机器自学的又一步
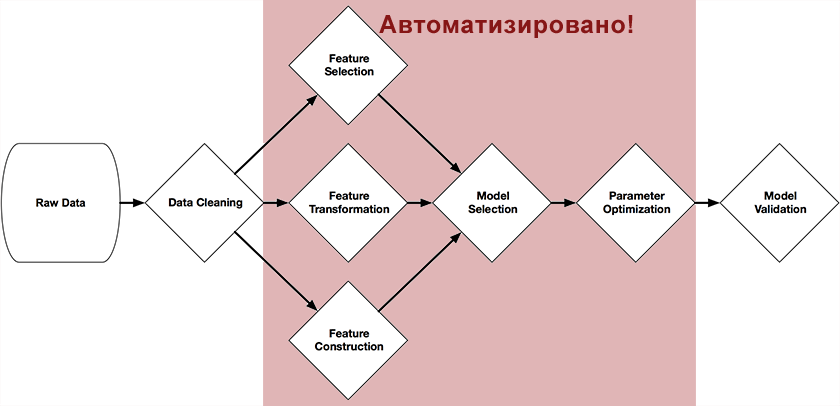 当然,数据科学中有很多自学模型,但是真的吗?实际上,没有:在机器学习中,人为因素在建立有效模型中起着决定性的作用。数据科学现在是科学与直觉的融合,因为尚无关于如何正确预测预测变量,从数十种现有预测模型中选择哪种模型以及如何在此模型中配置许多参数的形式化知识。所有这些都很难形式化,因此出现了自相矛盾的情况- 机器学习需要人为因素。需要构建学习链并调整参数的人才能轻松地将最佳模型变成绝对无用的东西。根据任务的复杂程度,将初始数据转换为预测模型的链条的构建可能需要花费数周的时间,并且通常仅需反复试验即可完成。这是一个严重的缺陷,因此产生了一个想法:机器学习是否可以像人一样教育自己?创建了这样的系统,令人惊讶的是,这一消息尚未传到habrasociety!
当然,数据科学中有很多自学模型,但是真的吗?实际上,没有:在机器学习中,人为因素在建立有效模型中起着决定性的作用。数据科学现在是科学与直觉的融合,因为尚无关于如何正确预测预测变量,从数十种现有预测模型中选择哪种模型以及如何在此模型中配置许多参数的形式化知识。所有这些都很难形式化,因此出现了自相矛盾的情况- 机器学习需要人为因素。需要构建学习链并调整参数的人才能轻松地将最佳模型变成绝对无用的东西。根据任务的复杂程度,将初始数据转换为预测模型的链条的构建可能需要花费数周的时间,并且通常仅需反复试验即可完成。这是一个严重的缺陷,因此产生了一个想法:机器学习是否可以像人一样教育自己?创建了这样的系统,令人惊讶的是,这一消息尚未传到habrasociety!TROT(基于树的管道优化工具)
兰迪·奥尔森(Randy Olson)是宾夕法尼亚大学计算遗传学实验室的研究生,他开发了一种基于树的管道优化工具,这是他的毕业设计的一部分。该系统定位为数据科学助理。它可以自动完成机器学习中最繁琐的部分,从而研究和选择成千上万个最适合处理数据的构建链。该系统使用scikit-learn库以Python编写,并通过遗传算法独立构建了完整的模型准备和构建链。本文开头的图显示了链中可以借助其自动化的那些部分:预处理程序和预测变量的选择,模型的选择,参数的优化。这个想法很简单-一种遗传算法。这是一种使用类似于自然选择机制的方法,通过随机选择来找到所需链的算法。在Wikipedia,Habr或“自学系统”一书中对它们进行了足够详细的描述。(我建议对此主题感兴趣的人使用电子形式的网络)。作为选择的一项功能(健身功能),使用了scikit方法及其参数作为测试对象中预测对象的准确性。结果
作者提供了一个简单的示例,说明如何使用TPOT来解决MNIST集合中手写数字分类的参考问题。from tpot import TPOT
from sklearn.datasets import load_digits
from sklearn.cross_validation import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, train_size=0.75)
tpot = TPOT(generations=5, verbosity=2)
tpot.fit(X_train, y_train)
print( tpot.score(X_train, y_train, X_test, y_test) )
tpot.export('tpot_exported_pipeline.py')
在运行代码后,几分钟后,TPOT可以获取模型构建链,其准确性达到98%。当TPOT发现随机森林分类器在MNIST数据上完美工作时,就会发生这种情况。但是,由于此过程是概率性的,因此建议为可重复的结果设置random_state参数-例如,对于5代,我只发现了一条带有SVC和KNeighborsClassifier的链。在另一个经典问题(费舍尔的虹膜)上对系统进行测试,可在10代内达到97%的准确性。未来
Trot是一个开源项目,始于一个月前(通常是此类系统的儿童年龄),目前正在积极开发中。在项目的网站上,作者鼓励数据科学家社区加入其代码可在github(https://github.com/rhiever/tpot)上获得的系统的开发中。当然,现在该系统远非理想,但该系统的构想看起来非常合乎逻辑-完全自动化机器学习的全过程。而且,如果这个想法得以发展,那么也许很快就会出现系统,人们只需要下载数据并获得结果即可。然后会出现另一个问题:是否完全需要一个人来建立自学模型?