Veremos como o Zabbix funciona com o banco de dados TimescaleDB como um back-end. Mostramos como começar do zero e como migrar com o PostgreSQL. Também fornecemos testes de desempenho comparativos das duas configurações.

HighLoad ++ Siberia 2019. Tomsk Hall. 24 de junho, 16:00. Resumos e
apresentação . A próxima conferência HighLoad ++ será realizada nos dias 6 e 7 de abril de 2020 em São Petersburgo. Detalhes e ingressos
aqui .
Andrey Gushchin (doravante denominado
AG): - Sou engenheiro de suporte técnico da ZABBIX (doravante denominado Zabbix), um treinador. Trabalho com suporte técnico há mais de 6 anos e fui diretamente confrontado com o desempenho. Hoje vou falar sobre o desempenho que o TimescaleDB pode oferecer quando comparado ao PostgreSQL 10. regular. Além disso, alguma parte introdutória - sobre como ele funciona.
Principais desafios de desempenho: da coleta à limpeza de dados
Para começar, existem certos desafios de desempenho que todo sistema de monitoramento encontra. O primeiro desafio de desempenho é a rápida coleta e processamento de dados.

Um bom sistema de monitoramento deve receber prontamente, em tempo hábil, todos os dados, processá-los de acordo com as expressões de gatilho, ou seja, processá-los de acordo com alguns critérios (em diferentes sistemas, é diferente) e salvá-los no banco de dados para usar esses dados no futuro.

O segundo desafio de desempenho é manter a história. Armazene no banco de dados com frequência e tenha acesso rápido e conveniente a essas métricas coletadas durante um período de tempo. O mais importante é que é conveniente obter esses dados, usá-los em relatórios, gráficos, gatilhos, em alguns valores limite, para alertas, etc.

O terceiro desafio de desempenho é limpar o histórico, ou seja, quando seu dia é tal que você não precisa armazenar nenhuma métrica detalhada que foi coletada em cinco anos (até meses ou dois meses). Alguns nós da rede foram excluídos ou, em alguns hosts, as métricas não são mais necessárias porque já estão desatualizadas e não são mais coletadas. Tudo isso precisa ser limpo para que seu banco de dados não cresça em um tamanho grande. Em geral, limpar o histórico costuma ser um teste sério para o armazenamento - muitas vezes afeta o desempenho.
Como resolver problemas de cache?
Agora vou falar especificamente sobre o Zabbix. No Zabbix, a primeira e a segunda chamadas são resolvidas usando o cache.

Coleta e processamento de dados - usamos RAM para armazenar todos esses dados. Agora esses dados serão discutidos em mais detalhes.
Também no lado do banco de dados, há um certo cache para as principais amostras - para gráficos, outras coisas.
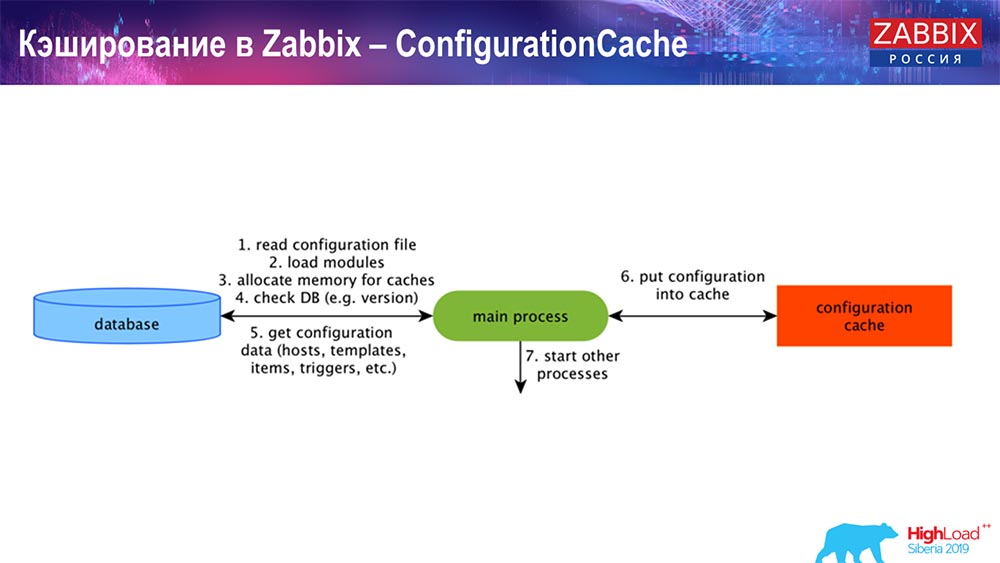
Armazenamento em cache no lado do servidor Zabbix: temos ConfigurationCache, ValueCache, HistoryCache, TrendsCache. O que é isso

O ConfigurationCache é o principal cache no qual armazenamos métricas, hosts, itens de dados, gatilhos; tudo o que você precisa para processar o pré-processamento, coletar dados, de quais hosts coletar, com que frequência. Tudo isso é armazenado no ConfigurationCache, para não ir ao banco de dados, nem criar solicitações desnecessárias. Após o início do servidor, atualizamos esse cache (criamos) e periodicamente (dependendo das configurações).
Armazenamento em cache no Zabbix. Coleta de dados
Aqui o esquema é bastante grande:

Os principais no esquema são esses coletores:
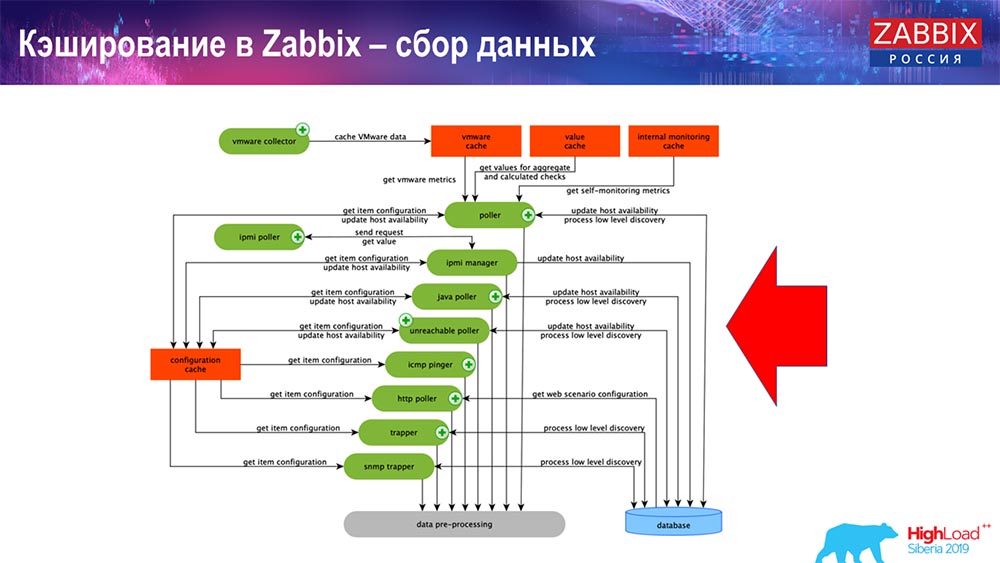
Estes são os próprios processos de montagem, vários “pesquisadores” responsáveis por diferentes tipos de montagem. Eles coletam dados via icmp, ipmi, de acordo com diferentes protocolos e transferem tudo para o pré-processamento.
Histórico de Pré-ProcessamentoCache
Além disso, se tivermos calculado elementos de dados (quem conhece o Zabbix - sabe), ou seja, calculados, elementos de dados agregados, nós os retiramos diretamente do ValueCache. Sobre como é preenchido, direi mais tarde. Todos esses coletores usam o ConfigurationCache para obter seus trabalhos e depois transmiti-los ao pré-processamento.
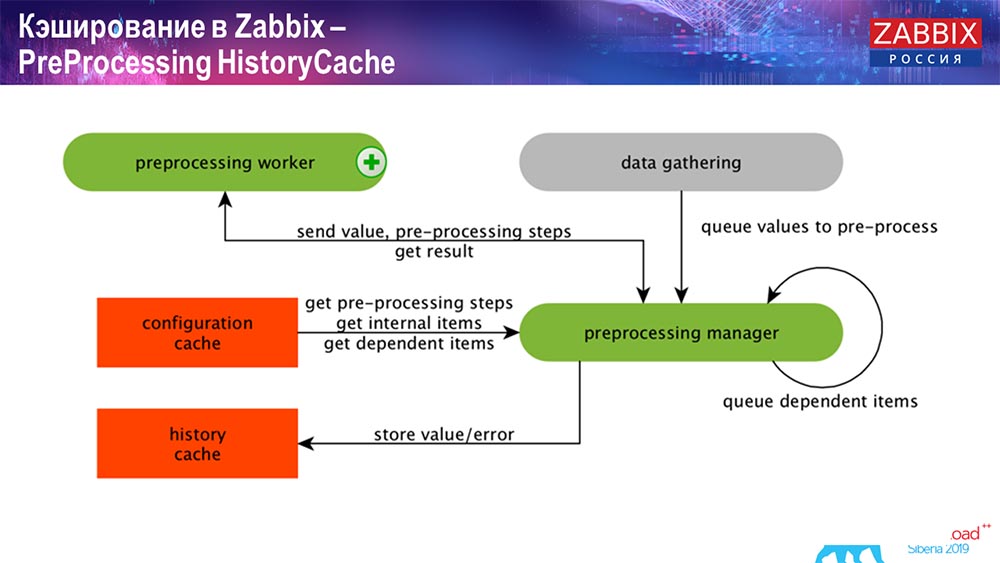
O pré-processamento também usa o ConfigurationCache para obter etapas de pré-processamento; processa esses dados de várias maneiras. A partir da versão 4.2, nós a submetemos ao proxy. Isso é muito conveniente, porque o pré-processamento é uma operação bastante difícil. E se você possui um "Zabbix" muito grande, com um grande número de elementos de dados e uma alta frequência de coleta, isso facilita muito o trabalho.
Assim, depois de processarmos esses dados de alguma maneira usando o pré-processamento, salvamos no HistoryCache para processá-los ainda mais. Isso encerra a coleta de dados. Passamos ao processo principal.
Operação do sincronizador de histórico
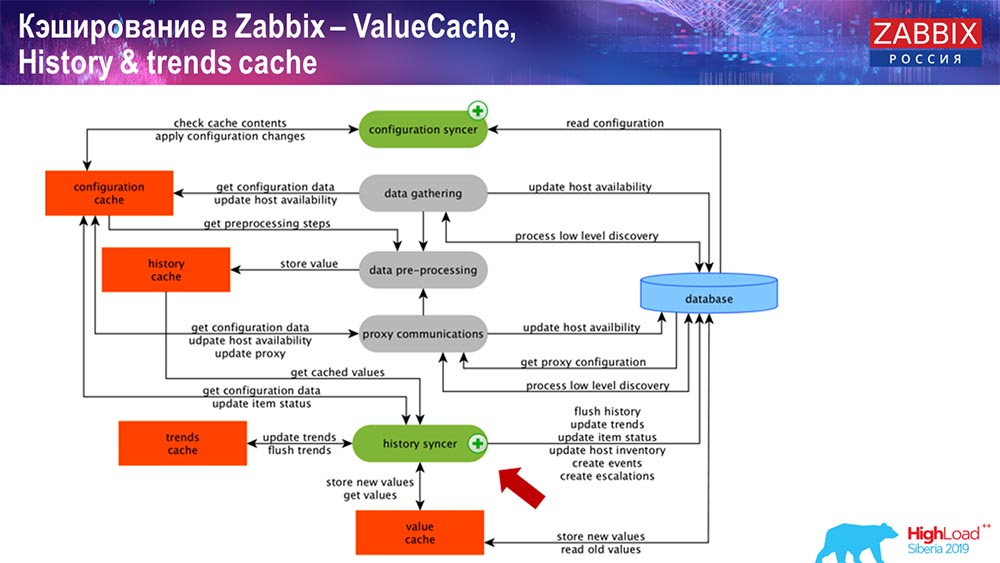
O principal processo no Zabbix (uma vez que é uma arquitetura monolítica) é o sincronizador de História. Este é o processo principal que lida especificamente com o processamento atômico de cada elemento de dados, ou seja, de cada valor:
- valor vem (é usado no HistoryCache);
- verifica no Configuration syncer: existem gatilhos para o cálculo? calcula-os;
se houver, ele cria eventos, cria uma escalação para criar um alerta, se necessário por configuração; - registra gatilhos para processamento subseqüente, agregação; se você agrega na última hora e assim por diante, esse valor lembra ValueCache, para não ir para a tabela de histórico; Assim, o ValueCache é preenchido com os dados necessários para o cálculo de gatilhos, elementos calculados, etc.
- o sincronizador de histórico grava todos os dados no banco de dados;
- o banco de dados os grava no disco - é aqui que o processo de processamento termina.
Bases de dados Armazenamento em cache
No lado do banco de dados, quando você deseja visualizar gráficos ou algum tipo de relatório de evento, existem vários caches. Mas, como parte deste relatório, não vou falar sobre eles.
Para o MySQL, existe o Innodb_buffer_pool, um monte de caches diferentes que também podem ser configurados.
Mas estes são os principais:
- shared_buffers;
- effective_cache_size;
- shared_pool.

Eu citei para todos os bancos de dados que existem certos caches que permitem manter na memória os dados que geralmente são necessários para consultas. Lá eles têm suas próprias tecnologias para isso.
Sobre o desempenho do banco de dados
Consequentemente, existe um ambiente competitivo, ou seja, o servidor Zabbix coleta dados e os registra. Ao reiniciar, ele também lê o histórico para preencher o ValueCache e assim por diante. Aqui você pode ter scripts e relatórios que usam a API do Zabbix, que é criada com base na interface da web. O "Zabbiks" -API é incluído no banco de dados e recebe os dados necessários para obter gráficos, relatórios ou alguma lista de eventos, problemas recentes.

Uma solução de visualização muito popular é o Grafana, usado por nossos usuários. Capaz de inserir diretamente através do "Zabbiks" -API e através do banco de dados. Ele também cria uma certa competição pela obtenção de dados: é necessário um ajuste melhor e mais preciso do banco de dados para corresponder à entrega rápida de resultados e testes.

Limpar histórico. Zabbix tem governanta
O terceiro desafio usado pelo Zabbix é esclarecer a história com a governanta. O Hauskiper está em conformidade com todas as configurações, ou seja, em nossos elementos de dados, é indicado quanto armazenar (em dias), quanto armazenar tendências, a dinâmica das mudanças.
Não falei sobre o TrendCache, que calculamos em tempo real: os dados chegam, agregamos em uma hora (basicamente esses são os números da última hora), a quantidade média / mínima e anotamos uma vez por hora na tabela de dinâmica de alterações (Trends) . O Hauskiper inicia e exclui dados do banco de dados usando seleções regulares, o que nem sempre é eficaz.
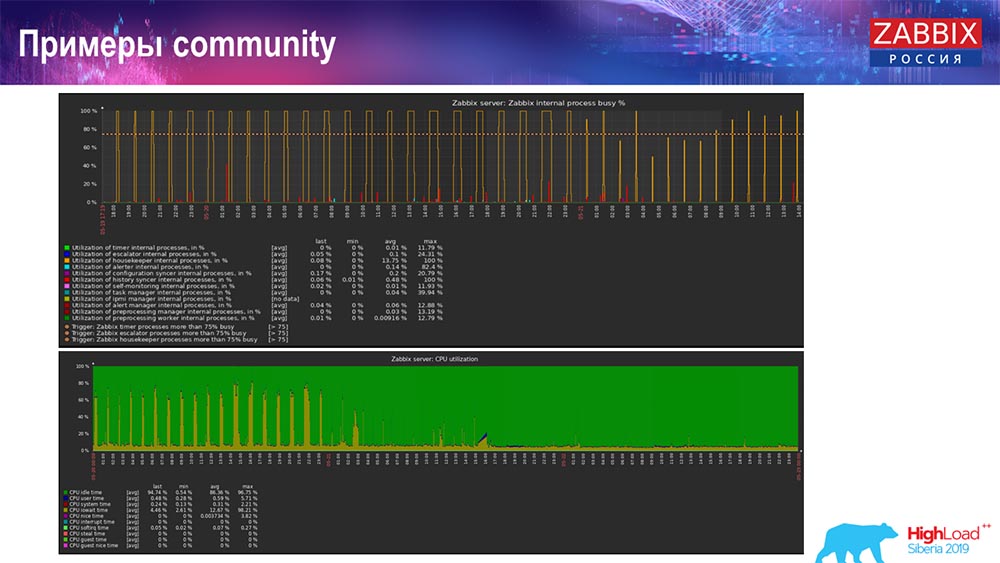
Como entender que é ineficiente? Você pode ver a figura a seguir nos gráficos de desempenho de processos internos:
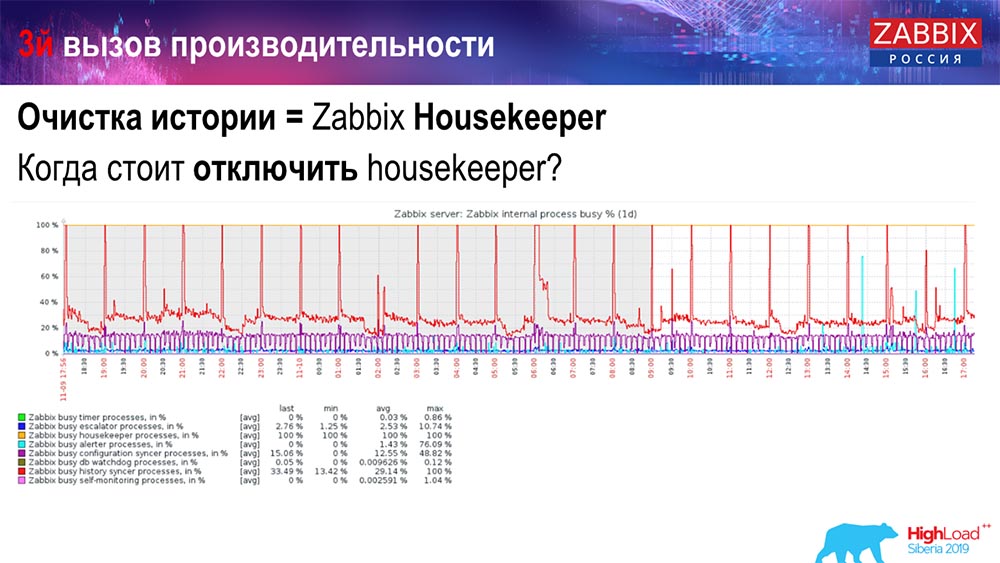
Seu sincronizador de histórico está constantemente ocupado (gráfico vermelho). E o gráfico "vermelho" que fica no topo. Este é o Hauskiper, que inicia e aguarda o banco de dados quando ele exclui todas as linhas especificadas.
Pegue um código de item: você precisa excluir os últimos 5 mil; Claro, por índices. Mas geralmente o conjunto de dados é grande o suficiente - o banco de dados ainda lê isso do disco e o eleva para o cache, e essa é uma operação muito cara para o banco de dados. Dependendo do tamanho, isso pode levar a certos problemas de desempenho.
Você pode desativar o Hauskiper de uma maneira simples - nós temos uma interface web familiar para todos. Definindo em Administração geral (configurações para "Governanta"), desabilitamos as tarefas domésticas internas para o histórico e as tendências internas. Assim, Hauskiper não controla mais isso:

O que posso fazer a seguir? Você desconectou, seus agendamentos subiram de nível ... Que problemas podem ser maiores nesse caso? O que pode ajudar?
Particionamento (particionamento)
Isso geralmente é configurado em todos os bancos de dados relacionais listados de uma maneira diferente. O MySQL possui sua própria tecnologia. Mas no geral eles são muito parecidos quando se trata de PostgreSQL 10 e MySQL. Obviamente, existem muitas diferenças internas em como tudo é implementado e como tudo isso afeta o desempenho. Mas, em geral, a criação de uma nova partição também costuma levar a certos problemas.

Dependendo da sua configuração (quantos dados você cria em um dia), eles geralmente definem o mínimo de 1 dia / partição e, para tendências, a dinâmica das alterações - 1 mês / nova partição. Isso pode mudar se você tiver uma configuração muito grande.
Digamos imediatamente sobre o tamanho da configuração: até 5 mil novos valores por segundo (os chamados nvps) - isso será considerado uma pequena "configuração". Média - de 5 a 25 mil valores por segundo. Tudo o que está acima já é instalações grandes e muito grandes que requerem uma configuração muito cuidadosa do próprio banco de dados.
Em instalações muito grandes, 1 dia - isso pode não ser o ideal. Eu pessoalmente vi no MySQL partições de 40 gigabytes por dia (e pode haver mais). Essa é uma quantidade muito grande de dados, que pode levar a alguns problemas. Precisa ser reduzido.
Por que particionar?
O que o particionamento fornece, acho que todo mundo sabe, é o particionamento de tabelas. Geralmente, esses são arquivos separados em solicitações de disco e extensão. Ele seleciona de maneira mais otimizada uma partição, se isso faz parte da partição usual.
Para o Zabbix, em particular, ele é usado por faixa, por faixa, ou seja, usamos um registro de data e hora (o número é comum, o horário desde o início da época). Você especifica o início do dia / fim do dia e esta é uma partição. Portanto, se você está solicitando dados há dois dias, tudo isso é selecionado no banco de dados mais rapidamente, porque você só precisa enviar um arquivo para o cache e emitir (em vez de uma tabela grande).

Muitos bancos de dados também aceleram a inserção (inserção em uma única tabela filho). Enquanto eu falo abstratamente, mas também é possível. Particionar muitas vezes ajuda.
Elasticsearch para NoSQL
Recentemente, na 3.4, implementamos uma solução para NoSQL. Adicionada a capacidade de escrever no Elasticsearch. Você pode escrever alguns tipos separados: escolha - escreva números ou alguns sinais; temos texto de string, você pode escrever logs no Elasticsearch ... Assim, a interface da web também acessará o Elasticsearch. Isso funciona bem em alguns casos, mas no momento pode ser usado.
TimescaleDB. Hypertables
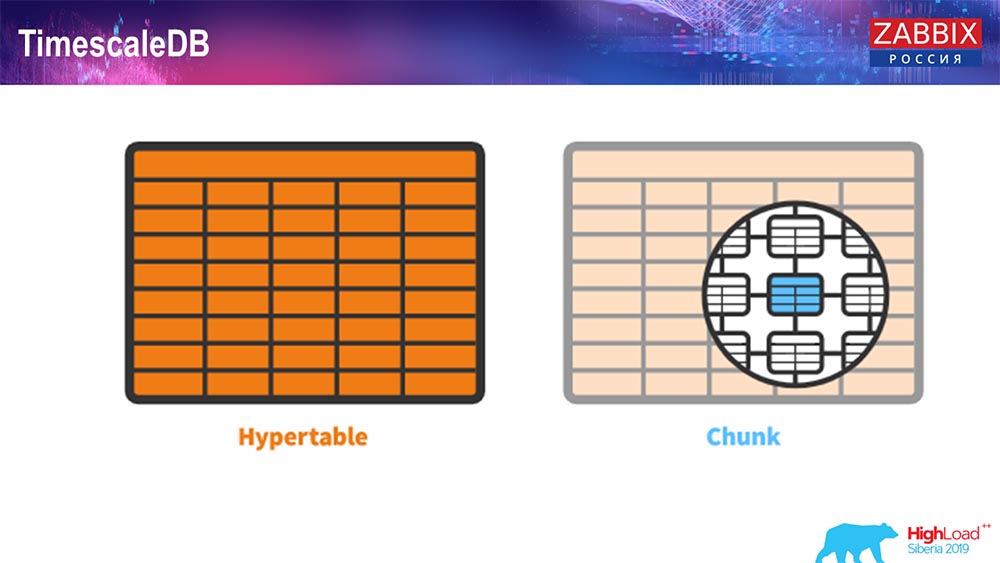
Para a 4.4.2, notamos uma coisa como o TimescaleDB. O que é isso Esta é uma extensão para o Postgres, ou seja, possui uma interface nativa do PostgreSQL. Além disso, esta extensão permite trabalhar com dados de séries temporais com muito mais eficiência e ter particionamento automático. Como é:

Isso é hipertabela - existe esse conceito na escala de tempo. Essa é a hipertabela que você cria e contém partes. Pedaços são partições, essas são tabelas filho, se não me engano. É realmente eficaz.
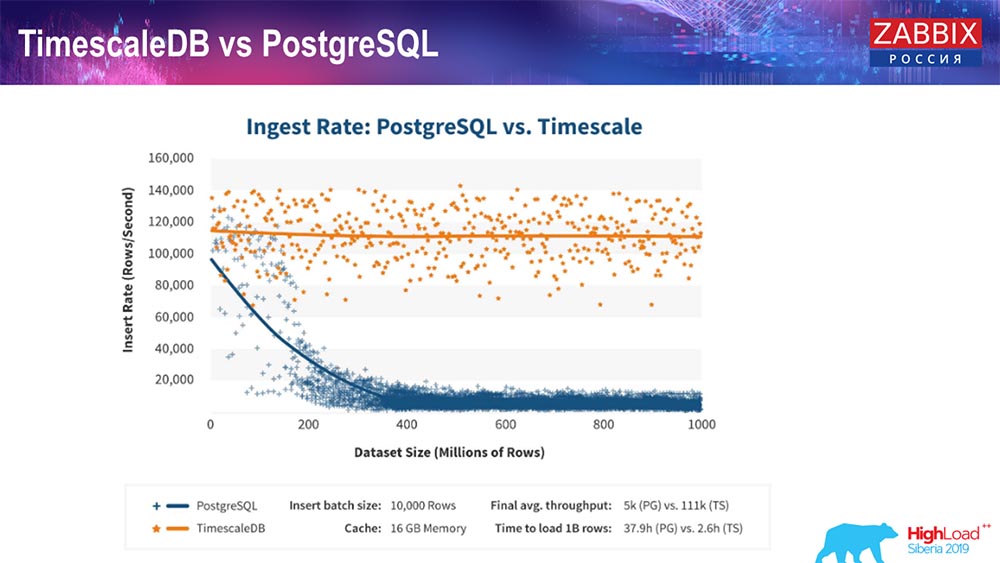
TimescaleDB e PostgreSQL
Como os fabricantes do TimescaleDB asseguram, eles usam um algoritmo de processamento de solicitação mais correto, em particular insert'ov, que permite que você tenha desempenho aproximadamente constante com um tamanho crescente da inserção do conjunto de dados. Ou seja, após 200 milhões de linhas do "Postgres", o normal começa a cair muito e perde o desempenho literalmente para zero, enquanto o "Timescale" permite inserir inserções da maneira mais eficiente possível com qualquer quantidade de dados.
Como instalar o TimescaleDB? Tudo é simples!
Ele está na documentação, está descrito - pode ser entregue a partir de pacotes para qualquer ... Depende dos pacotes oficiais do Postgres. Pode ser compilado manualmente. Aconteceu que eu tive que compilar para o banco de dados.
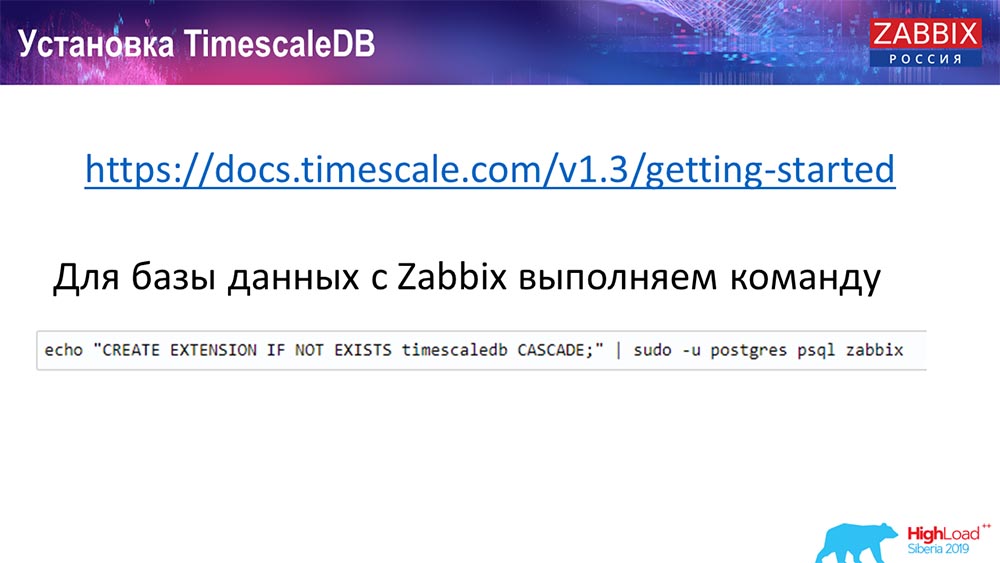
No Zabbix, apenas ativamos a extensão. Eu acho que aqueles que usaram o Extention no Postgres ... Você acabou de ativar o Extention, crie-o para o banco de dados do Zabbix que você usa.
E o último passo ...
TimescaleDB. Tabelas de histórico de migração
Você precisa criar uma hipertabela. Há uma função especial para isso - Criar hipertabela. Nele, o primeiro parâmetro indica a tabela necessária neste banco de dados (para a qual você precisa criar uma hipertabela).

O campo pelo qual você deseja criar e chunk_time_interval (este é o intervalo de chunks (partições a serem usadas). 86.400 é de um dia.
Parâmetro migrate_data: se você inserir true, isso transferirá todos os dados atuais para os pedaços criados anteriormente.
Eu mesmo usei migrate_data - leva uma quantidade decente de tempo, dependendo do tamanho do seu banco de dados. Eu tinha mais de um terabyte - a criação levou mais de uma hora. Em alguns casos, ao testar, excluí os dados históricos do texto (history_text) e da string (history_str), para não transferi-los - eles não eram realmente interessantes para mim.
E fazemos a última atualização em nossa db_extention: configuramos timescaledb para que o banco de dados e, em particular, nosso Zabbix entendam o que é db_extention. Ele o ativa e usa a sintaxe correta e as consultas ao banco de dados, usando os “recursos” necessários para o TimescaleDB.
Configuração do servidor
Eu usei dois servidores. O primeiro servidor é uma máquina virtual pequena o suficiente, 20 processadores, 16 gigabytes de RAM. Configure o Postgres 10.8:

O sistema operacional era o Debian, o sistema de arquivos era xfs. Fiz configurações mínimas para usar esse banco de dados específico, menos o que o Zabbix usará. Na mesma máquina, havia um servidor Zabbix, PostgreSQL e agentes de carregamento.

Usei 50 agentes ativos que usam o LoadableModule para gerar rapidamente vários resultados. Eles geraram linhas, números e assim por diante. Entupi o banco de dados com muitos dados. Inicialmente, a configuração continha 5 mil elementos de dados por host e aproximadamente cada elemento de dados continha um gatilho - para que fosse uma configuração real. Às vezes, é preciso até mais de um gatilho para usar.

Regulei o intervalo de atualização, a carga em si, para não apenas usar 50 agentes (adicionados mais), mas também usar elementos de dados dinâmicos e reduzir o intervalo de atualização para 4 segundos.
Teste de desempenho. PostgreSQL: 36 mil NVPs
O primeiro lançamento, a primeira configuração que tive no PostreSQL 10 puro neste hardware (35 mil valores por segundo). Em geral, como você pode ver na tela, a inserção de dados leva frações de segundo - tudo está bem e rápido, SSDs (200 gigabytes). A única coisa é que 20 GB são preenchidos rapidamente.
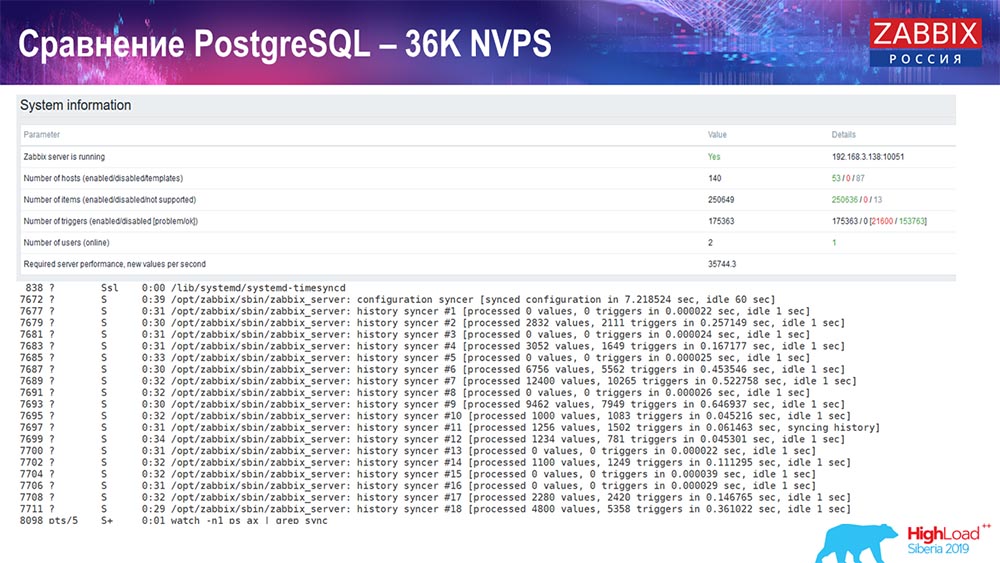
Haverá muitos mais desses gráficos. Este é o painel de desempenho padrão do servidor Zabbix.
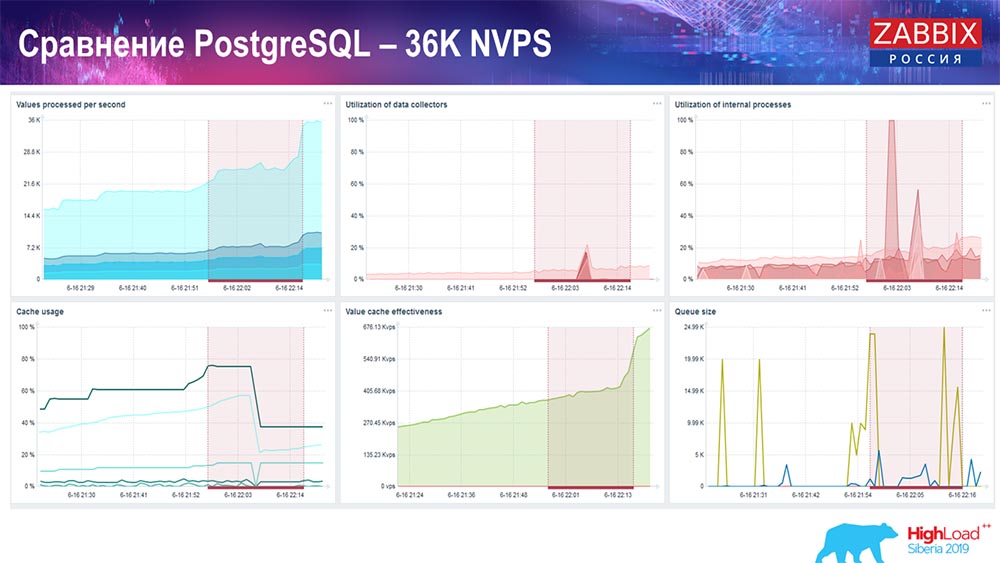
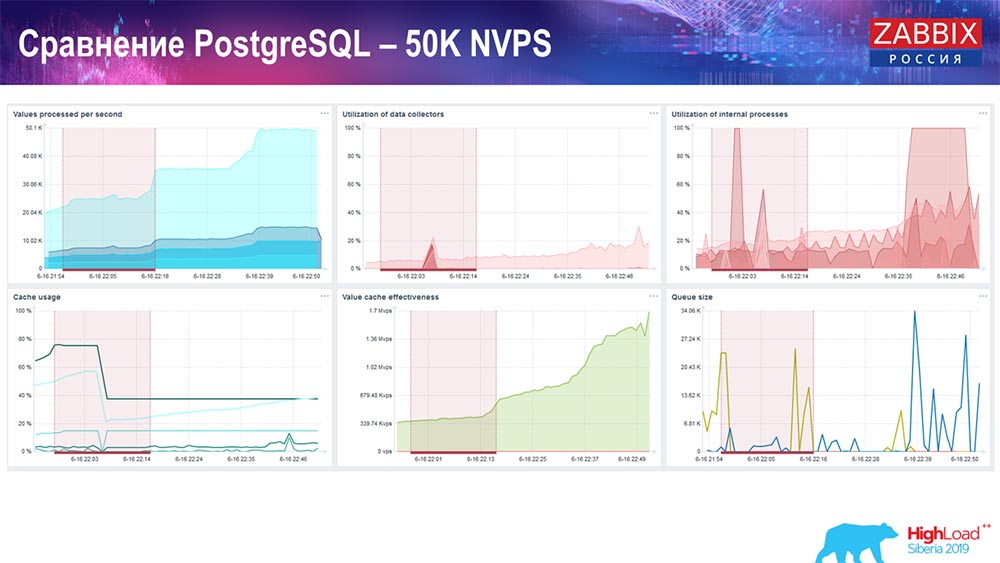
O primeiro gráfico é o número de valores por segundo (azul, canto superior esquerdo), 35 mil valores neste caso. Este (centro de carregamento) é o carregamento de processos de montagem e este (superior direito) é o carregamento de processos internos: sincronizadores de histórico e governanta, que estão em execução aqui há um tempo suficiente.
Este gráfico (parte inferior central) mostra o uso do ValueCache - quantas ocorrências do ValueCache para acionadores (vários milhares de valores por segundo). Outro gráfico importante é o quarto (canto inferior esquerdo), que mostra o uso do HistoryCache, sobre o qual eu falei, que é um buffer antes de inserir no banco de dados.
Teste de desempenho. PostgreSQL: 50 mil NVPs
Em seguida, aumentei a carga para 50 mil valores por segundo no mesmo hardware. Ao carregar com o Hauskiper, 10 mil valores já foram registrados em 2-3 segundos com o cálculo. Que, de fato, é mostrado na seguinte captura de tela:
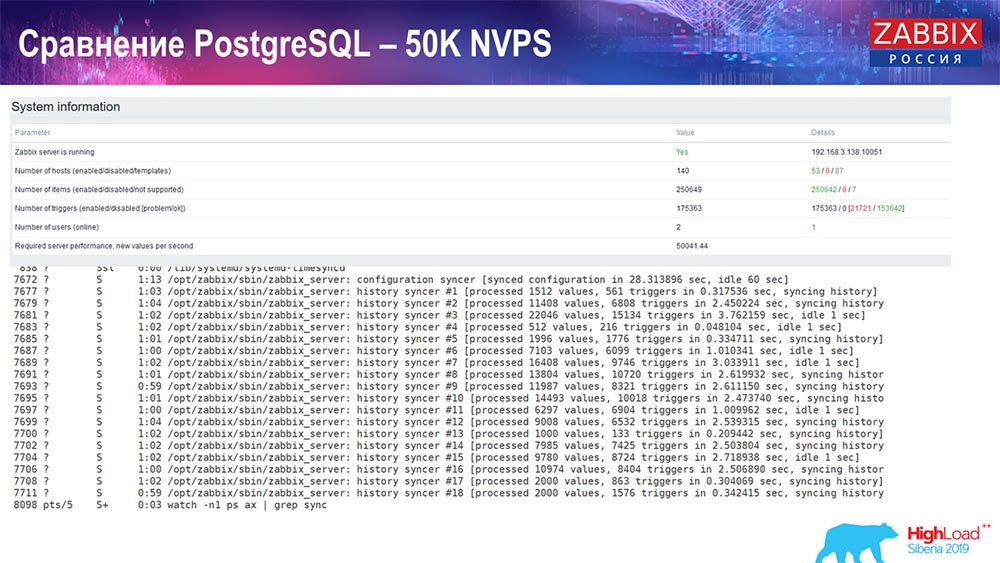
Hauskiper já está começando a interferir no trabalho, mas em geral o carregamento de caçadores de afundadores de história ainda está em 60% (terceiro gráfico, canto superior direito). O HistoryCache já durante o trabalho de "Hauskiper" começa a ser preenchido ativamente (canto inferior esquerdo). Era cerca de meio gigabyte, preenchido a 20%.
Teste de desempenho. PostgreSQL: 80 mil NVPs
Aumentou ainda mais para 80 mil valores por segundo:
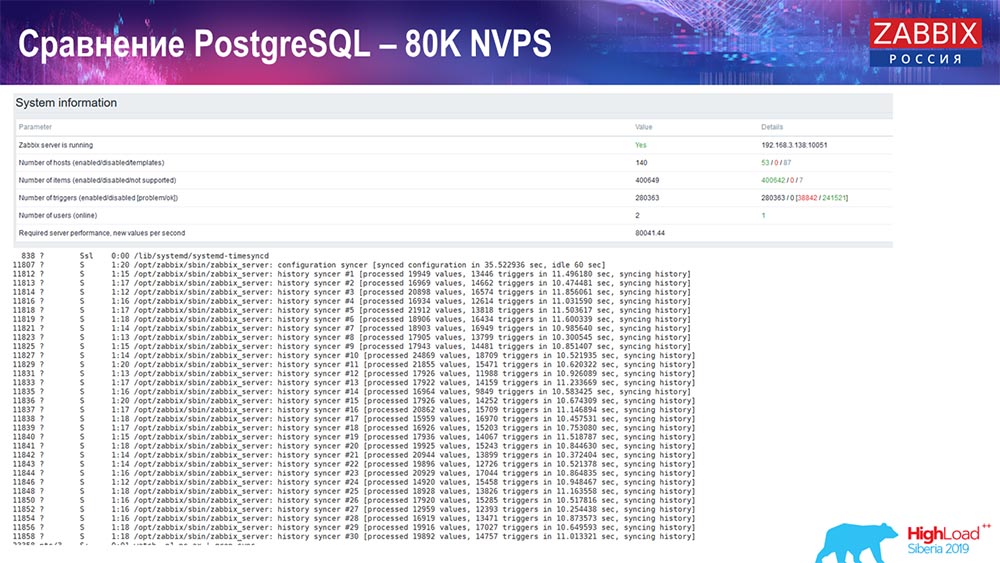
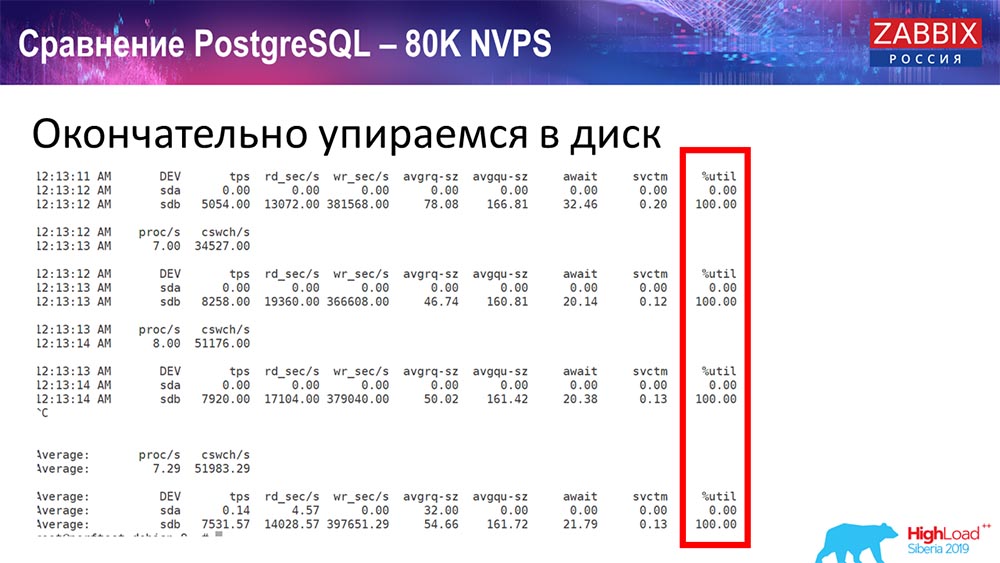
Foram aproximadamente 400 mil elementos de dados, 280 mil gatilhos. A inserção, como você pode ver, para o carregamento de chumbadas históricas (havia 30 delas) já era bastante alta. Além disso, aumentei vários parâmetros: histórico-afundadores, cache ... Nesse hardware, o carregamento dos afundadores de história começou a aumentar ao máximo, quase "até a prateleira" - de acordo com isso, o HistoryCache passou a uma carga muito alta:
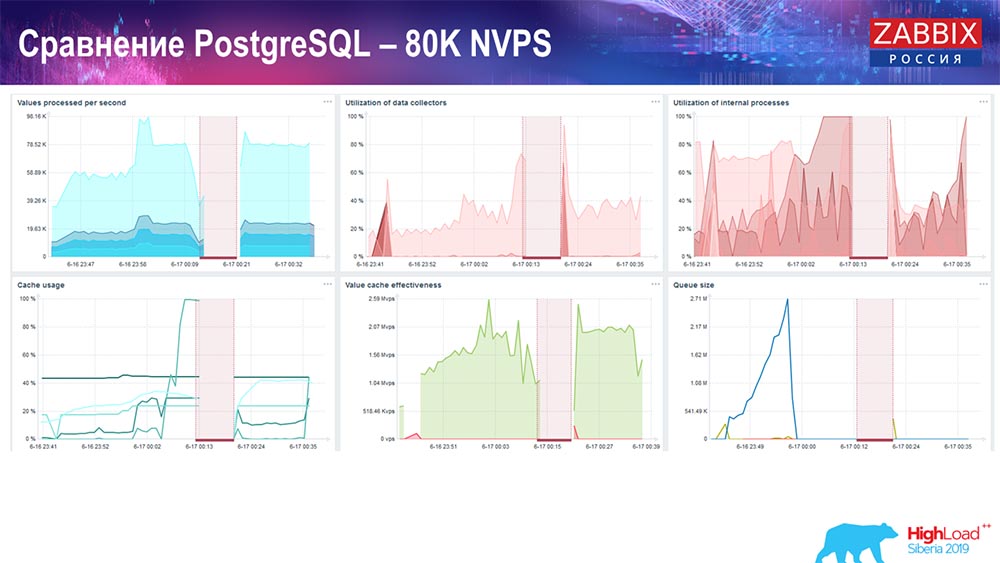
( , ) , – , . «» , , …
, 48 128 :
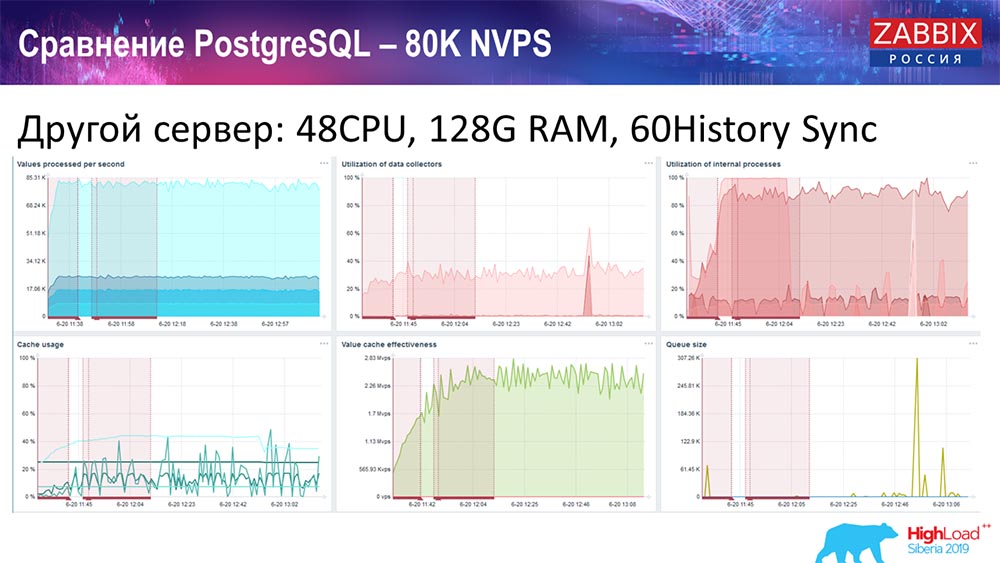
«» – History syncer (60 ) . « », , , , - .
. TimescaleDB: 80 NVPs
– TimescaleDB. :
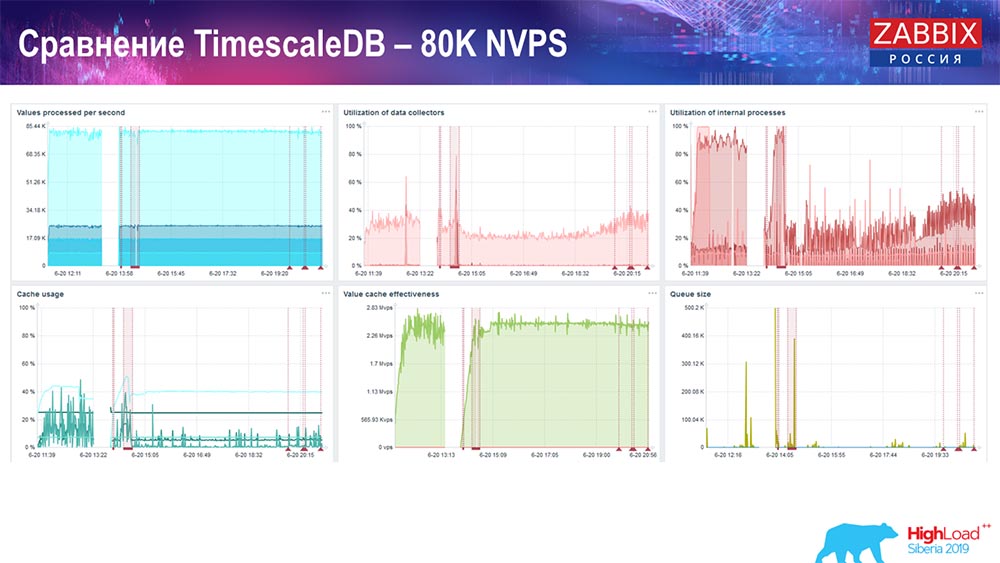
– . «»- -, , . 3 HistoryCache – , . , 80 – rate (, «»). setup, .
PostgreSQL: 120 NVPs
125 :

:
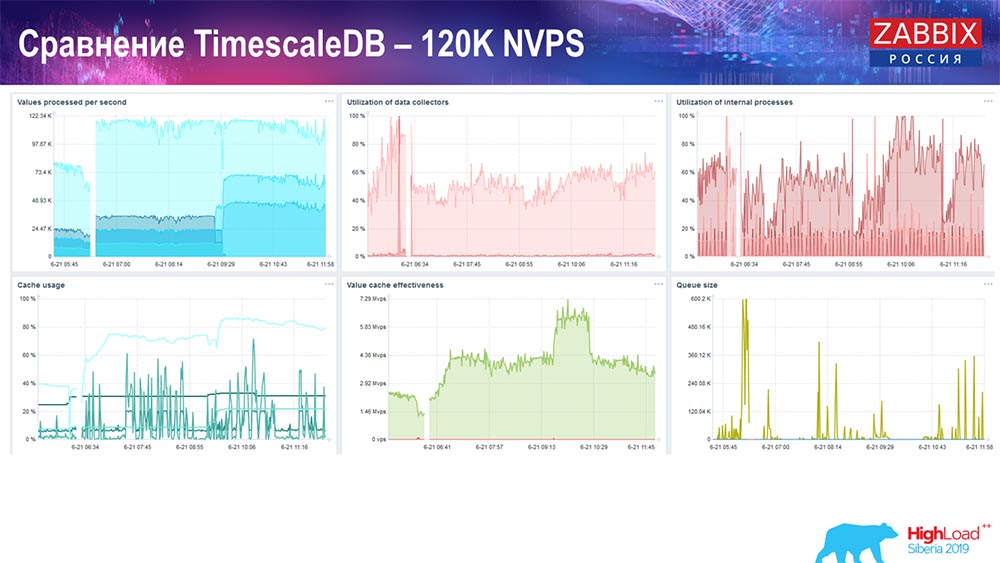
setup, . 1,5 , . , TimescaleDB, , MySQL.
, , . ! – TimescaleDB. : 120 .
«» :
TimescaleDB io.weight ; TimescaleDB. , ( SSD)!
- setup', , TimescaleDB, , . , .
: Conference – , Summit – . – «», , IRC. - – , .
( – ): – TimescaleDB , , , , «» «»? - , -, «», «», «» , ?
 :
: – , , : «» TimescaleDB. , , , «» . , ( TimescaleDB), , ! , , .
«»: - . , . setup'. MySQL… setup' .
: – , community, «»:
. «» TimescaleDB?
: – – . TimescaleDB , - . . .
: – – «».
( ): – , delete, – , , . «», , . , , big data: «!»
«» , . , select' , – « !» ( ). ! , .
: – SQL. , «» , – - . , , , , – Clickhouse, , - -?.. Kafka – ! - ?
: – . «» 3.4: , , ; - . . - , , «». , , , NoSQL- (, «») .
: – , , ?
: – , «» – , , . , - , , , .
: – , , «», ?
: – . , , , «» , . . : . – , – Grafana -.
: – , ?
: – , , .
: – RRD? SQL? RRD .
: – «Zabbix» RRD, , . SQL- – . – MySQL, PostgreSQL ( ). SQL RRD .

Um pouco de publicidade :)
Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando aos seus amigos
VPS baseado em nuvem para desenvolvedores a partir de US $ 4,99 , um
analógico exclusivo de servidores básicos que foi inventado por nós para você: Toda a verdade sobre o VPS (KVM) E5-2697 v3 (6 núcleos) 10GB DDR4 480GB SSD 1Gbps de 10GB de US $ 19 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
Dell R730xd 2 vezes mais barato no data center Equinix Tier IV em Amsterdã? Somente temos
2 TVs Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV a partir de US $ 199 na Holanda! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - a partir de US $ 99! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?