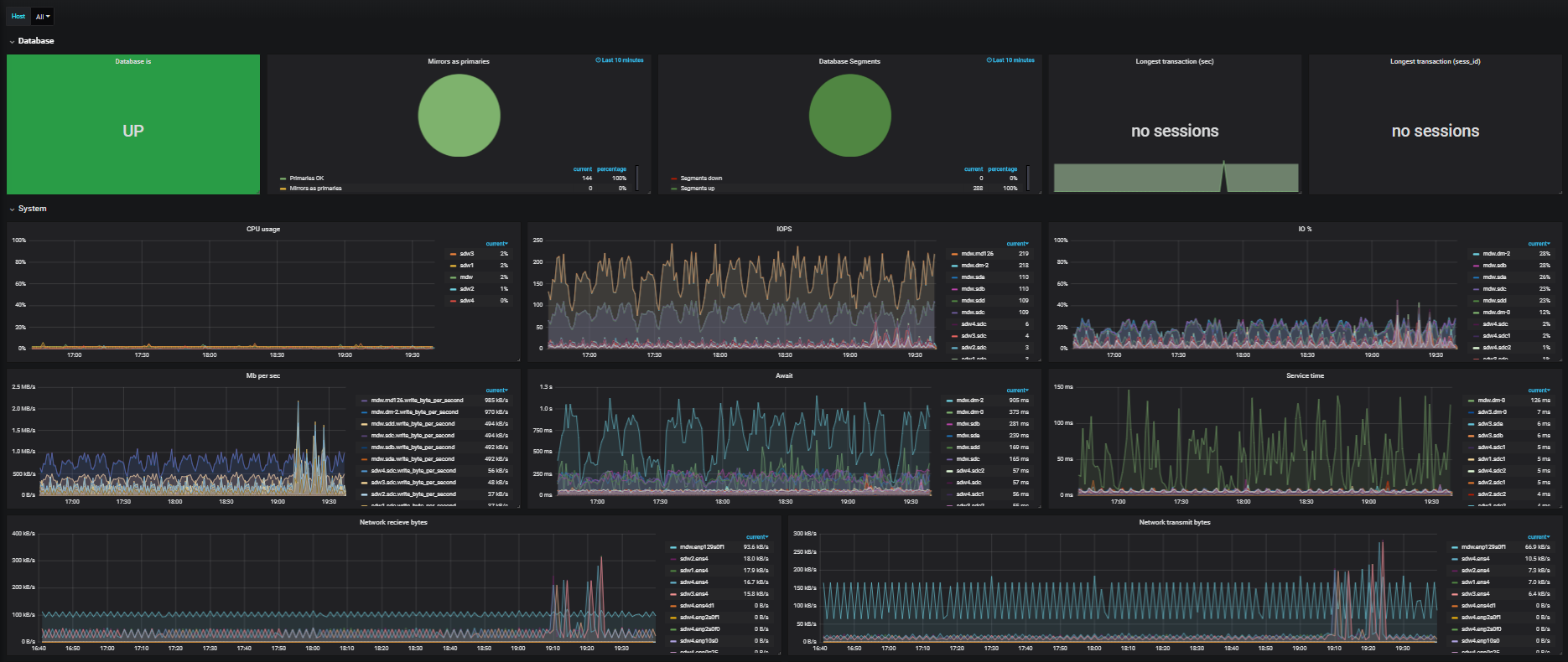
Para o Hadoop e o Greenplum, há uma oportunidade de preparar o SaaS. E se o Khadup é uma coisa bem conhecida, o Greenplum (é a base do produto ArenadataDB, que será discutido mais adiante) é interessante, mas já menos "de ouvido".
O Arenadata DB é um DBMS distribuído baseado no Greenplum de código aberto. Como outras soluções MPP (processamento de dados paralelos), para sistemas massivamente paralelos, a arquitetura da nuvem está longe de ser ótima. Isso pode reduzir o desempenho em até 30% (geralmente menos). Mas, no entanto, esse problema pode ser nivelado (que será discutido abaixo). Além disso, vale a pena comprar esse serviço da nuvem, geralmente é conveniente e lucrativo em comparação com a implantação do seu próprio cluster.
No local é claramente indicado nos guias, mas agora muitas pessoas percebem a escala da conveniência da nuvem. Todo mundo entende que haverá algum tipo de degradação do desempenho, mas ainda é tão superconveniente e rápido que já existem projetos em que isso é sacrificado em alguns estágios, como testar hipóteses.
Se você possui um data warehouse com mais de 1 TB e sistemas transacionais - não o seu perfil de carregamento, a seguir, uma história sobre o que pode ser feito como uma opção. Por que 1 TB? A partir deste volume, o uso do MPP é mais eficiente em termos de relação desempenho / custo quando comparado aos DBMSs clássicos.
Quando usar?
Quando o DBMS clássico de nó único por arquitetura não é adequado para seus volumes. Um caso comum é um novo data warehouse com capacidade superior a 1 TB. O MPP DBMS está agora em tendência, e o Greenplum é um dos melhores do mercado para tarefas modernas. Especialmente considerando a sua abertura. Há também vários sistemas proprietários com muitos recursos prontos para uso: Terradata, Sap Khan, Exadata, Vertika. Portanto, se você não puder pagar abacaxi e perdiz, pegue a ameixa.
O segundo caso é quando você possui um data warehouse existente em algo universal, como Oracle ou Pós-Congresso, mas os usuários reclamam regularmente de relatórios lentos. E quando há novas tarefas como o Big Data - quando os usuários desejam todos os dados imediatamente, eles não podem prever o que farão com eles. Existem muitas situações em que uma empresa operacional precisa de relatórios relevantes apenas um dia e não tem tempo para pagar em um dia. Ou seja, basicamente não há dados necessários. Nesse caso, também é conveniente usar os bancos de dados MPP e experimentar o SaaS na nuvem.
O terceiro caso é quando alguém segue o estilo Khadup e resolve as tarefas padrão do processamento de dados estruturados em lote, mas o cluster não está bem montado. Muitas vezes vemos que a tecnologia é aplicada um pouco e nem sequer como deveria. Por exemplo, você não precisa criar um banco de dados relacional no Khadup. No entanto, se o seu Hadoup de repente não tiver processamento em tempo real ou deveria, mas o administrador e o desenvolvedor fugiram horrorizados, você também pode olhar para o Greenplum na nuvem: o suporte será muito simples, mantendo a capacidade de processar grandes quantidades de dados.
Por que poucas pessoas estão tentando?
Qualquer MPP DBMS requer muita capacidade. Isso é muito ferro. De fato, as pessoas têm medo de tentar o nível de prova de conceito simplesmente por causa do preço de entrada. Eles não podem fazer isso fisicamente. Uma das principais idéias do nosso SaaS é oferecer a oportunidade de brincar com tudo isso sem comprar um cluster de ferro.
E encontramos regularmente clientes que dizem que não gostaríamos de acompanhar, operar e assim por diante de forma independente. E eu gostaria de terceirizar. Este é um sistema analítico e, na maioria das vezes, é crítico para os negócios, mas não é essencial para a missão. Muitos ocidentais estão terceirizando; também começamos recentemente.
Qual é a melhor coisa a fazer no MPP?
Armazém de dados corporativo clássico: para todas as fontes de dados, você obtém dados incrementais e as janelas são criadas para os usuários. Os usuários acima dessas fachadas de lojas criam seus relatórios. "Todo dia eu quero ver como estão as coisas nos negócios" - é isso.
Mais algumas palavras sobre a solução em nuvem
Antigamente, infra-estruturas desse tipo eram mal projetadas para nuvens. Mas, na realidade, mais e mais clientes estão entrando nas nuvens. O trabalho requer alto desempenho, pois gira em torno de muitas consultas analíticas grandes que consomem muitas CPUs, exigem muita memória e têm altas demandas em discos e infraestrutura de rede. Como resultado, quando os clientes implantam DBMSs distribuídos na nuvem, eles podem encontrar vários problemas.
O primeiro é o fraco desempenho da rede. Como tudo isso está acontecendo na nuvem em um ambiente virtual, pode haver muitas máquinas em um hypervisor. Máquinas virtuais podem ser espalhadas por diferentes hipervisores. Além disso, em alguns momentos eles podem estar espalhados por diferentes data centers, os supervisores podem girar sobre eles virtualmente. E por isso, a rede sofre muito. Ao processar um bilhão de registros em uma tabela, digamos 10 servidores, e ele direciona esses dados entre todos os servidores. Uma subespécie trabalha dentro, e mesmo dentro de um servidor, muitas dessas subespécies funcionam. Pode haver de 10 a 20 e agora todos eles começam a direcionar dados pela rede durante a execução da solicitação. A rede está caindo como culturas de inverno. Que conclusão pode ser tirada disso? Use nuvens de alta largura de banda, como a CROC Cloud, que fornece 56 GB no Infiniband.
O segundo problema é que os firewalls e as proteções DDoS parecem muito distorcidos. Lascado, decidido. Antes de usar, recomendamos que você agende uma hora extra para verificar novamente todas as configurações.
Migração ao vivo ainda imperceptível e atualização. Para arrastar uma máquina para outro hypervisor e depois voltar, você não precisa perder pacotes. É necessário shamanize com as configurações no final. Por exemplo, subimos quase imediatamente para aumentar a área de transferência. MTU aumentado para 9.000 jumboframe.
Claro, unidades que possuem HDD. Eles realmente não gostam desse registro, especialmente quando esses são setores muito, muito aleatórios na fila com o restante das solicitações. Decidimos dividir o armazenamento em segmentos: um é apenas para o Greenplum, o outro é compartilhado. Isso é necessário para situações em que uma dúzia de clientes está implantando instalações Greenplum em paralelo. O MPP utiliza o subsistema de disco na máxima extensão possível, os serviços em nuvem se interconectam ao armazenamento e o desempenho é quase o mesmo que o do canal. Se todos os clientes da nuvem não calcularem o MPP, você poderá obter um ganho muito significativo. A distribuição eficiente de energia em tais cargas funciona muito bem.
E por causa de sua própria arquitetura, o Greenplum na nuvem tem melhor desempenho do que Redshift, BigQuery e Snowflake.
Como é a implantação:
Assim:
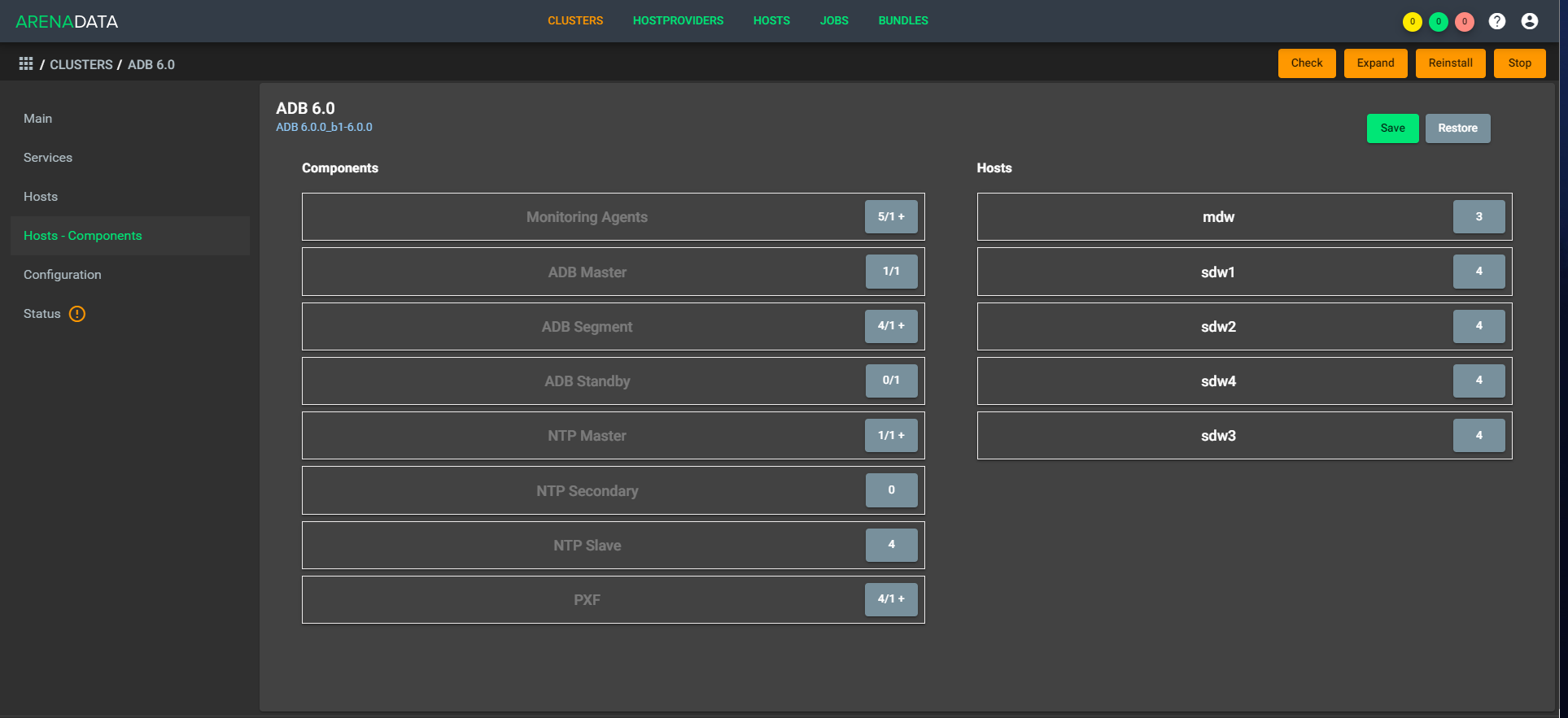
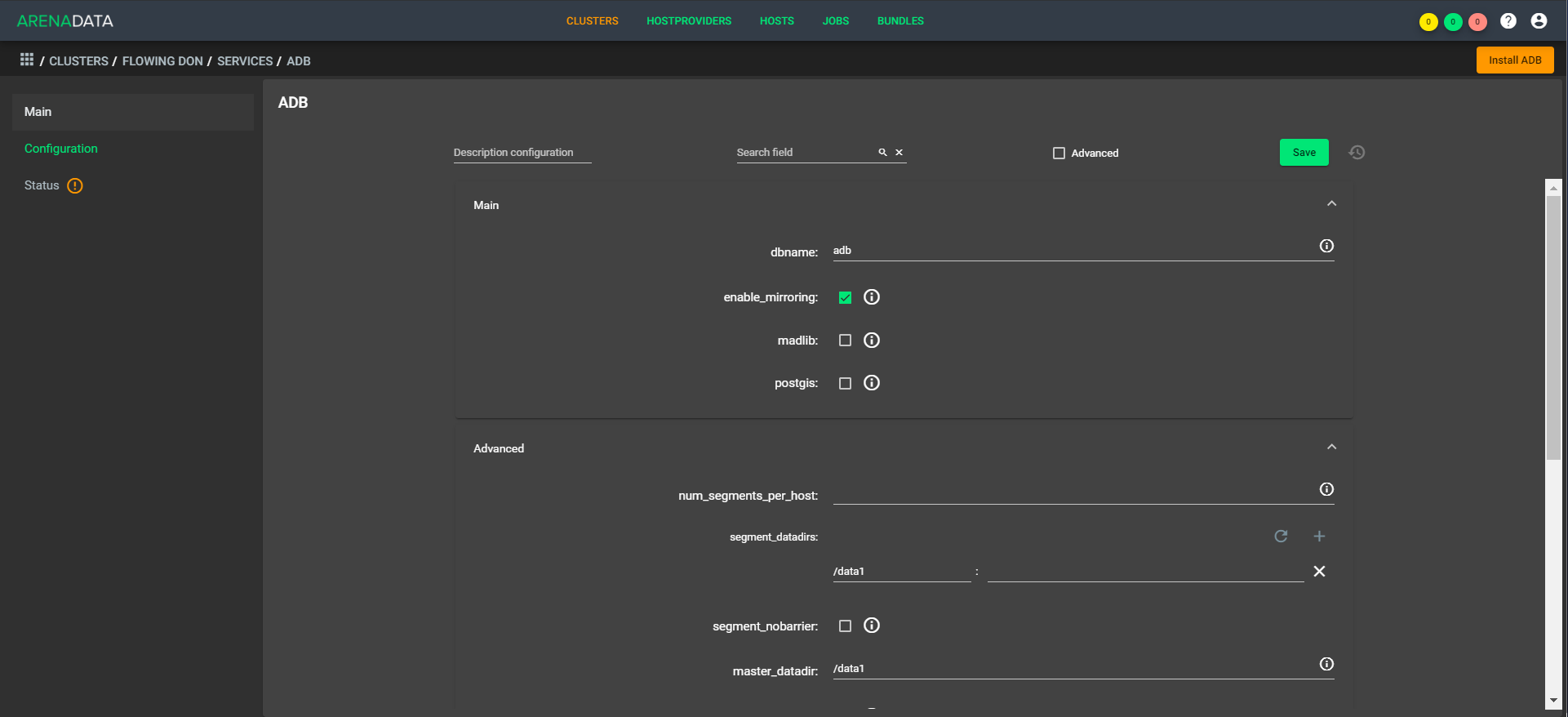
A arquitetura é "respirável", ou seja, você pode implantar rapidamente um fator simples na configuração. Como exemplo, à tarde, temos cinco CPUs e à noite, temos 1.000 manipuladores em ascensão e dez CPUs funcionando. Nesse caso, você não precisa equilibrar os dados, porque eles estão dentro do mesmo armazenamento. Uma extensão está disponível imediatamente, a compactação rápida ainda precisa ser concluída um pouco.
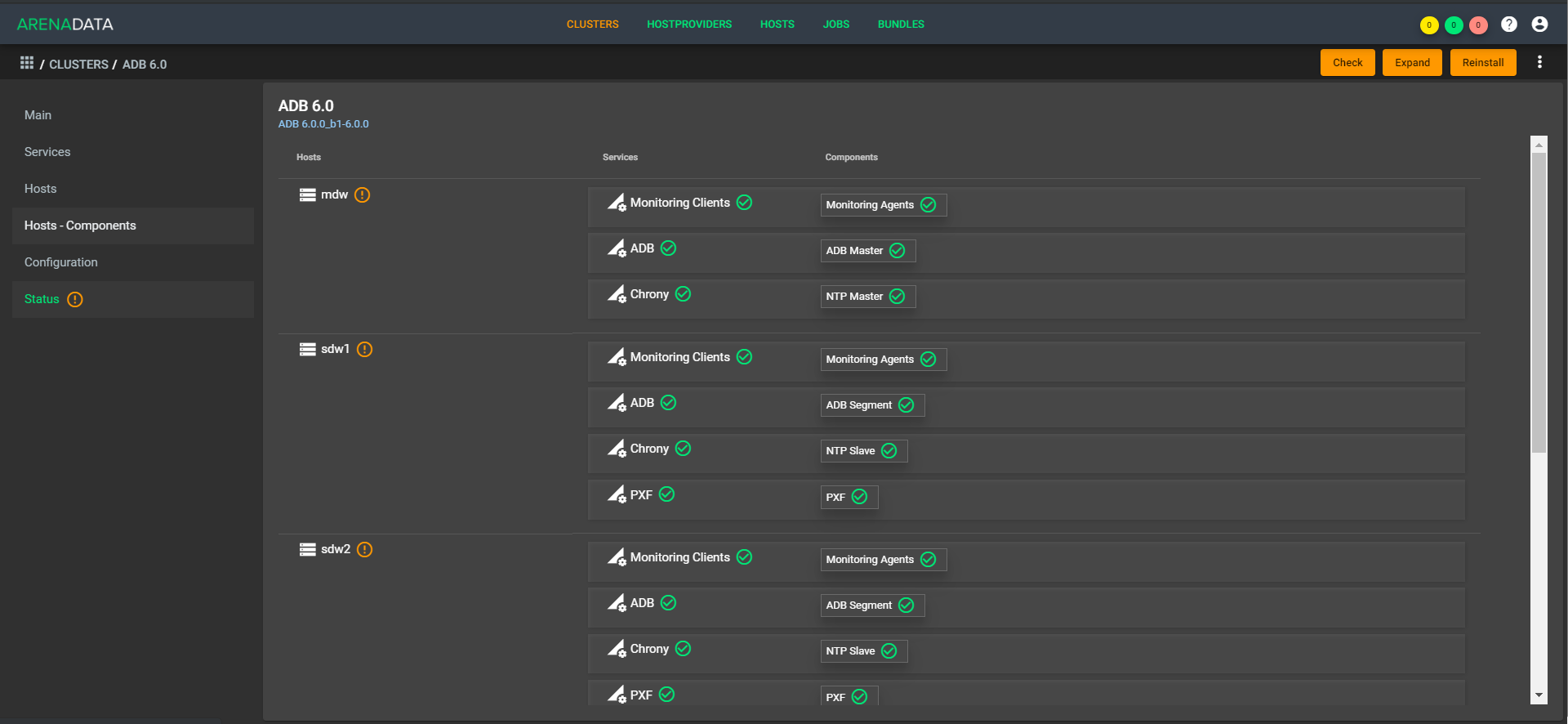
Agora, para o cliente, existe um único ponto de gerenciamento. Ele chega a um local, envia uma solicitação como: “Implante um plano de cluster para mim em tais máquinas”, e nosso suporte implementa as máquinas na nuvem (conosco ou com o cliente), coloca o Greenplum lá, inicia, configura e faz todas as configurações. O mesmo vale para monitoramento, gerenciamento, atualização. À medida que a automação prossegue, isso deixará o suporte nos botões da sua conta.
Primeiro entendemos a conveniência dessa abordagem em projetos internos e, em seguida, começamos a fornecer SaaS aos clientes. Temos uma profunda integração com o S3 - isso permite que você use o Greenplum como um sistema com camadas separadas para computação e armazenamento, ou use o S3 para backups e o Greenplum como um núcleo no QCD na nuvem. Há uma implantação flexível de ambientes para empresas usando a API CROC e a API ADCM.