
Pelo terceiro ano, realizamos o fórum RAIF (Russian Russian Intelligence Intelligence Forum), onde palestrantes do mundo dos negócios e da ciência falam sobre seu trabalho. Decidimos compartilhar os relatórios mais interessantes. Neste post, Andrey Filchenkov, chefe do ITMO Machine Learning Lab, conta toda a verdade sobre o AutoML.
No âmbito do fórum RAIF 2019, realizado em Skolkovo, organizado pela Jet Infosystems, fiz uma apresentação na qual falei sobre o AutoML e as perspectivas de seu uso. Como sou cientista, não preciso falar nesses eventos com muita frequência: geralmente participo de conferências científicas.
Uma das principais áreas com as quais lidamos é o AutoML. Além disso, sou o CTO de duas pequenas startups. Uma delas - as tecnologias Statanly - cria serviços AutoML e se dedica à análise de dados. Na verdade, sou a pessoa que inventa algoritmos, os implementa e os utiliza. Acho que sou a única pessoa que pode falar sobre o AutoML de todas as três posições possíveis.
O que é o AutoML?
No último ano, essa direção tem sido de grande interesse e agora pode ser comparada com o foco de atenção no aprendizado profundo popular em seu tempo. O advento do aprendizado automático de máquinas pode ser datado de 1976. Havia uma pequena comunidade de ML e, em 2017, começou a ganhar popularidade depois de um ano além dos limites do próprio aprendizado de máquina. Agora eles falam sobre ele nos negócios, na indústria e em vários outros campos. É verdade que, na Rússia, infelizmente, nem todas as pessoas da comunidade ML imaginam o que é o aprendizado automático de máquinas. Por que isso aconteceu?
A resposta é simples - a demanda por cientistas de dados cresce muito mais rapidamente do que conseguem formar-se em universidades e concluir cursos. Ao mesmo tempo, eles passam a maior parte do tempo (até 80%) escolhendo um modelo, configurando-o e aguardando até que tudo seja calculado. Isso ocorre porque não existe um algoritmo perfeito - infelizmente, qualquer um deles tem um escopo limitado e os especialistas em análise de dados precisam selecionar o algoritmo ideal para cada tarefa específica e configurá-lo. Aqui, muito já depende da qualificação do analista: quanto mais ele conhece na área de assunto e entende os algoritmos, mais otimizada a solução pode ser por um certo tempo. É aqui que o AutoML ajuda. Na verdade, o AutoML permite automatizar e acelerar a seleção de soluções e tarefas de aprendizado de máquina.
Vamos decidir imediatamente: existem duas direções relacionadas, mas diferentes uma da outra.
Primeiro: os dados são apresentados na tabela, existem rótulos e, quando precisamos classificá-los, selecionamos um objeto de uma lista grande e configuramos seus hiper parâmetros, e ao mesmo tempo podemos processar os dados.
O segundo cenário é mais complexo. Por exemplo, imagens, sequências e áreas em que o aprendizado profundo agora é o padrão - aqui a tarefa se torna um pouco mais interessante, porque você pode criar novas arquiteturas: elas não são tão fáceis de resolver. Portanto, “Procurar arquiteturas neurais” está empenhado no fato de selecionar a rede ideal e configurar hiperparâmetros que permitem resolver um ou outro problema. No entanto, o AutoML não leva em consideração a semântica dos dados. Existem também métodos que permitem “retirar” descrições de dados e usá-las para previsão, mas isso só ajuda a aumentar a aplicabilidade universal do AutoML. Realmente não importa de onde os dados vieram: se você é um gasman, um vendedor de sorvete ou qualquer outra pessoa - os métodos são universais. Ao mesmo tempo, o AutoML permite criar as soluções mais eficazes, por um lado, escolhendo soluções complexas e não as mais óbvias, mesmo para um especialista em análise de dados estruturais e, por outro lado, pesquisar e otimizar essas soluções mais rapidamente. E mais uma coisa não óbvia - o AutoML permite acelerar a escrita de código. Aqui, por exemplo:

À direita, o código está escrito em Keras para reconhecimento MNIST, e à esquerda está o código para Auto-Keras na biblioteca de automação escrita em Keras. A diferença é visível enquanto o tempo de gravação é economizado.
Abundância de soluções existentes (2019)
No momento, há um grande número de bibliotecas e plataformas diferentes para análise automática de dados, citei apenas algumas delas (na verdade, existem muito mais).
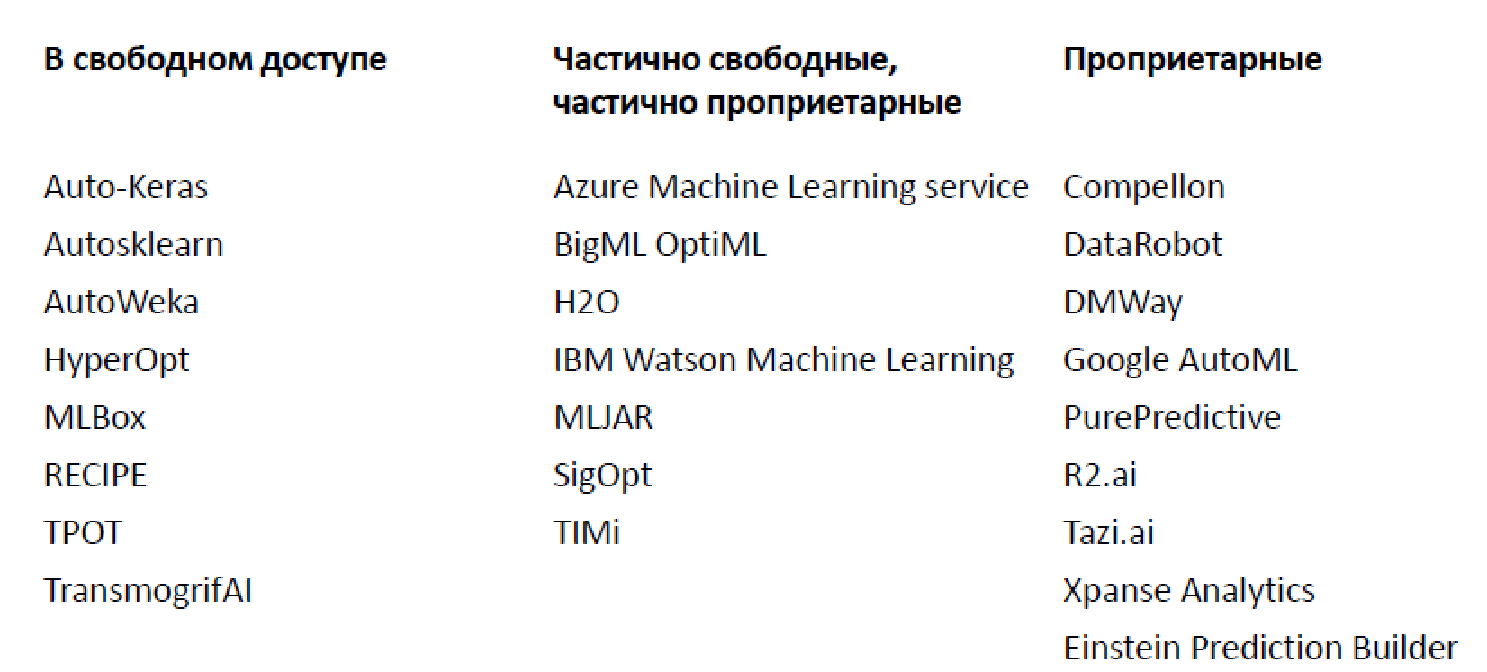
Existem dois abertos, que implementam funcionalidade limitada, e opções proprietárias. O mais famoso, provavelmente, é o Google AutoML, que não fornece um modelo, mas o treina em seus dados, permitindo que você o use por US $ 20 por hora. Além disso, há um grande número de cenários decentes quando a funcionalidade básica é fornecida gratuitamente, mas você precisa pagar por componentes mais avançados.
Previsões brilhantes
A própria comunidade elogia muito as perspectivas do AutoML. Por exemplo, Jeff Dean, cientista de inteligência artificial e pesquisador sênior do Google, disse em março de 2018 que a experiência existente em aprendizado de máquina poderia ser substituída por um aumento de cem vezes no poder da computação (quase tudo o que um cientista de dados faz -Você pode ser automatizado). Uma previsão um pouco mais contida, mas ainda assustadora, do Gartner diz que, até 2020, 40% dos cientistas de dados poderão ser substituídos pelo AutoML.
Pouco de alcatrão
É assim que a metodologia CRISP DM padrão se parece:
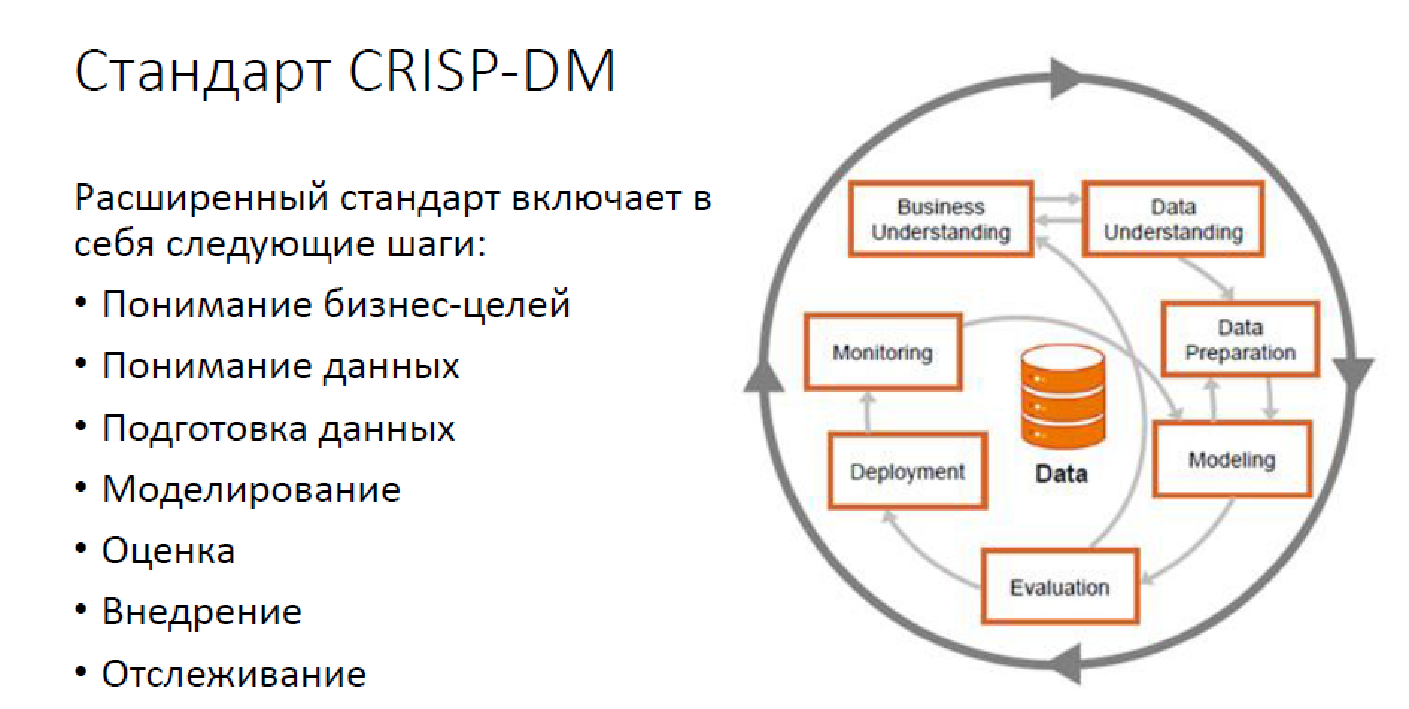
Esta é uma opção avançada, com monitoramento, mas mesmo assim. Hoje, resolver problemas de análise de dados não se resume apenas à construção de modelos. Temos um grande número de tarefas que precisam ser resolvidas e é necessário resolver com precisão pelas pessoas.
No momento, na maioria dos casos, o AutoML possui apenas 2,5 pilares: escolhendo um modelo, configurando-o e, às vezes, quando ele aparece, escolhendo recursos de síntese e apenas dados.
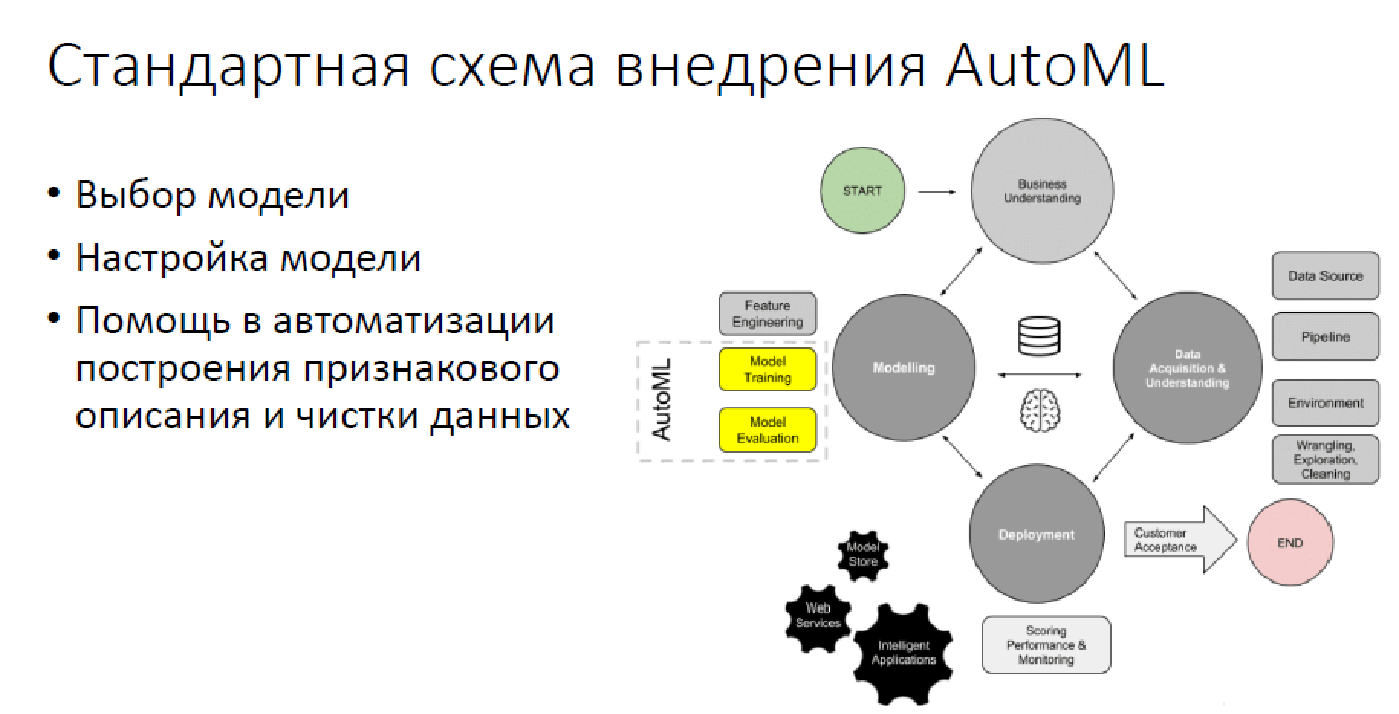
Além do AutoML
Infelizmente, um número bastante grande de operações é deixado ao mar, o que o AutoML não faz e não pode fazer em um futuro razoável. Naturalmente, isso implica a transformação de tarefas do mundo real no mundo da análise de dados: "Como projetar seu problema para que ele possa ser resolvido por meio da análise de dados?" São todos os tipos de rastreamento de modelo, avaliação de qualidade, busca de vários momentos desagradáveis - tudo para que a solução não pareça, por exemplo, muito intolerante com ninguém, porque isso já aconteceu. Naturalmente, nenhum AutoML pode suportar soluções e se comunicar com os clientes. Além disso, a interpretabilidade no momento atual está fora de questão.
Portanto, essa é uma ferramenta muito conveniente, mas, infelizmente, para nós, não resolve longe de todos os problemas.

O que estamos fazendo?
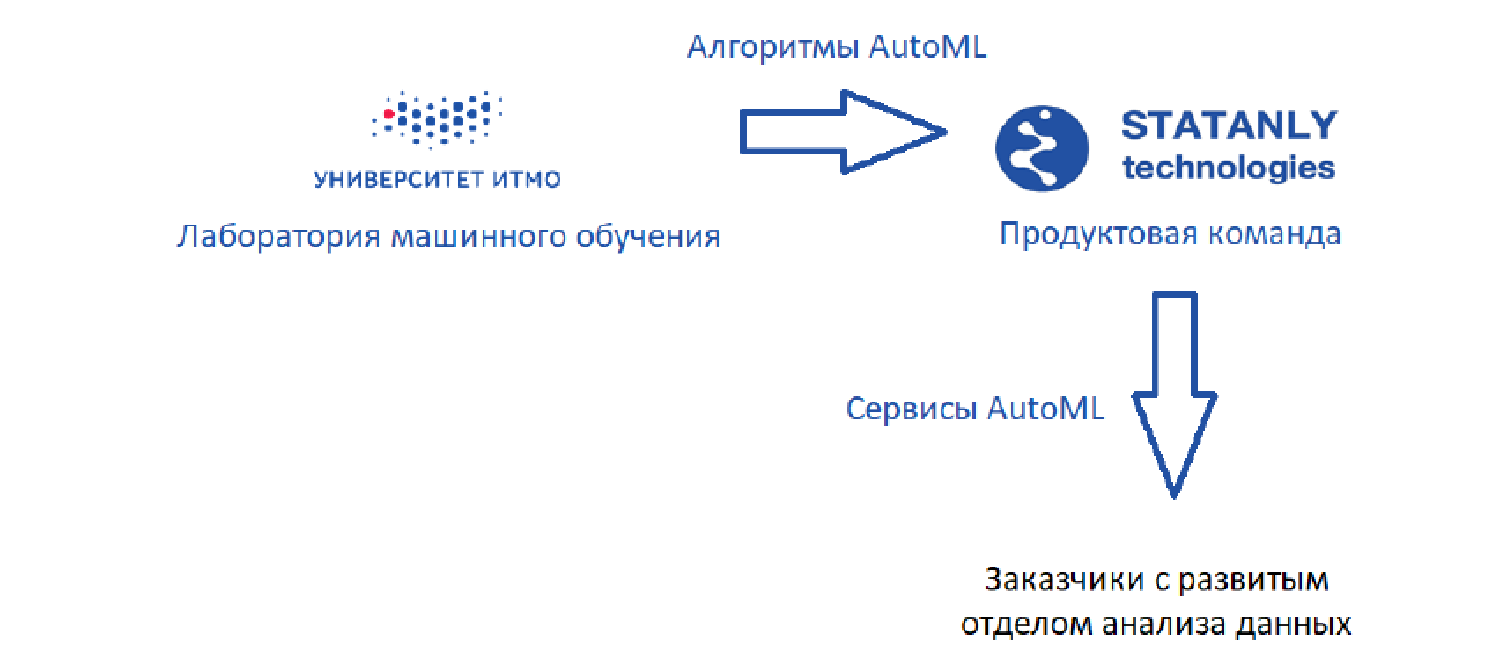
É assim que o circuito ideal se parece (a meu ver):
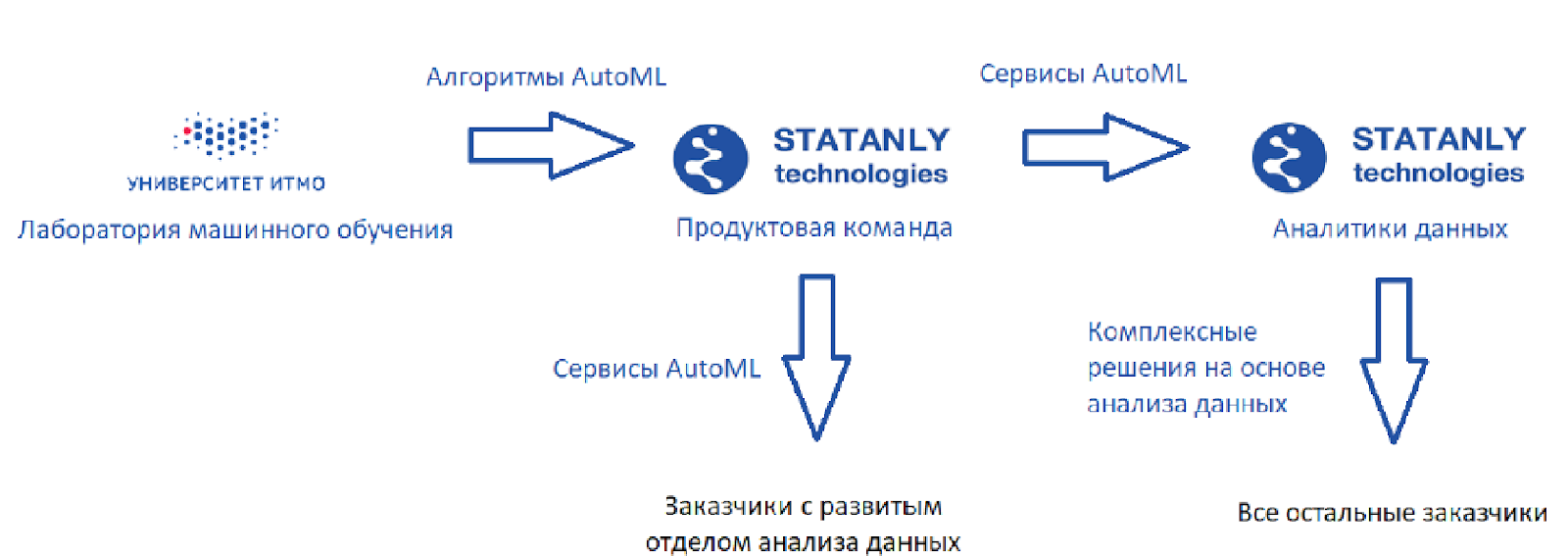
Existe um laboratório de aprendizado de máquina que desenvolve algoritmos, além da
Statanly Technologies - uma equipe de produtos que implementa serviços AutoML com base em nossos algoritmos. Eles trabalham para empresas que possuem um grande departamento de ciência de dados. Esses mesmos produtos são usados por uma equipe de analistas de dados da
própria Statanly Technologies e resolvem especificamente os problemas de empresas que ainda não expandiram ou criaram seu próprio departamento de análise de dados. O modelo parece ótimo, mas a realidade, é claro, é um pouco mais prosaica.
Começamos em 2017 com o fato de que não havia análise de dados aqui:
Queríamos lançar um produto que os analistas de dados usariam, mas em 2017, infelizmente, não conseguimos encontrar contato com os investidores - eles não entendiam o que era o AutoML, por que era necessário e quem o usaria.
No momento, não estamos vendendo nada, como uma empresa que desenvolve soluções AutoML, apenas facilitamos nossas vidas, como uma equipe envolvida na análise de dados:

Um pouco sobre como fazemos isso. Naturalmente, configuramos hiper parâmetros (sem pesquisa em grade), mas, além de configurá-los, quase sempre tentamos criar algumas soluções básicas baseadas em AutoML e, às vezes, nos ajudamos nas etapas de pré-processamento de dados.
Tenho alguns exemplos inspiradores e variados - praticamente tudo o que o AutoML e eu fizemos, do simples ao complexo.
Um exemplo simples é a tarefa da Gazpromneft: existe um poço, você precisa prever o tempo potencial de falha. Temos à nossa disposição dados e recursos tabulares clássicos. Como resultado, criamos um modelo preditivo usando o AutoML, enquanto nenhum analista ficou ferido, mas nem sequer participou do processo. De fato, essa acabou sendo a melhor solução:

Segunda história: Sinara Technologies. Aqui a tarefa era um pouco mais complicada, porque na verdade havia exatamente duas colunas: tempo / parâmetro + como ela mudou. Era necessário prever falha do motor. Aqui usamos o AutoML para nos ajudar um pouco no processamento de dados - construímos uma linha de base, que nós mesmos mais tarde superamos:

O terceiro exemplo: uma tarefa que, à primeira vista, não tem nada a ver com o AutoML. Existe um site para o canal TVC - um banco de dados de artigos nos quais pesquisar, e a pesquisa é semanticamente rica. Gostaríamos de encontrar não apenas expressões exatas das palavras, mas também um significado adequado. Além disso, uma grande lista de requisitos diferentes que também precisam ser considerados.
Como abordamos esse problema?
Decidimos indexar todos os documentos com base em grupos flexíveis de palavras semelhantes, porque a indexação é mais conveniente. Além disso, existem mais de 100 mil documentos no banco de dados e, se isso não for feito, a pesquisa será infinitamente longa. Em seguida, construímos uma representação vetorial (espero que todos tenham ouvido falar) e agrupamos as representações vetoriais para permitir a indexação.
O segundo problema: como agrupamos dados? Aplicamos o AutoML para selecionar medidas para avaliar a qualidade do clustering, bem como para selecionar algoritmos e hiper parâmetros para clustering:

Além disso, na maioria das vezes não usamos o AutoML. Aqui estão dois exemplos muito reveladores.
Em nossa segunda inicialização, o Special Video Analytics, o produto é um sistema para reconhecer os sinais dos carros para garantir seu acesso centralizado a um território fechado. O principal problema aqui é a pequena quantidade de dados. Nesse caso, é bastante difícil ajustar os parâmetros do modelo. E somos muito limitados, porque muitas vezes o AutoML é usado sem pensar e tenta ajustar os modelos com os mesmos dados em que são testados. Isso não pode ser feito: de acordo com os clássicos do aprendizado de máquina, é necessário destacar um conjunto de validação: quanto maior a pesquisa, mais máquinas deverão existir. Portanto, quando temos poucos dados, estamos mais preocupados em encontrar e marcar esses dados do que em construir um modelo mais complexo.
Outro exemplo é o nosso desenvolvimento conjunto com a Huawei. Fizemos um projeto para eles reconhecerem o texto nas imagens. Parece que você pode usar o AutoML aqui, já que já existem três métricas que podem ser otimizadas: qualidade do reconhecimento, tempo de reconhecimento e parâmetro do modelo (já que tudo isso deveria ser implementado em dispositivos móveis). Mas agora ninguém tem experiência suficiente para implementar de maneira ideal os três aspectos.
Como resultado, não havia poder computacional suficiente: tínhamos tempo limitado e não tínhamos um número suficiente de servidores. Se começássemos em casa (e devíamos estar no LICE), simplesmente não teríamos tempo. Como leva cinco horas para processar, nos custam apenas nossas competências.
Conclusão
Em geral, o AutoML é uma coisa muito útil, mas bastante restrita na aplicação. Naturalmente, ele não poderá encontrar soluções para o TK. Atualmente, o AutoML é útil apenas para analistas de dados. Talvez um dia ele os substitua, mas obviamente não nos próximos cinco anos.
Postado por Andrey Filchenkov, chefe do laboratório de aprendizado de máquina, ITMO