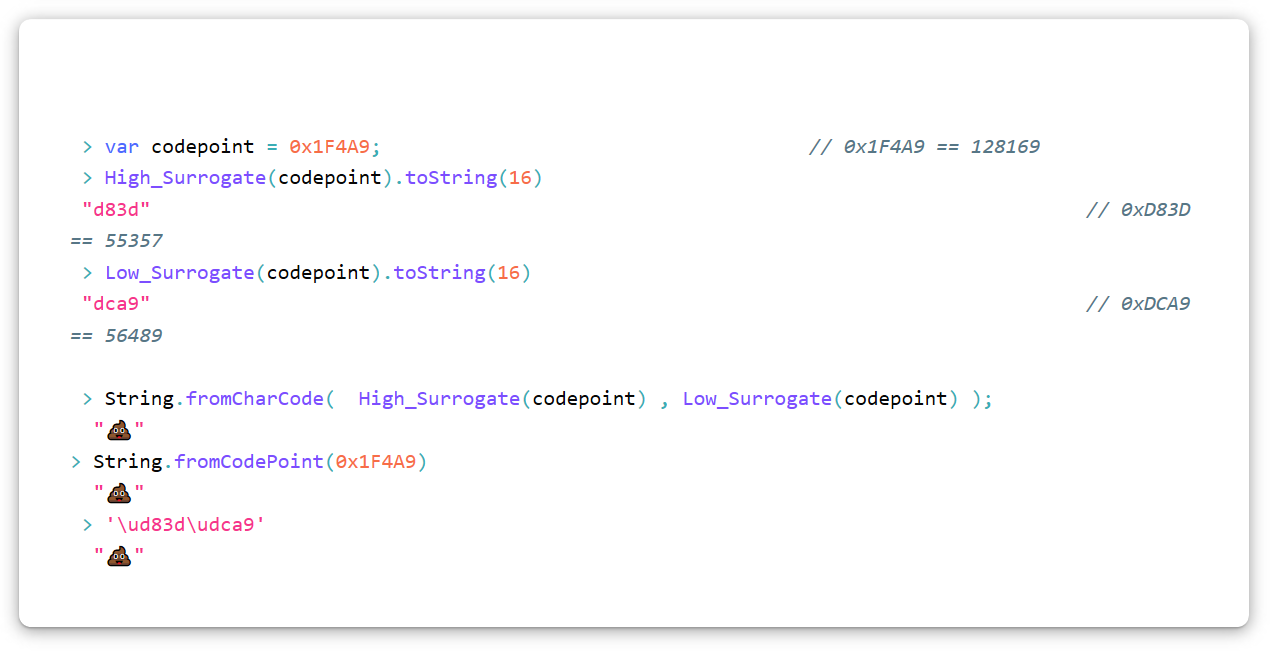
O caractere Unicode "Pilha de merda" (U + 1F4A9) no UTF-16 terá que ser codificado como um par substituto, ou seja, dois substitutos. Para converter qualquer ponto de código em um par substituto, use este algoritmo (em JavaScript). Lembre-se de que usamos notação hexadecimal.
var High_Surrogate = function(Code_Point){ return Math.floor((Code_Point - 0x10000) / 0x400) + 0xD800 }; var Low_Surrogate = function(Code_Point){ return (Code_Point - 0x10000) % 0x400 + 0xDC00 };
Composição e decomposição
O Unicode inclui um mecanismo para alterar a forma de um caractere, que estende bastante o conjunto de glifos com suporte. Isso se aplica aos diacríticos combináveis. Eles são inseridos após o personagem principal. Várias marcas diacríticas podem ser aplicadas à mesma marca. O Unicode também contém versões pré-compiladas da maioria dessas combinações para uso normal.
Algumas seqüências de caracteres também podem ser representadas como um único caractere chamado de caráter pré-composto, também conhecido como caráter composto. Por exemplo, o caractere [ü] pode ser codificado como o único ponto de código U + 00FC ou como o caractere base U + 0075 (u), seguido pelo caractere não independente U + 0308 (¨). O padrão Unicode codifica caracteres compostos para compatibilidade com padrões estabelecidos, como o Latim 1, que inclui muitos caracteres compostos, como [ü] e [ñ].
Caracteres compostos podem ser expandidos para consistência ou análise. Por exemplo, ao classificar em ordem alfabética, o símbolo [ü] pode ser decomposto em [u] seguido pelo símbolo não independente [¨]. Após essa decomposição, o algoritmo fica mais fácil de trabalhar com uma sequência de caracteres. Isso facilita a classificação em idiomas onde os modificadores de caracteres não afetam a ordem alfabética. O padrão Unicode define a
ordem de decomposição para todos os caracteres compostos. Ele também define formas de normalização para fornecer representações exclusivas de caracteres.
Mitos Unicode
Dos slides da apresentação de Mark Davis "Mitos do Unicode" .- Unicode é apenas um código de 16 bits . - Algumas pessoas acreditam erroneamente que Unicode é apenas um código de 16 bits, no qual cada caractere ocupa 16 bits e, portanto, existem 65.536 caracteres possíveis. De fato, isso não é inteiramente verdade. Esse é o mito Unicode mais comum; portanto, se você também pensava assim antes, não desanime.
- Você pode usar qualquer ponto de código que não seja usado para suas necessidades . - não. Algum dia, este lugar será substituído por outro símbolo. Em vez disso, use aviões para uso particular ou áreas sem caracteres em cada plano onde não haverá caracteres por padrão.
- Cada ponto de código Unicode representa um caractere . - não. Existem muitos pontos sem caracteres (FFFE, FFFF, 1FFFE etc.) Além disso, pontos de código substitutos, pontos de código privados e não utilizados, além de "caracteres" de controle / formatação (RLM, ZWNJ, etc.)
- O Unicode fica sem espaço . - Se preenchesse linearmente, terminaria em 2140. Mas o local não preenche linearmente. Planos futuros ver aqui .
- Todos os caracteres são correspondidos um a um . - não. As opções são:
- Um para muitos: (β → SS)
- Dado o contexto: (... Σ ← → ... ς e ao mesmo tempo ... ΣΤ ... ← → ... στ ...)
- Com base na localidade: (I ← → ı e ao mesmo tempo İ ← → i)
Codificações de aplicativos Unicode
Código fonte
Lista de personagens incríveis.
Compartilhar um documento pode transformar rapidamente a edição em uma batalha de rap escrita, travada por um arranjo cada vez mais confuso de gerentes de U + 202a a U + 202eCaracteres especiais
O Unicode Consortium publicou
um diagrama de pontuação geral, onde você pode encontrar mais informações.
Espere ... o que eu acabei de ler?Identificadores variáveis podem incluir espaços!
O espaço reservado U + 3164 Hangul é exibido como um espaço amplo. Se o caractere não for claramente
suportado na renderização , ele será exibido como completamente invisível (e não ocupa espaço, ou seja, "largura zero"). Isso significa que você nunca verá um caractere de substituição de caractere feio ( ).
Ainda não sei ao certo por que o U + 3164 é instruído a se comportar dessa maneira. Curiosamente, o U + 3164 foi adicionado ao Unicode na versão 1.1 (1993) - então os especialistas do Consortium tiveram muito tempo para pensar sobre isso. De qualquer forma, aqui estão alguns exemplos.
> var ᅟ = 'foo'; undefined > ᅟ 'foo' > var ㅤ= alert; undefined > var foo = 'bar' undefined > if ( foo ===ㅤ`baz` ){}
** Nota: ** Testei a renderização U + 3164 no Ubuntu e OS X com os seguintes parâmetros: `node`,` php`, `ruby`,` python3.5`, `scala`,` vim`, `cat` , `chrome` +` github gist '. Atom é o único sistema que falha ao exibir incorretamente campos vazios. Ainda tenho que verificar o código no Emacs e Sublime. Pelo que entendi, o Unicode Consortium não irá reatribuir ou renomear caracteres ou pontos de código, mas pode ser persuadido a alterar as propriedades de caracteres, como ID_Start e ID_Continue.Modificadores
O Zero Width Combiner (ZWJ) é um caractere não imprimível em um conjunto de computadores de algumas fontes complexas, como árabe ou qualquer fonte indiana. Quando colocado entre dois caracteres que não estariam conectados, o ZWJ os obriga a imprimir de forma combinada.
O desconector de largura zero (ZWNJ) é um caractere não imprimível em conjuntos de gravação baseados em computador com ligaduras. Quando colocados entre dois caracteres que de outra forma seriam unidos a uma ligadura, o ZWNJ os obriga a imprimir em suas formas final e original, respectivamente. Atua como um espaço, mas é usado quando é desejável manter as palavras próximas umas das outras ou combinar uma palavra com seu morfema.
> 'a' "a" > 'a\u{0308}' "ä" > 'a\u{20DE}\u{0308}' "a⃞̈" > 'a\u{20DE}\u{0308}\u{20DD}' "a⃞̈⃝"
Colisões de transformação em maiúsculas
Colisões de conversão em minúsculas
Peculiaridades e solução de problemas
- O comprimento da linha geralmente é determinado pelo número de pontos de código . Isso significa que pares substitutos serão considerados dois caracteres. Vários diacríticos podem ser sobrepostos a um símbolo:
a + ̈ == ̈a . Isso aumenta o comprimento da cadeia, produzindo apenas um caractere.
- Da mesma forma, a inversão de string geralmente se torna uma tarefa não trivial . Novamente, pares substitutos e diacríticos devem ser revertidos juntos. O ES Reverser oferece uma solução muito boa.
- As comparações em maiúsculas e minúsculas nem sempre correspondem . Eles podem ser expressos em tais relacionamentos:
- Um para muitos: (ß → SS)
- Dado o contexto: (... Σ ← → ... ς e ... ΣΤ ... ← → ... στ ...)
- Com base na localidade: (I ← → ı e İ ← → i)
Uma para muitas comparações
A maioria dos caracteres abaixo expressa seus mapeamentos um para muitos em letras maiúsculas e outros em letras minúsculas. Em princípio, a lista pode ser dividida em duas partes.
Ótimos pacotes e bibliotecas
- PhantomScript -: ghost :: flashlight: Executando JavaScript invisível e engenharia social
- ESReverser - manipulação de string JavaScript baseada em Unicode .
- mimic - Uso indevido de Unicode
- python-ftfy - tenta criar a máxima representação correta e completa do texto recebido no Unicode.
- vim-troll-stopper - Proteja seu código contra trolls unicode.
Emoji
Unicode (diversity), . .
, , . — . :
, .
8.0 ( 2015 ) - . , ( , FitzpatrickSkinType.pdf). .
Unicode
, \u{1F466}\u{1F3FE} .

+

→


JavaScript (ES6)
, ID_START , . , ID_CONTINUE , .
CSS .
<!-- place this within the document head --> <meta charset="UTF-8" /> <div class="ಠ_ಠ">You do not have access to this page.</div> <div class="">Your changes have been saved successfully!</div>
.ಠ_ಠ { border: 1px solid #f00; } . { background: lightgreen; }
HTML
HTML- , , .
, HTML .
:
function testBegin(str){ try{ eval(`document.createElement( '${str}' );`) return true; } catch(e){ return false; } } function testContinue(str){ try{ eval(`document.createElement( 'a${str}' );`) return true; } catch(e){ return false; } }
:
TrueType OpenType UTF-8, 65 535 . 1,1 UTF-8, .
256 .

, () (CJK). , , « ».
. 17- .
:
- — - .
- — , .
- — .
- — , . .
- , — , . , .
- — , . , [Ä] [A] [¨].
- — .
- — , , . .
- — , .
- — .
: c codepoints.net .