R é uma ferramenta muito poderosa para trabalhar com estatísticas: do pré-processamento à construção de modelos de qualquer complexidade e gráficos correspondentes.
Uma simples solicitação do Google fornecerá uma grande quantidade de literatura sobre como “usar o R com facilidade e rapidez”. Haverá livros enormes e várias anotações no Stack Overflow , que, à primeira vista, parecem um armazém interminável de exemplos, cada um dos quais em duas contas coletará o código necessário para resolver um problema específico. No entanto, na realidade, isso não é de todo verdade. Existem muito poucos materiais que diriam, por exemplo, como criar um cronograma simples "do zero", com receitas prontas para solucionar dificuldades que surgirão no decorrer da solução desse problema.
Para resolver problemas práticos, são necessárias instruções passo a passo específicas, e não uma descrição detalhada de toda a potência de um pacote. Além disso, exemplos de treinamento prontos (as mesmas íris ) são frequentemente de pouca utilidade, uma vez que pulam imediatamente um dos estágios mais importantes do trabalho com estatísticas - a coleta e o processamento preliminares dos próprios dados. Mas é precisamente para este trabalho que quase uma grande parte de todos os tempos leva! Um problema separado é a criação de agendas que correspondam a padrões formais e, com maior frequência, informais, de um determinado ambiente profissional.
Meus colegas e eu precisamos regularmente fazer cada vez mais visualizações de estatísticas e modelos baseados neles para publicar resultados científicos. Como os estudos dizem respeito à economia, muitos desses trabalhos são semelhantes ao jornalismo profissional.
Em algum momento, ficou claro que, para um trabalho em equipe eficaz, é necessário um tipo de pipeline de processamento estatístico completo. Este artigo nasceu como um guia introdutório para colegas e uma folha de dicas para eu executar este transportador. Parece que esse material pode ser útil para um público mais amplo.
R Gráficos sem dor: Passo a passo
Configuração básica R
Para trabalhar, você precisa de um pacote padrão: R + RStudio . Eles estão disponíveis gratuitamente para todas as plataformas comuns. R é instalado primeiro, depois o RStudio. Geralmente não há problemas.
Antes de trabalhar, é melhor salvar imediatamente o novo script em algum lugar do sistema de arquivos e instalar imediatamente o diretório de trabalho R na pasta em que o script está armazenado (menu Sessão - Definir Diretório de Trabalho - Para o Local do Arquivo de Origem). A última observação é importante, pois, caso contrário, o início de qualquer script externo ou nativo após a reinicialização do RStudio não ocorrerá. Por alguma razão, o RStudio não faz isso por padrão, o que seria lógico.
Mesmo no pacote básico R, existem ferramentas de visualização padrão (função de plotagem ) que permitem criar muitos tipos de gráficos, mas, no entanto, esses recursos claramente não são suficientes para ilustrações completas e altamente personalizáveis.
A biblioteca mais usada para gráficos em R é o pacote ggplot2 , que também usaremos.
Também vale a pena instalar imediatamente os pacotes readxl (para leitura de arquivos .xls, .xlsx) e dplyr (para trabalhar com matrizes), escalas (para trabalhar com diferentes escalas de dados), Cairo (para desenhar gráficos de ggplot para arquivos). Tudo isso pode ser feito com um comando:
install.packages("ggplot2", "readxl", "scales", "dplyr", "Cairo")
Coleta e preparação de dados
O mais surpreendente é que esse estágio em qualquer literatura, seja um livro teórico sério sobre estatística teórica aplicada ou um guia para pacotes estatísticos específicos, é dedicado a catastroficamente pouco espaço e tempo. No entanto, de acordo com a experiência de pesquisa e liderança independentes de estudantes e colegas mais jovens, sabe-se que é nesta fase que a maior parte do tempo e do esforço pode cair, portanto, é muito importante salvá-los, mesmo na solução de problemas puramente técnicos.
Há duas perguntas aqui:
- Como escolher o formato de arquivo correto?
- Qual é a melhor maneira de estruturar dados?
Com o formato, o dilema é simples: CSV versus Microsoft Excel (não é tão importante, “novo” .xlsx .xls antigo). Muitas pessoas pensam que o CSV se beneficia da simplicidade (na verdade, esse é um arquivo de texto comum no qual os valores das colunas são separados por vírgula ou ponto e vírgula) e velocidade. Mas eu escolho o Excel por dois motivos: primeiro, nesse arquivo, você pode armazenar várias tabelas simultaneamente em guias diferentes e, segundo, mais importante, não precisa pensar em escolher o separador de colunas e a casa decimal à direita. Para CSV, isso geralmente deve ser gravado manualmente no código R e verifique se o arquivo de dados é salvo com as mesmas configurações.
Estruturar dados é uma questão mais complexa, exigindo um entendimento básico de como os bancos de dados devem ser organizados. Se você não entrar na teoria dos bancos de dados relacionais sobre diferentes formas normais, então A tabela de dados deve ser redundante, ou seja , conter colunas extras. Isso é necessário para que, posteriormente, no script em R, você possa selecionar de maneira flexível determinadas informações para processamento adicional. Por exemplo, se queremos representar uma série temporal primitiva, precisamos criar colunas que correspondam a todas as características de agrupamento possíveis. Por exemplo, se esta é uma série de observações anuais sobre a população da cidade condicional de Severovostochinsk, precisaremos das seguintes colunas: ano (ano), var (nome do indicador), valor (valor do indicador).
Forneceremos quaisquer dados de entrada para esse estilo de apresentação de informações.
Exemplo
Objetivo: construir uma comparação da dinâmica dos volumes de colheita na Rússia, no Distrito Federal da Sibéria e no Território de Krasnoyarsk em 2009-2018.
A obtenção de dados para esta tarefa é bastante simples: basta encontrar o indicador correspondente no Sistema Estatístico e Informação Interdepartamental Unificado . A sutileza vem a seguir. Você pode baixar imediatamente os dados no formato .xlsx e estruturá-los manualmente, como mostrado acima. Felizmente, algumas fontes de informação (por exemplo, EMISS) permitem fazer isso com os recursos do próprio serviço, o que simplifica bastante o trabalho e reduz o tempo necessário para concluí-lo.
Portanto, para o EMISS, basta entrar no modo "Configurações" (o botão correspondente no canto superior direito da página de dados) e mover todos os sinais, exceto o "Período" da coluna "Colunas" para a coluna "Linhas". Acontece que uma mesa está quase pronta para o nosso trabalho futuro. Além disso, já no Excel (ou em qualquer outro editor adequado), faz sentido trazer a estrutura da tabela para um formato semelhante ao apresentado acima e garantir que a primeira linha contenha apenas os nomes das variáveis, com dados em latim (em princípio, R pode funcionar com títulos em russo mas isso é inconveniente ao escrever código). O resultado foi uma tabela (um fragmento é fornecido em várias linhas).
Agora você pode chamar o logging dessa planilha, salvar o livro inteiro no arquivo graphs.xlsx e acessar o RStudio.
Nós conectamos as bibliotecas necessárias.
library(ggplot2) library(readxl) library(Cairo) library(scales) library(dplyr)
Se estiver sendo preparada uma programação para uma publicação no idioma russo, você deverá definitivamente configurar o código do idioma apropriado. A opção mais moderna que funcionará na maioria dos casos é, obviamente, a codificação UTF-8:
Sys.setlocale("LC_ALL", "ru_RU.UTF-8")
Se o sistema for antigo (alguns Windows ou Linux antigo), você precisará primeiro entender qual codificação é usada por padrão - essa não é uma tarefa tão simples, que está longe do objetivo deste artigo.
Agora você precisa carregar os dados no R.
df_logging <- read_excel("graphs.xlsx", sheet ="logging")
A opção de sheet aqui define o nome da planilha na pasta de trabalho do Excel a partir da qual os dados serão carregados.
Construímos a versão mais simples da programação necessária.
ggplot(data=df_logging, aes(x=year, y=value)) + geom_line(aes(linetype=location))

Em princípio, quase “pronto para o uso” acabou sendo um cronograma bastante digno, o que é bastante adequado para uma análise inicial do processo em estudo, mas, do ponto de vista de uma possível publicação, ainda requer refinamentos significativos.
Primeiro, vamos trazer o estilo gráfico para um estilo mais acadêmico. O pacote ggplot2 possui vários temas básicos prontos. O tema theme_classic pode ser reconhecido como o mais adequado para o nosso caso. Como parte de sua configuração, você pode definir imediatamente o tamanho da fonte e do fone de ouvido. Minhas preferências pessoais pertencem ao sistema de fontes moderno PT Sans, PT Serif, PT Mono . Mas, é claro, você pode pedir um Times ou Helvetica mais clássico. Além disso, a publicação em que a publicação está planejada pode ter instruções especiais a esse respeito. O ponto base é empiricamente determinado como sendo 12 pt.
ggplot(data=df_logging, aes(x=year, y=value)) + geom_line(aes(linetype=location)) + theme_classic(base_family = "PT Sans", base_size = 12)
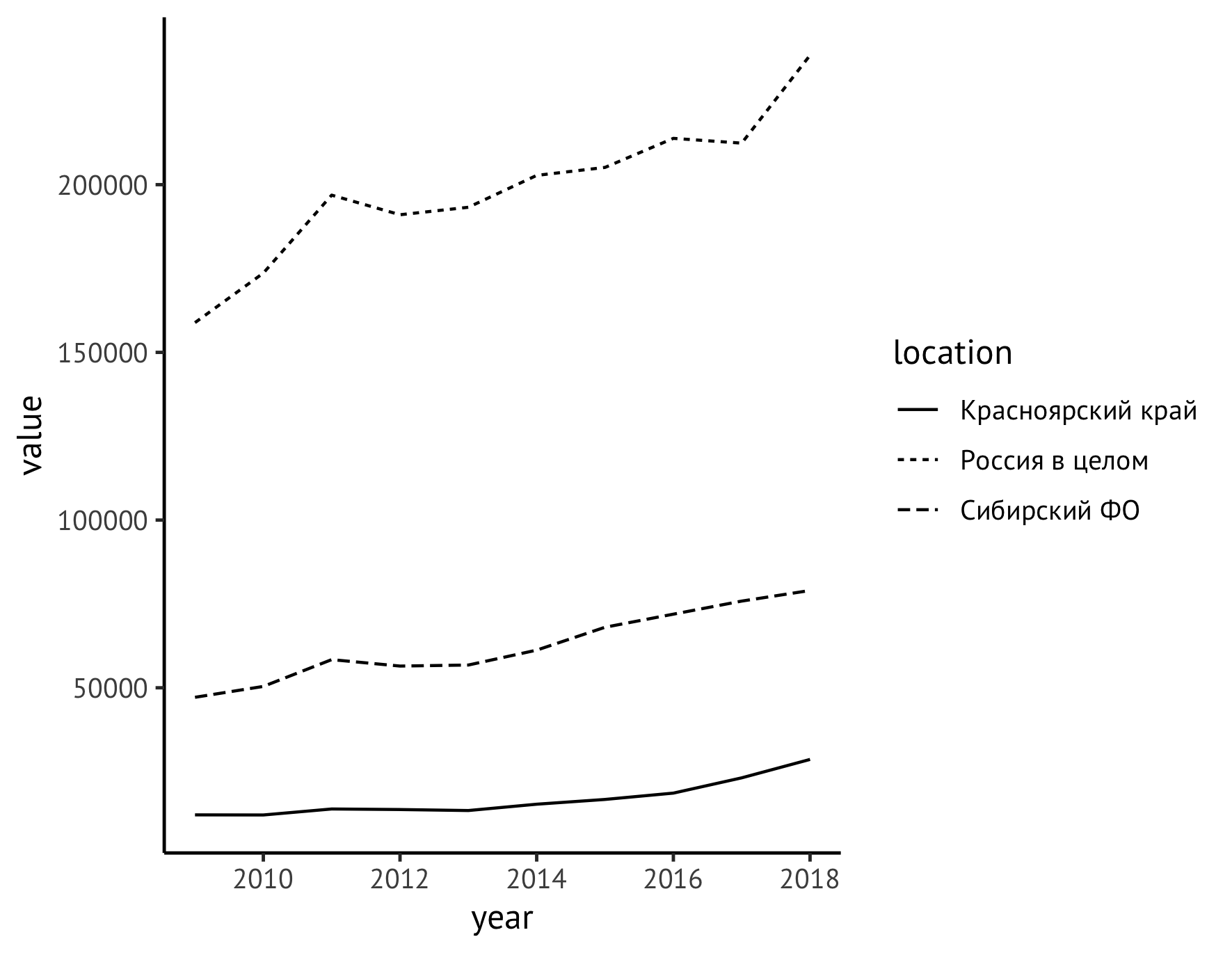
Em seguida, mova a legenda do campo direito do gráfico para baixo (usando a instrução de theme ) e, ao mesmo tempo, atribua nomes significativos aos eixos (instrução de labs ). Ao longo do eixo Y, escrevemos o nome do indicador com unidades de medida ("Registrando volumes, milhões de metros cúbicos") e excluímos os rótulos ao longo do eixo X, pois é claro que os anos estão marcados lá.
ggplot(data=df_logging, aes(x=year, y=value)) + geom_line(aes(linetype=location)) + theme_classic(base_family = "PT Sans", base_size = 12) + theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) + labs(x = "", y = " , . . ", color="")

Para tornar as unidades de medida mais convenientes para a percepção, passaremos de mil metros cúbicos. m para milhões. Para fazer isso, simplesmente divida os valores por 1000, ou seja, ajuste a primeira linha do nosso código da seguinte maneira:
ggplot(data=df_logging, aes(x=year, y=value/1000))
Ao mesmo tempo, você precisa alterar as unidades na inscrição:
labs(x = "", y = " , . ", color="")
E imediatamente melhoraremos um pouco o estilo da imagem adicionando pontos para indicar cada valor observado, para o qual adicionaremos uma instrução:
geom_point(size=2)
Você também pode definir explicitamente o estilo das próprias linhas. É lógico tornar o indicador para a Rússia uma linha sólida e para o Distrito Federal da Sibéria e o Território de Krasnoyarsk - versões diferentes de intermitentes:
scale_linetype_manual(values=c("twodash", "solid", "dotted"))
Agora o código geral e o gráfico ficam assim:
ggplot(data=df_logging, aes(x=year, y=value/1000)) + geom_line(aes(linetype=location)) + geom_point(size=1) + theme_classic(base_family = "PT Sans", base_size = 12) + theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) + scale_linetype_manual(values=c("twodash", "solid", "dotted")) + labs(x = "", y = " , . ", color="")

Resta resolver uma tarefa mais substantiva - aumentar o conteúdo informativo de nossa programação. Agora, pode-se ver que, em geral, o indicador para todos os objetos de observação aumentou, além disso, desde cerca de 2014 é mais forte do que antes. Mas seria muito mais claro se representássemos diretamente no gráfico também os valores no primeiro e no último ano e, digamos, no pico de 2011. A nova instrução geom_text ajudará:
geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")), data = subset(df_logging, year == 2009 | year == 2018 | year == 2011), check_overlap = TRUE, vjust=-0.8)
À primeira vista, parece bastante complicado, e devo dizer que não era realmente tão fácil montá-lo. Vou tentar explicar o que está acontecendo aqui. Por si só, geom_text adiciona rótulos de texto ao gráfico. Para esta instrução, é necessário um conjunto de dados. Se especificássemos df_logging diretamente, df_logging inscrições acima de cada ponto. Isso é feito com bastante frequência, mas para séries temporais bastante simples como a nossa, essa abordagem criará apenas ruído visual desnecessário sem fornecer novas informações sobre o comportamento do indicador observado. Portanto, levaremos apenas os anos essenciais para a compreensão da dinâmica do indicador: 2009 (início das observações), 2011 (pico local), 2018 (final das observações). Isso ajudará o subset padrão.
Para a exibição correta dos números de acordo com a tradição de língua russa, precisamos de uma vírgula como separador das partes inteiras e decimais ( decimal.mark ) e, para cortar o número de casas decimais, a instrução de dígitos. Várias experiências com ele, incluindo o uso da função round , levaram ao fato de que, se precisarmos de uma casa decimal, precisamos passar o valor 3 para digits .
A opção check_overlap não é diretamente necessária aqui, mas pode ser útil em outros casos: é um controle automático de etiquetas sobrepostas. A opção vjust controla o posicionamento dos rótulos verticalmente. O valor é selecionado com base em considerações de gosto.
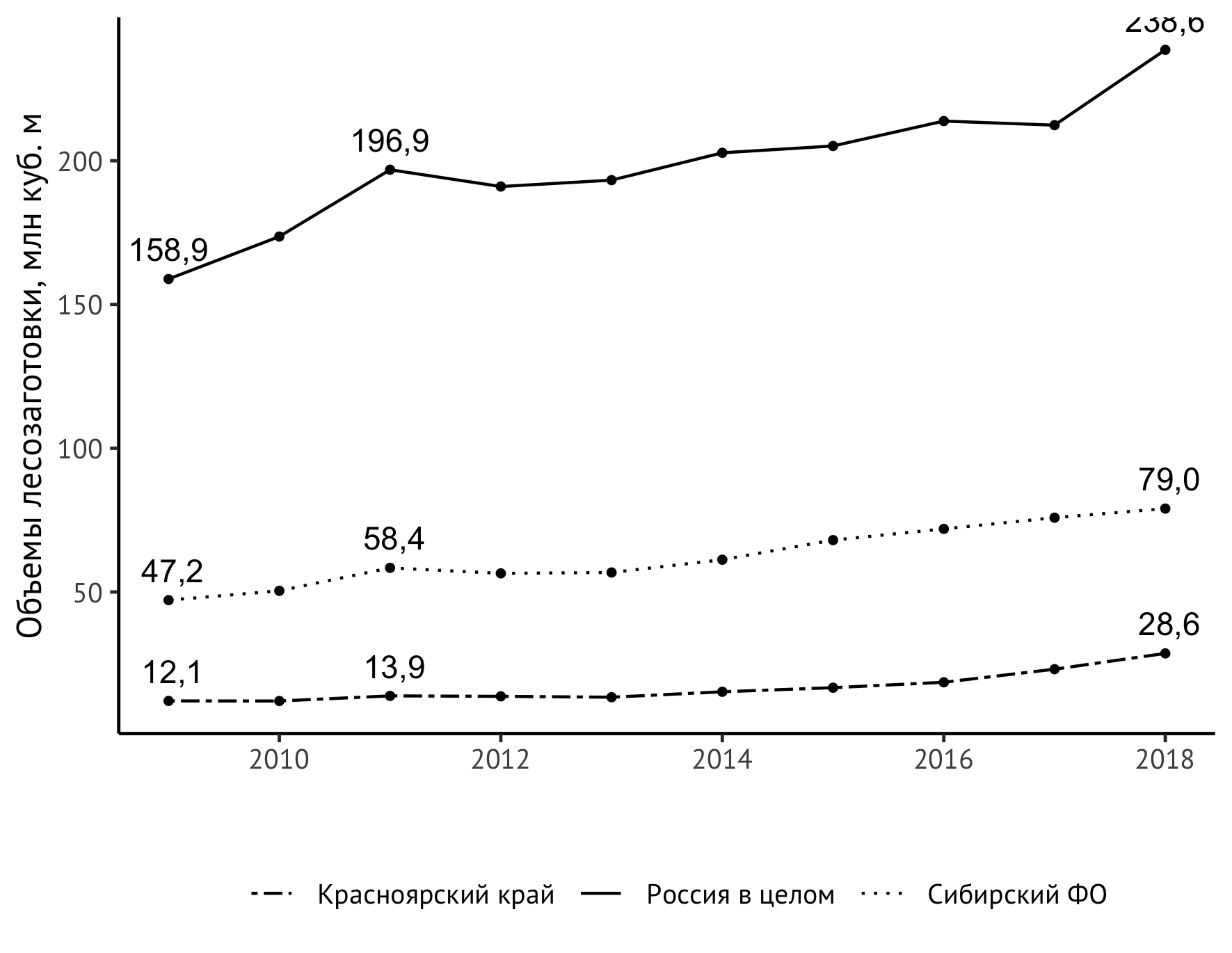
Agora, o cronograma é realmente interessante a considerar!
Mas um problema inesperado foi descoberto - o valor superior direito é "cortado" pelo tamanho vertical da imagem. Existem várias maneiras de resolver esse problema. Saí com um pequeno trecho da escala do eixo vertical, com um limite superior explícito de 250 milhões de metros cúbicos. m:
scale_y_continuous(limits = c(0,250))
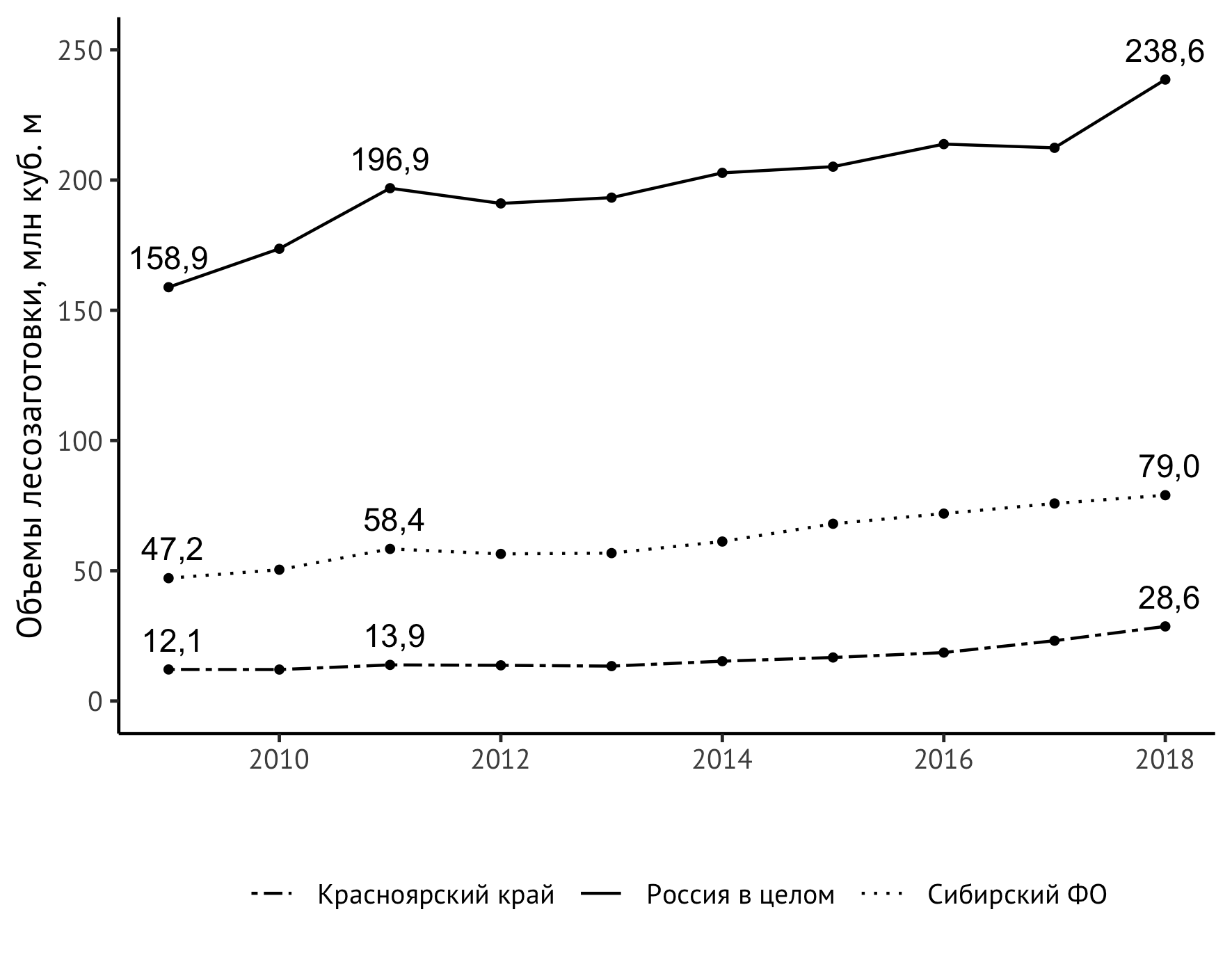
Feito! Portanto, o código final fica assim:
ggplot(data=df_logging, aes(x=year, y=value/1000)) + geom_line(aes(linetype=location)) + geom_point(size=1) + theme_classic(base_family = "PT Sans", base_size = 12) + theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) + geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")), data = subset(df_logging, year == 2009 | year == 2018 | year == 2011), check_overlap = TRUE, vjust=-0.8) + geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")), data = subset(df_logging, year == 2009 | year == 2018 | year == 2011), check_overlap = TRUE, vjust=-0.8) + scale_linetype_manual(values=c("twodash", "solid", "dotted")) + scale_y_continuous(limits = c(0,250)) + labs(x = "", y = " , . ", color="")
A imagem resultante está incluída na monografia: Modernização estrutural como um fator para aumentar a competitividade da região (no exemplo do Território de Krasnoyarsk) / ed. Shishatsky N.G. - Novosibirsk: IEOPP SB RAS, 2020 (no prelo).
Exportar
O plug-in de visualização de gráficos embutido no RStudio permite exportar imagens em vários formatos sem comandos adicionais, em apenas alguns cliques. O problema é que, para tarefas práticas, esse serviço é praticamente inútil. Ao salvar em formatos rasterizados (.jpg, .png), a configuração padrão é muito baixa; portanto, quando você importa uma imagem, por exemplo, no Word, ela fica desfocada. Com o vetor .eps ou .pdf, a situação é francamente pior: a economia ocorre com erros que não permitem a abertura do arquivo ou é salva sem a possibilidade de usar inscrições no idioma russo.
A solução é usar a função ggplot pacote ggplot .
Se a saída exigir um arquivo raster comum, por exemplo, no formato .png, tudo será bem simples:
ggsave("logging.png", width=709, height=549, units="px")
A geometria (opções width e height ) e as unidades de medida ( units ) podem ser omitidas, mas, por padrão, a imagem será exportada em quadrado, o que dificilmente é conveniente. Portanto, é melhor criar sua própria proporção e o tamanho necessário e definir esses parâmetros manualmente, como é feito na linha de código acima.
Para o uso subsequente da imagem em publicações em papel, é razoável exportar a imagem em formatos vetoriais, para que posteriormente no layout haja a possibilidade de alterar livremente a geometria da imagem. Muitas revistas preferem o formato .eps - também é conveniente usá-lo para exportar para o Word. Vamos precisar do driver Cairo já instalado e conectado:
ggsave(filename = "export.eps", width=15, height=11.6, units="cm", device = cairo_ps)
Os arquivos serão salvos no diretório atual em que o script R. está localizado.
O que mais ler
A literatura sobre gráficos em R é bastante. Aqui estão alguns exemplos, o primeiro dos quais é o trabalho do autor do pacote ggplot:
Provavelmente, o melhor e mais detalhado livro sobre gráficos em R em russo é o livro de Timofei Samsonov. Visualização e análise de dados geográficos na linguagem R. Este é um excelente guia detalhado para muitos problemas comuns e específicos que podem ser resolvidos com o R.
Você também pode recomendar um livro em russo sobre R em geral:
Shitikov V.K., Mastitsky S.E. Classificação, regressão, algoritmos de mineração de dados usando R. 2017 .
Apenas um exemplo interessante e motivador é uma apresentação poderosa sobre o uso do ggplot2 na preparação de desenhos para o influente jornal Financial Times .