Com base na discussão no bate-papo da
comunidade AWS MinskRecentemente, batalhas reais foram travadas pela definição de DevOps e SRE.
Apesar de, em muitos aspectos, discussões sobre esse tópico já terem começado, inclusive eu, decidi levar ao tribunal a comunidade habr e minha opinião sobre esse assunto. Para aqueles que estão interessados, bem-vindo ao gato. E deixe tudo começar de novo!
Antecedentes
Portanto, nos tempos antigos, uma equipe separada de desenvolvedores de software e administradores de servidor vivia separadamente. O primeiro escreveu com sucesso o código, o segundo, usando várias palavras afetuosas e afetuosas endereçadas ao primeiro, configurou os servidores, periodicamente chegando aos desenvolvedores e recebendo em troca um exaustivo “tudo funciona na minha máquina”. Os negócios aguardavam o software, tudo estava ocioso, periodicamente falido, todo mundo estava nervoso. Especialmente quem pagou por toda essa bagunça. Era da lâmpada gloriosa. Bem, sim, você já sabe de onde as pernas do DevOps crescem.
Práticas de DevOps de nascimento
Então tios sérios vieram e disseram que isso não é uma indústria, é impossível trabalhar assim. E modelos de ciclo de vida arrastados. Por exemplo, um modelo em V.
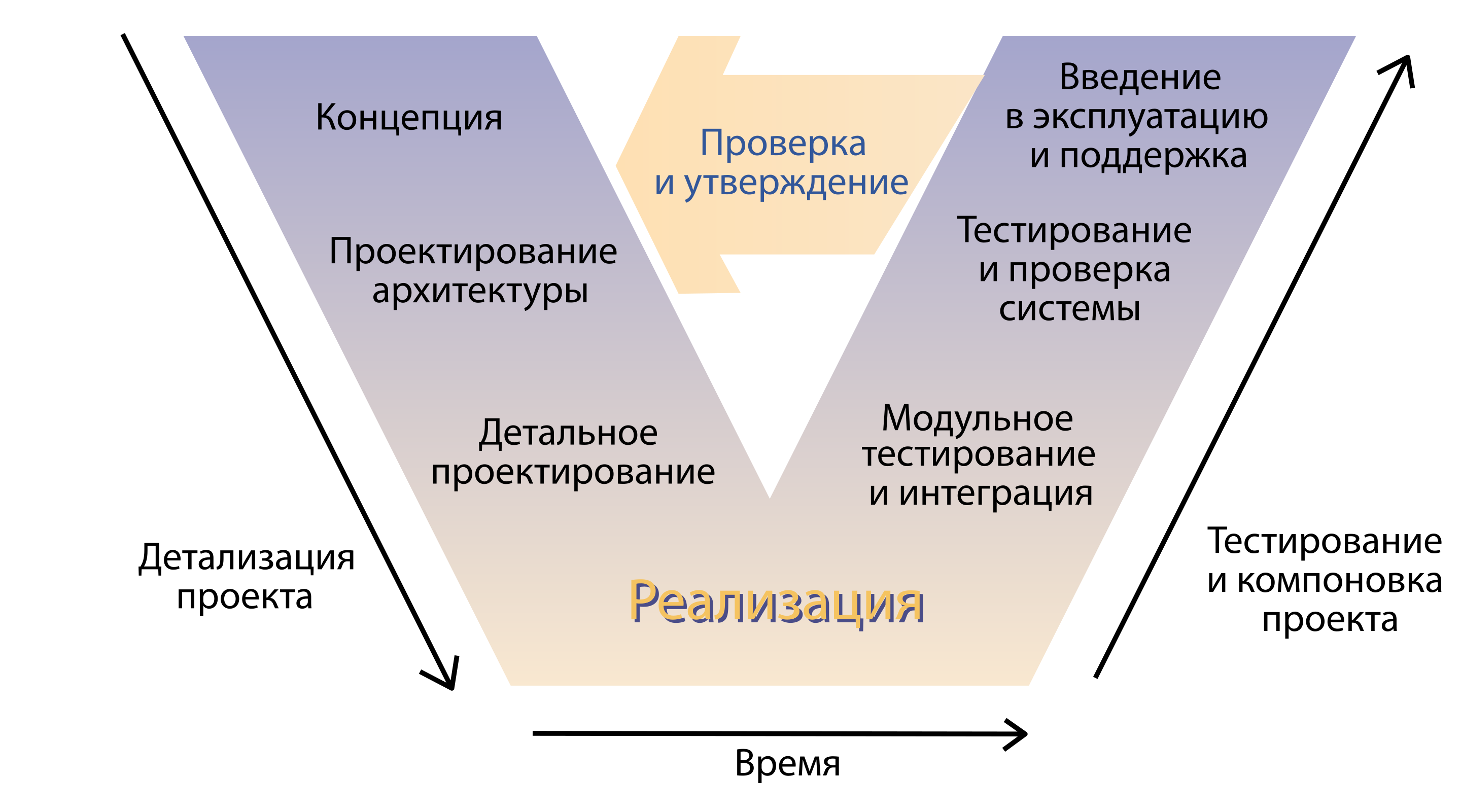
Então o que vemos? Os negócios vêm com um conceito, os arquitetos projetam soluções, os desenvolvedores escrevem o código e depois o fracasso. Alguém está testando o produto de alguma forma, alguém está entregando-o ao usuário final de alguma forma, e em algum lugar na saída desse modelo milagroso há um cliente comercial sozinho esperando o tempo prometido pelo mar. Chegamos à conclusão de que precisamos de métodos que permitam que esse processo seja estabelecido. E eles decidiram criar práticas que os implementariam.
Digressão lírica sobre o que é prática
Por prática, quero dizer um monte de tecnologia e disciplina. Um exemplo é a prática de descrever a infraestrutura com código de terraform. Disciplina é como descrever a infraestrutura com código, está na cabeça do desenvolvedor e a tecnologia é a própria terraform.
E eles decidiram chamá-los de práticas de DevOps - acho que eles queriam dizer de Desenvolvimento a Operações. Criamos diferentes coisas complicadas - práticas de CI / CD, práticas baseadas no princípio IaC, milhares delas. E tudo começou, os desenvolvedores escrevem o código, os engenheiros do DevOps transformam a descrição do sistema na forma de código em sistemas funcionais (sim, infelizmente, o código é apenas uma descrição, mas não a personificação do sistema), a entrega está girando e assim por diante. Os administradores de ontem, tendo dominado as novas práticas, orgulhosamente treinados novamente como engenheiros de DevOps, e tudo começou. E foi a tarde e a manhã ... desculpe, não de lá.
Tudo está de novo não graças a Deus
Assim que tudo se acalmou, e vários "metodologistas" astutos começaram a escrever livros pesados sobre as práticas do DevOps, as disputas começaram em silêncio, que é um engenheiro notório do DevOps e que o DevOps é uma cultura de produção, o descontentamento voltou a amadurecer. De repente, a entrega do software era uma tarefa absolutamente não trivial. Cada infra-estrutura de desenvolvimento tem sua própria pilha, você precisa coletá-la em algum lugar, implantar o ambiente em algum lugar, aqui você precisa do tomcat, ainda precisa de uma maneira complicada de iniciá-la - em geral, a cabeça está quebrando. E o problema, por incrível que pareça, acabou sendo principalmente na organização dos processos - essa função de entrega, como um gargalo, começou a bloquear processos. Além disso, a operação (Operações) não foi cancelada. Não é visível no modelo V e existe todo o ciclo de vida à direita. Como resultado, é necessário, de alguma forma, oferecer suporte à infraestrutura, observar o monitoramento, resolver incidentes e até lidar com a entrega. I.e. sentar-se com um pé, tanto no desenvolvimento quanto na operação - e, de repente, tais Operações e Desenvolvimento acabaram. E havia um hype enorme para microsserviços. E com eles, o desenvolvimento das máquinas locais começou a mudar para o Cloud - tente depurar algo localmente, se houver dezenas e centenas de microsserviços, aqui a entrega constante se torna um meio de sobrevivência. Para a "pequena empresa modesta", ainda não importava onde, mas ainda? E o Google?
Google SRE
O Google veio, comeu os maiores cactos e decidiu - não precisamos disso, precisamos de confiabilidade. E a confiabilidade deve ser gerenciada. E eu decidi - precisamos de especialistas que gerenciem a confiabilidade. Ele os chamou de engenheiros da SR e disse: aqui está você, faça-o como sempre, bem. Aqui você tem SLI, aqui você tem SLO, aqui você tem monitoramento. E cutucou o nariz nas operações. E chamou seu SRE de "DevOps confiável". Tudo parece estar bem, mas há um truque sujo que o Google poderia pagar - contratar pessoas que tinham habilidades de desenvolvedor e um
pouco mais de costura em casa, que conheciam o funcionamento dos sistemas de trabalho, como engenheiros de SR. Além disso, contratar pessoas e o próprio Google tem problemas - principalmente porque aqui compete com ele - é necessário descrever a lógica de negócios para alguém. A entrega foi interrompida pelos engenheiros de lançamento, SR - os engenheiros gerenciam a confiabilidade (é claro, não diretamente, mas influenciam a infraestrutura, alterando a arquitetura, rastreando alterações e indicadores, lidando com incidentes). Bom, você pode
escrever livros . Mas e se você não for o Google, mas a confiabilidade ainda preocupa de alguma forma?
Desenvolvendo idéias de DevOps
Chegou a tempo de o Docker, que cresceu do lxc, e vários sistemas de orquestração, como o Docker Swarm e o Kubernetes, e os engenheiros do DevOps expiraram - a unificação de práticas simplificou a entrega. Simplificado a tal ponto que se tornou possível até entregar aos desenvolvedores - que deployment.yaml está lá. A conteinerização resolve o problema. E a maturidade dos sistemas de CI / CD já está escrita no nível de um arquivo e tudo começou - os desenvolvedores farão eles mesmos. E então começamos a conversar sobre como podemos fazer nossa SRE, com ... sim, pelo menos com alguém.
SRE não no Google
Bem, ok, entregamos a entrega, parecemos expirar, voltamos aos bons velhos tempos, quando os administradores assistiam o processador carregar, sintonizavam os sistemas e bebiam silenciosamente algo incompreensível das canecas em paz e tranquilidade ... Pare. Não fizemos nada por isso (desculpe!). De repente, acontece que, na abordagem do Google, podemos adotar excelentes práticas - não é a carga do processador que importa, e não com que frequência mudamos de disco lá ou na nuvem otimizamos o custo, e as métricas de negócios são a mesma notória SLx. E ninguém tirou o gerenciamento de infraestrutura deles, e é necessário resolver incidentes, estar em serviço periodicamente e, em geral, estar no assunto de processos de negócios. E pessoal, já começam a programar um pouco em um bom nível, o Google está esperando por você.
Em resumo. De repente, mas você já está cansado de ler e está ansioso para
cuspir escrever ao autor no comentário ao artigo. O DevOps como uma prática de entrega, foi e será. E não vai a lugar nenhum. O SRE como um conjunto de práticas operacionais torna essa entrega bem-sucedida.