
Na RIT 2019, nosso colega Alexander Korotkov fez um
relatório sobre a automação do desenvolvimento no CIAN: para simplificar a vida e o trabalho, usamos nossa própria plataforma Integro. Ele rastreia o ciclo de vida das tarefas, remove operações de rotina dos desenvolvedores e reduz significativamente o número de bugs na produção. Nesta postagem, suplementaremos o relatório de Alexander e mostraremos como passamos de scripts simples para combinar produtos de código aberto por meio de nossa própria plataforma e o que uma equipe de automação separada faz.
Nível zero
"Não existe um nível zero, eu não sei disso"
Mestre Shifu do filme "Kung Fu Panda"A automação no CIAN começou 14 anos após a fundação da empresa. Depois, havia 35 pessoas na equipe de desenvolvimento. Difícil de acreditar, certo? Obviamente, a automação existia de alguma forma, mas uma área separada de integração contínua e entrega de código começou a tomar forma em 2015.
Naquela época, tínhamos um enorme monólito de Python, C # e PHP implantado em servidores Linux / Windows. Para a implantação desse monstro, tivemos um conjunto de scripts que executamos manualmente. Havia também uma montagem monolítica, causando sofrimento e sofrimento devido a conflitos ao mesclar ramificações, editar defeitos e reconstruir "com um conjunto diferente de tarefas na compilação". O processo simplificado ficou assim:

Isso não nos convinha, e queríamos criar um processo repetitivo, automatizado e controlado de criação e implantação. Para fazer isso, precisávamos de um sistema de CI / CD e escolhemos entre a versão gratuita do Teamcity e o Jenkins grátis, pois trabalhamos com eles e ambos nos convieram para um conjunto de funções. Escolhemos o Teamcity como um produto mais recente. Então, não usamos a arquitetura de microsserviço e não contamos com um grande número de tarefas e projetos.
Chegamos à ideia do nosso próprio sistema
A implementação do Teamcity removeu apenas uma parte do trabalho manual: ainda havia a criação de solicitação de recebimento, promoção de tarefas por status em Jira, seleção de tarefas para liberação. O Teamcity não conseguiu mais lidar com isso. Foi necessário escolher o caminho da automação adicional. Consideramos opções para trabalhar com scripts no Teamcity ou mudar para sistemas de automação de terceiros. Mas, no final, decidimos que precisávamos da flexibilidade máxima que apenas nossa própria solução oferece. Então apareceu a primeira versão do sistema de automação interno chamado Integro.
O Teamcity está envolvido na automação no nível de inicialização dos processos de montagem e implantação, e a Integro se concentrou na automação de nível superior dos processos de desenvolvimento. Era necessário combinar trabalho com tarefas no Jira com o processamento do código fonte associado no Bitbucket. Nesse estágio, o Integro começou a ter seus próprios fluxos de trabalho para trabalhar com tarefas de vários tipos.
Devido ao aumento da automação nos processos de negócios, o número de projetos e execuções no Teamcity aumentou. Então surgiu um novo problema: faltava uma instância gratuita do Teamcity (3 agentes e 100 projetos), adicionamos outra instância (mais 3 agentes e 100 projetos) e depois outra. Como resultado, obtivemos um sistema de vários clusters, que era difícil de gerenciar:
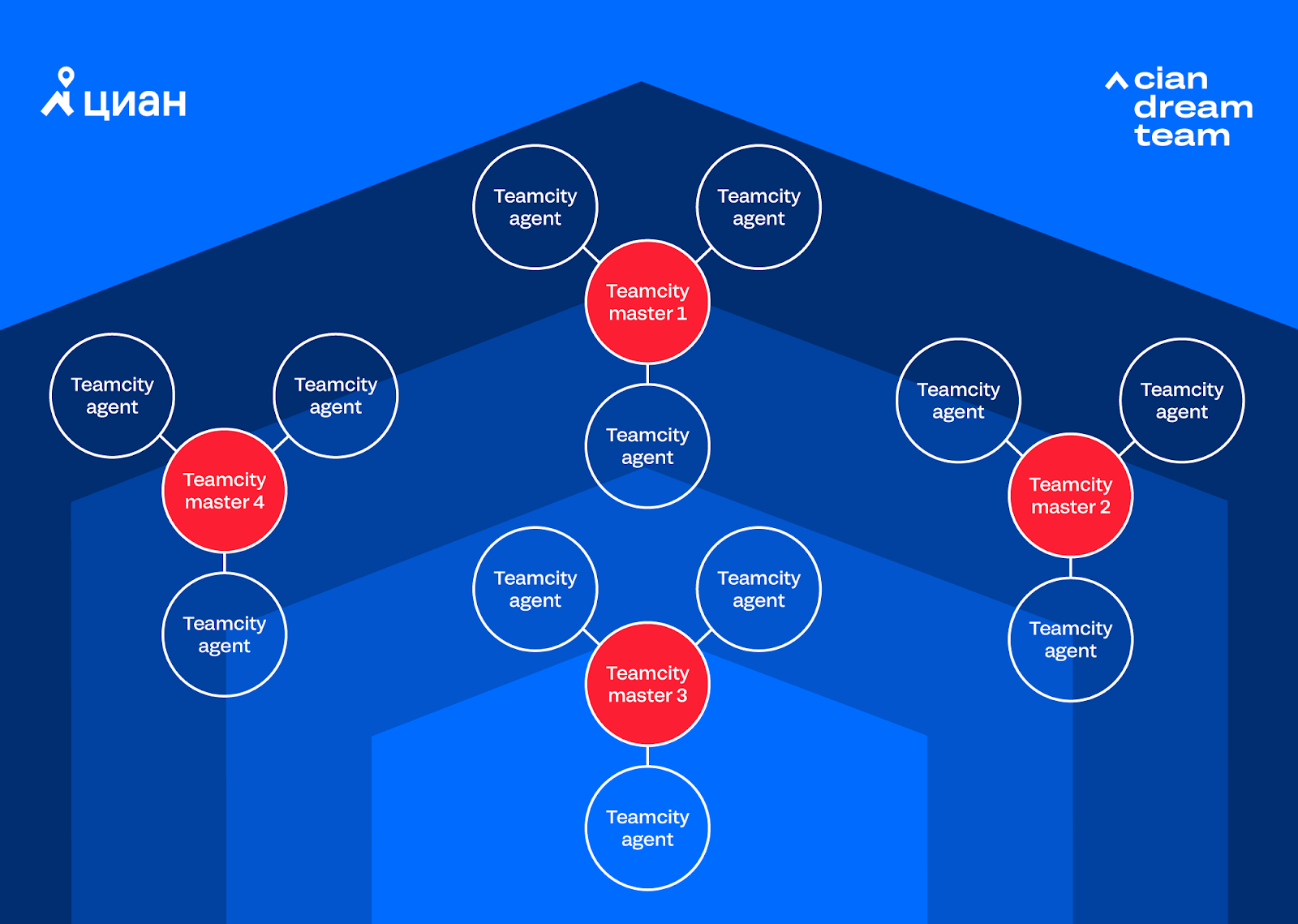
Quando surgiu a pergunta sobre a 4 instância, percebemos que não podemos mais viver assim, já que os custos totais do suporte a 4 instâncias não se encaixam mais em nenhuma estrutura. Surgiu a questão de comprar um Teamcity pago ou optar por um Jenkins grátis. Realizamos cálculos sobre instâncias e planos de automação e decidimos que viveríamos com Jenkins. Depois de algumas semanas, mudamos para Jenkins e nos livramos da parte da dor de cabeça associada ao suporte a várias instâncias do Teamcity. Portanto, pudemos nos concentrar no desenvolvimento do Integro e na conclusão do Jenkins por nós mesmos.
Com o crescimento da automação básica (na forma de criação automática de solicitações de recebimento, coleta e publicação da cobertura do código e outras verificações), houve um forte desejo de recusar o máximo possível de lançamentos manuais e de dar esse trabalho aos robôs. Além disso, a empresa começou a migrar para microsserviços, que exigiam lançamentos frequentes e separadamente um do outro. Então, gradualmente chegamos às liberações automáticas de nossos microsserviços (por enquanto, estamos lançando o monólito manualmente devido à complexidade do processo). Mas, como geralmente acontece, uma nova complexidade surgiu.
Automatizar testes
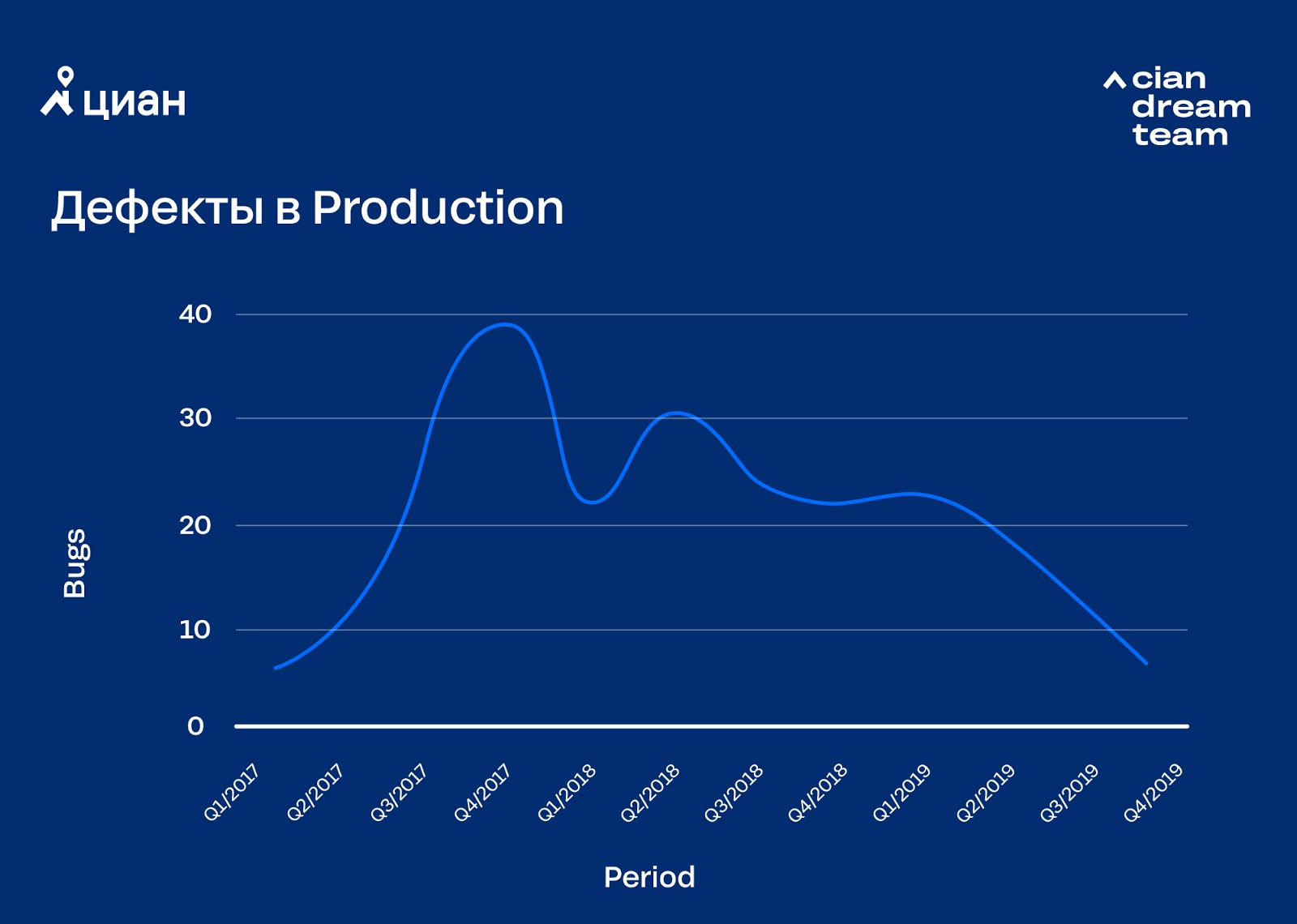
Devido à automação de lançamentos, os processos de desenvolvimento se aceleraram, em parte devido a pular algumas etapas dos testes. E isso levou a uma perda temporária de qualidade. Parece brega, mas, juntamente com a aceleração dos lançamentos, foi necessário alterar a metodologia de desenvolvimento do produto. Era necessário pensar em testar a automação, inculcar responsabilidade pessoal (aqui estamos falando sobre "aceitar uma ideia na cabeça" em vez de multas monetárias) do desenvolvedor pelo código liberado e bugs nele, bem como na decisão de emitir / não emitir a tarefa por meio de uma implantação automática.
Eliminando problemas de qualidade, tomamos duas decisões importantes: começamos a realizar testes em canárias e implementamos o monitoramento automático do histórico de erros com resposta automática ao excesso. A primeira solução tornou possível encontrar erros óbvios antes do código entrar totalmente em produção; a segunda reduziu o tempo de resposta a problemas na produção. É claro que ocorrem erros, mas gastamos a maior parte do tempo e energia não em correção, mas em minimização.
Equipe de automação
Agora, temos uma equipe de 130 desenvolvedores e continuamos
a crescer . A equipe de integração contínua e entrega de código (doravante denominada equipe de Implantação e Integração ou DI) é composta por 7 pessoas e trabalha em duas direções: desenvolvimento da plataforma de automação Integro e DevOps.
O DevOps é responsável pelo ambiente Dev / Beta do site CIAN, o ambiente Integro, ajuda os desenvolvedores a resolver problemas e desenvolve novas abordagens para os ambientes de dimensionamento. A linha de negócios da Integro lida com o próprio Integro e com serviços relacionados, por exemplo, plug-ins para Jenkins, Jira, Confluence e também desenvolve utilitários e aplicativos auxiliares para equipes de desenvolvimento.
A equipe de DI trabalha em conjunto com a equipe de Plataforma, que desenvolve arquiteturas, bibliotecas e abordagens de desenvolvimento dentro da empresa. Ao mesmo tempo, qualquer desenvolvedor dentro do CIAN pode contribuir para a automação, por exemplo, fazer microautomação para as necessidades da equipe ou compartilhar uma boa idéia de como tornar a automação ainda melhor.
Automação de torta de sopro em ciano
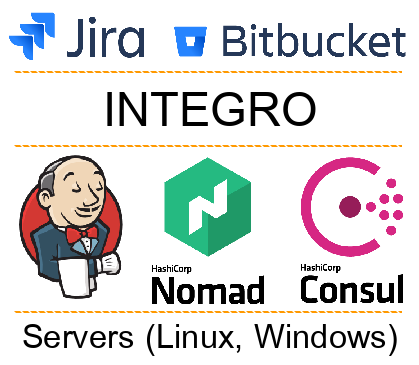
Todos os sistemas envolvidos na automação podem ser divididos em várias camadas:
- Sistemas externos (Jira, Bitbucket, etc.). As equipes de desenvolvimento trabalham com eles.
- Plataforma Integro. Na maioria das vezes, os desenvolvedores não trabalham diretamente com ele, mas é ela quem apóia o trabalho de toda a automação.
- Serviços de entrega, orquestração e descoberta (por exemplo, Jeknins, Consul, Nomad). Com a ajuda deles, implantamos o código nos servidores e fornecemos os serviços entre si.
- Camada física (servidor, SO, software relacionado). Nesse nível, nosso código funciona. Pode ser um servidor físico ou virtual (LXC, KVM, Docker).
Com base nesse conceito, dividimos as áreas de responsabilidade dentro da equipe de DI. Os dois primeiros níveis estão na área de responsabilidade da área de desenvolvimento da Integro e os dois últimos já estão na área de responsabilidade do DevOps. Essa separação permite que você se concentre nas tarefas e não interfere na interação, porque estamos próximos um do outro e trocamos constantemente conhecimento e experiência.
Integro
Vamos nos concentrar no Integro e começar com a pilha de tecnologia:
- CentOs 7
- Docker + Nômade + Consul + Cofre
- Java 11 (o antigo monólito Integro permanecerá no Java 8)
- Spring Boot 2.X + Configuração da nuvem da primavera
- PostgreSql 11
- Rabbitmq
- Apache inflamar
- Camunda (incorporado)
- Grafana + Grafite + Prometeu + Jaeger + ELK
- Interface do usuário da Web: React (CSR) + MobX
- SSO: Keycloak
Aderimos ao princípio do desenvolvimento de microsserviços, embora tenhamos legado na forma de um monólito da versão anterior do Integro. Cada microsserviço está girando em seu contêiner de docker, os serviços se comunicam entre si por meio de solicitações HTTP e mensagens RabbitMQ. Os microsserviços se encontram pelo Consul e executam uma solicitação, passando a autorização pelo SSO (Keycloak, OAuth 2 / OpenID Connect).

Como um exemplo real, considere a interação com Jenkins, que consiste nas seguintes etapas:
- O microsserviço de gerenciamento de fluxo de trabalho (a seguir denominado microsserviço de fluxo) deseja executar o assembly no Jenkins. Para fazer isso, ele encontra através da integração do microsserviço IP IP: PORT ao Jenkins (a seguir, microsserviço Jenkins) e envia a ele uma solicitação assíncrona para iniciar a montagem no Jenkins.
- O microsserviço Jenkins, após o recebimento da solicitação, gera e devolve o ID do trabalho, pelo qual será possível identificar o resultado do trabalho. Junto com isso, ele inicia a construção no Jenkins através de uma chamada para a API REST.
- O Jenkins cria e, quando concluído, envia um webhook com os resultados ao microsserviço Jenkins.
- Um microsserviço Jenkins, após receber um webhook, gera uma mensagem sobre a conclusão do processamento da solicitação e anexa os resultados da execução a ele. A mensagem gerada é enviada para a fila RabbitMQ.
- Por meio do RabbitMQ, a mensagem publicada chega ao microsserviço Flow, que aprende sobre o resultado do processamento de sua tarefa, correspondendo ao ID da tarefa da solicitação e da mensagem recebida.
Agora, temos cerca de 30 microsserviços que podem ser divididos em vários grupos:
- Gerenciamento de configuração.
- Informar e interagir com os usuários (mensageiros instantâneos, correio).
- Trabalhe com código fonte.
- Integração com ferramentas de implantação (jenkins, nômade, consul, etc.).
- Monitoramento (lançamentos, bugs, etc.).
- Utilitários da Web (interface do usuário para gerenciar ambientes de teste, coletar estatísticas etc.).
- Integração com rastreadores de tarefas e sistemas similares.
- Gerenciar fluxo de trabalho para diferentes tarefas.
Tarefas de fluxo de trabalho
O Integro automatiza atividades relacionadas ao ciclo de vida da tarefa. Simplificado pelo ciclo de vida da tarefa, entendemos o fluxo de trabalho de uma tarefa no Jira. Nos nossos processos de desenvolvimento, existem várias variações do fluxo de trabalho, dependendo do projeto, tipo de tarefa e opções selecionadas em uma tarefa específica.
Considere o fluxo de trabalho que usamos com mais frequência:
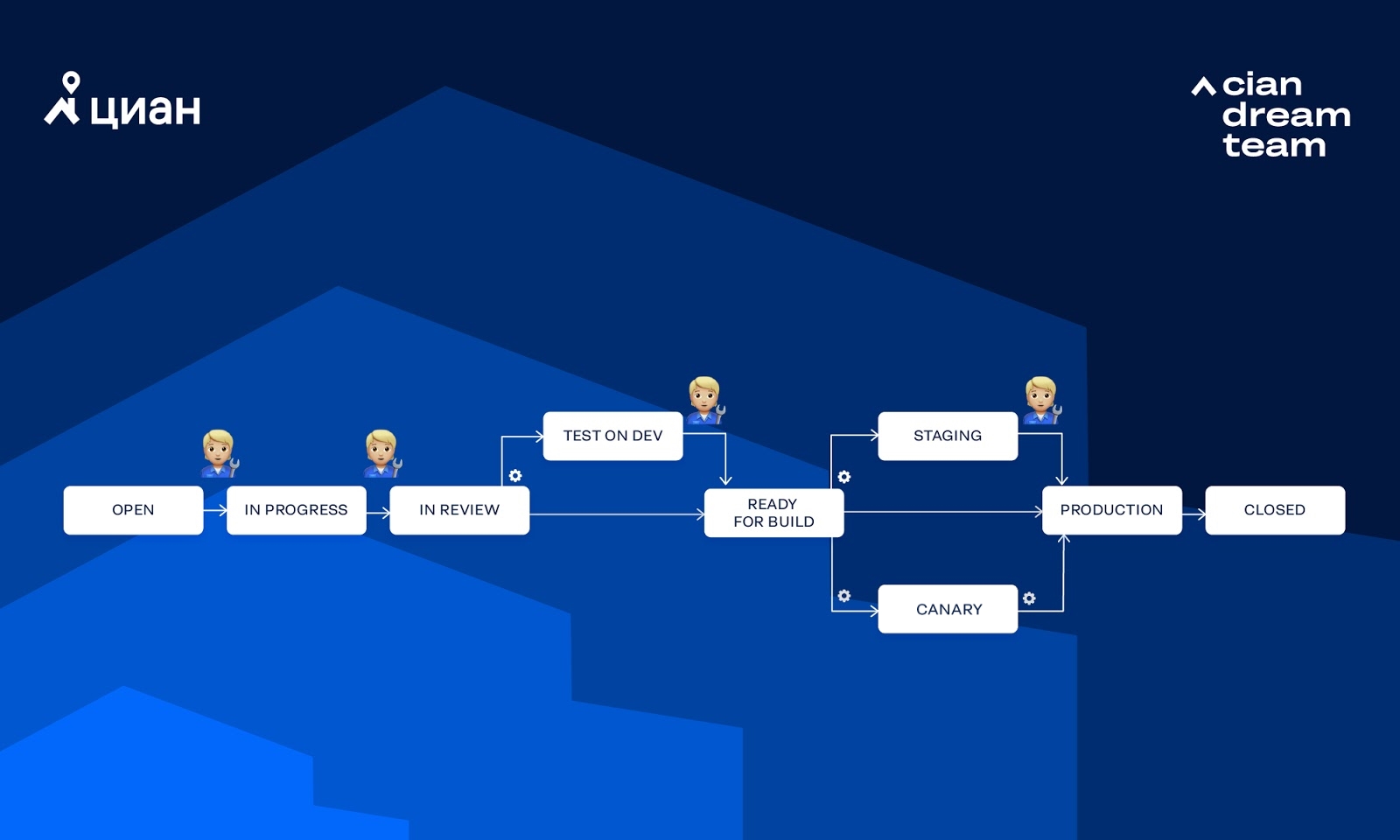
No diagrama, a engrenagem indica que a transição é chamada automaticamente pela Integro, enquanto a figura humana significa que a transição é chamada manualmente pela pessoa. Vejamos algumas maneiras pelas quais uma tarefa pode passar por esse fluxo de trabalho.
Teste totalmente manual para DEV + BETA sem testes em canários (geralmente liberamos um monólito):
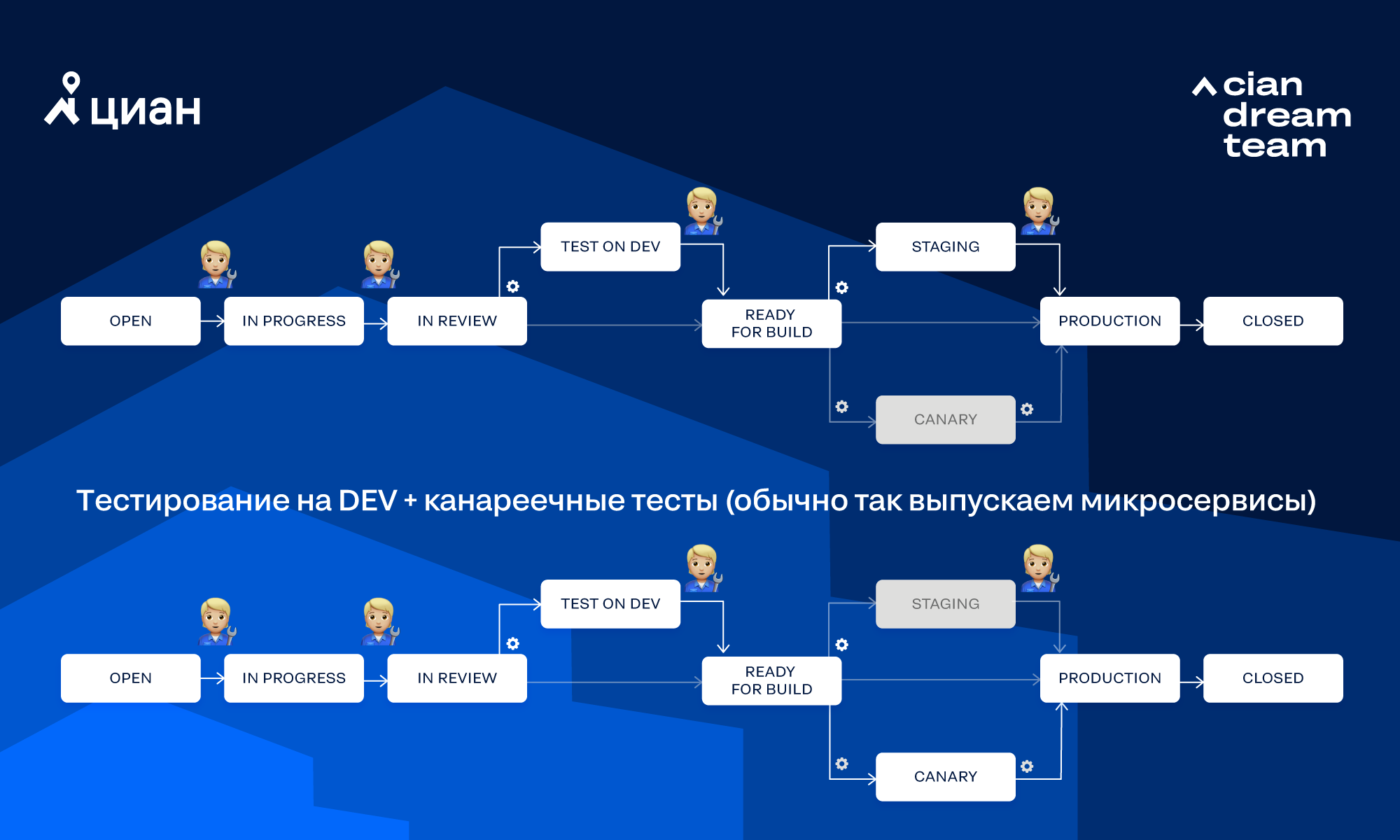
Pode haver outras combinações de transição. Às vezes, o caminho que a tarefa seguirá pode ser selecionado por meio de opções no Jira.
Movimento de tarefas
Considere as etapas básicas que são executadas ao mover a tarefa no fluxo de trabalho "Testando para testes canários DEV +":
1. O desenvolvedor ou o PM cria a tarefa.
2. O desenvolvedor assume a tarefa de trabalhar. Após a conclusão, o transfere para o status IN REVIEW.
3. O Jira envia o Webhook ao microsserviço Jira (é responsável pela integração com o Jira).
4. O microsserviço Jira envia uma solicitação ao serviço Flow (é responsável pelos fluxos de trabalho internos nos quais o trabalho é executado) para iniciar o fluxo de trabalho.
5. Dentro do serviço Flow:
- Os revisores da tarefa são atribuídos (Usuários-microservice que sabem tudo sobre usuários + Jira-microservice).
- Por meio do microsserviço de origem (ele conhece repositórios e ramificações, mas não funciona com o próprio código), procura repositórios nos quais há uma ramificação de nossa tarefa (para simplificar a pesquisa, o nome da ramificação corresponde ao número da tarefa em Jira). Na maioria das vezes, a tarefa tem apenas uma ramificação em um repositório, isso simplifica o gerenciamento da fila na implantação e reduz a conectividade entre os repositórios.
- Para cada ramificação encontrada, a seguinte sequência de ações é executada:
i) Abastecendo a ramificação principal (microsserviço Git para trabalhar com código).
ii) A ramificação está impedida de alterações pelo desenvolvedor (microsserviço Bitbucket).
iii) Uma solicitação pull é criada nesta ramificação (microsserviço Bitbucket).
iv) Uma mensagem sobre a nova solicitação de recebimento é enviada aos bate-papos do desenvolvedor (notifique o microsserviço por trabalhar com notificações).
v) Compilar, testar e implantar tarefas no DEV (microsserviço Jenkins para trabalhar com o Jenkins).
vi) Se todos os parágrafos anteriores tiverem sido concluídos com sucesso, a Integro colocará sua aprovação no pedido de solicitação (microsserviço Bitbucket). - A Integro espera uma aprovação por solicitação dos revisores designados.
- Assim que todas as aprovações necessárias forem recebidas (incluindo a aprovação dos testes automatizados), o Integro transfere a tarefa para o status Test on Dev (Jira microservice).
6. Os testadores testam a tarefa. Se não houver problemas, eles transferirão a tarefa para o status Ready For Build.
7. A Integro “vê” que a tarefa está pronta para lançamento e inicia sua implantação no modo canário (microsserviço Jenkins). A disponibilidade para liberação é determinada por um conjunto de regras. Por exemplo, uma tarefa no status correto, não há bloqueios em outras tarefas, agora não há cálculos ativos desse microsserviço, etc.
8. A tarefa é transferida para o status de Canárias (Jira-microservice).
9. Jenkins inicia no Nomad uma implantação de tarefas no modo canário (geralmente de 1 a 3 instâncias) e notifica o serviço de monitoramento de liberação (microsserviço DeployWatch) do cálculo.
10. O DeployWatch-microservice coleta erros de segundo plano e responde a ele, se necessário. Se o erro de segundo plano for excedido (a taxa de segundo plano é calculada automaticamente), os desenvolvedores são notificados por meio do microsserviço Notify. Se após 5 minutos o desenvolvedor não responder (clicar em Reverter ou Permanecer), a reversão automática das instâncias do canary será iniciada. Se o fundo não for excedido, o desenvolvedor deverá iniciar manualmente a implantação da tarefa na Produção (pressionando o botão na interface do usuário). Se dentro de 60 minutos o desenvolvedor não iniciar uma implantação na Produção, as instâncias canárias também serão implementadas por motivos de segurança.
11. Após iniciar a implantação no Production:
- A tarefa é transferida para o status Produção (microsserviço Jira).
- O microsserviço Jenkins inicia o processo de implantação e notifica a implantação do microsserviço DeployWatch.
- O DeployWatch-microservice verifica se todos os contêineres foram atualizados na Produção (houve casos em que nem todos foram atualizados).
- Uma notificação sobre os resultados da implantação no Production é enviada pelo microsserviço Notify.
12. Os desenvolvedores terão 30 minutos para iniciar a reversão da tarefa com Produção em caso de detecção de comportamento incorreto do microsserviço. Após esse período, a tarefa será automaticamente despejada no mestre (Git-microservice).
13. Após uma mesclagem bem-sucedida no mestre, o status da tarefa será alterado para Fechado (Jira microservice).
O esquema não pretende ser totalmente detalhado (na realidade, existem ainda mais etapas), mas permite avaliar o grau de integração nos processos. Não consideramos esse esquema ideal e melhoramos os processos de rastreamento automático de lançamentos e implantações.
O que vem a seguir
Temos grandes planos para o desenvolvimento da automação, por exemplo, a rejeição de operações manuais durante lançamentos de monólitos, melhoria do monitoramento durante a implantação automática, melhoria da interação com os desenvolvedores.
Mas, por enquanto, vamos parar neste lugar. Cobrimos superficialmente muitos tópicos na revisão de automação, alguns nem sequer os tocaram; portanto, teremos o maior prazer em responder a perguntas. Estamos aguardando sugestões sobre o que abordar em detalhes, escreva nos comentários.