DeepStereo算法将Google Street View镜头粘贴到流畅的视频中
Google研究人员John Flynn,Ivan Nyulander,James Filbin和Noah Sneyvli创建了一种算法,该算法可以将Street View全景视图服务中的图像合并到几乎没有明显伪像的平滑视频中。该算法称为DeepStereo,上面提供了其操作示例。所创建技术的可能用途包括创建简单的动画,图像处理,电影院和虚拟现实。不一定总是仅通过地图或数字照片就足以评估某个地方。从高于人的高度看街道可以帮助Google Street View等服务。但是这些是粘贴到全景中的照片,而不是视频。如果您需要创建从单个镜头向前移动的动画,那么简单地丢失图像序列的决定将不起作用-事实证明它太快了,因为图像的更改频率至少为每秒24帧。如果您在宽阔,平坦的道路或高速公路上行驶,则可以以慢动作的方式创建出色的动画。但是Google街景视图具有博物馆和华丽街道的全景图-快速更改框架的时间流逝在这里不起作用。两次拍摄之间需要丢失图像。为此创建了算法。研究人员团队利用公司的丰富知识来训练算法。在输入处有一组来自某些点的图像,目标是从其他点创建新的帧。要解决此问题,需要构建3D环境模型,由于障碍物,这通常是不可能的。挑战并不新鲜。某些先前的方法存在的问题会导致壁垒附近出现间隙,混叠和模糊。树木和其他物体的个别元素可能会使视线模糊,因此会造成特别的困难。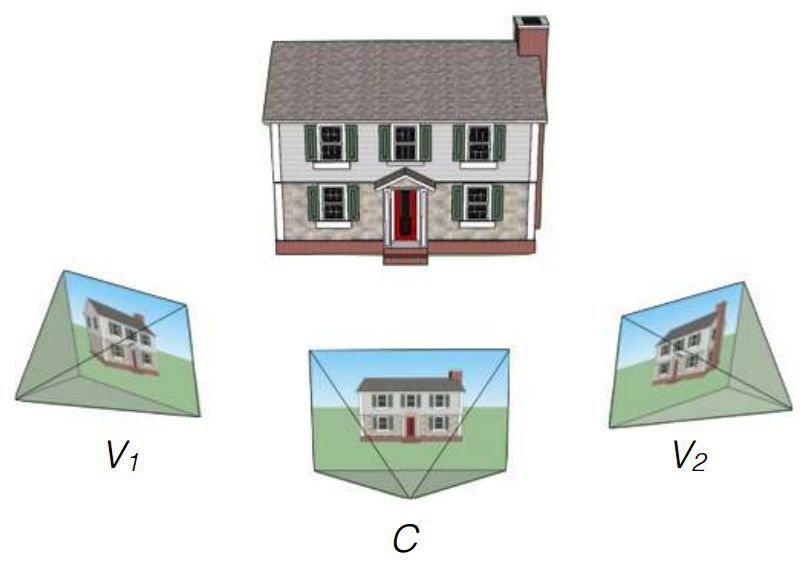 弗林(Flynn)的新方法使用了计算机视觉训练,这样他就可以了解丢失的帧中应该有哪些物体。为了进行训练,使用了来自行驶中的汽车的图像集。研究人员说,训练基地的数量达10万套图像。然后,使用来自Google街景视图的三张照片序列进行测试。该算法被迫处理两个极端图像,并提出了中间版本的变体。与原作的比较可以评价工作。DeepStereo团队的最终结果令人信服。乍一看,将其与真实摄影区分开来并不容易。值得注意的伪像包括分辨率的轻微损失以及前景中精细结构的消失。结构复杂且重叠其自身细节的对象可能显得模糊。该算法也无法创建不在原始图片中的曲面。运动对象(行人,汽车)被故意模糊以创建运动效果。渲染需要令人印象深刻的计算能力。要仅创建一张分辨率为512×512像素的图像,需要运行具有未命名技术特征的多核系统大约12分钟。创建更高分辨率的图像需要太多RAM。研究人员表达了他们希望通过使用视频卡处理器将渲染时间减少到几分钟甚至几秒钟来优化算法的希望。未来,如果进行重大改进,即使是实时也可以在GPU上运行算法。基于研究文本和MIT技术评论。arXiv:1506.06825 [cs.CV]
弗林(Flynn)的新方法使用了计算机视觉训练,这样他就可以了解丢失的帧中应该有哪些物体。为了进行训练,使用了来自行驶中的汽车的图像集。研究人员说,训练基地的数量达10万套图像。然后,使用来自Google街景视图的三张照片序列进行测试。该算法被迫处理两个极端图像,并提出了中间版本的变体。与原作的比较可以评价工作。DeepStereo团队的最终结果令人信服。乍一看,将其与真实摄影区分开来并不容易。值得注意的伪像包括分辨率的轻微损失以及前景中精细结构的消失。结构复杂且重叠其自身细节的对象可能显得模糊。该算法也无法创建不在原始图片中的曲面。运动对象(行人,汽车)被故意模糊以创建运动效果。渲染需要令人印象深刻的计算能力。要仅创建一张分辨率为512×512像素的图像,需要运行具有未命名技术特征的多核系统大约12分钟。创建更高分辨率的图像需要太多RAM。研究人员表达了他们希望通过使用视频卡处理器将渲染时间减少到几分钟甚至几秒钟来优化算法的希望。未来,如果进行重大改进,即使是实时也可以在GPU上运行算法。基于研究文本和MIT技术评论。arXiv:1506.06825 [cs.CV] Source: https://habr.com/ru/post/zh-CN381787/
All Articles