
Na Serokell, não estamos apenas envolvidos em projetos comerciais, mas também nos esforçamos para mudar o mundo para melhor. Por exemplo, estamos trabalhando para melhorar a principal ferramenta de todos os haskelistas - o Glasgow Haskell Compiler (GHC). Nosso foco foi expandir o sistema de tipos sob a influência do trabalho de Richard Eisenberg, "Tipos Dependentes em Haskell: Teoria e Prática" .
Em nosso blog, Vladislav já falou sobre o porquê de Haskell não ter tipos dependentes e como planejamos adicioná-los. Decidimos traduzir este post para o russo para que o maior número possível de desenvolvedores pudesse usar tipos dependentes e dar uma contribuição adicional ao desenvolvimento do Haskell como idioma.
Situação atual
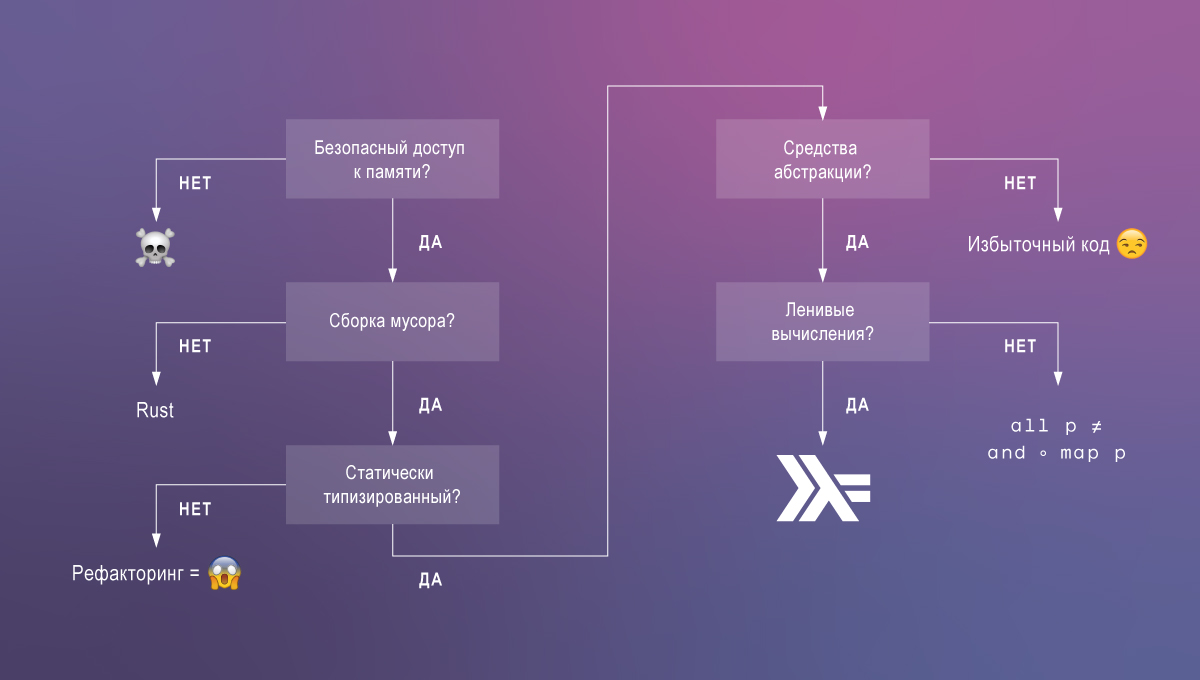
Tipos dependentes são o que mais sinto falta em Haskell. Vamos discutir o porquê. Do código que queremos:
- desempenho, ou seja, velocidade de execução e baixo consumo de memória;
- manutenibilidade e facilidade de entendimento;
- correção garantida pelo método de compilação.
Com as tecnologias existentes, raramente é possível atingir as três características, mas com suporte para os tipos dependentes de Haskell, a tarefa é simplificada.
Padrão Haskell: Ergonomia + Desempenho
Haskell é baseado em um sistema simples: um cálculo lambda polimórfico com cálculos preguiçosos, tipos de dados algébricos e classes de tipos. É essa combinação de recursos de linguagem que nos permite escrever um código elegante, suportado e ao mesmo tempo produtivo. Para fundamentar essa afirmação, comparamos brevemente o Haskell com os idiomas mais populares.
Idiomas com acesso inseguro à memória, como C, levam a erros e vulnerabilidades mais graves (por exemplo, estouros de buffer, vazamentos de memória). Às vezes, essas linguagens são necessárias, mas na maioria das vezes o uso delas é uma idéia mais ou menos.
Os idiomas de acesso seguro à memória formam dois grupos: aqueles que dependem do coletor de lixo e Rust. A ferrugem parece ser única ao oferecer acesso seguro à memória sem coleta de lixo . Também não há mais suporte ao Cyclone e outras linguagens de pesquisa neste grupo. Mas, diferentemente deles, o Rust está a caminho da popularidade. A desvantagem é que, apesar da segurança, o gerenciamento de memória do Rust não é trivial e manual. Em aplicativos que podem permitir o uso do coletor de lixo, é melhor gastar o tempo dos desenvolvedores em outras tarefas.
Existem idiomas restantes nos coletores de lixo, que serão divididos em duas categorias com base no sistema de tipos.
Linguagens dinamicamente tipadas (ou melhor, monotipadas ), como JavaScript ou Clojure, não fornecem análise estática e, portanto, não podem fornecer o mesmo nível de confiança na correção do código (e não, os testes não podem substituir os tipos - você precisa de ambos) !).
Linguagens de tipo estático, como Java ou Go, geralmente têm um sistema de tipo muito limitado. Isso força os programadores a escrever código redundante e colocar recursos de linguagem inseguros. Por exemplo, a falta de tipos genéricos no Go força o uso da interface {} e a conversão de tipos de tempo de execução . Também não há separação entre cálculos com efeitos colaterais (entrada, saída) e cálculos puros.
Por fim, entre os idiomas com acesso seguro à memória, um coletor de lixo e um poderoso sistema de tipos, Haskell se destaca pela preguiça. A computação preguiçosa é extremamente útil para escrever código modular e compostável. Eles possibilitam decompor em definições auxiliares qualquer parte das expressões, incluindo construções que definem um fluxo de controle.
Haskell parece ser uma linguagem quase perfeita até você perceber até que ponto está liberando todo o seu potencial em termos de verificação estática em comparação com ferramentas de prova de teoremas, como a Agda .
Como um exemplo simples de onde o sistema do tipo Haskell não é poderoso o suficiente, considere o operador de indexação de lista da Prelude (ou a indexação de uma matriz de um pacote primitive ):
(!!) :: [a] -> Int -> a indexArray :: Array a -> Int -> a
Nada nessas assinaturas de tipo reflete o requisito de que o índice seja não negativo e menor que o comprimento da coleção. Para software com requisitos de alta confiabilidade, isso é inaceitável.
Agda: ergonomia + correção
Os meios de prova de teoremas (por exemplo, Coq ) são ferramentas de software que permitem o uso de um computador para desenvolver provas formais de teoremas matemáticos. Para um matemático, usar essas ferramentas é como escrever evidências no papel. A diferença no rigor sem precedentes exigido por um computador para estabelecer a validade de tais evidências.
Para o programador, no entanto, os meios de provar os teoremas não são tão diferentes do compilador para a linguagem de programação esotérica com um sistema de tipos incrível (e possivelmente um ambiente de desenvolvimento integrado) e tudo medíocre (ou até ausente). Um meio de provar teoremas é, de fato, linguagens de programação, cujos autores passaram o tempo todo desenvolvendo um sistema de digitação e esqueceram que os programas ainda precisam ser executados.
O sonho acalentado de desenvolvedores de software verificados é um meio de provar teoremas, o que seria uma boa linguagem de programação com gerador de código e tempo de execução de alta qualidade. Nesta direção, incluindo os criadores de Idris experimentaram. Mas essa é uma linguagem com cálculos rigorosos (energéticos) e sua implementação no momento não é estável.
Entre todos os meios de provar os teoremas, os Agda Haskellists são os que mais gostam. De muitas maneiras, é semelhante ao Haskell, mas com um sistema de tipos mais poderoso. Nós da Serokell o usamos para provar as várias propriedades de nossos programas. Minha colega Dania Rogozin escreveu uma série de artigos sobre isso.
Aqui está um tipo de função de pesquisa semelhante ao operador Haskell (!!) :
lookup : ∀ (xs : List A) → Fin (length xs) → A
O primeiro parâmetro aqui é do tipo List A , que corresponde a [a] em Haskell. No entanto, xs o nome xs para fazer referência ao restante da assinatura de tipo. Em Haskell, podemos acessar argumentos da função apenas no corpo da função no nível do termo:
(!!) :: [a] -> Int -> a
Mas no Agda, podemos nos referir a esse valor xs no nível de tipo, o que fazemos no segundo parâmetro de lookup , Fin (length xs) . Uma função que se refere ao seu parâmetro no nível de tipo é chamada de função dependente e é um exemplo de tipos dependentes.
O segundo parâmetro na lookup é do tipo Fin n para n ~ length xs . Um valor do tipo Fin n corresponde a um número no intervalo [0, n) ; portanto, Fin (length xs) é um número não negativo menor que o comprimento da lista de entrada. É exatamente isso que precisamos para apresentar um índice válido de um item da lista. Grosso modo, a lookup ["x","y","z"] 2 passará na verificação de tipo, mas a lookup ["x","y","z"] 42 falhará.
Quando se trata de executar programas Agda, podemos compilá-los no Haskell usando o back-end do MAlonzo. Mas o desempenho do código gerado será insatisfatório. Isso não é culpa de MAlonzo: ele precisa inserir numerosos unsafeCoerce para que o GHC unsafeCoerce código já verificado pela Agda. Mas o mesmo unsafeCoerce reduz o desempenho (após a discussão deste artigo, constatou-se que problemas de desempenho podem ter sido causados por outros motivos - nota do autor) .
Isso nos coloca em uma posição difícil: precisamos usar o Agda para modelagem e verificação formal e, em seguida, reimplementar a mesma funcionalidade no Haskell. Com essa organização de fluxos de trabalho, nosso código Agda atua como uma especificação verificada por computador. Isso é melhor do que a especificação em linguagem natural, mas longe do ideal. O objetivo é que, se o código for compilado, ele funcionará de acordo com a especificação.
Haskell com extensões: correção + desempenho

Visando garantias estáticas de idiomas com tipos dependentes, o GHC percorreu um longo caminho. Foram adicionadas extensões para aumentar a expressividade do sistema de tipos. Comecei a usar o Haskell quando o GHC 7.4 era a versão mais recente do compilador. Mesmo assim, ele tinha as principais extensões para programação avançada em nível de tipo: RankNTypes , GADTs , TypeFamilies , DataKinds e PolyKinds .
No entanto, ainda não existem tipos dependentes completos em Haskell: nem funções dependentes (tipos)) nem pares dependentes (tipos Σ). Por outro lado, pelo menos temos uma codificação para eles!
As práticas atuais são as seguintes:
- codificar funções no nível de tipo como famílias de tipos particulares,
- use a funcionalização para habilitar funções não saturadas,
- colmatar a lacuna entre termos e tipos usando tipos únicos.
Isso leva a uma quantidade significativa de código redundante, mas a biblioteca de singletons automatiza sua geração através do Template Haskell.
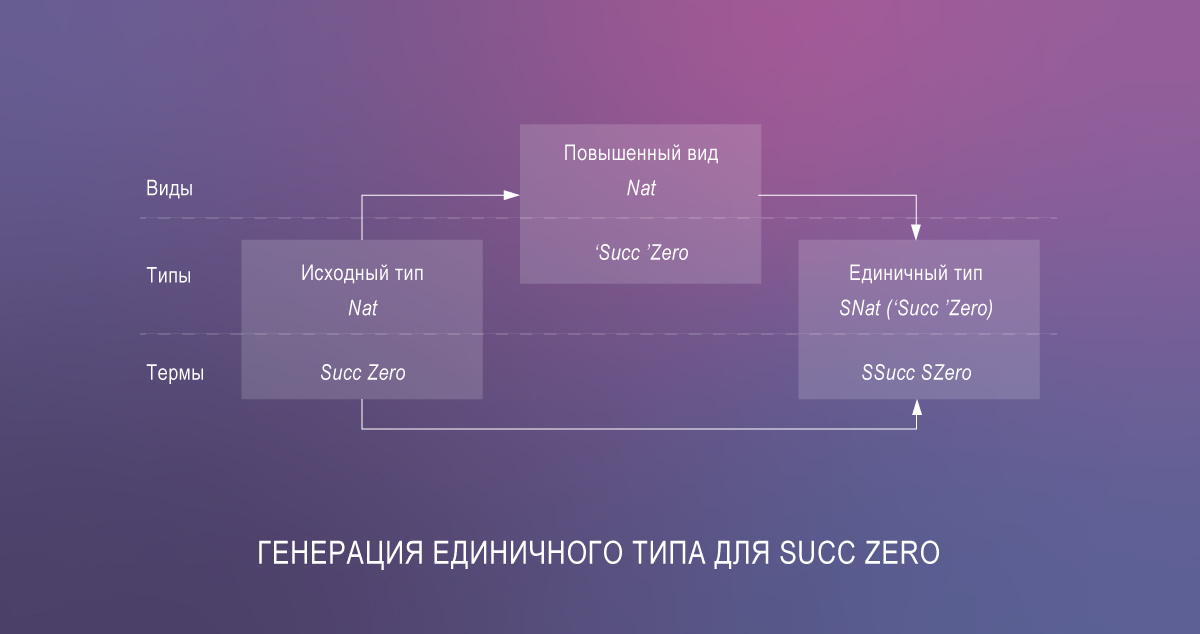
Portanto, o mais ousado e decisivo pode codificar tipos dependentes no Haskell agora. Como demonstração, aqui está uma implementação da função de lookup semelhante à variante no Agda:
{-# OPTIONS -Wall -Wno-unticked-promoted-constructors -Wno-missing-signatures #-} {-# LANGUAGE LambdaCase, DataKinds, PolyKinds, TypeFamilies, GADTs, ScopedTypeVariables, EmptyCase, UndecidableInstances, TypeSynonymInstances, FlexibleInstances, TypeApplications, TemplateHaskell #-} module ListLookup where import Data.Singletons.TH import Data.Singletons.Prelude singletons [d| data N = Z | SN len :: [a] -> N len [] = Z len (_:xs) = S (len xs) |] data Fin n where FZ :: Fin (S n) FS :: Fin n -> Fin (S n) lookupS :: SingKind a => SList (xs :: [a]) -> Fin (Len xs) -> Demote a lookupS SNil = \case{} lookupS (SCons x xs) = \case FZ -> fromSing x FS i' -> lookupS xs i'
E aqui está uma sessão do GHCi mostrando que as pesquisas de fato rejeitam índices muito grandes:
GHCi, version 8.6.2: http://www.haskell.org/ghc/ :? for help [1 of 1] Compiling ListLookup ( ListLookup.hs, interpreted ) Ok, one module loaded. *ListLookup> :set -XTypeApplications -XDataKinds *ListLookup> lookupS (sing @["x", "y", "z"]) FZ "x" *ListLookup> lookupS (sing @["x", "y", "z"]) (FS FZ) "y" *ListLookup> lookupS (sing @["x", "y", "z"]) (FS (FS FZ)) "z" *ListLookup> lookupS (sing @["x", "y", "z"]) (FS (FS (FS FZ))) <interactive>:5:34: error: • Couldn't match type ''S n0' with ''Z' Expected type: Fin (Len '["x", "y", "z"]) Actual type: Fin ('S ('S ('S ('S n0)))) • In the second argument of 'lookupS', namely '(FS (FS (FS FZ)))' In the expression: lookupS (sing @["x", "y", "z"]) (FS (FS (FS FZ))) In an equation for 'it': it = lookupS (sing @["x", "y", "z"]) (FS (FS (FS FZ)))
Este exemplo mostra que viabilidade não significa prático. Fico feliz que Haskell tenha recursos de linguagem para implementar lookupS , mas ao mesmo tempo estou preocupado com a complexidade desnecessária que surge. Fora dos projetos de pesquisa, eu não recomendaria esse estilo de código.
Nesse caso em particular, podemos obter o mesmo resultado com menos complexidade usando vetores indexados por comprimento. No entanto, a tradução direta de código da Agda revela melhor os problemas que você precisa ter em outras circunstâncias.
Aqui estão alguns deles:
- A relação de digitação
a :: t relação de destino do formulário t :: k diferentes. 5 :: Integer é verdadeiro em termos, mas não em tipos. "hi" :: Symbol é verdadeiro em tipos, mas não em termos. Isso requer que a Demote tipos Demote para mapear visualizações e tipos. - A biblioteca padrão usa
Int como uma representação dos índices da lista (e os singletons usam Nat em definições elevadas). Int e Nat são tipos não indutivos. Apesar de serem mais eficientes do que a codificação unária de números naturais, eles não funcionam muito bem com definições indutivas, como Fin ou lookupS . Por esse motivo, redefinimos o length como len . - Haskell não possui mecanismos internos para elevar funções ao nível de tipos.
singletons codificam como famílias de tipo privado e aplica a funcionalização para contornar a falta de uso parcial de famílias de tipo. Essa codificação é complicada. Além disso, tivemos que colocar a definição de len em uma citação de Template Haskell para que os singletons gerassem seu equivalente em nível de tipo, Len . - Não há funções dependentes internas. É preciso usar tipos de unidades para preencher a lacuna entre termos e tipos. Em vez da lista usual, passamos o
SList para a entrada lookupS . Portanto, devemos ter em mente várias definições de listas de uma só vez. Isso também gera sobrecarga durante a execução do programa. Surgem devido à conversão entre valores comuns e valores de tipos de unidade ( toSing , fromSing ) e devido à transferência do procedimento de conversão (restrição SingKind ).
Inconveniência é o menor problema. Pior, esses recursos de idioma não são confiáveis. Por exemplo, relatei o problema nº 12564 em 2016 e também o número 12088 do mesmo ano. Ambos os problemas impedem a implementação de programas mais avançados do que exemplos de livros didáticos (como listas de indexação). Esses bugs do GHC ainda não foram corrigidos, e a razão, ao que me parece, é que os desenvolvedores simplesmente não têm tempo suficiente. O número de pessoas que trabalham ativamente no GHC é surpreendentemente pequeno, então algumas coisas não acontecem.
Sumário
Mencionei anteriormente que queremos todas as três propriedades do código, então aqui está uma tabela que ilustra o estado atual das coisas:
Futuro brilhante
Das três opções disponíveis, cada uma tem suas desvantagens. No entanto, podemos corrigi-los:
- Pegue o Haskell padrão e adicione tipos dependentes diretamente, em vez de codificação inconveniente via
singletons . (Mais fácil dizer do que fazer.) - Leve o Agda e implemente um gerador de código eficiente e RTS para ele. (Mais fácil dizer do que fazer.)
- Leve Haskell com extensões, corrija bugs e continue adicionando novas extensões para simplificar a codificação dos tipos dependentes. (Mais fácil dizer do que fazer.)
A boa notícia é que todas as três opções convergem em um ponto (em certo sentido). Imagine a menor extensão do Haskell padrão que adiciona tipos dependentes e, portanto, permite garantir a correção do código pela maneira como ele é escrito. O código Agda pode ser compilado (transposto) para esse idioma sem um unsafeCoerce . E Haskell com extensões é, em certo sentido, um protótipo inacabado dessa linguagem. Algo precisa ser melhorado e algo precisa ser removido, mas, no final, alcançaremos o resultado desejado.
Livre de singletons
Um bom indicador de progresso é a simplificação da biblioteca de singletons . Como os tipos dependentes são implementados no Haskell, as soluções alternativas e o tratamento especial de casos especiais implementados em singletons não são mais necessários. Por fim, a necessidade deste pacote desaparecerá completamente. Por exemplo, em 2016, usando a extensão -XTypeInType removi o KProxy do SingKind e SomeSing . Essa alteração foi possível através da união de tipos e tipos. Compare definições antigas e novas:
class (kparam ~ 'KProxy) => SingKind (kparam :: KProxy k) where type DemoteRep kparam :: * fromSing :: SingKind (a :: k) -> DemoteRep kparam toSing :: DemoteRep kparam -> SomeSing kparam type Demote (a :: k) = DemoteRep ('KProxy :: KProxy k) data SomeSing (kproxy :: KProxy k) where SomeSing :: Sing (a :: k) -> SomeSing ('KProxy :: KProxy k)
Nas definições antigas, k ocorre exclusivamente nas posições de exibição, à direita das anotações no formato t :: k . Usamos kparam :: KProxy k para transferir k para tipos.
class SingKind k where type DemoteRep k :: * fromSing :: SingKind (a :: k) -> DemoteRep k toSing :: DemoteRep k -> SomeSing k type Demote (a :: k) = DemoteRep k data SomeSing k where SomeSing :: Sing (a :: k) -> SomeSing k
Nas novas definições, k se move livremente entre as posições de visualização e digitação, portanto não precisamos mais do KProxy . O motivo é que, começando com o GHC 8.0, tipos e tipos se enquadram na mesma categoria sintática.
Existem três mundos completamente separados no Haskell padrão: termos, tipos e visualizações. Se você olhar o código fonte do GHC 7.10, poderá ver um analisador separado para exibições e uma verificação separada. O GHC 8.0 não os possui mais: o analisador e a validação de tipos e visualizações são comuns.
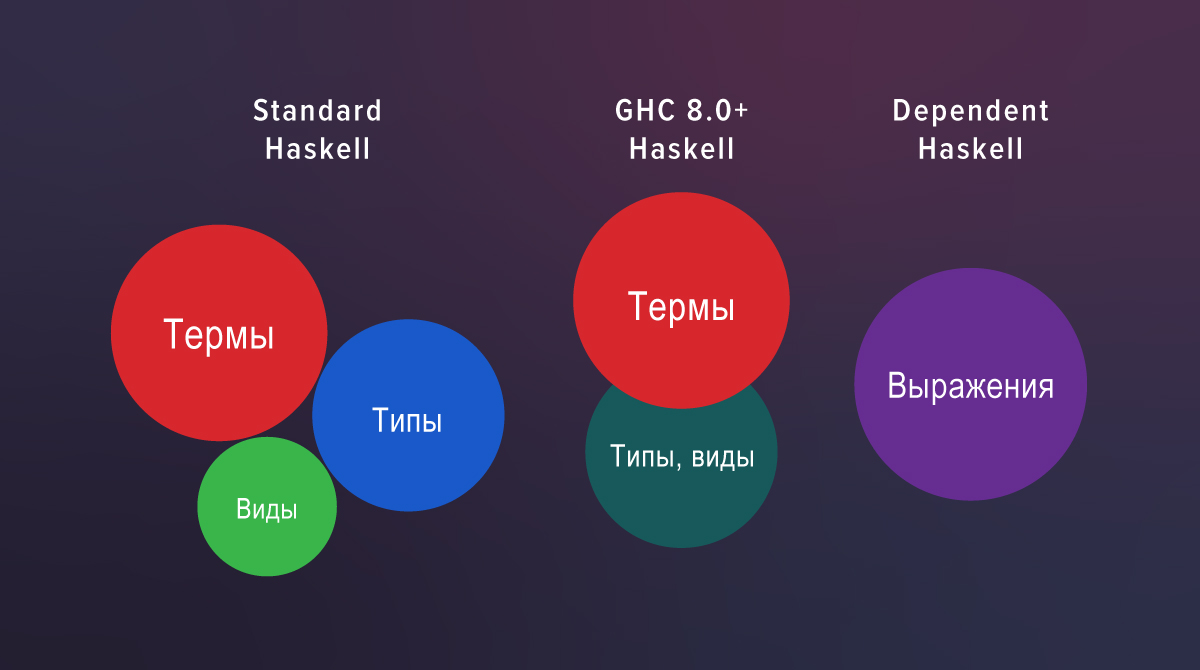
No Haskell com extensões, view é apenas a função do tipo:
f :: T z -> ...
No GHC 8.0-8.4, ainda havia algumas diferenças entre a resolução de nomes em tipos e tipos. Mas eu os minimizei para o GHC 8.6: criei a extensão StarIsType e introduzi a funcionalidade PolyKinds no PolyKinds . As diferenças restantes, eu fiz um aviso ao GHC 8.8 e completamente eliminado no GHC 8.10
Qual é o próximo passo? Vamos dar uma olhada no SingKind na versão mais recente dos singletons :
class SingKind k where type Demote k = (r :: Type) | r -> k fromSing :: Sing (a :: k) -> Demote k toSing :: Demote k -> SomeSing k
A Demote tipo Demote necessária para considerar as discrepâncias entre a relação de digitação a :: t relação de destino do formulário t :: k . Na maioria das vezes (para tipos de dados algébricos), o Demote é um mapeamento de identidade:
type Demote Bool = Booltype Demote [a] = [Demote a]type Demote (Either ab) = Either (Demote a) (Demote b)
Portanto, Demote (Either [Bool] Bool) = Either [Bool] Bool . Essa observação nos leva a fazer a seguinte simplificação:
class SingKind k where fromSing :: Sing (a :: k) -> k toSing :: k -> SomeSing k
Demote não Demote necessário! E, de fato, isso funcionaria com os tipos de dados Either [Bool] Bool e outros algébricos. Na prática, no entanto, estamos lidando com tipos de dados não algébricos: Integer, Natural , Char , Text e assim por diante. Se usadas como espécies, elas não são preenchidas: 1 :: Natural é verdade no nível dos termos, mas não no nível dos tipos. Por isso, estamos lidando com essas definições:
type Demote Nat = Natural type Demote Symbol = Text
A solução para esse problema é gerar tipos primitivos. Por exemplo, o Text definido assim:
Se ByteArray# corretamente ByteArray# e Int# ao nível dos tipos, podemos usar Text vez de Symbol . Ao fazer o mesmo com o Natural e possivelmente com outros tipos, você pode se livrar do Demote , certo?
Infelizmente, não é assim. Acima, fechei os olhos para o tipo de dados mais importante: funções. Eles também têm uma instância especial de Demote :
type Demote (k1 ~> k2) = Demote k1 -> Demote k2 type a ~> b = TyFun ab -> Type data TyFun :: Type -> Type -> Type
~> este é um tipo com o qual as funções em nível de tipo são codificadas em singletons com base nas famílias de tipos particulares e na funcionalidade .
A princípio, pode parecer uma boa idéia combinar ~> e -> , pois ambos significam o tipo (tipo) da função. O problema é que -> na posição de tipo e -> na posição de visualização significam coisas diferentes. No nível do termo, todas as funções de a a b são do tipo a -> b . No nível de tipo, apenas os construtores de a a b são do tipo a -> b , mas não são sinônimos de tipos nem famílias de tipos. Para deduzir tipos, o GHC assume que f ~ g e a ~ b seguem de fa ~ gb , o que é verdadeiro para construtores, mas não para funções - é por isso que há uma restrição.
Portanto, para elevar as funções ao nível dos tipos, mas para preservar a inferência de tipos, teremos que mover os construtores para um tipo separado. Nós chamamos de a :-> b , pois será realmente verdade que f ~ g e a ~ b seguem de fa ~ gb . Outras funções ainda serão do tipo a -> b . Por exemplo, Just :: a :-> Maybe a , mas ao mesmo tempo isJust :: Maybe a -> Bool .
Quando o Demote terminar, o último passo é se livrar do próprio Sing . Para fazer isso, precisamos de um novo quantificador, um híbrido entre forall e -> . Vamos dar uma olhada na função isJust:
isJust :: forall a. Maybe a -> Bool isJust = \x -> case x of Nothing -> False Just _ -> True
A função isJust parametrizada com o tipo a e, em seguida, com o valor x :: Maybe a . Esses dois parâmetros têm propriedades diferentes:
- Explicitação. Na
isJust (Just "hello") , passamos x = Just "hello" explicitamente, e a = String é implicitamente emitida pelo compilador. No Haskell moderno, também podemos forçar a passagem explícita de ambos os parâmetros: isJust @String (Just "hello") . - Relevância O valor passado para a entrada para
isJust no código também será transmitido durante a execução do programa: executamos um padrão correspondente a case e case para verificar se é Nothing ou Just . Portanto, o valor é considerado relevante. Mas seu tipo é apagado e não pode ser comparado com o padrão: a função manipula Maybe Int , Maybe String , Maybe Bool , etc. Portanto, é considerado irrelevante. Essa propriedade também é chamada de parametridade. - Vício. Em todos os
forall a. t forall a. t , o tipo t pode se referir a a e, portanto, depende do particular passado a . Por exemplo, isJust @String é do tipo Maybe String -> Bool e isJust @Int é do tipo Maybe Int -> Bool . Isso significa que forall é um quantificador dependente. Observe a diferença com o parâmetro value: não importa se chamamos isJust Nothing ou isJust (Just …) , o tipo de resultado é sempre Bool . Portanto, -> é um quantificador independente.
Para eliminar Sing , precisamos de um quantificador explícito e relevante, como a -> b , e ao mesmo tempo dependente, como forall (a :: k). t forall (a :: k). t . Denote-o como foreach (a :: k) -> t . Para SingI , também introduzimos um quantificador dependente implícito relevante, foreach (a :: k). t foreach (a :: k). t . Como resultado, singletons não serão necessários, pois acabamos de adicionar funções dependentes ao idioma.
Uma breve olhada em Haskell com tipos dependentes
Com o aumento das funções no nível dos tipos e no quantificador foreach , podemos reescrever as lookupS seguinte maneira:
data N = Z | SN len :: [a] -> N len [] = Z len (_:xs) = S (len xs) data Fin n where FZ :: Fin (S n) FS :: Fin n -> Fin (S n) lookupS :: foreach (xs :: [a]) -> Fin (len xs) -> a lookupS [] = \case{} lookupS (x:xs) = \case FZ -> x FS i' -> lookupS xs i'
Em suma, o código não o fez, mas os singletons muito bons em ocultar códigos redundantes. No entanto, o novo código é muito mais simples: não há mais SingKind , SList , SNil , SNil , SCons , fromSing . Não há uso do TemplateHaskell , pois agora podemos chamar a função len diretamente em vez de criar a família de tipos Len . O desempenho também será melhor, pois você não precisa mais converter fromSing .
Ainda precisamos redefinir o length como len para retornar um N definido indutivamente em vez de Int . Talvez esse problema não deva ser considerado na estrutura da adição de tipos dependentes ao Haskell, porque o Agda também usa um N definido indutivamente na função de lookup .
Em alguns aspectos, Haskell com tipos dependentes é ainda mais simples que o Haskell padrão. Ainda assim, em termos, tipos e tipos são combinados em uma linguagem única e uniforme. Posso facilmente imaginar escrever código nesse estilo em um projeto comercial para provar formalmente a correção dos principais componentes dos aplicativos. Muitas bibliotecas Haskell podem fornecer interfaces mais seguras sem a complexidade dos singletons .
Isso não será fácil de conseguir. Temos muitos problemas de engenharia que afetam todos os componentes do GHC: um analisador, resolução de nomes, verificação de tipo e até o idioma principal. Tudo precisará ser modificado ou completamente redesenhado.
Thesaurus