NeurIPS (
Sistemas de processamento de informações neurais ) é a maior conferência do mundo em aprendizado de máquina e inteligência artificial e o principal evento no mundo do aprendizado profundo.
Na nova década, os engenheiros do DS também dominarão biologia, lingüística e psicologia? Vamos contar em nossa análise.

Este ano, a conferência reuniu mais de 13.500 pessoas de 80 países em Vancouver, Canadá. Este não é o primeiro ano em que o Sberbank representou a Rússia na conferência - a equipe do DS falou sobre a introdução do BC nos processos bancários, sobre a concorrência do BC e sobre os recursos da plataforma Sberbank DS. Quais foram as principais tendências de 2019 na comunidade de ML? Os participantes da conferência contam:
Andrey Chertok e
Tatyana Shavrina .
Este ano, mais de 1400 artigos foram aceitos no NeurIPS - algoritmos, novos modelos e novos aplicativos para novos dados.
Link para todos os materiaisConteúdo:
- Tendências
- Interpretabilidade do modelo
- Multidisciplinaridade
- Raciocínio
- RL
- Gan
- Principais palestras convidadas
- "Inteligência social", Blaise Aguera e Arcas (Google)
- “Ciência de dados verídicos”, Bin Yu (Berkeley)
- “Modelagem do comportamento humano com aprendizado de máquina: oportunidades e desafios”, Nuria M Oliver, Albert Ali Salah
- “Do Sistema 1 ao Sistema 2 de Aprendizado Profundo”, Yoshua Bengio
2019 Tendências
1. Interpretabilidade do modelo e a nova metodologia de MLO tópico principal da conferência é a interpretação e a prova de por que obtemos esses ou aqueles resultados. Você pode falar por um longo tempo sobre a importância filosófica de interpretar a “caixa preta”, mas havia mais métodos reais e desenvolvimentos técnicos nessa área.
A metodologia de reprodutibilidade dos modelos e a extração de conhecimento deles é um novo conjunto de ferramentas da ciência. Os modelos podem servir como uma ferramenta para adquirir novos conhecimentos e testá-los, e todos os estágios de pré-processamento, treinamento e aplicação do modelo devem ser reproduzíveis.
Uma proporção significativa de publicações é dedicada não à construção de modelos e ferramentas, mas a problemas de garantia de segurança, transparência e verificabilidade dos resultados. Em particular, um fluxo separado apareceu sobre ataques ao modelo (ataques adversários), e são consideradas opções para ataques ao treinamento e ataques a aplicativos.
Artigos:
- Veridical Data Science é um artigo sobre metodologia de verificação de modelo. Ele inclui uma visão geral de ferramentas modernas para interpretar modelos, em particular, o uso da atenção e a obtenção de importância de recursos devido à "destilação" da rede neural por modelos lineares.
- Assim parece: Aprendizado profundo para reconhecimento de imagem interpretável Chaofan Chen, Oscar Li, Daniel Tao, Alina Barnett, Cynthia Rudin, Jonathan K. Su
- Uma referência para métodos de interpretabilidade em redes neurais profundas Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, Been Kim
- Rumo à Aprendizagem por Reforço Interpretável Usando Agentes de Atenção Aumentada Alexander Mott, Daniel Zoran, Mike Chrzanowski, Daan Wierstra, Danilo Jimenez Rezende
- Uma medida de importância de recurso MDI debitada para florestas aleatórias Xiao Li, Yu Wang, Sumanta Basu, Karl Kumbier, Bin Yu
- Extração de conhecimento sem dados observáveis Jaemin Yoo, Minyong Cho, Taebum Kim, U Kang
- Um passo em direção à quantificação da pesquisa de aprendizado de máquina reproduzível independentemente Edward Raff
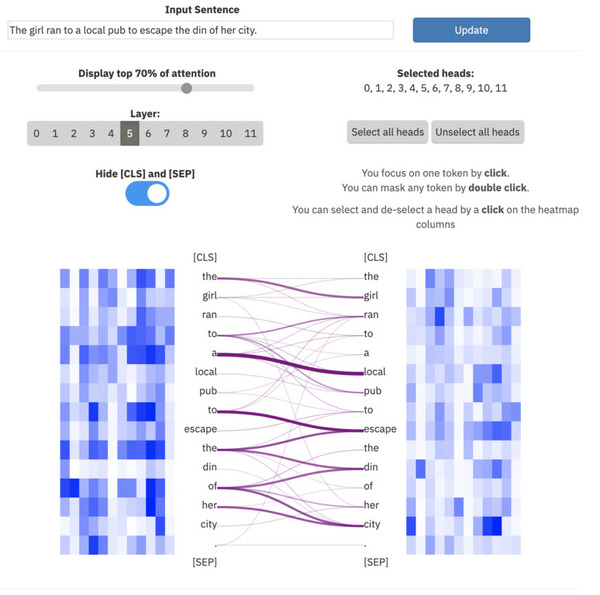 ExBert.net mostra interpretação de modelo para tarefas de processamento de texto
ExBert.net mostra interpretação de modelo para tarefas de processamento de texto
2. MultidisciplinaridadePara garantir uma verificação confiável e desenvolver mecanismos para testar e reabastecer o conhecimento, precisamos de especialistas de áreas afins que tenham competência em ML e na área de atuação (medicina, linguística, neurobiologia, educação etc.). Destaca-se a presença mais significativa de trabalhos e apresentações sobre neurociências e ciências cognitivas - há uma aproximação de especialistas e idéias de empréstimos.
Além dessa aproximação, a multidisciplinaridade é planejada no processamento conjunto de informações de várias fontes: texto e fotos, texto e jogos, banco de dados de gráficos + texto e fotos.
Artigos:
 Dois modelos - estrategista e intérprete - baseados em RL e PNL desempenham uma estratégia online3. Raciocínio
Dois modelos - estrategista e intérprete - baseados em RL e PNL desempenham uma estratégia online3. RaciocínioFortalecer a inteligência artificial - um movimento em direção a sistemas de auto-aprendizagem, "consciente", raciocínio e argumentação (raciocínio). Em particular, a inferência causal e o raciocínio de senso comum se desenvolvem. Parte dos relatórios é dedicada à meta-aprendizagem (como aprender a aprender) e à combinação de tecnologias DL com lógica de 1ª e 2ª ordem - o termo Inteligência Geral Artificial (AGI) torna-se um termo comum nos discursos dos palestrantes.
Artigos:
- Aprendizagem de gráficos heterogêneos para o raciocínio visual do senso comum Weijiang Yu, Jingwen Zhou, Weihao Yu, Xiaodan Liang e Nong Xiao
- Construindo uma ponte sobre o aprendizado de máquina e o raciocínio lógico pelo aprendizado abdutivo Wang-Zhou Dai, Qiuling Xu, Yang Yu, Zhi-Hua Zhou
- Implicitamente aprendendo a raciocinar em lógica de primeira ordem Vaishak Belle, Brendan Juba
- PHYRE: Uma nova referência para o raciocínio físico Anton Bakhtin, Laurens van der Maaten, Justin Johnson, Laura Gustafson e Ross Girshick
- Incorporação Quântica de Conhecimento para Raciocínio Dinesh Garg, Shajith Ikbal, Santosh K. Srivastava, Harit Vishwakarma, Hima Karanam, L Venkata Subramaniam
4. Aprendizado de ReforçoA maior parte do trabalho continua a desenvolver as áreas tradicionais de RL - DOTA2, Starcraft, combinando arquiteturas com visão computacional, PNL, bancos de dados de gráficos.
Um dia separado da conferência foi dedicado ao workshop de RL, que apresentou a arquitetura do Modelo Crítico de Ator Otimista, superando todos os anteriores, em particular o Soft Actor Critic.
Artigos:
 Jogadores do StarCraft lutam com a Alphastar (DeepMind)5. GAN
Jogadores do StarCraft lutam com a Alphastar (DeepMind)5. GANAs redes generativas ainda estão no foco das atenções: muitos trabalhos usam GANs de baunilha para provas matemáticas e também os aplicam em versões novas e incomuns (modelos geradores de gráficos, trabalhos em série, aplicativos para causar e afetar relacionamentos em dados, etc.).
Artigos:
Como o trabalho foi realizado mais de
1.400 abaixo, falaremos sobre as performances mais importantes.
Palestras convidadas
"Inteligência social", Blaise Aguera e Arcas (Google)
LinkSlides e vídeosO relatório é dedicado à metodologia geral de aprendizado de máquina e às perspectivas que estão mudando o setor no momento - que encruzilhada estamos enfrentando? Como o cérebro e a evolução funcionam, e por que usamos tão pouco que já sabemos bem sobre o desenvolvimento de sistemas naturais?
O desenvolvimento industrial do ML coincide em grande parte com os marcos do desenvolvimento do Google, que publica sua pesquisa no NeurIPS de ano para ano:
- 1997 - lançamento das capacidades de busca, primeiros servidores, pequeno poder de computação
- 2010 - Jeff Dean lança o projeto Google Brain, um boom da rede neural no início
- 2015 - implementação industrial de redes neurais, reconhecimento rápido de faces diretamente no dispositivo local, processadores de baixo nível aprimorados pela computação tensorial - TPU. Google lança Coral ai - um análogo do raspberry pi, um mini-computador para introduzir redes neurais em instalações experimentais
- 2017 - Google inicia o desenvolvimento de um treinamento descentralizado e combina os resultados do treinamento de redes neurais de diferentes dispositivos em um modelo - no android
Hoje, todo um setor se preocupa com a segurança dos dados, combinando e reproduzindo os resultados da aprendizagem em dispositivos locais.
Aprendizado federado - direção de ML, em que modelos individuais estudam independentemente e depois são combinados em um único modelo (sem centralizar os dados de origem), ajustado para eventos raros, anomalias, personalização etc. Todos os dispositivos Android são essencialmente um único supercomputador de computação para o Google.
Modelos generativos baseados em aprendizado federado são uma área promissora no futuro, segundo o Google, que está "nos estágios iniciais de crescimento exponencial". Os GANs, de acordo com o professor, são capazes de aprender a reproduzir o comportamento em massa de populações de organismos vivos, pensando em algoritmos.
Usando duas arquiteturas simples de GAN como exemplo, é mostrado que nelas a busca pelo caminho de otimização vagueia em um círculo, o que significa que a otimização não ocorre como tal. Além disso, esses modelos modelam com sucesso os experimentos que os biólogos realizam em populações bacterianas, forçando-os a aprender novas estratégias de comportamento em busca de alimentos. Podemos concluir que a vida funciona de maneira diferente da função de otimização.
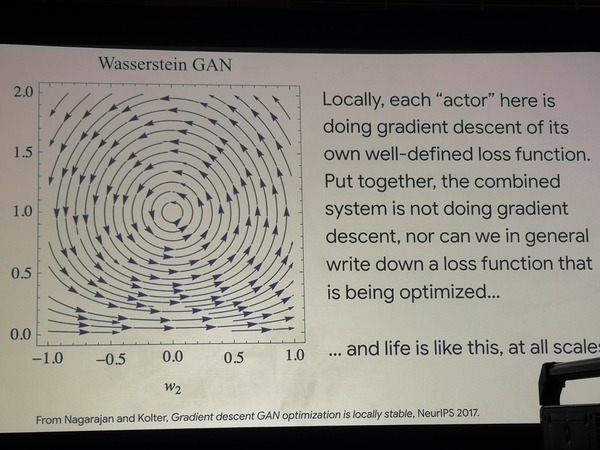 Otimização errônea de GAN
Otimização errônea de GANTudo o que estamos fazendo no âmbito do aprendizado de máquina agora são tarefas estreitas e extremamente formalizadas, enquanto esses formalismos são pouco generalizados e não correspondem ao nosso conhecimento da matéria em campos como neurofisiologia e biologia.
O que realmente vale a pena emprestar do campo da neurofisiologia em um futuro próximo é a nova arquitetura dos neurônios e uma pequena revisão dos mecanismos de propagação traseira do erro.
O próprio cérebro humano não aprende a usar uma rede neural:
- Ele não tem introduções preliminares aleatórias, incluindo aquelas estabelecidas pelos sentidos e na infância
- Ele tem as orientações estabelecidas para o desenvolvimento instintivo (o desejo de aprender um idioma com uma criança, postura ereta)
Aprender o cérebro individual é uma tarefa de baixo nível, talvez devêssemos considerar as “colônias” de indivíduos que mudam rapidamente, transmitindo conhecimento uns aos outros para reproduzir os mecanismos de evolução do grupo.
O que podemos levar para os algoritmos de ML agora:
- Aplique modelos de linhagem celular que forneçam treinamento para a população, mas a curta vida do indivíduo ("cérebro individual")
- Aprendizado de poucos tiros em alguns exemplos
- Estruturas neuronais mais complexas, funções de ativação ligeiramente diferentes
- Passando o "genoma" para as gerações futuras - algoritmo de propagação traseira
- Assim que conectarmos a neurofisiologia e as redes neurais, aprenderemos como construir um cérebro multifuncional a partir de muitos componentes.
Desse ponto de vista, a prática das soluções SOTA é prejudicial e deve ser revisada para desenvolver tarefas comuns (benchmarks).
“Ciência de dados verídicos”, Bin Yu (Berkeley)
Vídeos e slidesO relatório é dedicado ao problema de interpretação dos modelos de aprendizado de máquina e à metodologia de verificação direta e verificação. Qualquer modelo de ML treinado pode ser percebido como uma fonte de conhecimento que precisa ser extraída dele.
Em muitas áreas, especialmente na medicina, a aplicação do modelo é impossível sem extrair esse conhecimento oculto e interpretar os resultados do modelo - caso contrário, não teremos certeza de que os resultados serão estáveis, não aleatórios, confiáveis e não matarão o paciente. Toda a direção da metodologia de trabalho está se desenvolvendo dentro do paradigma de aprendizado profundo e vai além de seus limites - a ciência de dados verídica. O que é isso
Queremos alcançar a qualidade das publicações científicas e a reprodutibilidade dos modelos para que sejam:
- previsível
- computável
- estável
Esses três princípios formam a base da nova metodologia. Como os modelos de ML podem ser testados com base nesses critérios? A maneira mais fácil é construir modelos imediatamente interpretáveis (regressões, árvores de decisão). No entanto, queremos obter as vantagens imediatas do aprendizado profundo.
Várias maneiras existentes de lidar com o problema:
- interpretar o modelo;
- Use métodos baseados em atenção
- usar conjuntos de algoritmos para treinamento e garantir que modelos interpretáveis lineares aprendam a prever as mesmas respostas que uma rede neural, interpretando recursos de um modelo linear;
- Alterar e aumentar os dados de treinamento. Isso inclui a adição de ruído, interferência e aumento de dados;
- quaisquer métodos que garantam que os resultados do modelo não sejam aleatórios e não dependam de pequenas interferências indesejadas (ataques adversários);
- interpretar o modelo pós-factum após o treinamento;
- estude pesos de sinais de várias maneiras;
- estudar as probabilidades de todas as hipóteses, a distribuição de classes.
 Ataque adversário a um porco
Ataque adversário a um porcoErros de modelagem custam caro a todos: um exemplo vívido - o trabalho de Reinhart e Rogov "
Crescimento em tempos de dívida " influenciou as políticas econômicas de muitos países europeus e os forçou a seguir políticas de austeridade, mas a verificação cuidadosa dos dados e seus anos de processamento mais tarde mostrou o resultado oposto!
Qualquer tecnologia ML tem seu próprio ciclo de vida, da implementação à implementação. A tarefa da nova metodologia é verificar três princípios básicos em cada estágio da vida do modelo.
Resumo:
- Vários projetos estão sendo desenvolvidos para ajudar o modelo de ML a ser mais confiável. Por exemplo, deeptune (link para: github.com/ChrisCummins/paper-end2end-dl );
- Para um maior desenvolvimento da metodologia, é necessário melhorar significativamente a qualidade das publicações no campo da ML;
- O aprendizado de máquina precisa de líderes com treinamento multidisciplinar e conhecimento nas áreas técnica e humanitária.
“Modelagem do comportamento humano com aprendizado de máquina: oportunidades e desafios” Nuria M Oliver, Albert Ali Salah
Palestra sobre modelagem do comportamento humano, seus fundamentos tecnológicos e perspectivas de aplicação.
A modelagem do comportamento humano pode ser dividida em:
- comportamento individual
- comportamento em pequenos grupos
- comportamento em massa
Cada um desses tipos pode ser modelado usando ML, mas com informações e recursos de entrada completamente diferentes. Cada tipo também possui seus próprios problemas éticos pelos quais cada projeto passa:
- comportamento individual - roubo de identidade, fraude profunda;
- o comportamento de grupos de pessoas - desanonimização, obtenção de informações sobre movimentos, ligações telefônicas, etc;
Comportamento individualEm maior medida, o tema da Visão por Computador - reconhecimento das emoções humanas, suas reações. É possível apenas no contexto, no tempo ou com uma escala relativa de sua própria variabilidade de emoções. No slide, está o reconhecimento das emoções de Mona Lisa usando o contexto do espectro emocional das mulheres mediterrâneas. Resultado: um sorriso de alegria, mas com desprezo e nojo. O motivo é mais provável na maneira técnica de determinar a emoção "neutra".
Comportamento de pequenos gruposAté agora, o pior é modelado devido à falta de informação. Os trabalhos de 2018 a 2019 foram mostrados como exemplo. em dezenas de pessoas X dezenas de vídeos (consulte conjuntos de dados de imagem 100k ++). Para a melhor simulação nesta tarefa, são necessárias informações multimodais, de preferência de sensores a um tele-altímetro, termômetro, gravação de microfone, etc.
Comportamento em massaA área mais desenvolvida, como o cliente são as Nações Unidas e muitos estados. Câmeras de vigilância externa, dados de torres telefônicas - cobrança, SMS, chamadas, dados sobre o movimento entre as fronteiras dos estados - tudo isso dá uma idéia muito confiável do movimento dos fluxos das pessoas, das instabilidades sociais. Aplicações potenciais da tecnologia: otimização das operações de resgate, assistência e evacuação oportuna da população em caso de emergência. Os modelos utilizados são, na maioria das vezes, mal interpretados - esses são vários LSTMs e redes convolucionais. Houve uma breve observação de que a ONU está fazendo lobby por uma nova lei que obrigará as empresas europeias a compartilhar dados anonimizados necessários para qualquer pesquisa.
“Do Sistema 1 ao Sistema 2 de Aprendizado Profundo”, Yoshua Bengio
SlidesEm uma palestra de Joshua, o aprendizado profundo de Benjio encontra a neurociência no nível de estabelecimento de metas.
Benjio identifica dois tipos principais de tarefas, de acordo com a metodologia do ganhador do Nobel Daniel Kahneman (o livro “
Pense devagar, resolva rapidamente ”)
tipo 1 - Sistema 1, as ações inconscientes que realizamos “na máquina” (o cérebro antigo): dirigir um carro em lugares familiares, caminhar, reconhecer rostos.
tipo 2 - Sistema 2, ações conscientes (córtex cerebral), estabelecimento de metas, análise, pensamento, tarefas compostas.
Até o momento, a IA alcança níveis suficientes apenas em tarefas do primeiro tipo - enquanto nossa tarefa é trazê-la para o segundo, tendo aprendido como executar operações multidisciplinares e operar com lógica, habilidades cognitivas de alto nível.
Para atingir esse objetivo, propõe-se:
- use a atenção como um mecanismo chave para modelar o pensamento em tarefas da PNL
- use o meta-aprendizado e o aprendizado de representação para melhor modelar os sinais que afetam a consciência e sua localização - e com base neles mudar para operar com conceitos de nível superior.
Em vez da conclusão, deixamos a entrada da palestra convidada: Benjio é um dos muitos cientistas que estão tentando expandir o campo da ML além dos problemas de otimização, SOTA e novas arquiteturas.
A questão permanece em aberto, como a combinação dos problemas de consciência, a influência da linguagem no pensamento, neurobiologia e algoritmos é o que nos espera no futuro e nos permitirá avançar para máquinas que “pensam” como pessoas.
Obrigada