Olá Habr! Apresento a você a tradução do artigo "Visualizando um modelo de tradução automática neural (mecânica dos modelos Seq2seq com atenção)", de Jay Alammar.
Os modelos sequência a sequência (seq2seq) são modelos de aprendizado profundo que obtiveram grande sucesso em tarefas como tradução automática, resumo de texto, anotação de imagem etc. Por exemplo, no final de 2016, um modelo semelhante foi incorporado ao Google Translate. As bases dos modelos seq2seq foram estabelecidas em 2014 com o lançamento de dois artigos - Sutskever et al., 2014 , Cho et al., 2014 .
Para entender e usar adequadamente esses modelos, alguns conceitos devem ser esclarecidos. As visualizações propostas neste artigo serão um bom complemento para os artigos mencionados acima.
O modelo de sequência a sequência é um modelo que aceita uma sequência de entrada de elementos (palavras, letras, atributos de imagem etc.) e retorna outra sequência de elementos. O modelo treinado funciona da seguinte maneira:
Na tradução automática neural, uma sequência de elementos é uma coleção de palavras que são processadas por sua vez. A conclusão também é um conjunto de palavras:
Dê uma olhada sob o capô
Sob o capô, o modelo possui um codificador e decodificador.
O codificador processa cada elemento da sequência de entrada, converte as informações recebidas em um vetor chamado contexto. Após processar toda a sequência de entrada, o codificador envia o contexto para o decodificador, que então começa a gerar o elemento de sequência de saída por elemento.
O mesmo acontece com a tradução automática.
Para tradução automática, o contexto é um vetor (uma matriz de números), e o codificador e decodificador, por sua vez, são frequentemente redes neurais recorrentes (consulte a introdução ao RNN - uma introdução amigável às redes neurais recorrentes ).

Contexto é um vetor de números de ponto flutuante. Além disso, no artigo, os vetores serão visualizados em cores para que a cor mais clara corresponda às células com valores grandes.
Ao treinar o modelo, você pode definir o tamanho do vetor de contexto - o número de neurônios ocultos (unidades ocultas) no codificador RNN. Os dados de visualização mostram um vetor quadridimensional, mas em aplicativos reais o vetor de contexto terá uma dimensão da ordem de 256, 512 ou 1024.
Por padrão, a cada intervalo de tempo, a RNN recebe dois elementos para entrada: o próprio elemento de entrada (no caso de um codificador, uma palavra da frase original) e o estado oculto. A palavra, no entanto, deve ser representada por um vetor. Para converter uma palavra em vetor, eles recorrem a uma série de algoritmos chamados incorporação de palavras. Casamentos traduzem palavras em espaços vetoriais contendo informações semânticas e semânticas sobre eles (por exemplo, "rei" - "homem" + "mulher" = "rainha" ).
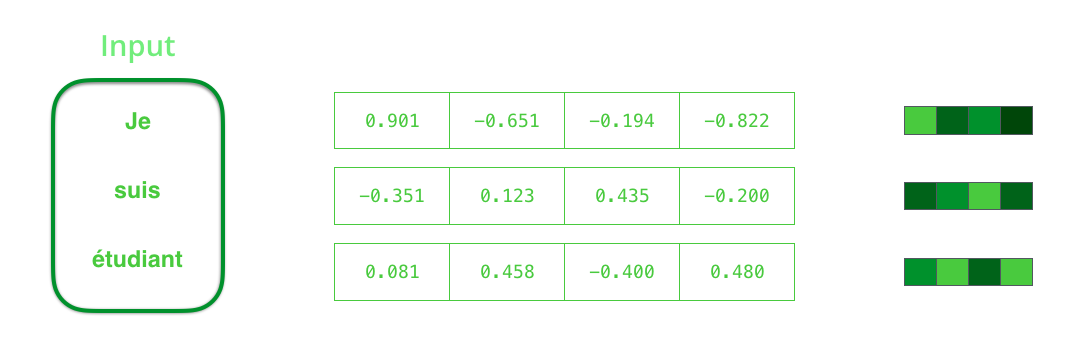
Antes de processar palavras, você deve convertê-las em vetores. Essa transformação é realizada usando o algoritmo de incorporação de palavras. Você pode usar as combinações pré-treinadas e as treinadas no seu conjunto de dados. 200-300 - dimensão típica do vetor de incorporação; este artigo usa a dimensão 4 para simplificar.
Agora que nos familiarizamos com nossos principais vetores / tensores, vamos relembrar o mecanismo da RNN e criar visualizações para descrevê-lo:
Na próxima etapa, a RNN pega o segundo vetor de entrada e o estado latente nº 1 para formar a saída nesse intervalo de tempo. Mais adiante neste artigo, animação semelhante é usada para descrever vetores dentro de um modelo de tradução automática neural.
Na visualização a seguir, cada quadro descreve o processamento de entradas por um codificador e a geração de saídas por um decodificador em um intervalo de tempo. Como o codificador e o decodificador são RNN, a cada intervalo de tempo, a rede neural está ocupada processando e atualizando seus estados ocultos com base nas entradas atuais e em todas as anteriores. Nesse caso, o último dos estados ocultos do codificador é o próprio contexto que é transmitido ao decodificador.
O decodificador também contém estados ocultos que são transferidos de um intervalo de tempo para outro. (Isso não está na visualização, representando apenas as partes principais do modelo.)
Passamos agora a outro tipo de visualização de modelos de sequência a sequência. Esta animação ajudará a entender os gráficos estáticos que descrevem esses modelos - os chamados uma visão desenrolada, onde, em vez de mostrar um decodificador, mostramos uma cópia para cada intervalo de tempo. Assim, podemos observar os elementos de entrada e saída a cada intervalo de tempo.
Preste atenção!
O vetor de contexto é um gargalo para esse tipo de modelo, dificultando o tratamento de frases longas. A solução foi proposta nos artigos de Bahdanau et al., 2014 e Luong et al., 2015 , que apresentaram uma técnica chamada mecanismo de atenção. Esse mecanismo melhora significativamente a qualidade dos sistemas de tradução automática, permitindo que os modelos se concentrem nas partes relevantes das seqüências de entrada.
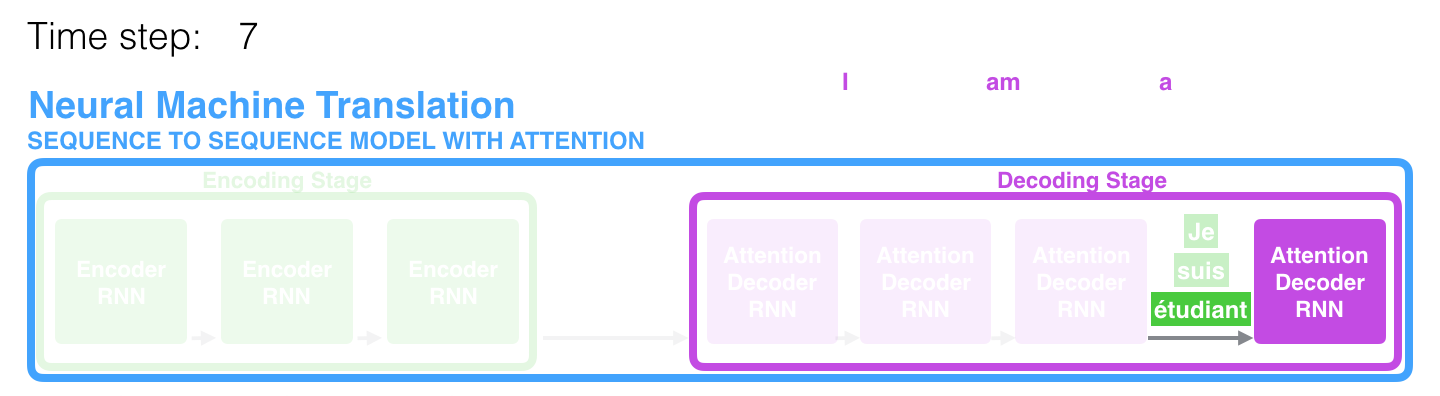
No 7º período de tempo, o mecanismo de atenção permite que o decodificador se concentre na palavra étudiant (estudante de francês) antes de gerar uma tradução para o inglês. Essa capacidade de amplificar o sinal da parte relevante da sequência de entrada permite que os modelos baseados no mecanismo de atenção obtenham um melhor resultado em comparação com outros modelos.
Ao considerar um modelo com um mecanismo de atenção em um alto nível de abstração, duas diferenças principais em relação ao modelo clássico de sequência a sequência podem ser distinguidas.
Primeiramente, o codificador transfere significativamente mais dados para o decodificador: em vez de transmitir apenas o último estado oculto após o estágio de codificação, o codificador envia todos os seus estados ocultos para ele:
Em segundo lugar, o decodificador passa por uma etapa adicional antes de gerar a saída. Para focar nas partes da sequência de entrada relevantes para o intervalo de tempo correspondente, o decodificador faz o seguinte:
- Examina um conjunto de estados latentes recebidos de um codificador - cada um dos estados latentes se correlaciona melhor com uma das palavras na sequência de entrada;
- Atribui uma determinada avaliação a cada estado latente (vamos omitir por enquanto como o procedimento de estimativa acontece);
- Multiplica cada estado oculto por uma função de avaliação convertida em softmax, destacando estados ocultos com uma classificação grande e relegando estados ocultos com um pequeno para o fundo.
Este "exercício de classificação" é realizado no decodificador a cada intervalo de tempo.
Portanto, resumindo tudo isso, consideramos o processo do modelo com o mecanismo de atenção:
- No decodificador, o RNN recebe a incorporação <END> do token e o estado oculto inicial.
- A RNN processa o elemento de entrada, gera a saída e um novo vetor de estado oculto (h4). A saída é descartada.
- O mecanismo de atenção usa os estados ocultos do codificador e o vetor h4 para calcular o vetor de contexto (C4) em um determinado intervalo de tempo.
- Os vetores h4 e C4 são concatenados em um único vetor.
- Esse vetor é passado através de uma rede neural feedforward (FFN), treinada em conjunto com o modelo.
- A saída da rede FFN indica a palavra de saída em um determinado intervalo de tempo.
- O algoritmo é repetido para o próximo intervalo de tempo.
Outra maneira de analisar qual parte da frase original o modelo foca em cada estágio do decodificador:
Observe que o modelo não conecta apenas a primeira palavra na entrada com a primeira palavra na saída. Ela realmente entendeu durante o processo de treinamento como combinar as palavras nesse par de idiomas considerado (no nosso caso, francês e inglês). Um exemplo de como esse mecanismo pode funcionar com precisão pode ser encontrado nos artigos sobre o mecanismo de atenção mencionado acima.

Se você sentir que está pronto para aprender como aplicar esse modelo, consulte o manual de Tradução Automática Neural (seq2seq) no TensorFlow.
Os autores