Se você está interessado em aprendizado de máquina, provavelmente já ouviu falar sobre BERT e transformadores.
O BERT é um modelo de linguagem do Google, mostrando resultados de ponta por uma ampla margem em várias tarefas. O BERT, e geralmente os transformadores, tornaram-se uma etapa completamente nova no desenvolvimento de algoritmos de processamento de linguagem natural (PNL). O artigo sobre eles e as "classificações" para vários benchmarks podem ser encontrados no site da Papers With Code .
Há um problema com o BERT: é problemático usar em sistemas industriais. O BERT-base contém 110M de parâmetros, BERT-grande - 340M. Devido a um número tão grande de parâmetros, é difícil fazer o download desse modelo em dispositivos com recursos limitados, como telefones celulares. Além disso, o longo tempo de inferência torna esse modelo inadequado quando a velocidade de resposta é crítica. Portanto, encontrar maneiras de acelerar o BERT é um tópico muito quente.
Em Avito, geralmente precisamos resolver problemas de classificação de texto. Essa é uma tarefa típica de aprendizado de máquina aplicada que foi bem estudada. Mas sempre há a tentação de tentar algo novo. Este artigo nasceu de uma tentativa de aplicar o BERT nas tarefas diárias de aprendizado de máquina. Nele, mostrarei como você pode melhorar significativamente a qualidade de um modelo existente usando o BERT sem adicionar novos dados ou complicar o modelo.

Destilação de conhecimento como método de aceleração de redes neurais
Existem várias maneiras de acelerar / clarear redes neurais. A revisão mais detalhada que conheci foi publicada no blog Intento no Medium .
Os métodos podem ser divididos em três grupos:
- Mudança na arquitetura de rede.
- Compressão de modelo (quantização, poda).
- Destilação de conhecimento.
Se os dois primeiros métodos são relativamente bem conhecidos e compreensíveis, o terceiro é menos comum. Pela primeira vez, a idéia de destilação foi proposta por Rich Caruana no artigo “Model Compression” . Sua essência é simples: você pode treinar um modelo leve que imite o comportamento de um modelo de professor ou mesmo de um conjunto de modelos. No nosso caso, o professor será o BERT e o aluno será um modelo leve.
Desafio
Vamos analisar a destilação usando a classificação binária como exemplo. Pegue o conjunto de dados aberto SST-2 do conjunto padrão de tarefas que testam modelos para PNL.
Este conjunto de dados é uma coleção de resenhas de filmes com IMDb divididos por cor emocional - positiva ou negativa. A métrica neste conjunto de dados é precisão.
Treinar modelos baseados no BERT ou "professores"
Primeiro de tudo, você precisa treinar o modelo “grande” baseado em BERT, que se tornará professor. A maneira mais fácil de fazer isso é pegar os embeddings do BERT e treinar o classificador sobre eles, adicionando uma camada à rede.
Graças à biblioteca de tranformers, é muito fácil fazer isso, porque existe uma classe pronta para o modelo BertForSequenceClassification. Na minha opinião, o tutorial mais detalhado e compreensível para o ensino desse modelo foi publicado pela Towards Data Science .
Vamos imaginar que recebemos um modelo BertForSequenceClassification treinado. No nosso caso, num_labels = 2, pois temos uma classificação binária. Usaremos esse modelo como um "professor".
Aprendendo "aluno"
Você pode ter qualquer arquitetura como estudante: uma rede neural, um modelo linear, uma árvore de decisão. Vamos tentar ensinar o BiLSTM para uma melhor visualização. Para começar, ensinaremos BiLSTM sem BERT.
Para enviar texto para a entrada de uma rede neural, você precisa apresentá-lo como um vetor. Uma das maneiras mais fáceis é mapear cada palavra para seu índice no dicionário. O dicionário consistirá nas principais palavras mais populares do conjunto de dados, além de duas palavras de serviço: "pad" - "palavra fictícia" para que todas as seqüências tenham o mesmo tamanho e "unk" - para palavras fora do dicionário. Vamos construir o dicionário usando o conjunto padrão de ferramentas do torchtext. Para simplificar, não usei palavras incorporadas pré-treinadas.
import torch from torchtext import data def get_vocab(X): X_split = [t.split() for t in X] text_field = data.Field() text_field.build_vocab(X_split, max_size=10000) return text_field def pad(seq, max_len): if len(seq) < max_len: seq = seq + ['<pad>'] * (max_len - len(seq)) return seq[0:max_len] def to_indexes(vocab, words): return [vocab.stoi[w] for w in words] def to_dataset(x, y, y_real): torch_x = torch.tensor(x, dtype=torch.long) torch_y = torch.tensor(y, dtype=torch.float) torch_real_y = torch.tensor(y_real, dtype=torch.long) return TensorDataset(torch_x, torch_y, torch_real_y)
Modelo BiLSTM
O código para o modelo ficará assim:
import torch from torch import nn from torch.autograd import Variable class SimpleLSTM(nn.Module): def __init__(self, input_dim, embedding_dim, hidden_dim, output_dim, n_layers, bidirectional, dropout, batch_size, device=None): super(SimpleLSTM, self).__init__() self.batch_size = batch_size self.hidden_dim = hidden_dim self.n_layers = n_layers self.embedding = nn.Embedding(input_dim, embedding_dim) self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=n_layers, bidirectional=bidirectional, dropout=dropout) self.fc = nn.Linear(hidden_dim * 2, output_dim) self.dropout = nn.Dropout(dropout) self.device = self.init_device(device) self.hidden = self.init_hidden() @staticmethod def init_device(device): if device is None: return torch.device('cuda') return device def init_hidden(self): return (Variable(torch.zeros(2 * self.n_layers, self.batch_size, self.hidden_dim).to(self.device)), Variable(torch.zeros(2 * self.n_layers, self.batch_size, self.hidden_dim).to(self.device))) def forward(self, text, text_lengths=None): self.hidden = self.init_hidden() x = self.embedding(text) x, self.hidden = self.rnn(x, self.hidden) hidden, cell = self.hidden hidden = self.dropout(torch.cat((hidden[-2, :, :], hidden[-1, :, :]), dim=1)) x = self.fc(hidden) return x
Treinamento
Para este modelo, a dimensão do vetor de saída será (batch_size, output_dim). No treinamento, usaremos o logloss usual. PyTorch possui uma classe BCEWithLogitsLoss que combina entrmo sigmóide e entropia cruzada. O que você precisa
def loss(self, output, bert_prob, real_label): criterion = torch.nn.BCEWithLogitsLoss() return criterion(output, real_label.float())
Código para uma era de aprendizado:
def get_optimizer(model): optimizer = torch.optim.Adam(model.parameters()) scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 2, gamma=0.9) return optimizer, scheduler def epoch_train_func(model, dataset, loss_func, batch_size): train_loss = 0 train_sampler = RandomSampler(dataset) data_loader = DataLoader(dataset, sampler=train_sampler, batch_size=batch_size, drop_last=True) model.train() optimizer, scheduler = get_optimizer(model) for i, (text, bert_prob, real_label) in enumerate(tqdm(data_loader, desc='Train')): text, bert_prob, real_label = to_device(text, bert_prob, real_label) model.zero_grad() output = model(text.t(), None).squeeze(1) loss = loss_func(output, bert_prob, real_label) loss.backward() optimizer.step() train_loss += loss.item() scheduler.step() return train_loss / len(data_loader)
Código para verificação após a época:
def epoch_evaluate_func(model, eval_dataset, loss_func, batch_size): eval_sampler = SequentialSampler(eval_dataset) data_loader = DataLoader(eval_dataset, sampler=eval_sampler, batch_size=batch_size, drop_last=True) eval_loss = 0.0 model.eval() for i, (text, bert_prob, real_label) in enumerate(tqdm(data_loader, desc='Val')): text, bert_prob, real_label = to_device(text, bert_prob, real_label) output = model(text.t(), None).squeeze(1) loss = loss_func(output, bert_prob, real_label) eval_loss += loss.item() return eval_loss / len(data_loader)
Se tudo isso estiver organizado, obteremos o seguinte código para treinar o modelo:
import os import torch from torch.utils.data import (TensorDataset, random_split, RandomSampler, DataLoader, SequentialSampler) from torchtext import data from tqdm import tqdm def device(): return torch.device("cuda" if torch.cuda.is_available() else "cpu") def to_device(text, bert_prob, real_label): text = text.to(device()) bert_prob = bert_prob.to(device()) real_label = real_label.to(device()) return text, bert_prob, real_label class LSTMBaseline(object): vocab_name = 'text_vocab.pt' weights_name = 'simple_lstm.pt' def __init__(self, settings): self.settings = settings self.criterion = torch.nn.BCEWithLogitsLoss().to(device()) def loss(self, output, bert_prob, real_label): return self.criterion(output, real_label.float()) def model(self, text_field): model = SimpleLSTM( input_dim=len(text_field.vocab), embedding_dim=64, hidden_dim=128, output_dim=1, n_layers=1, bidirectional=True, dropout=0.5, batch_size=self.settings['train_batch_size']) return model def train(self, X, y, y_real, output_dir): max_len = self.settings['max_seq_length'] text_field = get_vocab(X) X_split = [t.split() for t in X] X_pad = [pad(s, max_len) for s in tqdm(X_split, desc='pad')] X_index = [to_indexes(text_field.vocab, s) for s in tqdm(X_pad, desc='to index')] dataset = to_dataset(X_index, y, y_real) val_len = int(len(dataset) * 0.1) train_dataset, val_dataset = random_split(dataset, (len(dataset) - val_len, val_len)) model = self.model(text_field) model.to(device()) self.full_train(model, train_dataset, val_dataset, output_dir) torch.save(text_field, os.path.join(output_dir, self.vocab_name)) def full_train(self, model, train_dataset, val_dataset, output_dir): train_settings = self.settings num_train_epochs = train_settings['num_train_epochs'] best_eval_loss = 100000 for epoch in range(num_train_epochs): train_loss = epoch_train_func(model, train_dataset, self.loss, self.settings['train_batch_size']) eval_loss = epoch_evaluate_func(model, val_dataset, self.loss, self.settings['eval_batch_size']) if eval_loss < best_eval_loss: best_eval_loss = eval_loss torch.save(model.state_dict(), os.path.join(output_dir, self.weights_name))
Destilação
A idéia desse método de destilação é retirada de um artigo de pesquisadores da Universidade de Waterloo . Como eu disse acima, o "aluno" deve aprender a imitar o comportamento do "professor". Qual é exatamente o comportamento? No nosso caso, essas são as previsões do modelo do professor no conjunto de treinamento. E a idéia principal é usar a saída de rede antes de aplicar a função de ativação. Supõe-se que, dessa maneira, o modelo possa aprender melhor a representação interna do que no caso das probabilidades finais.
O artigo original propõe adicionar um termo à função de perda, que será responsável pelo erro "imitação" - MSE entre os logs do modelo.

Para esses fins, fazemos duas pequenas alterações: altere o número de saídas de rede de 1 para 2 e corrija a função de perda.
def loss(self, output, bert_prob, real_label): a = 0.5 criterion_mse = torch.nn.MSELoss() criterion_ce = torch.nn.CrossEntropyLoss() return a*criterion_ce(output, real_label) + (1-a)*criterion_mse(output, bert_prob)
Você pode reutilizar todo o código que escrevemos redefinindo apenas o modelo e a perda:
class LSTMDistilled(LSTMBaseline): vocab_name = 'distil_text_vocab.pt' weights_name = 'distil_lstm.pt' def __init__(self, settings): super(LSTMDistilled, self).__init__(settings) self.criterion_mse = torch.nn.MSELoss() self.criterion_ce = torch.nn.CrossEntropyLoss() self.a = 0.5 def loss(self, output, bert_prob, real_label): return self.a * self.criterion_ce(output, real_label) + (1 - self.a) * self.criterion_mse(output, bert_prob) def model(self, text_field): model = SimpleLSTM( input_dim=len(text_field.vocab), embedding_dim=64, hidden_dim=128, output_dim=2, n_layers=1, bidirectional=True, dropout=0.5, batch_size=self.settings['train_batch_size']) return model
Isso é tudo, agora nosso modelo está aprendendo a "imitar".
Comparação de modelos
No artigo original, os melhores resultados de classificação para o SST-2 são obtidos em a = 0, quando o modelo aprende apenas a imitar, sem levar em consideração os rótulos reais. A precisão ainda é menor que o BERT, mas significativamente melhor que o BiLSTM comum.

Tentei repetir os resultados do artigo, mas em meus experimentos o melhor resultado foi obtido em = 0,5.
É assim que os gráficos de perda e precisão são exibidos ao aprender LSTM da maneira usual. A julgar pelo comportamento da perda, o modelo aprendeu rapidamente e, em algum momento após a sexta era, o treinamento começou.
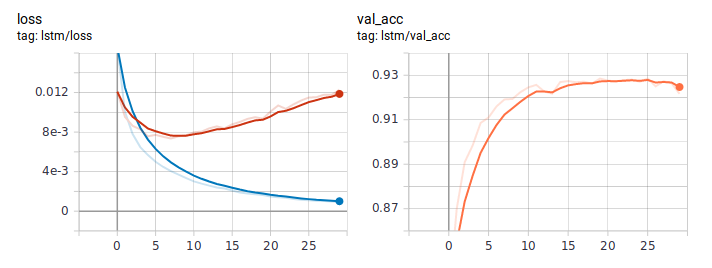
Gráficos de destilação:
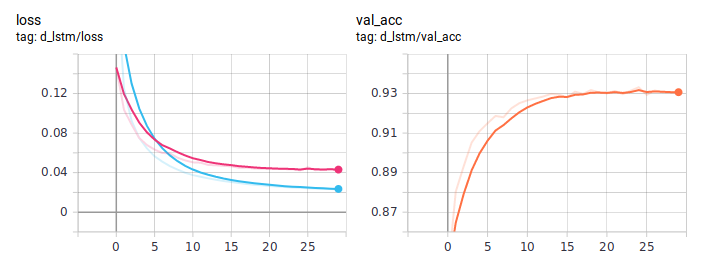
O BiLSTM destilado é consistentemente melhor que o normal. É importante que eles sejam absolutamente idênticos na arquitetura, a única diferença está na maneira de ensinar. Publiquei o código de treinamento completo no GitHub .
Conclusão
Neste guia, tentei explicar a idéia básica de uma abordagem de destilação. A arquitetura específica do aluno dependerá da tarefa em questão. Mas, em geral, essa abordagem é aplicável em qualquer tarefa prática. Devido à complexidade no estágio de treinamento do modelo, é possível obter um aumento significativo em sua qualidade, mantendo a simplicidade original da arquitetura.