Na verdade, não pretendia ver de que cor eram as entranhas de Rust. Peguei um projeto de hobby no Go, fui ao GitHub para ver o estado do fasthttp: está em desenvolvimento? Bem, pelo menos suportado? Cresceu. Fui, procurei onde o fasthttp fica nos benchmarks do TechEmpower . Eu olho: e lá fasthttp mal mostra metade do que o líder obtém - algumas ações em alguns Rust. Que dor.
Aqui eu cruzava os braços, batia a cabeça no chão (três vezes) e gritava: "Aleluia, na verdade Rust é um deus verdadeiro, quão cego eu era antes!". Mas as alças não deram certo ou a testa se arrependeu ... Em vez disso, entrei no código dos testes escritos em Go e nos testes actix-web no Rust. Para resolver isso.
Depois de algumas horas, descobri:
- por que a estrutura actix-web Rust ocupa o primeiro lugar em todos os testes TechEmpower,
- como o Java inicia o Script.
Agora vou contar tudo em ordem.
O que é o TechEmpower Framework Benchmark?
Se uma estrutura da web demonstrar se vai ou, digamos, às vezes pensar em sussurrar para os amigos "eu sou rápido", ela certamente cairá no benchmark do TechEmpower Framework. Um local popular para medir o desempenho.
O site tem um design peculiar: as guias de filtros, rodadas, condições e resultados para diferentes tipos de testes estão espalhados na página com uma mão generosa. Tão generoso e abrangente que você nem percebe. Mas vale a pena clicar nas guias, as informações por trás delas são úteis.
A maneira mais fácil é obter os resultados dos testes em texto simples, "Olá, mundo!" para servidores web. Os autores da estrutura geralmente fornecem um link para ela: supostamente estamos nos mantendo nos primeiros cem. O caso está correto e útil. Em geral, dar texto claro é bom para muitos, e os líderes entram em um grupo restrito.
Nas proximidades, nessas mesmas guias, estão os resultados de testes de outros tipos (cenários). Existem sete deles, mais detalhes podem ser encontrados aqui . Esses scripts testam não apenas como a estrutura / plataforma lida com o processamento de uma solicitação HTTP simples, mas uma combinação com um cliente de banco de dados, mecanismo de modelo ou serializador JSON.
Existem dados de teste em um ambiente virtual, em um hardware físico. Além dos gráficos, existem dados tabulares. Em geral, muitas coisas interessantes, vale a pena procurar, não apenas olhando para a posição da "sua" plataforma.
A primeira coisa que me veio à mente depois de passar pelos resultados dos testes: "Por que tudo é TÃO TÃO diferente do texto simples?!". Em texto simples, os líderes entram em um grupo restrito, mas quando se trata de trabalhar com o banco de dados, o actix-web lidera por uma margem significativa. Ao mesmo tempo, mostra um tempo estável de processamento de solicitações. Shaitan.
Outra anomalia: uma solução JavaScript incrivelmente poderosa. É chamado ex4x. Aconteceu que o código dele era um pouco menos do que completamente escrito em Java. Utilizado pelo Java Runtime, JDBC. O código JavaScript é traduzido em bytecode e cola as bibliotecas Java. Eles literalmente o pegaram - e anexaram o Script ao Java. Os truques dos rostos pálidos não têm limites.
Como ver o código e o que há dentro
O código para todos os testes está no GitHub. Tudo está em um único repositório, o que é muito conveniente. Você pode clonar e assistir, você pode assistir diretamente no GitHub. O teste envolve mais de 300 combinações diferentes da estrutura com serializadores, mecanismos de modelo e o cliente de banco de dados. Em diferentes linguagens de programação, com uma abordagem diferente para o desenvolvimento. As implementações em um idioma estão próximas e podem ser comparadas com a implementação em outros idiomas. O código é mantido pela comunidade, não é o trabalho de uma pessoa ou equipe.
O código de referência é um ótimo lugar para ampliar seus horizontes. É interessante analisar como pessoas diferentes resolvem os mesmos problemas. Não há muito código, as bibliotecas e soluções usadas são fáceis de distinguir. Não me arrependo de tudo que cheguei lá. Eu aprendi muito Primeiro de tudo sobre Rust.
Antes de Rust, eu tinha uma ideia muito vaga. Qualquer artigo sobre C, C ++, D e especialmente Go certamente contará com alguns comentadores que explicam detalhadamente e com angústia que vaidade, bobagem e estupidez são escritas em outra coisa, desde que exista. Gasconha Ferrugem. Às vezes, eles se empolgam tanto que dão exemplos de código do que uma pessoa despreparada ou poucos aceitando levado a um estupor: "Por que, por que, por que todos esses símbolos?!"
Portanto, abrir o código foi assustador.
Eu olhei Acontece que os programas no Rust podem ser lidos. Além disso, o código é lido tão bem que eu até instalei o Rust, tentei compilar o teste e mexer um pouco nele.
Aqui quase abandonei esse negócio, porque a compilação dura muito tempo. Muito tempo. Se eu fosse D'Artagnan, ou mesmo um colérico, teria corrido para a Gasconha, e mil demônios seguiriam desanimados. Mas eu consegui. Tomei chá de novo. Parece que nem uma xícara: no meu laptop, a primeira compilação levou cerca de 20 minutos e, no entanto, tudo ficou mais divertido. Talvez até a próxima grande atualização.
Mas não é o próprio Rust?
Não. Não é uma linguagem de programação.
Claro, Rust é uma linguagem maravilhosa. Poderoso, flexível, embora por hábito e detalhado. Mas a própria linguagem não escreverá código rápido. A linguagem é uma das ferramentas, uma das decisões tomadas pelo programador.
Como eu disse - doar texto simples é rapidamente obtido por muitos. O desempenho das estruturas actix-web, fasthttp e uma dúzia de outras ao processar uma solicitação simples é bastante comparável, ou seja, outros idiomas têm a capacidade técnica de competir com o Rust.
A própria Actix-web, é claro, é “culpada”: um produto rápido, pragmático e excelente. A serialização é conveniente, o mecanismo de modelo é bom - também ajuda muito.
Mais notavelmente, os resultados dos testes que trabalham com o banco de dados diferem.
Depois de cavar um pouco no código, destaquei três principais diferenças que (me parece) ajudaram os testes actix a se distanciarem dos concorrentes nos testes sintéticos:
- Modo de operação tokio-postgres em pipeline em pipeline;
- Usando uma única conexão com um teste de Rust em vez de um pool de conexões com um teste escrito em Go;
- Atualizando benchmarks actix com um único comando enviado por meio de uma consulta simples em vez de enviar vários comandos UPDATE.
Que tipo de modo de transporte?
Aqui está um trecho da documentação do tokio-postgres (usada no benchmark da biblioteca do cliente PostgreSQL) explicando o que seus desenvolvedores significam:
Sequential Pipelined | Client | PostgreSQL | | Client | PostgreSQL | |----------------|-----------------| |----------------|-----------------| | send query 1 | | | send query 1 | | | | process query 1 | | send query 2 | process query 1 | | receive rows 1 | | | send query 3 | process query 2 | | send query 2 | | | receive rows 1 | process query 3 | | | process query 2 | | receive rows 2 | | | receive rows 2 | | | receive rows 3 | | | send query 3 | | | | process query 3 | | receive rows 3 | |
O cliente no modo pipelined (pipelined) não espera uma resposta do PostgreSQL, mas envia a próxima consulta enquanto o PostgreSQL está processando a anterior. Pode-se observar que dessa maneira é possível processar a mesma sequência de consultas ao banco de dados significativamente mais rapidamente.
Se a conexão no modo pipelined for duplex (oferecendo a possibilidade de obter resultados em paralelo com o envio), esse tempo poderá ser ligeiramente reduzido. Parece que já existe uma versão experimental do tokio-postgres em que uma conexão duplex é aberta.
Como o cliente PostgreSQL envia várias mensagens (Parse, Bind, Execute e Sync) para cada consulta SQL enviada para execução e recebe uma resposta, o modo em pipeline será mais eficaz, mesmo ao processar consultas únicas.
E por que não está no Go?
Porque o Go geralmente usa pools de conexão com o banco de dados. As conexões não devem ser usadas em paralelo.
Se você executar as mesmas consultas SQL por meio de um pool, em vez de uma conexão, teoricamente poderá obter um tempo de execução ainda mais curto com um cliente serial comum do que quando estiver trabalhando em uma única conexão, seja três vezes em pipeline:
| Connection | Connection 2 | Connection 3 | PostgreSQL | |----------------|----------------|----------------|-----------------| | send query 1 | | | | | | send query 2 | | process query 1 | | receive rows 1 | | send query 3 | process query 2 | | | receive rows 2 | | process query 3 | | | receive rows 3 | |
Parece que a pele de carneiro (modo de transporte) não vale a pena.
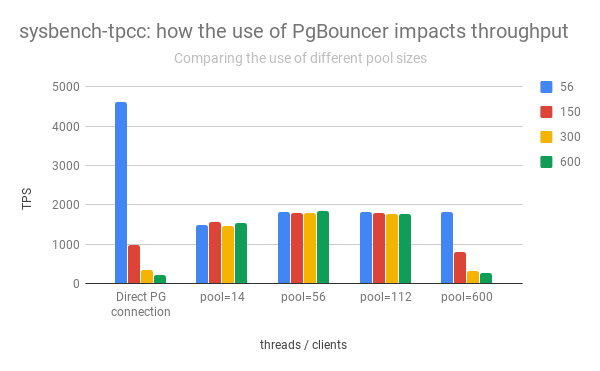
Somente sob carga alta, o número de conexões com o servidor PostgreSQL pode ser um problema.
E o que o número de conexões tem a ver com isso?
O ponto aqui é como o servidor PostgreSQL responde a um aumento no número de conexões.
O grupo esquerdo de colunas mostra a ascensão e queda do desempenho do PostgreSQL, dependendo do número de conexões abertas:
( Adaptado do post Percona )
Pode-se observar que, com um aumento no número de conexões abertas, o desempenho do servidor PostgreSQL está caindo rapidamente.
Além disso, abrir uma conexão direta não é "gratuito". Imediatamente após a abertura, o cliente envia informações de serviço "concorda" com o servidor PostgreSQL sobre como as solicitações serão processadas.
Portanto, na prática, você deve limitar o número de conexões ativas com o PostgreSQL, frequentemente passando-as adicionalmente pelo pgbouncer ou outra odisséia.
Então, por que o Actix-Web foi mais rápido?
Primeiro, o próprio Actix-Web é bastante rápido. É ele quem estabelece o "teto", e ele é um pouco mais alto que o dos outros. Outras bibliotecas usadas (serde, yarde) também são muito, muito produtivas. Mas parece-me que, em testes que trabalham com o PostgreSQL, foi possível sair porque o servidor actix-web inicia um encadeamento no núcleo do processador. Cada thread abre apenas uma conexão com o PostgreSQL.
Quanto menos conexões ativas, mais rápido o PostgreSQL funciona (veja os gráficos acima).
O cliente que opera no modo pipelined (tokio-postgres) permite que você use efetivamente uma conexão com o PostgreSQL para processamento paralelo de consultas de usuários. Os manipuladores de solicitação HTTP despejam seus comandos SQL em uma fila e alinham em outra para receber resultados. Os resultados são divertidos, os atrasos são mínimos, todos estão felizes. O desempenho geral é superior a um sistema com um pool de conexões.
Então você precisa abandonar a piscina, escrever um cliente de pipeline do PostgreSQL e a felicidade e a velocidade incrível surgirão imediatamente?
Possivelmente. Mas não de uma só vez.
Quando é improvável que o modo transportador seja salvo e certamente não será salvo
O esquema usado no código de referência não funcionará com transações do PostgreSQL.
No benchmark, as transações não são necessárias e o código é escrito levando em consideração que não haverá transações. Na prática, eles acontecem.
Se o código de back-end abrir uma transação do PostgreSQL (por exemplo, para alterar atômicas duas tabelas diferentes), todos os comandos enviados por essa conexão serão executados dentro dessa transação.
Como a conexão com o PostgreSQL é usada em paralelo, tudo se confunde. Os comandos que devem ser executados em uma transação projetada pelo desenvolvedor são combinados com comandos sql iniciados por manipuladores de solicitação http paralelos. Receberemos perda aleatória de dados e problemas com sua integridade.
Então, olá transação - adeus uso paralelo de uma conexão. Você precisará garantir que a conexão não seja usada por outros manipuladores de solicitação http. Você precisará interromper o processamento de solicitações HTTP recebidas antes de fechar a transação ou usar um pool para transações, abrindo várias conexões com o servidor de banco de dados. Existem várias implementações de pool para o Rust, e não uma. Além disso, eles existem no Rust separadamente da implementação do cliente de banco de dados. Você pode escolher de acordo com o gosto, cor, cheiro ou aleatoriamente. Ir não funciona dessa maneira. O poder dos genéricos, sim.
Um ponto importante: no teste, cujo código eu procurei, as transações não abrem. Esta questão simplesmente não vale a pena. O código de referência é otimizado para uma tarefa específica e condições operacionais muito específicas da aplicação. A decisão de usar uma conexão por fluxo de servidor provavelmente foi tomada conscientemente e mostrou-se muito eficaz.
Existe algo mais interessante no código de referência?
Sim
O cenário para medir o desempenho é detalhado em detalhes. Bem como os critérios que o código que participa dos testes deve atender. Uma delas é que todas as consultas ao servidor de banco de dados devem ser executadas seqüencialmente.
O seguinte fragmento de código (um pouco abreviado) parece que não atende aos critérios:
let mut worlds = Vec::with_capacity(num);
Tudo parece um lançamento típico de processos paralelos. Porém, como uma conexão com o PostgreSQL é usada, as consultas ao servidor de banco de dados são enviadas seqüencialmente. Um por um. Conforme necessário. Nenhum crime.
Porque Bem, em primeiro lugar, no código (que foi dado na redação, que funcionou na 18ª rodada), async / wait ainda não é usado, mas apareceu em Rust mais tarde. E, através de futuros, é mais fácil enviar consultas SQL "em paralelo" - como no código acima. Isso permite que você obtenha um aumento de desempenho adicional: enquanto o PostgreSQL aceita e processa a primeira consulta SQL, o restante é alimentado a ela. O servidor da Web não espera o resultado de cada um, mas alterna para outras tarefas e retorna ao processamento da solicitação http apenas quando todas as consultas SQL forem concluídas.
Para o PostgreSQL, o bônus é que o mesmo tipo de consulta no mesmo contexto (conexão) seja seguido. A probabilidade de o plano de consulta não ser reconstruído aumenta.
Acontece que as vantagens do modo de pipeline (consulte o diagrama da documentação do tokio-postgres) são totalmente exploradas, mesmo ao processar uma única solicitação http.
O que mais?
Usando o protocolo de consulta simples para atualizações em lote
O protocolo de comunicação entre o cliente e o servidor PostgreSQL permite métodos alternativos para executar comandos SQL. O protocolo usual (Consulta estendida) envolve o envio de várias mensagens ao cliente: Analisar, Vincular, Executar e Sincronizar. Uma alternativa é o protocolo Simple Query, segundo o qual uma única mensagem é suficiente para executar um comando e obter resultados - Consulta.
A principal diferença entre o protocolo usual é a transferência de parâmetros de solicitação: eles são transmitidos separadamente do próprio comando. É mais seguro O protocolo simplificado assume que todos os parâmetros da consulta SQL serão convertidos em uma sequência e incluídos no corpo da consulta.
Uma solução interessante usada nos benchmarks actix-web foi atualizar várias entradas da tabela com um único comando enviado pelo protocolo Simple Query.
De acordo com a referência, ao processar uma solicitação do usuário, o servidor da web deve atualizar vários registros na tabela, escrever números aleatórios. Obviamente, atualizar registros sucessivamente com consultas seqüenciais leva mais tempo do que uma única consulta atualizando todos os registros de uma só vez.
A solicitação gerada no código de teste é mais ou menos assim:
UPDATE world SET randomnumber = temp.randomnumber FROM (VALUES (1, 2), (2, 3) ORDER BY 1) AS temp(id, randomnumber) WHERE temp.id = world.id
Onde (1, 2), (2, 3) são os pares de identificadores de linha / novo valor do campo número aleatório.
O número de registros atualizados é variável, não fazendo sentido preparar a solicitação (PREPARE) antecipadamente. Como os dados para atualização são numéricos e a fonte pode ser confiável (o próprio código de teste), não há risco de injeção de SQL, os dados são simplesmente incluídos no corpo do SQL e tudo é enviado usando o protocolo Simple Query.
Há rumores de consulta simples. Encontrei uma recomendação: "Trabalhe apenas no protocolo Simple Query, e tudo será rápido e bom". Eu a percebo com muito ceticismo. A Consulta Simples permite reduzir o número de mensagens enviadas ao servidor PostgreSQL movendo o processamento dos parâmetros de consulta para o lado do cliente. Você pode ver o ganho para consultas geradas dinamicamente com um número variável de parâmetros. Para o mesmo tipo de consultas SQL (que são mais comuns), o ganho não é óbvio. Bem, e quão seguro será o processamento dos parâmetros da consulta, no caso da Consulta Simples, ela determina a implementação da biblioteca do cliente.
Como escrevi acima, neste caso, o corpo da consulta SQL é gerado dinamicamente, os dados são numéricos e gerados pelo próprio servidor. A combinação perfeita para consulta simples. Mas, mesmo neste caso, vale a pena testar outras opções. As alternativas dependem da plataforma PostgreSQL e do cliente: o pgx (client for Go) permite enviar um pacote de comandos, JDBC - para executar um comando várias vezes seguidas com parâmetros diferentes. Ambas as soluções podem ser executadas na mesma velocidade ou até mais rápidas.
Então, por que a Rust está liderando?
O líder, é claro, não é Rust. Os testes baseados no actix-web estão liderando - é ele quem define o "teto" do desempenho. Existem, por exemplo, foguetes e ferro, que ocupam posições modestas. Mas, no momento, é o actix-web que determina o potencial de uso do Rust no desenvolvimento da web. Quanto a mim, o potencial é muito alto.
Outro servidor "secreto" não óbvio, mas importante, baseado no actix-web, que permitiu ocupar o primeiro lugar em todos os benchmarks do TechEmpower - em como ele funciona com o PostgreSQL:
- Somente uma conexão com o PostgreSQL por fluxo do servidor da web é aberta. Essa conexão usa o modo em pipeline, o que permite que seja efetivamente usada para processamento paralelo de solicitações de usuários.
- Quanto menos conexões ativas, mais rápido o PostgreSQL responde. A velocidade do processamento de solicitações do usuário aumenta. Ao mesmo tempo, sob carga, todo o sistema funciona mais estável (os atrasos no processamento de solicitações de entrada são mais baixos, crescem mais lentamente).
Onde a velocidade é importante, essa opção provavelmente será mais rápida do que o uso de multiplexadores (como pgbouncer e odyssey). E certamente ele foi mais rápido nos benchmarks.
É muito interessante como async / waitit, que apareceu em Rust, e o recente drama com o actix-web afetará a popularidade do Rust no desenvolvimento da web. Também é interessante como os resultados do teste serão alterados após processá-los no modo assíncrono / aguardado.