思维衍生的逻辑2:一些链接算法
挑战:
将经常重复的事件序列分成单独的链,其中不会有多余的内容。此任务有许多解决方案。经常使用“烘焙”-那些经常使用的关系是固定的,而其他关系则被削弱。在决赛中,您应该获得一个链条,在链条中,最频繁重复的事件具有紧密的联系。该解决方案具有许多缺点,其中包括-低速度。但是我们确实有Redozubov发出的识别波,我们可以使用其他算法,这些算法可以在第一次重复后形成一条新链。让我们从一个简单的开始。在最后的音符中描述了一种用于在存储链中记录所有事件的方法。让系统一次读取“衰减”一词,然后再读取“瀑布”一词。这两个词具有相同的部分-三个字母的结尾。根据问题的情况,有必要突出显示链“垫”。该链没有任何先决条件,也就是说,它可以轻松识别相应的输入。一种解决方案
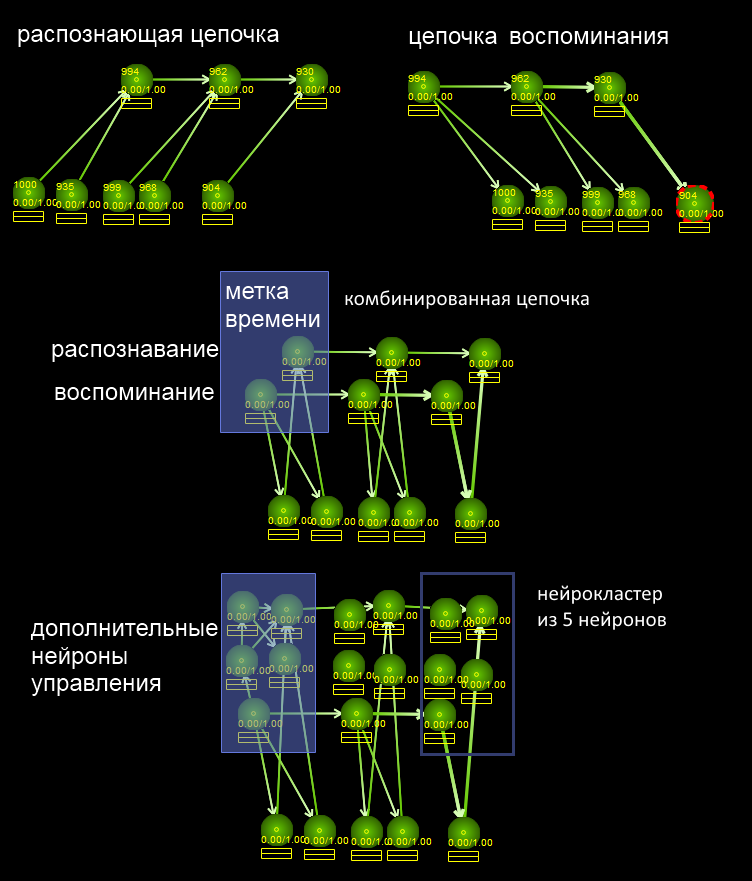 我们将任务分为两部分:1)找到两个相似的事件系列(您需要了解,这两个词大约包含相似的序列)2)在单独的链(“填充”)中选择它们让我们从第2部分开始。如图所示,我们使神经簇复杂化并带有时间戳,时间戳将所有事件存储在存储链中。多亏了识别部分(从属性到广义时间戳的连接方向),子任务1得以解决-查找具有公共属性的位置,并且由于链接断开的存储链,子任务2也得以解决。子任务2的解决方案是:我们将开始同时调用两个单词他们有什么共同点。也就是说,系统将通过与那些字母相对应的神经元发送激活信号。如果在两个单词中都找到字母,则必须记住该字母。为此,只需一半的力气即可完成记忆。如果神经元的激活阈值为T,则记忆链应发送0.5 T的动作电位。只有在以下情况下才会超过激活阈值当症状在两个链中都遇到时。此后,症状被激活。然后,您可以将常用的记忆算法与上一篇文章中的代码一起使用-海马体将创建一条记忆链,并为其分配两个链共同的符号。我们将解决方案简化为上一个解决方案。在ENS(体内NS)中,可以通过改变发送时间(到达的尖峰数),神经递质的数量或使用抑制性连接(将1T变为0.5T)来实现“半激活”。子任务1稍微复杂一些,因为它应该与模糊识别一起工作。也就是说,即使在链的中间某处丢失了一些常见的标志,您仍然应该注意到这种情况。让我提醒您,相对而言,神经元可以处于三种模式-休息,发送单个信号和高频激活模式。可以接受的是,“完全识别”会导致神经元过渡到高频激活模式,而模糊识别会导致单个信号传输。或者我们可以假设在神经簇中将存在专门的神经元,其中一些仅在完全重合和确信的识别下才能起作用,而其他神经元在仅识别部分特征时才起作用。有很多解决方案,主要是要以某种方式注意到所需集群上激活的出现。
我们将任务分为两部分:1)找到两个相似的事件系列(您需要了解,这两个词大约包含相似的序列)2)在单独的链(“填充”)中选择它们让我们从第2部分开始。如图所示,我们使神经簇复杂化并带有时间戳,时间戳将所有事件存储在存储链中。多亏了识别部分(从属性到广义时间戳的连接方向),子任务1得以解决-查找具有公共属性的位置,并且由于链接断开的存储链,子任务2也得以解决。子任务2的解决方案是:我们将开始同时调用两个单词他们有什么共同点。也就是说,系统将通过与那些字母相对应的神经元发送激活信号。如果在两个单词中都找到字母,则必须记住该字母。为此,只需一半的力气即可完成记忆。如果神经元的激活阈值为T,则记忆链应发送0.5 T的动作电位。只有在以下情况下才会超过激活阈值当症状在两个链中都遇到时。此后,症状被激活。然后,您可以将常用的记忆算法与上一篇文章中的代码一起使用-海马体将创建一条记忆链,并为其分配两个链共同的符号。我们将解决方案简化为上一个解决方案。在ENS(体内NS)中,可以通过改变发送时间(到达的尖峰数),神经递质的数量或使用抑制性连接(将1T变为0.5T)来实现“半激活”。子任务1稍微复杂一些,因为它应该与模糊识别一起工作。也就是说,即使在链的中间某处丢失了一些常见的标志,您仍然应该注意到这种情况。让我提醒您,相对而言,神经元可以处于三种模式-休息,发送单个信号和高频激活模式。可以接受的是,“完全识别”会导致神经元过渡到高频激活模式,而模糊识别会导致单个信号传输。或者我们可以假设在神经簇中将存在专门的神经元,其中一些仅在完全重合和确信的识别下才能起作用,而其他神经元在仅识别部分特征时才起作用。有很多解决方案,主要是要以某种方式注意到所需集群上激活的出现。什么时候做
问题是什么时候进行这种搜索。可以有几种方法:1)专门的睡眠模式-更准确地说是“慢速睡眠”。该系统经历一天中学习到的所有事件,并寻找与其其他内存匹配的内容。在这种情况下,系统使用内存-以降序发送,然后给信号的神经元留出时间将信号“向上”发送给其他内存。之后,他总结并搜索具有最大总激活量的那些记忆。然后,他选择这些位置之一并启动子任务2-“选择链”。2)没有专门的睡眠方案。该系统可以在感知过程中进行即时搜索-当前情况如何?实际上,由于神经元发送信号,搜索在正常思维过程中自动发生,系统只能注意与当前情况有很多共同之处的记忆,如果有必要,请运行分析-选择常规子链。相似的算法
这些算法看起来很简单,但是它们包含了许多微妙之处,甚至比快速排序算法中的要多,正如您所知,快速排序算法很长一段时间都不会出现错误。此任务类似于已知任务,例如搜索常见的DNA子序列。在每个步骤中,只有DNA只能具有一个核苷酸,并且在每个时间戳记的神经网络中,可以有任意数量的字符。因此,与DNA搜索相比,此任务是更一般的情况。如果您尝试通过操纵符号列表来转移现有算法并在没有神经网络的情况下解决此类“漏洞”问题,那么您的头就会开始旋转-所有这些嵌套的匹配列表,匹配序列列表以及其他问题。通过向神经元发送激活来解决此问题要容易得多-神经元已经存在,它们会自动执行所有操作,已经为它们分配了内存,不需要嵌套列表,仅用于分析某些神经元并运行必要的算法。我将子任务1和2模式分别称为一个和两个前导链。也就是说,“存储链中有多少活跃的降序神经元发送信号以突出显示匹配项。” 如果只有一个这样的召回链,那么它正在寻找第二个候选者进行验证。如果已经找到候选人,则可以激活他并开始突出显示标志。这样的名称(“ 1或2前导链”)将使按名称而不是“子任务1或2”来引用这些算法成为可能。具有一个前导链的模式也可以称为“重合搜索模式”,而具有两个前导链的模式可以称为巧合突出显示模式。搜索比赛...
(1,1条主导链)可以通过以下方式进行:1)线性查看一天中遇到的所有记忆。可以出于以下目的转换到此模式以进行调试:将特殊的Unicode字符或特殊的单词插入到ANN的输入数据测试集中;读取后,ANN将切换到“慢睡眠”模式并开始搜索匹配项。意思是-他们用真实的数据填充了ANN,启动了查找泛化的调试算法。2)不使用线性搜索,而是从最有趣的情况开始分析-对那些具有最大情感色彩的情况进行分析。由于这些算法非常繁琐,因此需要进行优化。在大鼠中,回想起白天似乎比白天回想起来快大约10倍。睡眠所需时间少于清醒时间。因此,通过在所有内存之间均匀分配时间,可以对每个内存进行管理,以仅比较几种相似的情况,其中大多数将是垃圾且无关紧要的巧合。因此,专注于最重要的内容并开始使用它是有益的。我们可以说该算法又增加了一个步骤-0个前导链,在这一步中,系统应选择内存中具有最高重要性的下一个事件,并将其传递给下一步-使其成为寻找比赛的线索链。3)可以从清醒时开始制作衬线-预先建立到需要在晚上进行比较的最有趣地方的连接。会记住一些巧合的巧合链,但将来,如果它们的重要性随着时间而逐渐消失,它们可能会被遗忘。忘了
忘记会导致神经簇被删除-removeNC操作,与newNC操作相反。在ENS中,神经元不会流到任何地方,它们也不会死亡,它们的连接只会减弱到不再对它们的体征做出反应的程度,并准备重新调整以记住另一种组合。在我们的模型中,不需要存储此类神经元,可以立即将其删除-这将加快ANN的运行速度,减少内存消耗并简化调试。这使您可以将内存消耗需求降低一个数量级。并行化
为了从1模式过渡到2模式,我首先尝试创建控制神经元,该神经元产生信号切换,分析和模式改变。但是后来我发现这项工作太底层了,开始编写命令式C ++代码-例如“遍历所有群集,对其进行分析,选择所需的群集,然后考虑是否更改操作模式”之类的代码。这样的系统的性能问题:如果您使神经元硬件,则可以并行化它们(是的,至少在视频卡上)。然后,可以轻松且自动地对集群中具有控制神经元和连接的代码进行并行化(这只是一个激活包,根据任务的条件进行了并行化),但是命令性C ++代码每次都必须独立进行并行化。因此,对于小型单线程神经网络,更容易编写C ++代码;对于大规模并行的ANN,最好将其工作在ANN内部传递给神经元及其之间的连接。从硬件ANN的角度来看,我们绝不能忘记C ++中的“遍历所有神经元”或“遍历所有神经团”是O(1),这是发送激活的一个步骤。因此可以看出理想并行化的ANN的1VT和2VT(前导链)都具有相同的计算复杂度。延续:人工神经网络中的原始预测Source: https://habr.com/ru/post/zh-CN388725/
All Articles