Este artigo é uma tradução do meu artigo no meio -
Introdução ao Data Lake , que acabou sendo bastante popular, provavelmente devido à sua simplicidade. Portanto, decidi escrever em russo e complementá-lo um pouco para que uma pessoa simples que não seja especialista em dados entenda o que é um data warehouse (DW) e o que é um Data Lake e como eles se dão bem .
Por que eu quis escrever sobre um data lake? Trabalho com dados e análises há mais de 10 anos e agora definitivamente trabalho com grandes dados no Amazon Alexa AI em Cambridge, que fica em Boston, embora eu moro em Victoria, na ilha de Vancouver, e frequentemente visite Boston, Seattle e Vancouver, e às vezes até em Moscou, falo em conferências. De vez em quando, escrevo, mas escrevo principalmente em inglês, e já escrevi
vários livros , também preciso compartilhar tendências de análise da América do Norte e, às vezes, escrevo em
telegramas .
Sempre trabalhei com data warehouses e, desde 2015, comecei a trabalhar em estreita colaboração com a Amazon Web Services e, em geral, mudei para a análise de nuvem (AWS, Azure, GCP). Eu assisti à evolução das soluções de análise desde 2007 e até trabalhei no fornecedor do data warehouse Teradat e a implementei no Sberbank. Em seguida, o Big Data com Hadoop apareceu. Todos começaram a dizer que a era dos armazenamentos havia passado e agora tudo estava no Hadoop. Depois, começaram a falar sobre o Data Lake novamente, agora que o data warehouse certamente havia terminado. Felizmente (talvez para alguém e, infelizmente, que ganhou muito dinheiro com a configuração do Hadoop), o data warehouse não foi embora.
Neste artigo, consideraremos o que é um data lake. Este artigo é destinado a pessoas que têm pouca ou nenhuma experiência com data warehousing.

Na foto, Lake Bled é um dos meus lagos favoritos, embora eu tenha estado lá apenas uma vez, mas me lembro por toda a vida. Mas falaremos sobre outro tipo de lago - data lake. Talvez muitos de vocês já tenham ouvido falar sobre esse termo mais de uma vez, mas outra definição não fará mal a ninguém.
Primeiro de tudo, aqui estão as definições mais populares do Data Lake:
“Armazenamento de arquivos de todos os tipos de dados brutos disponíveis para análise por qualquer pessoa da organização” - Martin Fowler.
“Se você acha que uma exibição de dados é uma garrafa de água purificada, embalada e empacotada para uso conveniente, o data lake é um enorme reservatório de água em sua forma natural. Usuários, posso tirar água para mim, mergulhar nas profundezas, explorar "- James Dixon.
Agora sabemos com certeza que o data lake é sobre análise, ele permite armazenar grandes quantidades de dados em sua forma original e temos o acesso necessário e conveniente aos dados.
Costumo gostar de simplificar as coisas, se consigo distinguir um termo complexo em palavras simples, entendi por mim mesmo como ele funciona e para que serve. De alguma forma, eu estava escolhendo meu iPhone na galeria de fotos, e me ocorreu que este é um verdadeiro lago de dados, e até fiz um slide para conferências:

Tudo é muito simples. Tiramos uma foto no telefone, a foto é salva no telefone e pode ser salva no iCloud (armazenamento de arquivos na nuvem). O telefone também coleta metadados da foto: o que é mostrado, geo-tag, tempo. Como resultado, podemos usar a conveniente interface do iPhone para encontrar nossa foto e, ao mesmo tempo, ver indicadores, por exemplo, quando procuro fotos com a palavra fogo, encontro 3 fotos com a imagem de um incêndio. Para mim, é como uma ferramenta de Business Intelligence que funciona de maneira muito rápida e clara.
E, é claro, não devemos esquecer a segurança (autorização e autenticação); caso contrário, nossos dados podem facilmente entrar em acesso aberto. Há muitas notícias sobre grandes corporações e empresas iniciantes, nas quais os dados são de domínio público devido à negligência dos desenvolvedores e à não observação de regras simples.
Mesmo uma imagem tão simples nos ajuda a imaginar o que é um data lake, suas diferenças em relação a um data warehouse tradicional e seus principais elementos:
- O carregamento de dados (ingestão) é um componente essencial de um data lake. Os dados podem entrar no data warehouse de duas maneiras: lote (download em intervalos) e streaming (fluxo de dados).
- O armazenamento de arquivos é o principal componente do Data Lake. Precisamos que o armazenamento seja facilmente escalável, extremamente confiável e de baixo custo. Por exemplo, na AWS, esse é o S3.
- Catálogo e pesquisa - para evitar o Data Swamp (é quando despejamos todos os dados em uma pilha e é impossível trabalhar com eles), precisamos criar uma camada de metadados para classificar os dados para que os usuários possam facilmente encontre os dados que eles precisam para análise. Além disso, você pode usar soluções de pesquisa adicionais, como o ElasticSearch. A pesquisa ajuda o usuário a procurar os dados desejados através de uma interface conveniente.
- Processamento (processo) - esta etapa é responsável pelo processamento e transformação de dados. Podemos transformar dados, mudar suas estruturas, limpar e muito mais.
- Segurança - é importante gastar tempo projetando uma solução de segurança. Por exemplo, criptografia de dados durante o armazenamento, processamento e carregamento. É importante usar métodos de autenticação e autorização. Em conclusão, é necessária uma ferramenta de auditoria.
Do ponto de vista prático, podemos caracterizar um data lake com três atributos:
- Colete e armazene o que quiser - o data lake contém todos os dados, dados brutos brutos por qualquer período de tempo e dados processados / limpos.
- Análise profunda - um data lake permite que os usuários explorem e analisem dados.
- Acesso flexível - um data lake fornece acesso flexível a vários dados e vários cenários.
Agora podemos falar sobre a diferença entre um data warehouse e um data lake. As pessoas costumam perguntar:
- Mas e o armazém de dados?
- Estamos substituindo o data warehouse por um data lake ou estamos expandindo?
- É possível ficar sem um data lake?
Em suma, não há uma resposta clara. Tudo depende da situação específica, das habilidades da equipe e do orçamento. Por exemplo, migrando um data warehouse para Oracle na AWS e criando um data lake pela subsidiária da Amazon - Woot -
Nossa história do data lake: como o Woot.com construiu um data lake sem servidor na AWS .
Por outro lado, o fornecedor Snowflake afirma que você não precisa mais pensar em um data lake, pois a plataforma de dados (até 2020 era um data warehouse) permite combinar um data lake e um data warehouse. Não trabalhei muito com o Snowflake e é um produto verdadeiramente único que pode fazer isso. O preço da pergunta é outra questão.
Concluindo, minha opinião pessoal é que ainda precisamos de um data warehouse como a principal fonte de dados para nossos relatórios e armazenamos tudo o que não se encaixa no data lake. Todo o papel da análise é fornecer acesso conveniente aos negócios para a tomada de decisões. De qualquer forma, os usuários corporativos trabalham com mais eficiência com um data warehouse do que com um data lake, por exemplo, na Amazon - há Redshift (armazém de dados analíticos) e Redshift Spectrum / Athena (interface SQL para data lake no S3, com base no Hive / Presto). O mesmo se aplica a outros armazéns de dados analíticos modernos.
Vejamos uma arquitetura típica de data warehouse:
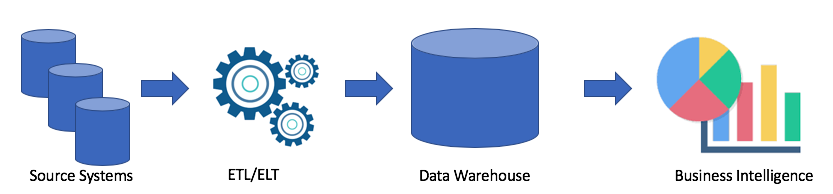
Esta é uma solução clássica. Temos sistemas de origem; usando ETL / ELT, copiamos os dados no data warehouse analítico e conectamos a solução à minha solução de Business Intelligence (meu Tableau favorito e o seu?).
Esta solução tem as seguintes desvantagens:
- As operações ETL / ELT levam tempo e recursos.
- Como regra, a memória para armazenar dados em um data warehouse analítico não é barata (por exemplo, Redshift, BigQuery, Teradata), pois precisamos comprar um cluster inteiro.
- Os usuários corporativos têm acesso a dados limpos e frequentemente agregados e não têm a capacidade de obter dados brutos.
Claro, tudo depende do seu caso. Se você não tiver problemas com seu data warehouse, absolutamente não precisará de um data lake. Porém, quando surgirem problemas com falta de espaço, capacidade ou preço da questão, você poderá considerar a opção de um data lake. Por isso, o data lake é muito popular. Aqui está um exemplo de uma arquitetura de data lake:

Usando a abordagem de data lake, carregamos dados brutos em nosso data lake (lote ou streaming) e processamos os dados conforme necessário. O data lake permite que os usuários de negócios criem suas próprias transformações de dados (ETL / ELT) ou analisem dados em soluções de Business Intelligence (se você tiver o driver correto).
O objetivo de qualquer solução analítica é atender usuários de negócios. Portanto, devemos sempre trabalhar nos requisitos do negócio. (Na Amazônia, esse é um dos princípios - trabalhar para trás).
Trabalhando com o data warehouse e o data lake, podemos comparar as duas soluções:
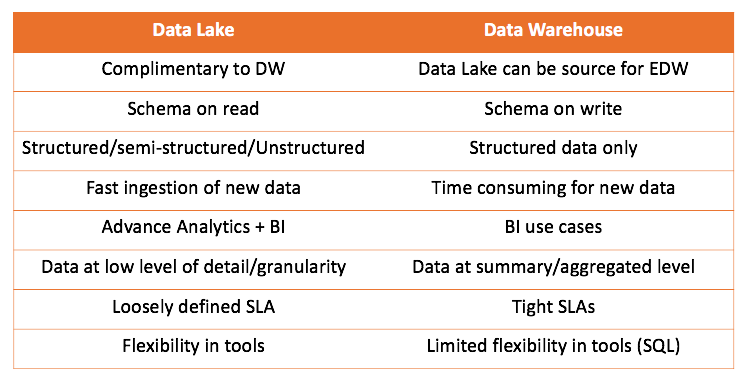
A principal conclusão que se pode tirar é que o data warehouse não compete com o data lake, mas o complementa mais. Mas cabe a você o que é certo para o seu caso. É sempre interessante tentar você mesmo e tirar as conclusões certas.
Também gostaria de falar sobre um dos casos em que comecei a usar a abordagem de data lake. Tudo é bastante comum, tentei usar a ferramenta ELT (tínhamos o Matillion ETL) e o Amazon Redshift, minha solução funcionou, mas não se encaixava nos requisitos.
Eu precisava pegar logs da web, transformá-los e agregá-los para fornecer dados para 2 casos:
- A equipe de marketing queria analisar a atividade de bots para SEO
- A TI queria observar as métricas do site
Logs muito simples, muito simples. Aqui está um exemplo:
https 2018-07-02T22:23:00.186641Z app/my-loadbalancer/50dc6c495c0c9188 192.168.131.39:2817 10.0.0.1:80 0.086 0.048 0.037 200 200 0 57 "GET https://www.example.com:443/ HTTP/1.1" "curl/7.46.0" ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2 arn:aws:elasticloadbalancing:us-east-2:123456789012:targetgroup/my-targets/73e2d6bc24d8a067 "Root=1-58337281-1d84f3d73c47ec4e58577259" "www.example.com" "arn:aws:acm:us-east-2:123456789012:certificate/12345678-1234-1234-1234-123456789012" 1 2018-07-02T22:22:48.364000Z "authenticate,forward" "-" "-"
Um arquivo pesava de 1 a 4 megabytes.
Mas havia uma dificuldade. Tínhamos 7 domínios em todo o mundo e, em um dia, 7.000 mil arquivos foram criados. Este não é um volume muito grande, apenas 50 gigabytes. Mas o tamanho do nosso cluster Redshift também era pequeno (4 nós). O download de um único arquivo da maneira tradicional levou cerca de um minuto. Ou seja, a tarefa não foi resolvida na testa. E foi esse o caso quando decidi usar a abordagem de data lake. A solução tinha algo parecido com isto:
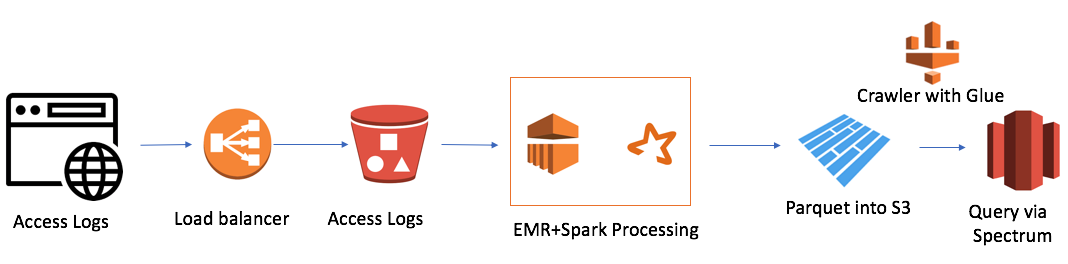
É bem simples (quero observar que a vantagem de trabalhar na nuvem é a simplicidade). Eu usei:
- AWS Elastic Map Reduce (Hadoop) como poder de computação
- AWS S3 como um armazenamento de arquivos com a capacidade de criptografar dados e restringir o acesso
- Spark como InMemory Computing Power e PySpark para lógica e transformação de dados
- Parquet como resultado do Spark
- AWS Glue Crawler como um coletor de metadados sobre novos dados e partições
- Redshift Spectrum como uma interface SQL para o data lake para usuários existentes do Redshift
O menor cluster EMR + Spark processou um monte de arquivos em 30 minutos. Existem outros casos para a AWS, especialmente muitos relacionados ao Alexa, onde há muitos dados.
Mais recentemente, descobri que uma das desvantagens do data lake é o GDPR. O problema é que quando o cliente pede para ele excluir e os dados estão em um dos arquivos, não podemos usar a linguagem de manipulação de dados e a operação DELETE como no banco de dados.
Felizmente, o artigo esclareceu a diferença entre um data warehouse e um data lake. Se foi interessante, ainda posso traduzir meus artigos ou o artigo de profissionais que li. E também fale sobre as soluções com as quais trabalho e sua arquitetura.