O Zabbix é um sistema popular de monitoramento aberto usado por um grande número de empresas. Vou falar sobre a experiência de criar um cluster de monitoramento.
No relatório, mencionei brevemente as alterações feitas anteriormente (patches), que expandem significativamente os recursos do sistema e preparam a base para o cluster (upload de histórico para “Clickhouse”, pesquisa assíncrona). E analisarei em detalhes os problemas que surgiram durante o clustering do sistema - resolvendo conflitos de identidade no banco de dados, um pouco sobre o teorema do CAP e monitoramento com bancos de dados distribuídos, sobre as nuances do Zabbix trabalhando no modo de cluster: backup e coordenação de servidores e proxies, sobre "domínios de monitoramento" e uma nova aparência na arquitetura do sistema.
Falarei brevemente sobre como iniciar um cluster em casa, onde obter as fontes e quais outras. serão necessárias configurações para o cluster.

HighLoad ++ Siberia 2019. Tomsk Hall. 24 de junho, 17h Resumos e
apresentação . A próxima conferência HighLoad ++ será realizada nos dias 6 e 7 de abril de 2020 em São Petersburgo. Detalhes e ingressos
aqui .
Mikhaili Makurov (a seguir - MM): - Trabalho para uma empresa prestadora. O fornecedor é chamado Intersvyaz, funciona na cidade de Chelyabinsk. Temos aproximadamente 1,5 milhão de pessoas. E para que o provedor funcione, existe uma enorme infraestrutura. Temos cerca de 70 mil equipamentos: comutadores, dispositivos IoT ... - muito de tudo que precisa ser monitorado. Especificamente, este relatório é sobre o uso do Zabbix, sobre a criação de um cluster baseado no Zabbix para monitoramento de infraestrutura.
Eu tenho 12 anos no provedor. Agora, não estou fazendo nada técnico, trata-se mais de gerenciar pessoas. E esse (material técnico) é realmente o meu hobby. Vou desenvolver este tópico um pouco.
Problemas de monitoramento
Eu acho que tenho sorte. Cerca de um ano e meio atrás, eu terminei em um projeto que soava assim: "Precisamos resolver alguns problemas com nosso monitoramento". Eu herdei uma zona de responsabilidade (monitoramento), que consistia em vários servidores, especificamente em 21 servidores:

Havia 4 servidores poderosos e 15 proxies - era tudo hardware. Houve algumas reclamações sobre esse monitoramento. A primeira é que foi muito. Não temos um único servidor com o provedor que ocupa muito espaço. Isso é dinheiro, eletricidade ... De fato, isso não é um grande problema.

O grande problema era que o monitoramento não acompanhava o quanto queríamos dele. Para aqueles que não usaram o Zabbix ativamente, este é um painel que mostra atraso nas verificações:

A maioria dos nossos cheques estava na zona vermelha. Eles correram mais de 10 minutos mais devagar do que queríamos, ou seja, estavam 10 minutos atrasados. Não era muito agradável, mas ainda era possível viver mais ou menos. O maior problema foi este:

Era um sistema de monitoramento de uma rede em funcionamento. Quando o trabalho planejado foi realizado, um segmento de milhares caiu em cinco interruptores. Juntamente com esses comutadores, o comutador e o monitoramento foram esquecidos. Quando tudo foi restaurado, duas horas depois e o monitoramento foi restaurado. Foi dolorosamente desagradável, e essa frase deve constar em todos os relatórios:

"Nós devemos fazer algo com este projeto!"
E aqui vou contar duas histórias. Então tentamos ir simultaneamente de duas maneiras. Temos um grupo de integração - ele escolheu a maneira de construir um sistema modular (houve um relatório muito interessante do Avito para o Highload em novembro do ano passado em Moscou - eles conversaram sobre isso):

Zabbix = pessoas + API + eficiência
Os caras de pequenos pedaços começaram a construir um sistema. E com vários entusiastas, continuei trabalhando no Zabbix. Havia razões para isso. Quais são as razões?
- Em primeiro lugar, há uma API legal. E quando você tem de 60 a 70 mil elementos de monitoramento, fica claro que tudo isso funciona apenas automaticamente - você não pode adicionar tantas mãos sem erros.
- Pessoal. Existem turnos de monitoramento de plantão 24 horas por dia, 7 dias por semana. Estes não são especialistas em TI, são pessoas de plantão. Mostramos ao "Grafan" alguns outros sistemas - é difícil para eles. Existem administradores acostumados à diversidade, à conveniência de monitorar no próprio Zabbix: modelos, detecção automática - e isso é legal!
- O Zabbix pode ser eficaz.
O banco de dados SQL fica mais lento? Uma resposta - Clickhouse
A primeira razão era óbvia. Em seguida, trabalhamos no MySQL e encontramos cerca de 6 a 7 mil métricas por segundo, observamos atrasos constantes nos discos.

Hoje já soou 100 vezes: a única resposta é Clickhouse:
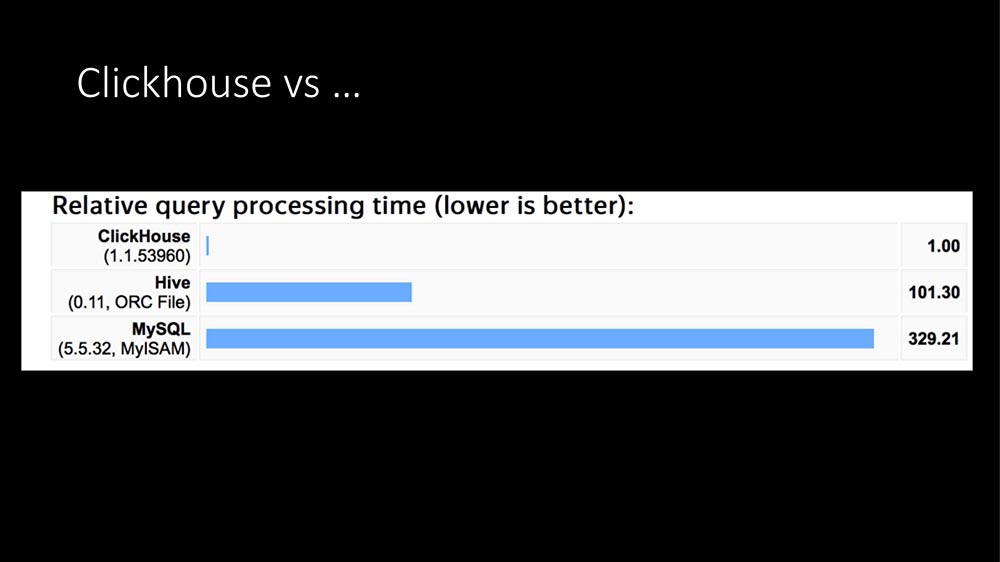
Na estrutura das consultas, a maior parte das consultas (nosso perfil em poucas horas) são registros de métricas. Gravar métricas em um banco de dados SQL é extremamente caro. Aqui o TimeScaleDB apareceu ... Então, tivemos um "Clickhouse" em operação por cerca de um ano para outras tarefas (fazemos grandes dados, temos um grande aplicativo - em geral, um provedor agora é um negócio de TI completo).
Depois de analisar belos gráficos da Internet (que o “Clickhouse” é centenas de vezes mais rápido, que precisa de muito pouco espaço) e com a experiência atual, escrevemos nosso módulo HistoryStorage para o “Zabbix” para que ele possa salvar os dados do “Clickhouse” diretamente (ou seja, não da exportação de arquivos, mas diretamente).

Além disso, escrevemos um módulo para a "frente". Todos esses belos gráficos no painel de administração do Zabbix podem ser criados a partir da Clickhouse. É claro que a API também funciona.
O efeito é aproximadamente o mesmo - o servidor SQL como uma entidade dedicada não se tornou completamente, ou seja, a carga caiu para zero. O mais notável é que já tínhamos um cluster dedicado “Clickhouse”: quando demos toda a nossa carga lá, ela aumentou de 6 para 10 mil métricas. Os funcionários que administram disseram: "Mas não vemos algo que chegou. Não!
Como expandimos a Clickhouse
Vou dizer ainda mais: para testes, tentamos carregar de 140 a 150 mil métricas por segundo (não conseguimos mais extrair do Zabbix, depois vou dizer o porquê), e o Clickhouse também não vê essa carga. Ou seja, é muito confortável, carga legal. Em geral, existe esse módulo.
Além disso, expandimos um pouco:

Em nossa versão, você pode desativar os nanossegundos. Você provavelmente sabe: o Zabbix grava segundos e nanossegundos em dois campos. Nos campos "Clickhouse" nos quais a variabilidade é muito grande, ocupe muito espaço.
A propósito, sobre o lugar. Uma métrica no Clickhouse (agora temos aproximadamente 700 bilhões de métricas registradas) ocupa 2,9 bytes. De acordo com a documentação do Zabbix, uma métrica nos bancos de dados SQL leva de 40 a 100 bytes. Desativar os nanossegundos economiza outros 40%, ou seja, cerca de 1,5 bytes por métrica. Ou seja, "Clickhouse" é muito eficaz em termos de localização.
A pedido de nossos funcionários envolvidos no aprendizado de máquina, optamos por escrever o host e o nome da métrica. Como a variabilidade dos dados é grande, isso não ocupa muito espaço adicional, apesar de os dados de texto poderem ser significativos (ainda não foram verificados com testes longos).
Além disso, fizemos duas adições, pois desenvolvemos o Zabbix e muitas vezes tivemos que removê-lo. Uma adição muito interessante: no início, como o “Clickhouse” permite a leitura de milhões de registros, podemos preencher o cache do histórico. No início, estamos atrasados por 30 a 40 segundos extras, mas obtemos um serviço iniciado imediatamente com um cache aquecido.
Nos casos em que é mais fácil coletar da infraestrutura, ainda existe uma opção: proibir a leitura do cache por algum tempo. É melhor trabalhar rapidamente por 5 minutos, sem contar os gatilhos, e o cache será preenchido. Se você não fizer isso, a estagnação dos afundadores de história começa.
Em geral, existe um módulo "Clickhouse". Pode ser usado.
Eficiência de sondagem
Apesar de termos resolvido os problemas com a base, os freios e o problema com quinze proxies ainda permaneciam. Eles estavam conectados com isso:

Este é o principal pipeline de processamento de dados no Zabbix. Há um estágio de coleta de dados, há pré-processamento e sincronizadores históricos que fazem todo o trabalho (cálculo de gatilhos, alertas, salvamento de histórico). O gargalo do cache acabou por ser:

Por que a pesquisa é lenta? Porque os encadeamentos que fazem os pedidos vão para a fila na configuração de cache para métricas de unidade e bloqueiam. Existem outros lugares, mas eles não são tão estreitos. Por exemplo, existe um pré-processamento em si e um cache de histórico. Em nosso SQL, recebemos as seguintes restrições:

Talvez isso se deva ao fato de que, no nosso caso, a base é de aproximadamente 5 milhões de métricas, que removemos. Com todas as otimizações que fizemos, conseguimos obter 70 mil métricas no gargalo (no cache de configuração), mas apenas no caso em que as processamos em massa.
O que é processamento em massa? O Poller acessa o cache de configuração e executa a tarefa não por uma métrica, mas por 4 ou 8 mil. Ao mesmo tempo, ele tem outra oportunidade maravilhosa: agora ele pode fazer pesquisas de forma assíncrona, porque ele tem 4 mil métricas ... Por que eles fazem um após o outro? Você pode perguntar tudo imediatamente!
A pesquisa assíncrona é mais eficiente que o proxy!
Para os principais tipos usados pelo provedor - SNMP e AGENT, reescrevemos a sondagem para o modo assíncrono e, agregadamente, isso aumentou a velocidade de 100 para 200 vezes. Tínhamos 15 proxies, os dividíamos em 150 - eles haviam desaparecido completamente. Como resultado, tudo se transformou em dois bancos, necessários apenas para a reserva:

Banco uniprocessador (um custo Xeon 1280). Este é o meu tempo:

Cerca de 60% é gratuito, mas esse toque de 60% a 40% é executado scripts periódicos na própria máquina (scripts externos). Eles podem ser otimizados até que os problemas sejam criados.
Escala é algo como isto:

São 62 mil hosts, cerca de 5 milhões de métricas. Nossa necessidade atual é de aproximadamente 20 mil métricas por segundo.
Bem, como tudo? Resolvemos os problemas de desempenho, o histórico expandido, a pesquisa é incrível. O problema foi resolvido? Na verdade não ... Tudo seria muito simples.
Eu joguei um truque no gráfico anterior (nem todos mostrados):

Existem dois problemas. Eu quero dizer: "Tolos, estradas". Há um fator humano, há equipamentos.
Um servidor ainda não é suficiente. Em cerca de um ano de operação, houve dois casos com problemas de hardware - uma unidade SSD e outra coisa. A maioria dos problemas é o fator humano quando as pessoas fazem algum tipo de teste. Em nossa empresa, o Zabbix é usado como um serviço: todos os departamentos podem escrever algo próprio lá.
Eu gostaria de expandir. Eu gostaria de não depender de uma lata. Eu queria que pudéssemos ficar ainda mais fortes. E eu gostaria de expandir de acordo com o princípio de expansão. Não há nada a discutir aqui: crescer, aumentar a capacidade de uma lata, é irrelevante há 20 anos.

O cluster solicitou ...
Em algum lugar de dezembro, a primeira versão apareceu. Uma unidade de cluster atômica é o que é processado em um host separado. O host foi selecionado.

O fato é que no Zabbix existem conexões bastante fortes entre itens que podem estar no mesmo host, ou seja, os gatilhos podem ser conectados, eles podem ser processados juntos no pré-processamento. Porém, entre os hosts, a conectividade não é tão alta; portanto, é normal usar esse cluster entre os nós do cluster - haverá muito tráfego lá. A principal tarefa dos clusters é concordar entre si quem está envolvido em quais hosts.
Eu gostaria de contornar nosso limite máximo de 60 a 70 mil métricas, porque o apetite vem da comida. Temos pessoas envolvidas em QoE ... Qualidade da experiência - uma análise de como a Internet funciona para assinantes com base em métricas de trânsito, ou seja, você fornece todas as métricas de TCP a 1,5 milhão de pessoas, despejando-as no monitoramento - há muitos dados.
E eu queria confiabilidade. Eu queria que algo acontecesse ... O funcionário de plantão ligou e disse: "Temos problemas com o servidor", desligou-o e resolveremos amanhã.
Primeiro cluster
A primeira versão foi implementada com base no etcd:

Etcd é um armazenamento de valor-chave distribuído usado em muitos projetos progressivos (tanto quanto eu entendo, no Kubernetes). Tudo foi ótimo. O Etcd fornece ferramentas muito interessantes - por exemplo, resolve o problema de escolher o servidor principal. Mas esse problema ...
Tínhamos um "Zabbix" clássico de três links: "web" - a base - o próprio servidor. E adicionamos "Clickhouse" lá, e agora adicionamos o etcd também. Os administradores começaram a se esquivar: existem muitas dependências aqui - provavelmente não será confiável. No processo de desenvolvimento, mais uma coisa ficou clara: no próprio Zabbix já existe uma maneira interna de comunicação entre servidores, é usada apenas entre o servidor e o proxy, o chamado processo de pesquisa de proxy:

É muito legal para comunicação entre servidores com alterações mínimas. Isso permitiu que o etcd não usasse (pelo menos temporariamente), simplificasse bastante o código e, o mais importante, trabalhasse no código que foi verificado (parece que há 5 ou 7 anos nesse código).
Como os servidores são coordenados em um cluster?
A coordenação é feita por tipo, como o protocolo IGP. Para que os servidores tenham prioridade (agora vou dizer por que isso é necessário) e para evitar conflitos no banco de dados SQL ao gravar logs, cada servidor recebe um identificador (até agora manualmente) - este é um número de 0 a 63 (63 - é apenas uma constante, talvez mais):

O servidor com o identificador máximo se torna o "mestre". Quando lançamos nossos primeiros clusters de teste, a primeira coisa que nossos administradores disseram foi: “Uau! E vamos colocá-los em sites diferentes. Bem, ótimo! ”(Voltaremos a isso). E quando alguém distribuir clusters, será possível controlar como a topologia é redistribuída: para onde será a função do "mestre" em caso de queda no servidor "Zabbix" principal:

Nesse caso, assim:

Pisar
No Zabbix original, isso é feito da seguinte maneira: o próprio servidor é responsável por gerar índices de incremento automático. Para impedir que muitas instâncias pisem umas nas outras (para não criar logs com os mesmos índices), é usada a etapa: "Zabbix" com o identificador "1" gerará múltiplos de um - 1, 11, 21; com o identificador "7" - 7, 17, 27 (com nuances).
Dirigimos com modificadores.

Como os servidores interagem entre si?
Esse é o legado dos Hello Packets do IGP a cada 5 segundos. Portanto, os servidores sabem que têm vizinhos. Portanto, o "mestre" sabe que há vizinhos por perto e, com base nisso, o "mestre" decide quais hosts podem ser distribuídos para quais servidores.

Por conseguinte, existe uma configuração. De acordo com a memória antiga, eu chamo de topologia. Uma topologia é essencialmente uma lista de servidores e hosts que pertencem a eles.
O protocolo é simples - este é JSON:

Este também é o legado do proxy Zabbix e da comunicação do servidor Zabbix. Em geral, não faz sentido usar outra coisa. A única coisa é que, no caso do Zabbix, existem 4 bytes (ZBXD), mas esse não é o ponto.
No pacote hello, o identificador do servidor é transmitido: quando o servidor envia o pacote, ele diz seu identificador e sua versão da topologia - dessa forma, os servidores descobrem rapidamente que há uma nova versão da topologia e são atualizados rapidamente.
Na verdade, a topologia em si é apenas uma árvore, uma lista de servidores. Para cada servidor, uma lista de hosts suportados:

E então surge um problema interessante.
Existe uma frase tão mágica - monitorar domínios
Qual é o objetivo? No Zabbix clássico, tudo era simples - uma atitude inequívoca: esse host é monitorado por esse proxy, esse proxy fornece dados ao servidor. Se o proxy não foi instalado (ou não é necessário), esse servidor monitora todos os hosts:

Quando temos muitos servidores, o que fazer? Além disso, pode haver um problema com o fato de termos servidores distribuídos geograficamente, e o servidor em um escritório que trabalha lentamente em Kemerovo começará a tentar monitorar toda a infraestrutura de Novosibirsk.

Nós não queremos isso. Queremos ter algum tipo de mecanismo para que nem todos os servidores, mas os que selecionamos (possivelmente com base na geografia), possam monitorar um host específico. Ao mesmo tempo, queremos gerenciar isso e queremos que seja simples. Para isso, a idéia de monitorar domínios foi inventada. Na verdade, esses são grupos simples - simplesmente já existem grupos no registro.
E quando eu fiz isso, os caras da operação conversaram comigo - disseram: “Os grupos nos confundem muito. Sempre começamos a pensar em grupos normais. ” Portanto, este nome: monitorando domínios.
Os hosts se relacionam sem ambiguidade: um host - um domínio:

O domínio do host pode incluir qualquer número de servidores. Os servidores podem estar em qualquer número de domínios. Isso é uma coisa muito flexível. Para expandir a flexibilidade e quebrar completamente o cérebro, há também um domínio padrão:

Os servidores que são membros do domínio padrão são monitorados por todos os hosts que não possuem servidores ativos ou que não possuem um domínio de monitoramento.
Isso apenas nos permite vincular topologicamente os hosts a alguns servidores e controlar como os hosts são distribuídos no caso de um servidor cair:

O próximo problema que encontramos ...
Cluster: pense diferente
Quando temos muitos servidores, há novas oportunidades para construir um cluster, para construir uma topologia. Esse é um clássico quando temos algum tipo de site central e há sites remotos; ou, digamos, um proxy onde a carga é delegada:

No caso do cluster Zabbix, ele pode ser implementado de duas maneiras. Você pode seguir o caminho clássico: apenas o dobro da infraestrutura. No centro, temos dois servidores que formam um cluster, podem reorganizar os hosts ou se responsabilizarem se o vizinho cair. Assim, você pode criar proxies adicionais nos mesmos servidores - temos uma reserva dupla:

Você pode usar os novos "recursos" e fazer o seguinte:

O principal não é ir para uma situação em que um servidor geograficamente remoto esteja monitorando alguma infraestrutura grande em outro local. Este é mais um problema de administração (eu chamo de negócio) porque é um problema de configuração.
Cluster: cérebro dividido e ponto de vista
, :
- split brain;
- point of view ( ).
. Split brain – , . , - – ? , , ( ).
point of view : , , , . . , RTT , .
:

, . , , . , – . , , , .
SQL-
, , , . . , , … . .
-, , , - – . , Galera MySQL.
PostgreSQL. «» : , , – . «», , .
?
, :


– . :
- - (Logs), . problems, events events recovery. , – , .
- 15 (State). – ( – – «» ). . , ; – …
- - (Configuration update).
«. «», SQL-:

-, :

. -, , … – , 2 ! : « , ». - , , .
. , :

, . SQL- . , SQL-. ( - ), «» ( ). …
.
, , «» . . , ?

«»- (. . «» daemon). ( ): ( 1 63, «») ( , ).
ServerIP IP-. , , IP- . - , proxy poller, trapper hello-, proxy poller .
. , , « »:

:

, default. . – , IP-, , ( ). «» – default.
-, .
- .
- , : « , ». .
- - , .
- , hello-time, : « »; .
- .
, , , . 30-40 . , , , .
, . - : « , !» -!

– : - , - , , GitLab, CI/CD, . , , – .
, , – 4.0.9 (4.2 ). Roadmap – -. -, «»; , RPM'.

( ) «» «»-. . , . – : , - … ? !.. «», .
SQL- , , . History Storage.
Referências
5 . .
-, , , , . . -.

, ? ! , , , . - - , . , , . , :

. «»- , .
- , , , .
- «» : , Configuration Cache, .
- , , . , , .
- - , . , , . 200 , – .
Nota: o proxy passivo ainda não é suportado!Eu removi o código. Isso se deve ao fato de ser difícil para as pessoas criar outro mecanismo, que servidor ainda será responsável por esse proxy.Próximos proxies ativos vão para os servidores. Existe uma opção de servidor para isso (proxy padrão). O proxy modificado possui a opção Servidores: E o que esse servidor modificado faz? Mantém uma conexão KPI com todos os servidores especificados para ele; solicita configuração, envia dados para o primeiro servidor disponível da lista. Isso resolve o problema. Suponha que se você possui um proxy configurado no servidor Zabbix e o servidor Zabbix caiu, existe outro no cluster para não ficar sem um proxy; então o proxy simplesmente se conecta a outro.
E o que esse servidor modificado faz? Mantém uma conexão KPI com todos os servidores especificados para ele; solicita configuração, envia dados para o primeiro servidor disponível da lista. Isso resolve o problema. Suponha que se você possui um proxy configurado no servidor Zabbix e o servidor Zabbix caiu, existe outro no cluster para não ficar sem um proxy; então o proxy simplesmente se conecta a outro.Perguntas
Pergunta da platéia (doravante - A): - Gostaria de esclarecer como estão as coisas entre os servidores? Com qual protocolo eles se comunicam? Existe algum tipo de segurança? Porque não é muito "seguro" levar a comunicação entre os servidores à Internet ... Como está indo?
MM: - Eu acho que este é um candidato à melhor pergunta - direto ao ponto! De fato, quando mudamos para a comunicação padrão, os servidores para a comunicação entre servidores herdaram todos os recursos do protocolo de comunicação que existem entre o servidor e o proxy. Vou esclarecer: há criptografia, compactação de dados. Por favor - da mesma maneira que tudo é configurado via web, como é padrão para o servidor e proxy; tudo vai funcionar.
A: - Como o Hauskiper funciona para você no caso da Clickhouse?
MM: - No “Zabbix” padrão, não há interface da “Governanta” para a Interface do Histórico, ou seja, a Interface do Histórico não suporta a rotação de dados (o ElasticSearch, por exemplo, não suporta). Talvez no 4.2 seja (eu não olhei), mas até agora no 4.0.9.
Facilite isso! O novo "Clickhouse" possui uma partição. Eu gostaria de fazer desativando partições desatualizadas. É claro que não haverá rotação no nível de itens individuais, mas há um truque no Zabbix: você pode especificar valores globais (por exemplo, armazenar o histórico inteiro por não mais de 90 dias) - você pode limpar todos os itens, o histórico inteiro desses valores globais . E será feito! Há mais sobre este tópico no Gitlab.
Queremos fazer o direito arquitetônico: expandir a Interface do Histórico, para que basicamente seja ... Em geral, não quero deixar dívidas técnicas, mas isso será feito. Por ser necessário, mais "Clickhouse" começou a apoiar.
A: - Como você se sente sobre isso? Acontece que você está realizando bastante trabalho de não fornecedor.
MM: - Eu provavelmente não coloquei muito corretamente. Este é o meu hobby! Na verdade, não sou especialista técnico - sou gerente. No meu tempo livre eu pratico.
A: - Pensei que você estivesse fazendo isso como parte do seu negócio principal ...
MM: - Os negócios me dão um lugar legal para testar. Na verdade, eu recomendo - alivia o cérebro. Em algum lugar da "coisa" administrativa, eu diria isso - quando você pode mudar de problemas humanos para esses. Eles são tão legais resolvidos! Essas são questões técnicas. Você programou e funciona da maneira que você programou! É uma pena que as pessoas não devam fazer isso.
R: - Você escreve para “Clickhouse” através de algum proxy ou diretamente?
MM: - Diretamente. De fato, a Interface de História alterada, usada para o "Elastix", também é herdada. O URL é usado, ou seja, através da interface http "Zabbiks" envia "Clickhouse". O que é legal, o Zabbix agrega quando há um grande fluxo de história, milhares de métricas em um pacote e isso cai muito bem na Clickhouse.
A: - De fato, ele escreve bachi para ele?
MM: - Sim. Uma consulta SQL executada pelo URL geralmente contém mil métricas. Admins "Clickhouse" apenas feliz.
Apresentador: - Este é o final do programa nesta sala. Há um programa noturno organizado e há algo que somente você pode fazer. E sugiro que, enquanto você se comunica, pense sobre quais coisas interessantes você pode ... Quando você conta um ao outro sobre seus casos, é mais provável que você possa falar disso. Ao discutir um com o outro, você pode encontrar apenas algumas dicas - o comitê do programa aceitará sua inscrição, considerará e ajudará a criar uma boa história sobre ela. Talvez você tenha algum tipo de história sobre como trabalhar com o comitê do programa?
MM: - Na verdade, muitos comentários são dados. Tive muita sorte: uma pessoa do comitê do programa mora em Chelyabinsk e Highload é a única conferência que trabalha tão de perto com os palestrantes. Eu nunca vi nada assim em nenhum outro lugar. É muito benéfico! Diferentes estágios: os caras assistem ao vídeo, comentam os slides - isso realmente acontece no assunto (ortografia, erros de digitação). Muito legal! Eu recomendo! Tente você mesmo!
Um pouco de publicidade :)
Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando aos seus amigos
VPS baseado em nuvem para desenvolvedores a partir de US $ 4,99 , um
analógico exclusivo de servidores básicos que foi inventado por nós para você: Toda a verdade sobre o VPS (KVM) E5-2697 v3 (6 núcleos) 10GB DDR4 480GB SSD 1Gbps de 10GB de US $ 19 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
Dell R730xd 2 vezes mais barato no data center Equinix Tier IV em Amsterdã? Somente temos
2 TVs Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV a partir de US $ 199 na Holanda! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - a partir de US $ 99! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?